《大数据跟我学系列文章-轻松通关 Flink ——06.Flink 进阶篇》
大数据跟我学系列文章006-轻松通关 Flink
——06.Flink 进阶篇
模块二:进阶篇第07讲:Flink 常见核心概念分析
第08讲:Flink 窗口、时间和水印
第09讲:Flink 状态与容错
第10讲:Flink Side OutPut 分流
第11讲:Flink CEP 复杂事件处理
第12讲:Flink 常用的 Source 和 Connector
模块三:生产实践篇
第13讲:如何实现生产环境中的 Flink 高可用配置
第14讲:Flink Exactly-once 实现原理解析
第15讲:如何排查生产环境中的反压问题
第16讲:如何处理生产环境中的数据倾斜问题
第17讲:生产环境中的并行度和资源设置
第18讲:如何进行生产环境作业监控
第19讲:Flink 如何做维表关联
第20讲:Flink 高级应用之海量数据高效去重
第21讲:Flink 在实时计算平台和实时数据仓库中的作用
模块四:高级实战篇
第22讲:项目背景和整体架构设计
第23讲:Mock Kafka 消息并发送
第24讲:Flink 消费 Kafka 数据业务开发
第25讲:Flink 中 watermark 的定义和使用
第26讲:Flink 中的聚合函数和累加器的设计和使用
第27讲:Flink Redis Sink 实现
第28讲:TopN 热门商品功能实现
第29讲:项目背景和实时处理系统架构设计
第30讲:Flume 和 Kafka 整合和部署
第31讲:Kafka 模拟数据生成和发送
第32讲:Flink 和 Kafka 整合时间窗口设计
第33讲:Flink 计算 PV、UV 代码实现
第34讲:Flink 和 Redis 整合以及 Redis Sink 实现
第35讲:项目背景和 Flink CEP 简介
第36讲:自定义消息事件
第37讲:自定义 Pattern 和报警规则
第38讲:Flink 调用 CEP 实现报警功能
模块五:面试篇
第39讲:Flink 面试-基础篇
第40讲:Flink 面试-进阶篇
第41讲:Flink 面试-源码篇
第42讲:Flink 面试-方案设计篇
结束语
文章目录
- 大数据跟我学系列文章006-轻松通关 Flink
-
- ——06.Flink 进阶篇
- 前言
- 一、Flink 常见核心概念分析
-
- 分布式缓存
- 故障恢复和重启策略
-
- 故障恢复
- 重启策略
-
- (1) 无重启策略模式
- (2) 固定延迟重启策略模式
- (3) 失败率重启策略模式
- 并行度
-
- (1) 算子级别
- (2) 执行环境级别
- (3) 提交任务级别
- (4) 系统配置级别
- slot
- 二、Flink窗口、时间和水印
-
- Flink 的窗口和时间
-
- 窗口
- 时间
-
- (1) 事件时间(Event Time)
- (2) 处理时间(Processing Time)
- (3) 摄入时间(Ingestion Time)
- 水印(WaterMark)
-
- 水印的本质是什么
- 水印是如何生成的
- 水印种类
-
- (1)周期性水印
- (2)PunctuatedWatermark 水印
- 案例(模拟一个实时接收 Socket 的 DataStream 程序)
- 三、Flink 状态与容错
-
- 状态
-
- Flink 状态分类和使用
- 状态示例
- 状态后端种类和配置
-
- (1)MemoryStateBackend
- (2)FsStateBackend
- (3)RocksDBStateBackend
- 总结
- 四、Flink Side OutPut 分流
-
- 分流场景
- 分流的方法
-
- (1)Filter 分流
- (2)Split 分流
- (3)SideOutPut 分流
- 总结
- 五、Flink CEP 复杂事件处理
-
- 背景
- 程序结构
- 模式定义
-
- (1)简单模式
- (2)联合模式
- (3)匹配后的忽略模式
- 源码解析
- 实战案例
- 六、Flink常用的Source和Connector
-
- 预定义和自定义 Source
-
- (1)基于文件
- (2)基于 Collections
- (3)基于 Socket-模拟一个实时计算环境
- (4)自定义 Source
- (5)自带连接器
- (6)基于 Apache Bahir 发布
-
- 集群模式:
- 哨兵模式:
- (7)基于异步 I/O 和可查询状态
前言
本文为拉勾课程《 42讲轻松通关 Flink》笔记,本着“只有亲身实践过并整理成体系才属于自己真正掌握的知识” 的理念写出本篇文章,后续每天更新,持续关注,欢迎留言讨论~。
一、Flink 常见核心概念分析
在 Flink 这个框架中,有很多独有的概念,比如分布式缓存、重启策略、并行度等,这些概念是我们在进行任务开发和调优时必须了解,从原理和应用场景分别介绍这些概念。
二、Flink 窗口、时间和水印
主要介绍 Flink 中的时间和水印。
我们在之前的课时中反复提到过窗口和时间的概念,Flink 框架中支持事件时间、摄入时间和处理时间三种。而当我们在流式计算环境中数据从 Source 产生,再到转换和输出,这个过程由于网络和反压的原因会导致消息乱序。因此,需要有一个机制来解决这个问题,这个特别的机制就是“水印”。
三、Flink 状态与容错
主要讲解 Flink 的状态和容错。
在 Flink 的框架中,进行有状态的计算是 Flink 最重要的特性之一。
所谓的状态,其实指的是 Flink 程序的中间计算结果。Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。
四、Flink Side OutPut 分流
介绍 Flink 中提供的一个很重要的功能:旁路分流器。
五、Flink CEP 复杂事件处理
介绍 Flink 中提供的一个很重要的功能:复杂事件处理 CEP。
六、Flink 常用的 Source 和 Connector
介绍 Flink 中支持的 Source 和常用的 Connector。
Flink 作为实时计算领域强大的计算能力,以及与其他系统进行对接的能力都非常强大。Flink 自身实现了多种 Source 和 Connector 方法,并且还提供了多种与第三方系统进行对接的 Connector。
提示:以下是本篇文章正文内容,下面案例仅供参考
一、Flink 常见核心概念分析
分布式缓存、重启策略、并行度等,这些概念是我们在进行任务开发和调优时必须了解的,这一课时我将会从原理和应用场景分别介绍这些概念。
分布式缓存
熟悉 Hadoop 的你应该知道,分布式缓存最初的思想诞生于 Hadoop 框架,Hadoop 会将一些数据或者文件缓存在 HDFS 上,在分布式环境中让所有的计算节点调用同一个配置文件。在 Flink 中,Flink 框架开发者们同样将这个特性进行了实现。
Flink 提供的分布式缓存类型 Hadoop,目的是为了在分布式环境中让每一个 TaskManager 节点保存一份相同的数据或者文件,当前计算节点的 task 就像读取本地文件一样拉取这些配置。
分布式缓存在我们实际生产环境中最广泛的一个应用,就是在进行表与表 Join 操作时,如果一个表很大,另一个表很小,那么我们就可以把较小的表进行缓存,在每个 TaskManager 都保存一份,然后进行 Join 操作。
那么我们应该怎样使用 Flink 的分布式缓存呢?举例如下:
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.registerCachedFile("/Users/wangzhiwu/WorkSpace/quickstart/distributedcache.txt", "distributedCache");
//1:注册一个文件,可以使用hdfs上的文件 也可以是本地文件进行测试
DataSource<String> data = env.fromElements("Linea", "Lineb", "Linec", "Lined");
DataSet<String> result = data.map(new RichMapFunction<String, String>() {
private ArrayList<String> dataList = new ArrayList<String>();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//2:使用该缓存文件
File myFile = getRuntimeContext().getDistributedCache().getFile("distributedCache");
List<String> lines = FileUtils.readLines(myFile);
for (String line : lines) {
this.dataList.add(line);
System.err.println("分布式缓存为:" + line);
}
}
@Override
public String map(String value) throws Exception {
//在这里就可以使用dataList
System.err.println("使用datalist:" + dataList + "-------" +value);
//业务逻辑
return dataList +":" + value;
}
});
result.printToErr();
}
从上面的例子中可以看出,使用分布式缓存有两个步骤。
