笔记摘抄
语料链接:https://pan.baidu.com/s/1YxGGYmeByuAlRdAVov_ZLg
提取码:tzao
neg.txt和pos.txt各5000条酒店评论,每条评论一行。
1. 导包和设定超参数
import numpy as np
import random
import torch
import matplotlib.pylab as plt
from torch.nn.utils import clip_grad_norm_
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from transformers import BertTokenizer, BertForSequenceClassification, AdamW
from transformers import get_linear_schedule_with_warmup
SEED = 123
BATCH_SIZE = 16
learning_rate = 2e-5
weight_decay = 1e-2
epsilon = 1e-8
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
2. 数据预处理
2.1 读取文件
def readFile(filename):
with open(filename, encoding='utf-8') as f:
content = f.readlines()
return content
pos_text, neg_text = readFile('./hotel/pos.txt'), readFile('./hotel/neg.txt')
sentences = pos_text + neg_text
# 设定标签
pos_targets = np.ones([len(pos_text)]) # (5000, )
neg_targets = np.zeros([len(neg_text)]) # (5000, )
targets = np.concatenate((pos_targets, neg_targets), axis=0).reshape(-1, 1) # (10000, 1)
total_targets = torch.tensor(targets)
2.2 BertTokenizer进行编码,将每一句转成数字
model_name = 'bert-base-chinese'
cache_dir = './sample_data/'
tokenizer = BertTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
print(pos_text[2])
print(tokenizer.tokenize(pos_text[2]))
print(tokenizer.encode(pos_text[2]))
print(tokenizer.convert_ids_to_tokens(tokenizer.encode(pos_text[2])))
不错,下次还考虑入住。交通也方便,在餐厅吃的也不错。
['不', '错', ',', '下', '次', '还', '考', '虑', '入', '住', '。', '交', '通', '也', '方', '便', ',', '在', '餐', '厅', '吃', '的', '也', '不', '错', '。']
[101, 679, 7231, 8024, 678, 3613, 6820, 5440, 5991, 1057, 857, 511, 769, 6858, 738, 3175, 912, 8024, 1762, 7623, 1324, 1391, 4638, 738, 679, 7231, 511, 102]
['[CLS]', '不', '错', ',', '下', '次', '还', '考', '虑', '入', '住', '。', '交', '通', '也', '方', '便', ',', '在', '餐', '厅', '吃', '的', '也', '不', '错', '。', '[SEP]']
为了使每一句的长度相等,稍作处理;
# 将每一句转成数字 (大于126做截断,小于126做 Padding,加上首位两个标识,长度总共等于128)
def convert_text_to_token(tokenizer, sentence, limit_size = 126):
tokens = tokenizer.encode(sentence[:limit_size]) # 直接截断
if len(tokens) < limit_size + 2: # 补齐(pad的索引号就是0)
tokens.extend([0] * (limit_size + 2 - len(tokens)))
return tokens
input_ids = [convert_text_to_token(tokenizer, sen) for sen in sentences]
input_tokens = torch.tensor(input_ids)
print(input_tokens.shape) # torch.Size([10000, 128])
2.3 attention_masks, 在一个文本中,如果是PAD符号则是0,否则就是1
# 建立mask
def attention_masks(input_ids):
atten_masks = []
for seq in input_ids: # [10000, 128]
seq_mask = [float(i > 0) for i in seq] # PAD: 0; 否则: 1
atten_masks.append(seq_mask)
return atten_masks
atten_masks = attention_masks(input_ids)
attention_tokens = torch.tensor(atten_masks)
print(attention_tokens.shape) # torch.Size([10000, 128])
构造input_ids 和 atten_masks 的目的 和 前面一节中提到的
.encode_plus函数返回的 input_ids 和 attention_mask 一样input_type_ids 和 本次任务无关,它是针对每个训练集有两个句子的任务(如问答任务)。
2.4 划分训练集和测试集
- 两个划分函数的参数 random_state 和 test_size 值要一致,才能使得 train_inputs 和 train_masks一一对应。
from sklearn.model_selection import train_test_split
train_inputs, test_inputs, train_labels, test_labels = train_test_split(input_tokens, total_targets,
random_state=666, test_size=0.2)
train_masks, test_masks, _, _ = train_test_split(attention_tokens, input_tokens,
random_state=666, test_size=0.2)
print(train_inputs.shape, test_inputs.shape) # torch.Size([8000, 128]) torch.Size([2000, 128])
print(train_masks.shape) # torch.Size([8000, 128])和train_inputs形状一样
print(train_inputs[0])
print(train_masks[0])
torch.Size([8000, 128]) torch.Size([2000, 128])
torch.Size([8000, 128])
tensor([ 101, 2769, 6370, 4638, 3221, 10189, 1039, 4638, 117, 852,
2769, 6230, 2533, 8821, 1039, 4638, 7599, 3419, 3291, 1962,
671, 763, 117, 3300, 671, 2476, 1377, 809, 1288, 1309,
4638, 3763, 1355, 119, 2456, 6379, 1920, 2157, 6370, 3249,
6858, 7313, 106, 102, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0])
tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0.])