-
第一步:首先需要在 env 环境中注册一个文件,该文件可以来源于本地,也可以来源于 HDFS ,并且为该文件取一个名字。
-
第二步:在使用分布式缓存时,可根据注册的名字直接获取。
可以看到,在上述案例中,我们把一个本地的 distributedcache.txt 文件注册为 distributedCache,在下面的 map 算子中直接通过这个名字将缓存文件进行读取****并且进行了处理。
我们直接运行该程序,在控制台可以看到如下输出:
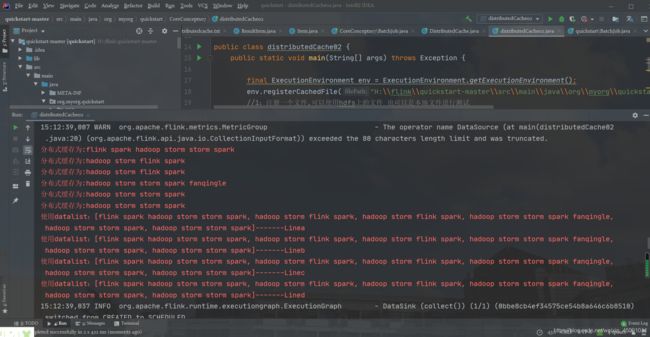
再次运行它:
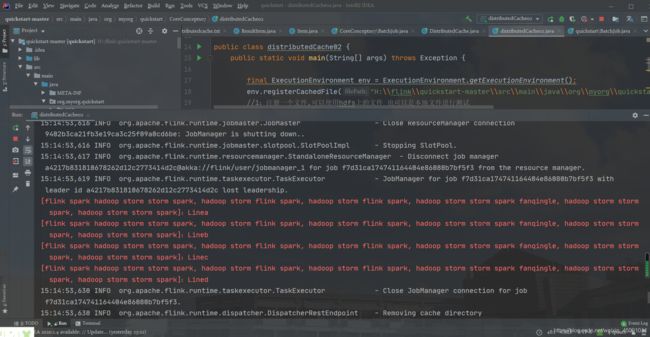
在使用分布式缓存时也需要注意一些问题,需要我们缓存的文件在任务运行期间最好是只读状态,否则会造成数据的一致性问题。另外,缓存的文件和数据不宜过大,否则会影响 Task 的执行速度,在极端情况下会造成 OOM。
故障恢复和重启策略
自动故障恢复是 Flink 提供的一个强大的功能,在实际运行环境中,我们会遇到各种各样的问题从而导致应用挂掉,比如我们经常遇到的非法数据、网络抖动等。
Flink 提供了强大的可配置故障恢复和重启策略来进行自动恢复。
故障恢复
我们在上一课时中介绍过 Flink 的配置文件,其中有一个参数 jobmanager.execution.failover-strategy: region。
Flink 支持了不同级别的故障恢复策略,jobmanager.execution.failover-strategy的可配置项有两种:full 和 region。
当我们配置的故障恢复策略为 full 时,集群中的 Task 发生故障,那么该任务的所有 Task 都会发生重启。而在实际生产环境中,我们的大作业可能有几百个 Task,出现一次异常如果进行整个任务重启,那么经常会导致长时间任务不能正常工作,导致数据延迟。
但是事实上,我们可能只是集群中某一个或几个 Task 发生了故障,只需要重启有问题的一部分即可,这就是 Flink 基于 Region 的局部重启策略。在这个策略下,Flink 会把我们的任务分成不同的 Region,当某一个 Task 发生故障时,Flink 会计算需要故障恢复的最小 Region。
Flink 在判断需要重启的 Region 时,采用了以下的判断逻辑:
(1) 发生错误的 Task 所在的 Region 需要重启;
(2) 如果当前 Region 的依赖数据出现损坏或者部分丢失,那么生产数据的 Region 也需要重启;
(3) 为了保证数据一致性,当前 Region 的下游 Region 也需要重启。
重启策略
Flink 提供了多种类型和级别的重启策略,常用的重启策略包括:
(1) 固定延迟重启策略模式
(2) 失败率重启策略模式
(3)无重启策略模式
Flink 在判断使用的哪种重启策略时做了默认约定,如果用户配置了 checkpoint,但没有设置重启策略,那么会按照固定延迟重启策略模式进行重启;如果用户没有配置 checkpoint,那么默认不会重启。
下面我们分别对这三种模式进行详细讲解。
(1) 无重启策略模式
在这种情况下,如果我们的作业发生错误,任务会直接退出。
我们可以在 flink-conf.yaml 中配置:restart-strategy: none
也可以在程序中使用代码指定:
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
(2) 固定延迟重启策略模式
固定延迟重启策略会通过在 flink-conf.yaml 中设置如下配置参数,来启用此策略:restart-strategy: fixed-delay
固定延迟重启策略模式需要指定两个参数,首先 Flink 会根据用户配置的重试次数进行重试,每次重试之间根据配置的时间间隔进行重试,如下表所示:
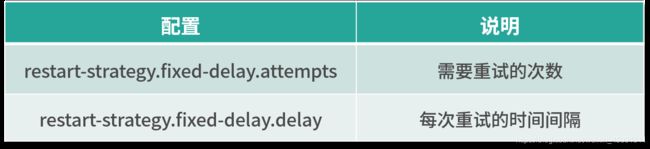
举个例子,假如我们需要任务重试 3 次,每次重试间隔 5 秒,那么需要进行一下配置:
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 5 s
当前我们也可以在代码中进行设置:
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(5, TimeUnit.SECONDS) // 时间间隔
));
(3) 失败率重启策略模式
首先我们在 flink-conf.yaml 中指定如下配置:restart-strategy: failure-rate
这种重启模式需要指定三个参数,如下表所示。失败率重启策略在 Job 失败后会重启,但是超过失败率后,Job 会最终被认定失败。在两个连续的重启尝试之间,重启策略会等待一个固定的时间。
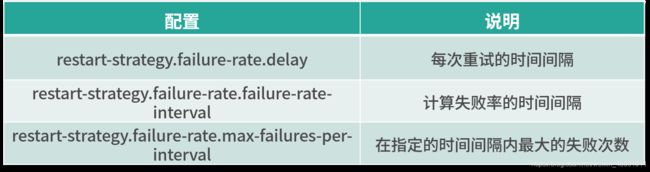
这种策略的配置理解较为困难,我们举个例子,假如 5 分钟内若失败了 3 次,则认为该任务失败,每次失败的重试间隔为 5 秒。
那么我们的配置应该是:
restart-strategy.failure-rate.max-failures-per-interval: 3 restart-strategy.failure-rate.failure-rate-interval: 5 min restart-strategy.failure-rate.delay: 5 s
当然,也可以在代码中直接指定:
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个时间间隔的最大故障次数
Time.of(5, TimeUnit.MINUTES), // 测量故障率的时间间隔
Time.of(5, TimeUnit.SECONDS) // 每次任务失败时间间隔
));
最后,需要注意的是,在实际生产环境中由于每个任务的负载和资源消耗不一样,我们推荐在代码中指定每个任务的重试机制和重启策略。
并行度
并行度是 Flink 执行任务的核心概念之一,它被定义为在分布式运行环境中我们的一个算子任务被切分成了多少个子任务并行执行。我们提高任务的并行度(Parallelism)在很大程度上可以大大提高任务运行速度。
一般情况下,我们可以通过四种级别来设置任务的并行度。
(1) 算子级别
在代码中可以调用 setParallelism 方法来设置每一个算子的并行度。例如:
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new LineSplitter())
.groupBy(0)
.sum(1).setParallelism(1);
事实上,Flink 的每个算子都可以单独设置并行度。这也是我们最推荐的一种方式,可以针对每个算子进行任务的调优。
(2) 执行环境级别
我们在创建 Flink 的上下文时可以显示的调用 env.setParallelism() 方法,来设置当前执行环境的并行度,这个配置会对当前任务的所有算子、Source、Sink 生效。当然你还可以在算子级别设置并行度来覆盖这个设置。
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(5);
(3) 提交任务级别
用户在提交任务时,可以显示的指定 -p 参数来设置任务的并行度,例如:./bin/flink run -p 10 WordCount.jar
(4) 系统配置级别
我们在上一课时中提到了 flink-conf.yaml 中的一个配置:parallelism.default,该配置即是在系统层面设置所有执行环境的并行度配置。
整体上讲,这四种级别的配置生效优先级如下:算子级别 > 执行环境级别 > 提交任务级别 > 系统配置级别。
slot
在这里,要特别提一下 Flink 中的 Slot 概念。我们知道,Flink 中的 TaskManager 是执行任务的节点,那么在每一个 TaskManager 里,还会有“槽位”,也就是 Slot。Slot 个数代表的是每一个 TaskManager 的并发执行能力。
假如我们指定 taskmanager.numberOfTaskSlots:3,即每个 taskManager 有 3 个 Slot ,那么整个集群就有 3 * taskManager 的个数多的槽位。这些槽位就是我们整个集群所拥有的所有执行任务的资源。
二、Flink窗口、时间和水印
Flink 的窗口和时间
窗口
根据窗口数据划分的不同,目前 Flink 支持如下 3 种:
- 滚动窗口,窗口数据有固定的大小,窗口中的数据不会叠加;
- 滑动窗口,窗口数据有固定的大小,并且有生成间隔;
- 会话窗口,窗口数据没有固定的大小,根据用户传入的参数进行划分,窗口数据无叠加。
时间
Flink 中的时间分为三种:
- 事件时间(Event Time),即事件实际发生的时间;
- 摄入时间(Ingestion Time),事件进入流处理框架的时间;
- 处理时间(Processing Time),事件被处理的时间。
下面的图详细说明了这三种时间的区别和联系:
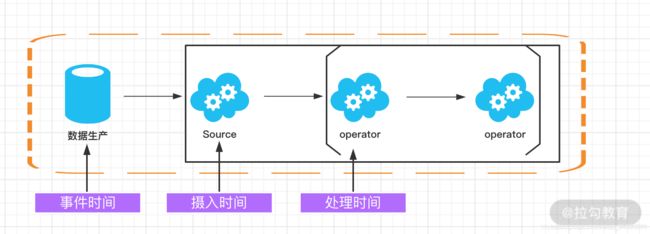
(1) 事件时间(Event Time)
事件时间(Event Time)指的是数据产生的时间,这个时间一般由数据生产方自身携带,比如 Kafka 消息,每个生成的消息中自带一个时间戳代表每条数据的产生时间。Event Time 从消息的产生就诞生了,不会改变,也是我们使用最频繁的时间。
利用 Event Time 需要指定如何生成事件时间的“水印”,并且一般和窗口配合使用,具体会在下面的“水印”内容中详细讲解。