2.5 创建DataLoader,用来取出一个batch的数据
TensorDataset 可以用来对 tensor 进行打包,就好像 python 中的 zip 功能。
该类通过每一个 tensor 的第一个维度进行索引,所以该类中的 tensor 第一维度必须相等,且TensorDataset 中的参数必须是 tensor类型。
RandomSampler:对数据集随机采样。
SequentialSampler:按顺序对数据集采样。
train_data = TensorDataset(train_inputs, train_masks, train_labels)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sample=train_sampler, batch_size=BATCH_SIZE)
test_data = TensorDataset(test_inputs, test_masks, test_labels)
test_sampler = RandomSampler(test_data)
test_dataloader = DataLoader(test_data, sampler=test_sampler, batch_size=BATCH_SIZE)
查看一下train_dataloader的内容:
for i, (train, mask, label) in enumerate(train_dataloader):
# torch.Size([16, 128]) torch.Size([16, 128]) torch.Size([16, 1])
print(train.shape, mask.shape, label.shape)
break
print('len(train_dataloader) = ', len(train_dataloader)) # 500
3. 创建模型、优化器
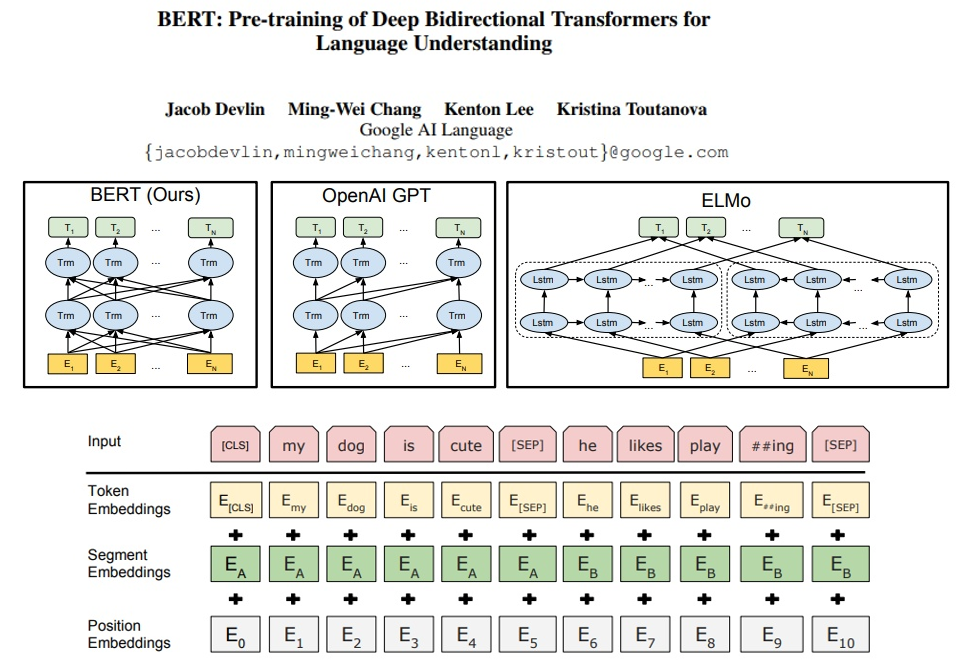
3.1 创建模型
model = BertForSequenceClassification.from_pretrained(model_name, num_labels = 2) # num_labels表示2个分类,好评和差评
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=2, bias=True)
)
3.2 定义优化器
参数eps是为了 提高数值稳定性 而添加到分母的一个项(默认: 1e-8)。
optimizer = AdamW(model.parameters(), lr = learning_rate, eps = epsilon)
更通用的写法:bias和LayNorm.weight没有用权重衰减
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params' : [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
'weight_decay' : weight_decay
},
{'params' : [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
'weight_decay' : 0.0
}
]
optimizer = AdamW(optimizer_grouped_parameters, lr = learning_rate, eps = epsilon)