我们可以在代码中指定 Flink 系统使用的时间类型为 EventTime:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置时间属性为 EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<MyEvent> stream = env.addSource(new FlinkKafkaConsumer09<MyEvent>(topic, schema, props));
stream
.keyBy( (event) -> event.getUser() )
.timeWindow(Time.hours(1))
.reduce( (a, b) -> a.add(b) )
.addSink(...);
Flink 注册 EventTime 是通过 InternalTimerServiceImpl.registerEventTimeTimer 来实现的:
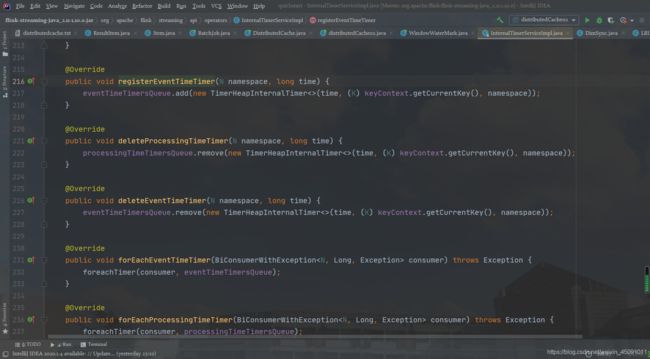
可以看到,该方法有两个入参:namespace 和 time,其中 time 是触发定时器的时间,namespace 则被构造成为一个 TimerHeapInternalTimer 对象,然后将其放入 KeyGroupedInternalPriorityQueue 队列中。
那么 Flink 什么时候会使用这些 timer 触发计算呢?答案在这个方法里:

这个方法中的 while 循环部分会从 eventTimeTimersQueue 中依次取出触发时间小于参数 time 的所有定时器,调用 triggerTarget.onEventTime() 方法进行触发。
这就是 EventTime 从注册到触发的流程。
(2) 处理时间(Processing Time)
处理时间(Processing Time)指的是数据被 Flink 框架处理时机器的系统时间,Processing Time 是 Flink 的时间系统中最简单的概念,但是这个时间存在一定的不确定性,比如消息到达处理节点延迟等影响。
我们同样可以在代码中指定 Flink 系统使用的时间为 Processing Time:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
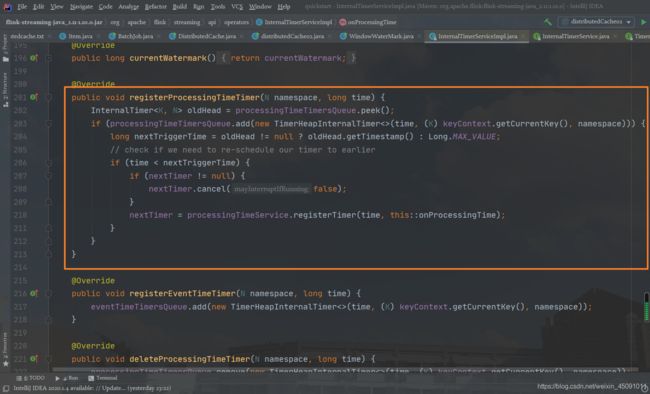
registerProcessingTimeTimer() 方法为我们展示了如何注册一个 ProcessingTime 定时器:
每当一个新的定时器被加入到 processingTimeTimersQueue 这个优先级队列中时,如果新来的 Timer 时间戳更小,那么更小的这个 Timer 会被重新注册 ScheduledThreadPoolExecutor 定时执行器上。
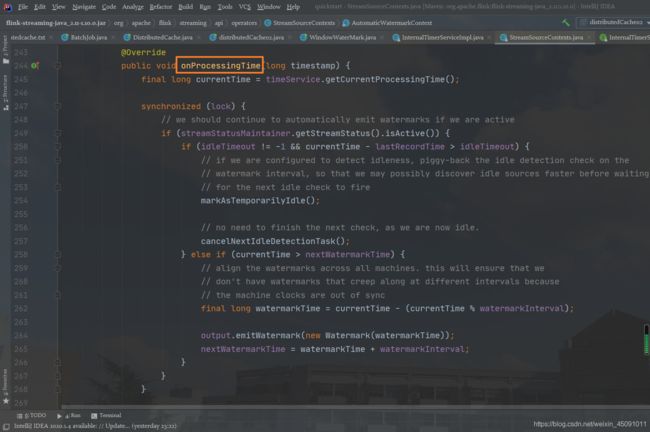
Processing Time 被触发是在 InternalTimeServiceImpl 的 onProcessingTime() 方法中:
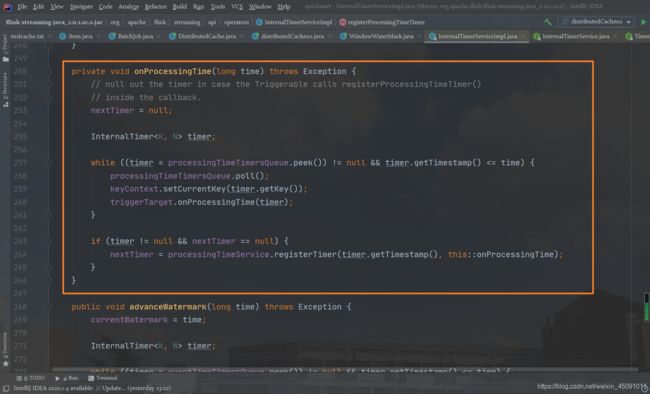
一直循环获取时间小于入参 time 的所有定时器,并运行 triggerTarget 的 onProcessingTime() 方法。
(3) 摄入时间(Ingestion Time)
摄入时间(Ingestion Time)是事件进入 Flink 系统的时间,在 Flink 的 Source 中,每个事件会把当前时间作为时间戳,后续做窗口处理都会基于这个时间。理论上 Ingestion Time 处于 Event Time 和 Processing Time之间。
与事件时间相比,摄入时间无法处理延时和无序的情况,但是不需要明确执行如何生成 watermark。在系统内部,摄入时间采用更类似于事件时间的处理方式进行处理,但是有自动生成的时间戳和自动的 watermark。
可以防止 Flink 内部处理数据是发生乱序的情况,但无法解决数据到达 Flink 之前发生的乱序问题。如果需要处理此类问题,建议使用 EventTime。
Ingestion Time 的时间类型生成相关的代码在 AutomaticWatermarkContext 中:
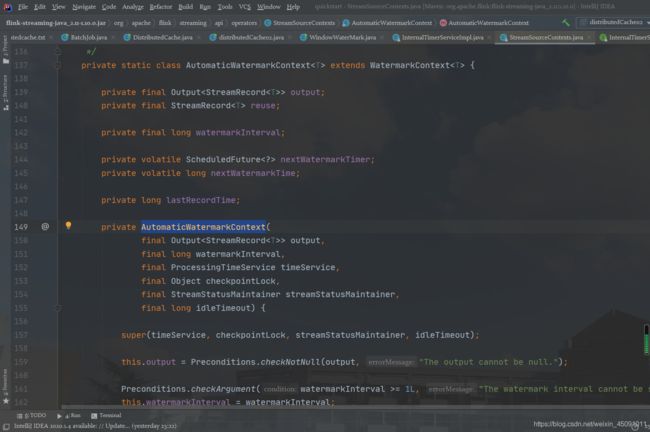
我们可以看出,这里会设置一个 watermark 发送定时器,在 watermarkInterval 时间之后触发。
处理数据的代码在 processAndCollect() 方法中:

水印(WaterMark)
水印(WaterMark)是 Flink 框架中最晦涩难懂的概念之一,有很大一部分原因是因为翻译的原因。
WaterMark 在正常的英文翻译中是水位,但是在 Flink 框架中,翻译为“水位线”更为合理,它在本质上是一个时间戳。
在上面的时间类型中我们知道,Flink 中的时间:
- EventTime 每条数据都携带时间戳;
- ProcessingTime 数据不携带任何时间戳的信息;
- IngestionTime 和 EventTime 类似,不同的是 Flink 会使用系统时间作为时间戳绑定到每条数据,可以防止 Flink 内部处理数据是发生乱序的情况,但无法解决数据到达 Flink 之前发生的乱序问题。
所以,我们在处理消息乱序的情况时,会用 EventTime 和 WaterMark 进行配合使用。
首先我们要明确几个基本问题。
水印的本质是什么
水印的出现是为了解决实时计算中的数据乱序问题,它的本质是 DataStream 中一个带有时间戳的元素。如果 Flink 系统中出现了一个 WaterMark T,那么就意味着 EventTime < T 的数据都已经到达,窗口的结束时间和 T 相同的那个窗口被触发进行计算了。
也就是说:水印是 Flink 判断迟到数据的标准,同时也是窗口触发的标记。
在程序并行度大于 1 的情况下,会有多个流产生水印和窗口,这时候 Flink 会选取时间戳最小的水印。
水印是如何生成的
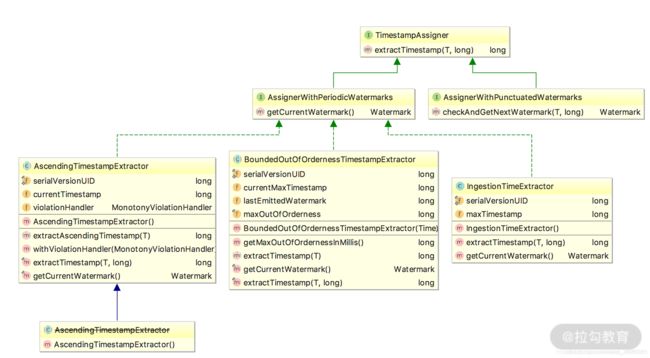
Flink 提供了 assignTimestampsAndWatermarks() 方法来实现水印的提取和指定,该方法接受的入参有 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 两种。
整体的类图如下:
水印种类
(1)周期性水印
我们在使用 AssignerWithPeriodicWatermarks 周期生成水印时,周期默认的时间是 200ms,这个时间的指定位置为:
@PublicEvolving
public void setStreamTimeCharacteristic(TimeCharacteristic characteristic) {
this.timeCharacteristic = Preconditions.checkNotNull(characteristic);
if (characteristic == TimeCharacteristic.ProcessingTime) {
getConfig().setAutoWatermarkInterval(0);
} else {
getConfig().setAutoWatermarkInterval(200);
}
}
是否还记得上面我们在讲时间类型时会通过 env.setStreamTimeCharacteristic() 方法指定 Flink 系统的时间类型,这个 setStreamTimeCharacteristic() 方法中会做判断,如果用户传入的是 TimeCharacteristic.eventTime 类型,那么 AutoWatermarkInterval 的值则为 200ms ,如上述代码所示。当前我们也可以使用 ExecutionConfig.setAutoWatermarkInterval() 方法来指定自动生成的时间间隔。
在上述的类图中可以看出,我们需要通过 TimestampAssigner 的 extractTimestamp() 方法来提取 EventTime。
Flink 在这里提供了 3 种提取 EventTime() 的方法,分别是:
- AscendingTimestampExtractor
- BoundedOutOfOrdernessTimestampExtractor
- IngestionTimeExtractor
这三种方法中 BoundedOutOfOrdernessTimestampExtractor() 用的最多,需特别注意,在这个方法中的 maxOutOfOrderness 参数,该参数指的是允许数据乱序的时间范围。简单说,这种方式允许数据迟到 maxOutOfOrderness 这么长的时间。
public BoundedOutOfOrdernessTimestampExtractor(Time maxOutOfOrderness) {
if (maxOutOfOrderness.toMilliseconds() < 0) {
throw new RuntimeException("Tried to set the maximum allowed " +
"lateness to " + maxOutOfOrderness + ". This parameter cannot be negative.");
}