3.3 学习率预热,训练时先从小的学习率开始训练
epochs = 2
# training steps 的数量: [number of batches] x [number of epochs].
total_steps = len(train_dataloader) * epochs
# 设计 learning rate scheduler.
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps = 0,
num_training_steps = total_steps)
4.训练、评估模型
4.1 模型准确率
def binary_acc(preds, labels): # preds.shape = [16, 2] labels.shape = [16, 1]
# torch.max: [0]为最大值, [1]为最大值索引
correct = torch.eq(torch.max(preds, dim=1)[1], labels.flatten()).float()
acc = correct.sum().item() / len(correct)
return acc
4.2 计算模型运行时间
import time
import datetime
def format_time(elapsed):
elapsed_rounded = int(round(elapsed))
return str(datetime.timedelta(seconds = elapsed_rounded)) # 返回 hh:mm:ss 形式的时间
4.3 训练模型
传入model的参数必须是tensor类型的;
-
nn.utils.clip_grad_norm_(parameters, max_norm, norm_type=2) 用于解决神经网络训练过拟合的方法;
输入是(NN参数,最大梯度范数,范数类型=2) 一般默认为L2 范数;
Tip: 注意这个方法只在训练的时候使用,在测试的时候不用;
def train(model, optimizer):
t0 = time.time()
avg_loss, avg_acc = [],[]
model.train()
for step, batch in enumerate(train_dataloader):
# 每隔40个batch 输出一下所用时间.
if step % 40 == 0 and not step == 0:
elapsed = format_time(time.time() - t0)
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))
b_input_ids, b_input_mask, b_labels = batch[0].long().to(device), batch[1].long().to(device), batch[2].long().to(device)
output = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)
loss, logits = output[0], output[1] # loss: 损失, logits: predict
avg_loss.append(loss.item())
acc = binary_acc(logits, b_labels) # (predict, label)
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
clip_grad_norm_(model.parameters(), 1.0) # 大于1的梯度将其设为1.0, 以防梯度爆炸
optimizer.step() # 更新模型参数
scheduler.step() # 更新learning rate
avg_acc = np.array(avg_acc).mean()
avg_loss = np.array(avg_loss).mean()
return avg_loss, avg_acc
- 此处 output的形式为(元组类型,第0个元素是loss值,第1个元素是每个batch中好评和差评的概率):
(tensor(0.0210, device='cuda:0', grad_fn=),
tensor([[-2.9815, 2.6931],
[-3.2380, 3.1935],
[-3.0775, 3.0713],
[ 3.0191, -2.3689],
[ 3.1146, -2.7957],
[ 3.7798, -2.7410],
[-0.3273, 0.8227],
[ 2.5012, -1.5535],
[-3.0231, 3.0162],
[ 3.4146, -2.5582],
[ 3.3104, -2.2134],
[ 3.3776, -2.5190],
[-2.6513, 2.5108],
[-3.3691, 2.9516],
[ 3.2397, -2.0473],
[-2.8622, 2.7395]], device='cuda:0', grad_fn=))
4.4 评估模型
调用model模型时不传入label值。
def evaluate(model):
avg_acc = []
model.eval() # 表示进入测试模式
with torch.no_grad():
for batch in test_dataloader:
b_input_ids, b_input_mask, b_labels = batch[0].long().to(device), batch[1].long().to(device), batch[2].long().to(device)
output = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
acc = binary_acc(output[0], b_labels)