this.maxOutOfOrderness = maxOutOfOrderness.toMilliseconds();
this.currentMaxTimestamp = Long.MIN_VALUE + this.maxOutOfOrderness;
}
public abstract long extractTimestamp(T element);
@Override
public final Watermark getCurrentWatermark() {
long potentialWM = currentMaxTimestamp - maxOutOfOrderness;
if (potentialWM >= lastEmittedWatermark) {
lastEmittedWatermark = potentialWM;
}
return new Watermark(lastEmittedWatermark);
}
@Override
public final long extractTimestamp(T element, long previousElementTimestamp) {
long timestamp = extractTimestamp(element);
if (timestamp > currentMaxTimestamp) {
currentMaxTimestamp = timestamp;
}
return timestamp;
}
(2)PunctuatedWatermark 水印
这种水印的生成方式 Flink 没有提供内置实现,它适用于根据接收到的消息判断是否需要产生水印的情况,用这种水印生成的方式并不多见。
举个简单的例子,假如我们发现接收到的数据 MyData 中以字符串 watermark 开头则产生一个水印:
data.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks<UserActionRecord>() {
@Override
public Watermark checkAndGetNextWatermark(MyData data, long l) {
return data.getRecord.startsWith("watermark") ? new Watermark(l) : null;
}
@Override
public long extractTimestamp(MyData data, long l) {
return data.getTimestamp();
}
});
class MyData{
private String record;
private Long timestamp;
public String getRecord() {
return record;
}
public void setRecord(String record) {
this.record = record;
}
public Timestamp getTimestamp() {
return timestamp;
}
public void setTimestamp(Timestamp timestamp) {
this.timestamp = timestamp;
}
}
案例(模拟一个实时接收 Socket 的 DataStream 程序)
我们上面讲解了 Flink 关于水印和时间的生成,以及使用,下面举一个例子来讲解。
模拟一个实时接收 Socket 的 DataStream 程序,代码中使用 AssignerWithPeriodicWatermarks 来设置水印,将接收到的数据进行转换,分组并且在一个 5 秒的窗口内获取该窗口中第二个元素最小的那条数据。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
//设置为eventtime事件类型
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置水印生成时间间隔100ms
env.getConfig().setAutoWatermarkInterval(100);
DataStream<String> dataStream = env
.socketTextStream("127.0.0.1", 9000)
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<String>() {
private Long currentTimeStamp = 0L;
//设置允许乱序时间
private Long maxOutOfOrderness = 5000L;
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentTimeStamp - maxOutOfOrderness);
}
@Override
public long extractTimestamp(String s, long l) {
String[] arr = s.split(",");
long timeStamp = Long.parseLong(arr[1]);
currentTimeStamp = Math.max(timeStamp, currentTimeStamp);
System.err.println(s + ",EventTime:" + timeStamp + ",watermark:" + (currentTimeStamp - maxOutOfOrderness));
return timeStamp;
}
});
dataStream.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String s) throws Exception {
String[] split = s.split(",");
return new Tuple2<String, Long>(split[0], Long.parseLong(split[1]));
}
})
.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.minBy(1)
.print();
env.execute("WaterMark Test Demo");
}
我们第一次试验的数据如下:
可以做一个简单的判断,第一条数据的时间戳为 1588659181000,窗口的大小为 5 秒,那么应该会在 flink,1588659185000 这条数据出现时触发窗口的计算。
我们用 nc -lk 9000 命令启动端口,然后输出上述试验数据,看到控制台的输出:
很明显,可以看到当第五条数据出现后,窗口触发了计算。
下面再模拟一下数据乱序的情况,假设我们的数据来源如下:
其中的 flink,1588659180000 为乱序消息,来看看会发生什么?
可以看到,时间戳为 1588659180000 的这条消息并没有被处理,因为此时代码中的允许乱序时间 private Long maxOutOfOrderness = 0L 即不处理乱序消息。
下面修改 private Long maxOutOfOrderness = 5000L,即代表允许消息的乱序时间为 5 秒,然后把同样的数据发往 socket 端口。
可以看到,我们把所有数据发送出去仅触发了一次窗口计算,并且输出的结果中 watermark 的时间往后顺延了 5 秒钟。所以,maxOutOfOrderness 的设置会影响窗口的计算时间和水印的时间,如下图所示:
假如我们继续向 socket 中发送数据:
在这里要特别说明,Flink 在用时间 + 窗口 + 水印来解决实际生产中的数据乱序问题,有如下的触发条件:
watermark 时间 >= window_end_time;
在 [window_start_time,window_end_time) 中有数据存在,这个窗口是左闭右开的。
此外,因为 WaterMark 的生成是以对象的形式发送到下游,同样会消耗内存,因此水印的生成时间和频率都要进行严格控制,否则会影响我们的正常作业。
三、Flink 状态与容错
状态
所谓的状态,其实指的是 Flink 程序的中间计算结果。
Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。
状态
我们在 Flink 的官方博客中找到这样一段话,可以认为这是对状态的定义:
When working with state, it might also be useful to read about Flink’s
state backends. Flink provides different state backends that specify
how and where state is stored. State can be located on Java’s heap or
off-heap. Depending on your state backend, Flink can also manage the
state for the application, meaning Flink deals with the memory
management (possibly spilling to disk if necessary) to allow
applications to hold very large state. State backends can be
configured without changing your application logic.