avg_acc.append(acc)
avg_acc = np.array(avg_acc).mean()
return avg_acc
此处output的形式为(元组类型,第0个元素是每个batch中好评和差评的概率):(区别写label的model)
(tensor([[ 3.8217, -2.7516],
[ 2.7585, -2.0853],
[-2.9317, 2.9092],
[-3.3724, 3.2597],
[-2.8692, 2.6741],
[-3.2784, 2.9276],
[ 3.4946, -2.8895],
[ 3.7855, -2.8623],
[-2.2249, 2.4336],
[-2.4257, 2.4606],
[ 3.3996, -2.5760],
[-3.1986, 3.0841],
[ 3.6883, -2.9492],
[ 3.2883, -2.3600],
[ 2.6723, -2.0778],
[-3.1868, 3.1106]], device='cuda:0'),)
4.5 运行训练模型和评估模型
for epoch in range(epochs):
train_loss, train_acc = train(model, optimizer)
print('epoch={},训练准确率={},损失={}'.format(epoch, train_acc, train_loss))
test_acc = evaluate(model)
print("epoch={},测试准确率={}".format(epoch, test_acc))
Batch 40 of 500. Elapsed: 0:00:27.
Batch 80 of 500. Elapsed: 0:00:53.
Batch 120 of 500. Elapsed: 0:01:20.
Batch 160 of 500. Elapsed: 0:01:47.
Batch 200 of 500. Elapsed: 0:02:14.
Batch 240 of 500. Elapsed: 0:02:40.
Batch 280 of 500. Elapsed: 0:03:07.
Batch 320 of 500. Elapsed: 0:03:34.
Batch 360 of 500. Elapsed: 0:04:01.
Batch 400 of 500. Elapsed: 0:04:28.
Batch 440 of 500. Elapsed: 0:04:55.
Batch 480 of 500. Elapsed: 0:05:22.
epoch=0,训练准确率=0.90275,损失=0.2619755164962262
epoch=0,测试准确率=0.9325
Batch 40 of 500. Elapsed: 0:00:27.
Batch 80 of 500. Elapsed: 0:00:53.
Batch 120 of 500. Elapsed: 0:01:20.
Batch 160 of 500. Elapsed: 0:01:47.
Batch 200 of 500. Elapsed: 0:02:14.
Batch 240 of 500. Elapsed: 0:02:41.
Batch 280 of 500. Elapsed: 0:03:08.
Batch 320 of 500. Elapsed: 0:03:35.
Batch 360 of 500. Elapsed: 0:04:02.
Batch 400 of 500. Elapsed: 0:04:28.
Batch 440 of 500. Elapsed: 0:04:55.
Batch 480 of 500. Elapsed: 0:05:22.
epoch=1,训练准确率=0.953375,损失=0.15345162890665234
epoch=1,测试准确率=0.9435
5. 预测
def predict(sen):
input_id = convert_text_to_token(tokenizer, sen)
input_token = torch.tensor(input_id).long().to(device) #torch.Size([128])
atten_mask = [float(i>0) for i in input_id]
attention_token = torch.tensor(atten_mask).long().to(device) #torch.Size([128])
output = model(input_token.view(1, -1), token_type_ids=None, attention_mask=attention_token.view(1, -1)) #torch.Size([128])->torch.Size([1, 128])否则会报错
print(output[0])
return torch.max(output[0], dim=1)[1]
label = predict('酒店位置难找,环境不太好,隔音差,下次不会再来的。')
print('好评' if label==1 else '差评')
label = predict('酒店还可以,接待人员很热情,卫生合格,空间也比较大,不足的地方就是没有窗户')
print('好评' if label==1 else '差评')
label = predict('"服务各方面没有不周到的地方, 各方面没有没想到的细节"')
print('好评' if label==1 else '差评')
tensor([[ 2.3774, -4.0351]], device='cuda:0', grad_fn=)
差评
tensor([[-2.5653, 2.7316]], device='cuda:0', grad_fn=)
好评
tensor([[-2.0390, 1.6002]], device='cuda:0', grad_fn=)
好评