这段话告诉我们,所谓的状态指的是,在流处理过程中那些需要记住的数据,而这些数据既可以包括业务数据,也可以包括元数据。Flink 本身提供了不同的状态管理器来管理状态,并且这个状态可以非常大。
Flink 的状态数据可以存在 JVM 的堆内存或者堆外内存中,当然也可以借助第三方存储,例如 Flink 已经实现的对 RocksDB 支持。Flink 的官网同样给出了适用于状态计算的几种情况:
When an application searches for certain event patterns, the state
will store the sequence of events encountered so far When aggregating
events per minute/hour/day, the state holds the pending aggregates
When training a machine learning model over a stream of data points,
the state holds the current version of the model parameters When
historic data needs to be managed, the state allows efficient access
to events that occurred in the past
以上四种情况分别是:复杂事件处理获取符合某一特定时间规则的事件、聚合计算、机器学习的模型训练、使用历史的数据进行计算。
Flink 状态分类和使用
我们在之前的课时中提到过 KeyedStream 的概念,并且介绍过 KeyBy 这个算子的使用。在 Flink 中,根据数据集是否按照某一个 Key 进行分区,将状态分为 Keyed State 和 Operator State(Non-Keyed State)两种类型。

如上图所示,Keyed State 是经过分区后的流上状态,每个 Key 都有自己的状态,图中的八边形、圆形和三角形分别管理各自的状态,并且只有指定的 key 才能访问和更新自己对应的状态。
与 Keyed State 不同的是,Operator State 可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。每个算子子任务上的数据共享自己的状态。
但是有一点需要说明的是,无论是 Keyed State 还是 Operator State,Flink 的状态都是基于本地的,即每个算子子任务维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。
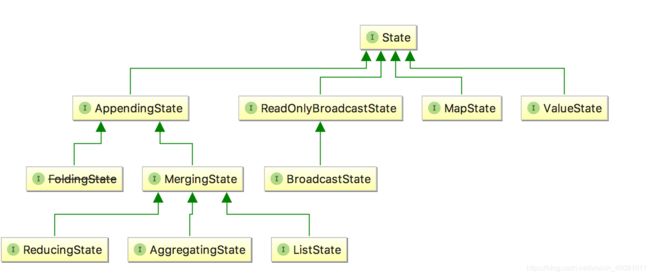
我们可以看一下 State 的类图,对于 Keyed State,Flink 提供了几种现成的数据结构供我们使用,State 主要有四种实现,分别为 ValueState、MapState、AppendingState 和 ReadOnlyBrodcastState ,其中 AppendingState 又可以细分为 ReducingState、AggregatingState 和 ListState。
那么我们怎么访问这些状态呢?Flink 提供了 StateDesciptor 方法专门用来访问不同的 state,类图如下: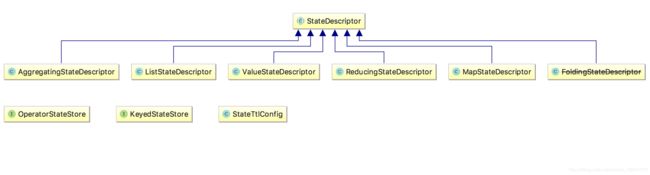
状态示例
下面演示一下如何使用 StateDesciptor 和 ValueState,代码如下:
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 5L), Tuple2.of(1L, 2L))
.keyBy(0)
.flatMap(new CountWindowAverage())
.printToErr();
env.execute("submit job");
}
public static class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
private transient ValueState<Tuple2<Long, Long>> sum;
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
Tuple2<Long, Long> currentSum;
// 访问ValueState
if(sum.value()==null){
currentSum = Tuple2.of(0L, 0L);
}else {
currentSum = sum.value();
}
// 更新
currentSum.f0 += 1;
// 第二个元素加1
currentSum.f1 += input.f1;
// 更新state
sum.update(currentSum);
// 如果count的值大于等于2,求知道并清空state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // state的名字
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {})
); // 设置默认值
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
descriptor.enableTimeToLive(ttlConfig);
sum = getRuntimeContext().getState(descriptor);
}
}
在上述例子中,我们通过继承 RichFlatMapFunction 来访问 State,通过 getRuntimeContext().getState(descriptor) 来获取状态的句柄。而真正的访问和更新状态则在 Map 函数中实现。
我们这里的输出条件为,每当第一个元素的和达到二,就把第二个元素的和与第一个元素的和相除,最后输出。我们直接运行,在控制台可以看到结果:
Operator State 的实际应用场景不如 Keyed State 多,一般来说它会被用在 Source 或 Sink 等算子上,用来保存流入数据的偏移量或对输出数据做缓存,以保证 Flink 应用的 Exactly-Once 语义。
同样,我们对于任何状态数据还可以设置它们的过期时间。如果一个状态设置了 TTL,并且已经过期,那么我们之前保存的值就会被清理。
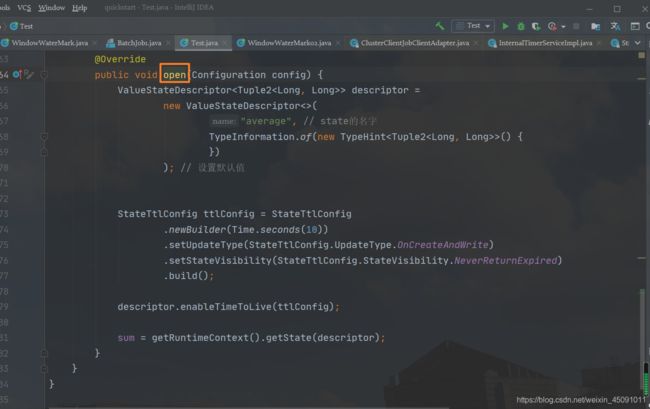
想要使用 TTL,我们需要首先构建一个 StateTtlConfig 配置对象;然后,可以通过传递配置在任何状态描述符中启用 TTL 功能。
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
descriptor.enableTimeToLive(ttlConfig);
StateTtlConfig 这个类中有一些配置需要我们注意:
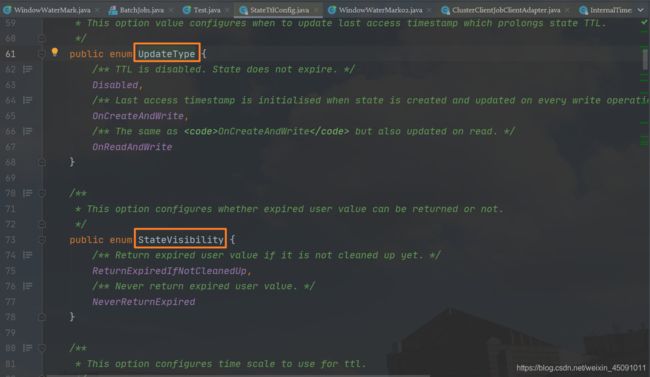
UpdateType 表明了过期时间什么时候更新,而对于那些过期的状态,是否还能被访问则取决于 StateVisibility 的配置。
状态后端种类和配置
我们在上面的内容中讲到了 Flink 的状态数据可以存在 JVM 的堆内存或者堆外内存中,当然也可以借助第三方存储。默认情况下,Flink 的状态会保存在 taskmanager 的内存中,Flink 提供了三种可用的状态后端用于在不同情况下进行状态后端的保存。
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
(1)MemoryStateBackend
顾名思义,MemoryStateBackend 将 state 数据存储在内存中,一般用来进行本地调用,我们在使用 MemoryStateBackend 时需要注意的一些点包括:
每个独立的状态(state)默认限制大小为 5MB,可以通过构造函数增加容量 状态的大小不能超过 akka 的 Framesize 大小
聚合后的状态必须能够放进 JobManager 的内存中
MemoryStateBackend 可以通过在代码中显示指定:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new MemoryStateBackend(DEFAULT_MAX_STATE_SIZE,false));
其中,new MemoryStateBackend(DEFAULT_MAX_STATE_SIZE,false) 中的 false 代表关闭异步快照机制。关于快照,我们在后面的课时中有单独介绍。
很明显 MemoryStateBackend 适用于本地调试使用,来记录一些状态很小的 Job 状态信息。
(2)FsStateBackend
FsStateBackend 会把状态数据保存在 TaskManager 的内存中。CheckPoint 时,将状态快照写入到配置的文件系统目录中,少量的元数据信息存储到 JobManager 的内存中。
使用 FsStateBackend 需要我们指定一个文件路径,一般来说是 HDFS 的路径,例如,hdfs://namenode:40010/flink/checkpoints。
我们同样可以在代码中显示指定:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints", false));
FsStateBackend 因为将状态存储在了外部系统如 HDFS 中,所以它适用于大作业、状态较大、全局高可用的那些任务。
(3)RocksDBStateBackend
RocksDBStateBackend 和 FsStateBackend 有一些类似,首先它们都需要一个外部文件存储路径,比如 HDFS 的 hdfs://namenode:40010/flink/checkpoints,此外也适用于大作业、状态较大、全局高可用的那些任务。
但是与 FsStateBackend 不同的是,RocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 运行节点的数据目录下。
这意味着,RocksDBStateBackend 可以存储远超过 FsStateBackend 的状态,可以避免向 FsStateBackend 那样一旦出现状态暴增会导致 OOM,但是因为将状态数据保存在 RocksDB 数据库中,吞吐量会有所下降。
此外,需要注意的是,RocksDBStateBackend 是唯一支持增量快照的状态后端。
总结
我们在这一课时中讲解了 Flink 中的状态分类和使用,并且用实际案例演示了用法;此外介绍了 Flink 状态的保存方式和优缺点。
四、Flink Side OutPut 分流
介绍 Flink 中提供的一个很重要的功能:旁路分流器。
分流场景
我们在生产实践中经常会遇到这样的场景,需把输入源按照需要进行拆分,比如我期望把订单流按照金额大小进行拆分,或者把用户访问日志按照访问者的地理位置进行拆分等。面对这样的需求该如何操作呢?
分流的方法
通常来说针对不同的场景,有以下三种办法进行流的拆分。
(1)Filter 分流
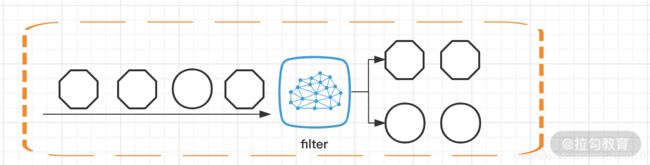
Filter 方法我们(Flink 常用的 DataSet 和 DataStream API)讲过,这个算子用来根据用户输入的条件进行过滤,每个元素都会被 filter() 函数处理,如果 filter() 函数返回 true 则保留,否则丢弃。那么用在分流的场景,我们可以做多次 filter,把我们需要的不同数据生成不同的流。
来看下面的例子:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> zeroStream = items.filter((FilterFunction<Tuple3<Integer, Integer, Integer>>) value -> value.f0 == 0);
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> oneStream = items.filter((FilterFunction<Tuple3<Integer, Integer, Integer>>) value -> value.f0 == 1);
zeroStream.print();
oneStream.printToErr();
//打印结果
String jobName = "user defined streaming source";
env.execute(jobName);
}
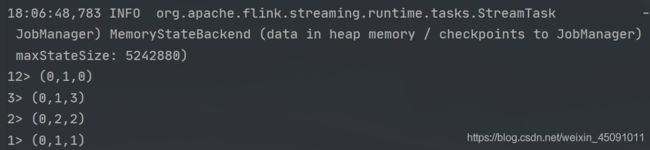
在上面的例子中我们使用 filter 算子将原始流进行了拆分,输入数据第一个元素为 0 的数据和第一个元素为 1 的数据分别被写入到了 zeroStream 和 oneStream 中,然后把两个流进行了打印。


可以看到 zeroStream 和 oneStream 分别被打印出来。
Filter 的弊端是显而易见的,为了得到我们需要的流数据,需要多次遍历原始流,这样无形中浪费了我们集群的资源。
(2)Split 分流
Split 也是 Flink 提供给我们将流进行切分的方法,需要在 split 算子中定义 OutputSelector,然后重写其中的 select 方法,将不同类型的数据进行标记,最后对返回的 SplitStream 使用 select 方法将对应的数据选择出来。
我们来看下面的例子:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
SplitStream<Tuple3<Integer, Integer, Integer>> splitStream = items.split(new OutputSelector<Tuple3<Integer, Integer, Integer>>() {
@Override
public Iterable<String> select(Tuple3<Integer, Integer, Integer> value) {
List<String> tags = new ArrayList<>();
if (value.f0 == 0) {
tags.add("zeroStream");
} else if (value.f0 == 1) {
tags.add("oneStream");
}
return tags;
}
});
splitStream.select("zeroStream").print();
splitStream.select("oneStream").printToErr();
//打印结果
String jobName = "user defined streaming source";
env.execute(jobName);
}
同样,我们把来源的数据使用 split 算子进行了切分,并且打印出结果。

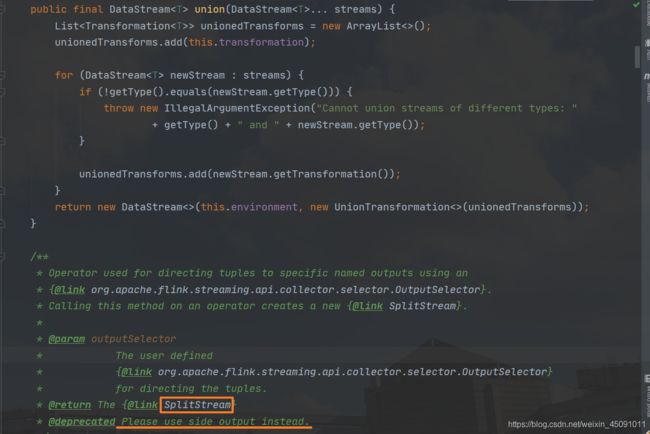
但是要注意,使用 split 算子切分过的流,是不能进行二次切分的,假如把上述切分出来的 zeroStream 和 oneStream 流再次调用 split 切分,控制台会抛出以下异常。
Exception in thread "main" java.lang.IllegalStateException: Consecutive multiple splits are not supported. Splits are deprecated. Please use side-outputs.
这是什么原因呢?我们在源码中可以看到注释,该方式已经废弃并且建议使用最新的 SideOutPut 进行分流操作。
(3)SideOutPut 分流
SideOutPut 是 Flink 框架为我们提供的最新的也是最为推荐的分流方法,在使用 SideOutPut 时,需要按照以下步骤进行:
- 定义 OutputTag
- 调用特定函数进行数据拆分
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
在这里我们使用 ProcessFunction 来讲解如何使用 SideOutPut:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
OutputTag<Tuple3<Integer,Integer,Integer>> zeroStream = new OutputTag<Tuple3<Integer,Integer,Integer>>("zeroStream") {};
OutputTag<Tuple3<Integer,Integer,Integer>> oneStream = new OutputTag<Tuple3<Integer,Integer,Integer>>("oneStream") {};
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> processStream= items.process(new ProcessFunction<Tuple3<Integer, Integer, Integer>, Tuple3<Integer, Integer, Integer>>() {
@Override
public void processElement(Tuple3<Integer, Integer, Integer> value, Context ctx, Collector<Tuple3<Integer, Integer, Integer>> out) throws Exception {
if (value.f0 == 0) {
ctx.output(zeroStream, value);
} else if (value.f0 == 1) {
ctx.output(oneStream, value);
}
}
});
DataStream<Tuple3<Integer, Integer, Integer>> zeroSideOutput = processStream.getSideOutput(zeroStream);
DataStream<Tuple3<Integer, Integer, Integer>> oneSideOutput = processStream.getSideOutput(oneStream);
zeroSideOutput.print();
oneSideOutput.printToErr();
//打印结果
String jobName = "user defined streaming source";
env.execute(jobName);
}
可以看到,我们将流进行了拆分,并且成功打印出了结果。这里要注意,Flink 最新提供的 SideOutPut 方式拆分流是可以多次进行拆分的,无需担心会爆出异常。
总结
这一课时我们讲解了 Flink 的一个小的知识点,是我们生产实践中经常遇到的场景,Flink 在最新的版本中也推荐我们使用 SideOutPut 进行流的拆分。
五、Flink CEP 复杂事件处理
介绍 Flink 中提供的一个很重要的功能:复杂事件处理 CEP
背景
Complex Event Processing(CEP)是 Flink 提供的一个非常亮眼的功能,关于 CEP 的解释我们引用维基百科中的一段话:
CEP, is event processing that combines data from multiple sources to
infer events or patterns that suggest more complicated circumstances.
The goal of complex event processing is to identify meaningful events
(such as opportunities or threats) and respond to them as quickly as
possible.
在我们的实际生产中,随着数据的实时性要求越来越高,实时数据的量也在不断膨胀,在某些业务场景中需要根据连续的实时数据,发现其中有价值的那些事件。
说到底,Flink 的 CEP 到底解决了什么样的问题呢?
比如,我们需要在大量的订单交易中发现那些虚假交易,在网站的访问日志中寻找那些使用脚本或者工具**“爆破”登录的用户,或者在快递运输中发现那些滞留很久没有签收的包裹**等。
如果你对 CEP 的理论基础非常感兴趣,推荐一篇论文“Efficient Pattern Matching over Event Streams”。
Flink 对 CEP 的支持非常友好,并且支持复杂度非常高的模式匹配,其吞吐和延迟都令人满意。
程序结构
Flink CEP 的程序结构主要分为两个步骤:
- 定义模式
- 匹配结果
我们在官网中可以找到一个 Flink 提供的案例:
DataStream<Event> input = ...
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
return event.getId() == 42;
}
}
).next("middle").subtype(SubEvent.class).where(
new SimpleCondition<SubEvent>() {
@Override
public boolean filter(SubEvent subEvent) {
return subEvent.getVolume() >= 10.0;
}
}
).followedBy("end").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
return event.getName().equals("end");
}
}
);
PatternStream<Event> patternStream = CEP.pattern(input, pattern);
DataStream<Alert> result = patternStream.process(
new PatternProcessFunction<Event, Alert>() {
@Override
public void processMatch(
Map<String, List<Event>> pattern,
Context ctx,
Collector<Alert> out) throws Exception {
out.collect(createAlertFrom(pattern));
}
});
在这个案例中可以看到程序结构分别是:
- 第一步,定义一个模式 Pattern,在这里定义了一个这样的模式,即在所有接收到的事件中匹配那些以 id 等于 42 的事件,然后匹配 volume 大于 10.0 的事件,继续匹配一个 name 等于 end 的事件;
- 第二步,匹配模式并且发出报警,根据定义的 pattern 在输入流上进行匹配,一旦命中我们的模式,就发出一个报警。
模式定义
Flink 支持了非常丰富的模式定义,这些模式也是我们实现复杂业务逻辑的基础。我们把支持的模式简单做了以下分类,完整的模式定义 API 支持可以参考官网资料。
(1)简单模式

(2)联合模式

(3)匹配后的忽略模式

源码解析
我们在上面的官网案例中可以发现,Flink CEP 的整个过程是:
- 从一个 Source 作为输入
- 经过一个 Pattern 算子转换为** PatternStream**
- 经过 select/process 算子转换为 DataStream
我们来看一下 select 和 process 算子都做了什么?
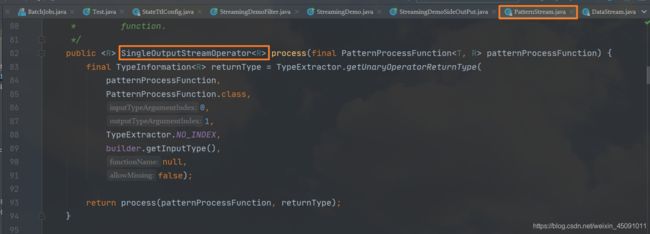
可以看到最终的逻辑都是在 PatternStream 这个类中进行的。
public <R> SingleOutputStreamOperator<R> process(final PatternProcessFunction<T, R> patternProcessFunction) {
final TypeInformation<R> returnType = TypeExtractor.getUnaryOperatorReturnType(
patternProcessFunction,
PatternProcessFunction.class,
0,
1,
TypeExtractor.NO_INDEX,
builder.getInputType(),
null,
false);
return process(patternProcessFunction, returnType);
}
最终经过 PatternStreamBuilder 的 build 方法生成了一个 SingleOutputStreamOperator,这个类继承了 DataStream。

最终的处理计算逻辑其实都封装在了 CepOperator 这个类中,而在 CepOperator 这个类中的 processElement 方法则是对每一条数据的处理逻辑。
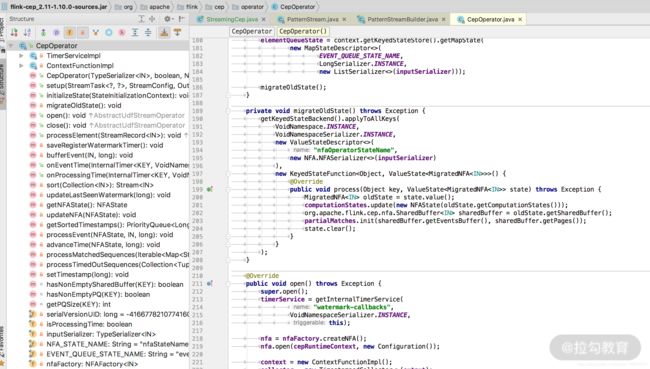
同时由于 CepOperator 实现了 Triggerable 接口,所以会执行定时器。所有核心的处理逻辑都在 updateNFA 这个方法中。
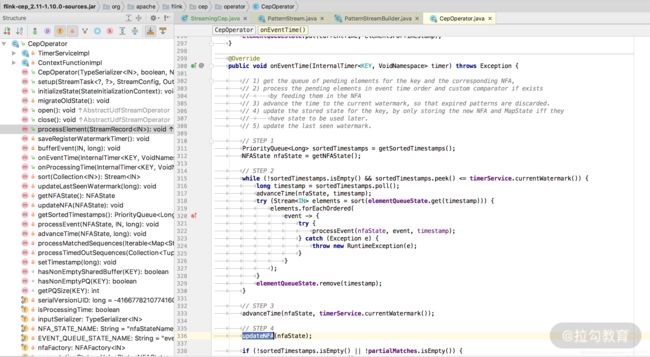
入口在这里:
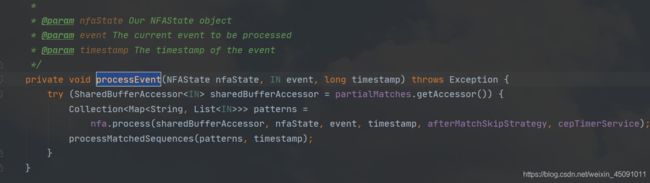
NFA 的全称为 非确定有限自动机,NFA 中包含了模式匹配中的各个状态和状态间的转换。
在 NFA 这个类中的核心方法是:process 和 advanceTime,这两个方法的实现有些复杂,总体来说可以归纳为,每当一条新来的数据进入状态机都会驱动整个状态机进行状态转换。
实战案例
我们模拟电商网站用户搜索的数据来作为数据的输入源,然后查找其中重复搜索某一个商品的人,并且发送一条告警消息。
代码如下:
public static void main(String[] args) throws Exception{
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource source = env.fromElements(
//浏览记录
Tuple3.of("Marry", "外套", 1L),
Tuple3.of("Marry", "帽子",1L),
Tuple3.of("Marry", "帽子",2L),
Tuple3.of("Marry", "帽子",3L),
Tuple3.of("Ming", "衣服",1L),
Tuple3.of("Marry", "鞋子",1L),
Tuple3.of("Marry", "鞋子",2L),
Tuple3.of("LiLei", "帽子",1L),
Tuple3.of("LiLei", "帽子",2L),
Tuple3.of("LiLei", "帽子",3L)
);
//定义Pattern,寻找连续搜索帽子的用户
Pattern<Tuple3<String, String, Long>, Tuple3<String, String, Long>> pattern = Pattern
.<String, String, Long>>begin("start")
.where(new SimpleCondition<Tuple3<String, String, Long>>() {
@Override
public boolean filter(Tuple3<String, String, Long> value) throws Exception {
return value.f1.equals("帽子");
}
}) //.timesOrMore(3);
.next("middle")
.where(new SimpleCondition<Tuple3<String, String, Long>>() {
@Override
public boolean filter(Tuple3<String, String, Long> value) throws Exception {
return value.f1.equals("帽子");
}
});
KeyedStream keyedStream = source.keyBy(0);
PatternStream patternStream = CEP.pattern(keyedStream, pattern);
SingleOutputStreamOperator matchStream = patternStream.select(new PatternSelectFunction<Tuple3<String, String, Long>, String>() {
@Override
public String select(Map<String, List<Tuple3<String, String, Long>>> pattern) throws Exception {
List<Tuple3<String, String, Long>> middle = pattern.get("middle");
return middle.get(0).f0 + ":" + middle.get(0).f2 + ":" + "连续搜索两次帽子!";
}
});
matchStream.printToErr();
env.execute("execute cep");
}
上述代码的逻辑我们可以分解如下。
首先定义一个数据源,模拟了一些用户的搜索数据,然后定义了自己的 Pattern。这个模式的特点就是连续两次搜索商品“帽子”,然后进行匹配,发现匹配后输出一条提示信息,直接打印在控制台上。
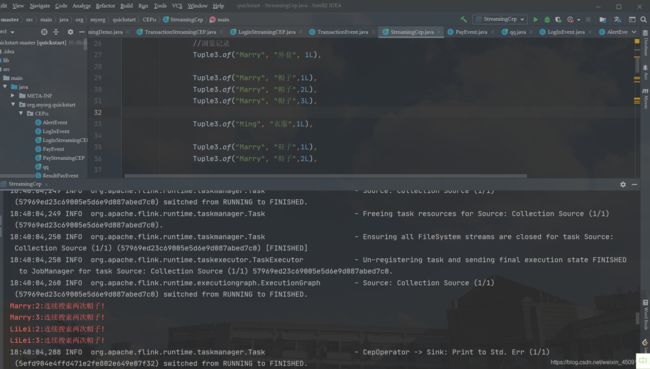
可以看到,提示信息已经打印在了控制台上。
六、Flink常用的Source和Connector
Flink 作为实时计算领域强大的计算能力,以及与其他系统进行对接的能力都非常强大。Flink 自身实现了多种 Source 和 Connector 方法,并且还提供了多种与第三方系统进行对接的 Connector。
我们可以把这些 Source、Connector 分成以下几个大类。
预定义和自定义 Source
在前面的“Flink 常用的 DataSet 和 DataStream API”中提到过几种 Flink 已经实现的新建 DataStream 方法。
(1)基于文件
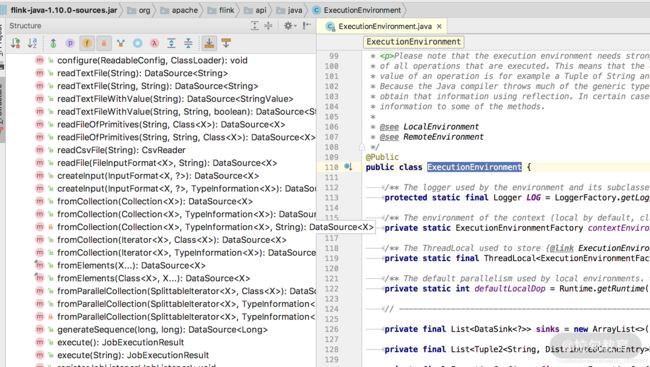
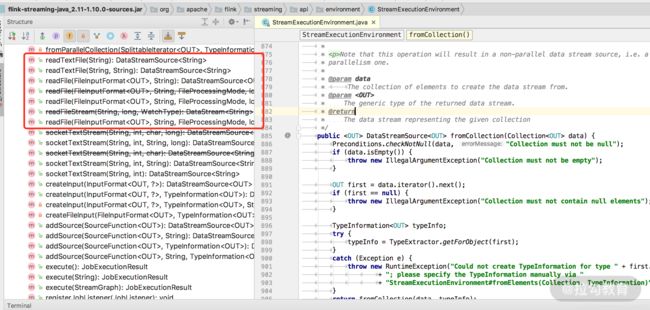
我们在本地环境进行测试时可以方便地从本地文件读取数据:
readTextFile(path)
readFile(fileInputFormat, path)
...
可以直接在 ExecutionEnvironment 和 StreamExecutionEnvironment 类中找到 Flink 支持的读取本地文件的方法,如下图所示:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// read text file from local files system
DataSet<String> localLines = env.readTextFile("file:///path/to/my/textfile");
// read text file from an HDFS running at nnHost:nnPort
DataSet<String> hdfsLines = env.readTextFile("hdfs://nnHost:nnPort/path/to/my/textfile");
// read a CSV file with three fields
DataSet<Tuple3<Integer, String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.types(Integer.class, String.class, Double.class);
// read a CSV file with five fields, taking only two of them
DataSet<Tuple2<String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.includeFields("10010") // take the first and the fourth field
.types(String.class, Double.class);
// read a CSV file with three fields into a POJO (Person.class) with corresponding fields
DataSet<Person>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.pojoType(Person.class, "name", "age", "zipcode");
(2)基于 Collections
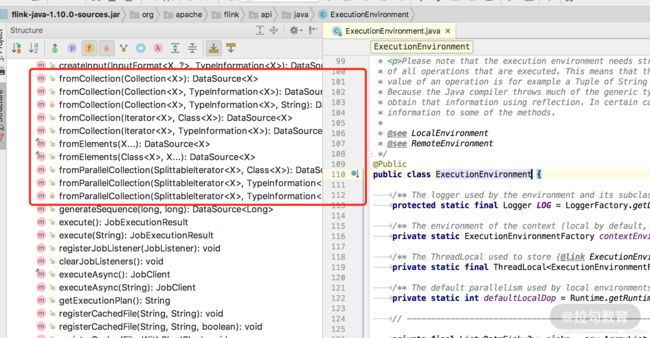
我们也可以基于内存中的集合、对象等创建自己的 Source。一般用来进行本地调试或者验证。
例如:
fromCollection(Collection)
fromElements(T ...)
我们也可以在源码中看到 Flink 支持的方法,如下图所示:
DataSet<String> text = env.fromElements(
"Flink Spark Storm",
"Flink Flink Flink",
"Spark Spark Spark",
"Storm Storm Storm"
);
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
(3)基于 Socket-模拟一个实时计算环境
通过监听 Socket 端口,我们可以在本地很方便地模拟一个实时计算环境。
StreamExecutionEnvironment 中提供了 socketTextStream 方法可以通过 host 和 port 从一个 Socket 中以文本的方式读取数据。
DataStream<String> text = env.socketTextStream("127.0.0.1", 9000, "\n");
(4)自定义 Source
我们可以通过实现 Flink 的SourceFunction 或者 ParallelSourceFunction 来实现单个或者多个并行度的 Source。
例如,我们在之前的课程中用到的:
public class MyStreamingSource implements SourceFunction<Item> {
private boolean isRunning = true;
/**
* 重写run方法产生一个源源不断的数据发送源
* @param ctx
* @throws Exception
*/
public void run(SourceContext<Item> ctx) throws Exception {
while(isRunning){
Item item = generateItem();
ctx.collect(item);
//每秒产生一条数据
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
}
//随机产生一条商品数据
private Item generateItem(){
int i = new Random().nextInt(100);
ArrayList<String> list = new ArrayList();
list.add("HAT");
list.add("TIE");
list.add("SHOE");
Item item = new Item();
item.setName(list.get(new Random().nextInt(3)));
item.setId(i);
return item;
}
}
(5)自带连接器
Flink 中支持了比较丰富的用来连接第三方的连接器,可以在官网中找到 Flink 支持的各种各样的连接器:
- Apache Kafka (source/sink)
- Apache Cassandra (sink)
- Amazon Kinesis Streams (source/sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache NiFi (source/sink)
- Twitter Streaming API (source)
- Google PubSub (source/sink)
需注意,我们在使用这些连接器时通常需要引用相对应的 Jar 包依赖。而且一定要注意,对于某些连接器比如 Kafka 是有版本要求的,一定要去官方网站找到对应的依赖版本。
(6)基于 Apache Bahir 发布
Flink 还会基于 Apache Bahir 来发布一些 Connector,比如我们常用的 Redis 等。
Apache Bahir 的代码最初是从 Apache Spark 项目中提取的,后作为一个独立的项目提供。Apache Bahir
通过提供多样化的流连接器(Streaming Connectors)和 SQL 数据源扩展分析平台的覆盖面,最初只是为 Apache
Spark 提供拓展。目前也为 Apache Flink 提供,后续还可能为 Apache Beam 和更多平台提供拓展服务。
我们可以在 Bahir 的首页中找到目前支持的 Flink 连接器:
- Flink streaming connector for ActiveMQ
- Flink streaming connector for Akka
- Flink streaming connector for Flume
- Flink streaming connector for InfluxDB
- Flink streaming connector for Kudu
- Flink streaming connector for Redis
- Flink streaming connector for Netty
其中就有我们非常熟悉的 Redis,很多同学 Flink 项目中访问 Redis 的方法都是自己进行的实现,推荐使用 Bahir 连接器。
在本地单机情况下:
public static class RedisExampleMapper implements RedisMapper<Tuple2<String, String>>{
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "HASH_NAME");
}
@Override
public String getKeyFromData(Tuple2<String, String> data) {
return data.f0;
}
@Override
public String getValueFromData(Tuple2<String, String> data) {
return data.f1;
}
}
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("127.0.0.1").build();
DataStream<String> stream = ...;
stream.addSink(new RedisSink<Tuple2<String, String>>(conf, new RedisExampleMapper());
当然我们也可以使用在集群或者哨兵模式下使用 Redis 连接器。
集群模式:
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder()
.setNodes(new HashSet<InetSocketAddress>(Arrays.asList(new InetSocketAddress(5601)))).build();
DataStream<String> stream = ...;
stream.addSink(new RedisSink<Tuple2<String, String>>(conf, new RedisExampleMapper());
哨兵模式:
FlinkJedisSentinelConfig conf = new FlinkJedisSentinelConfig.Builder()
.setMasterName("master").setSentinels(...).build();
DataStream<String> stream = ...;
stream.addSink(new RedisSink<Tuple2<String, String>>(conf, new RedisExampleMapper());
(7)基于异步 I/O 和可查询状态
异步 I/O 和可查询状态都是 Flink 提供的非常底层的与外部系统交互的方式。
其中异步 I/O 是为了解决 Flink 在实时计算中访问外部存储产生的延迟问题,如果我们按照传统的方式使用 MapFunction,那么所有对外部系统的访问都是同步进行的。在很多情况下,计算性能受制于外部系统的响应速度,长时间进行等待,会导致整体吞吐低下。
我们可以通过继承 RichAsyncFunction 来使用异步 I/O:
/**
* 实现 'AsyncFunction' 用于发送请求和设置回调
*/
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
/** 能够利用回调函数并发发送请求的数据库客户端 */
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// 发送异步请求,接收 future 结果
final Future<String> result = client.query(key);
// 设置客户端完成请求后要执行的回调函数
// 回调函数只是简单地把结果发给 future
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// 显示地处理异常
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// 创建初始 DataStream
DataStream<String> stream = ...;
// 应用异步 I/O 转换操作
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
其中,ResultFuture 的 complete 方法是异步的,不需要等待返回。
我们在之前讲解 Flink State 时,提到过 Flink 提供了 StateDesciptor 方法专门用来访问不同的 state,StateDesciptor 同时还可以通过 setQueryable 使状态变成可以查询状态。可查询状态目前是一个 Beta 功能,暂时不推荐使用。