【python进阶】你还在使用for循环新建数组?生成器表达式帮你一行解决

引言
♂️作者简介:生鱼同学,大数据科学与技术专业硕士在读,曾获得华为杯数学建模国家二等奖,MathorCup 数学建模竞赛国家二等奖,亚太数学建模国家二等奖。
✍️研究方向:复杂网络科学
兴趣方向:利用python进行数据分析与机器学习,数学建模竞赛经验交流,网络爬虫等。
在python学习的过程中,我们最先接触到的就是python的数组,元组,字典等基础类型,但很少有人深入讨论python的内置序列类型以及它们的高级使用姿势。
深度学习python的内置序列,不仅能让我们编写的API更加的易用简介,也能够更好的理解python中各种序列的特性。
在本文中,我们就来一起解锁python内置序列的高级用法,玩转pyhon序列。
内置序列类型
python中有很多的序列类型,主要可以分为以下两类:
- 容器序列:能存放不同数据类型的数据的序列。(list, tuple, collections.deque)
- 扁平序列:只能容纳一种类型的序列。(str, bytes, bytearray, memoryview, array.array)
说明:扁平序列储存的是一段连续的内存空间,而容器序列存放的是它们包含的任意类型对象的引用。
另外,序列类型还可以从可修改与不可修改的角度进行分类,主要能被分成以下两类:
- 可变序列:list, bytearray, array.array, collections.deque, memoryview
- 不可变序列:str, tuple, bytes
为了深入的讨论可变序列与不可变序列的差异,我们看下面这个UML图:
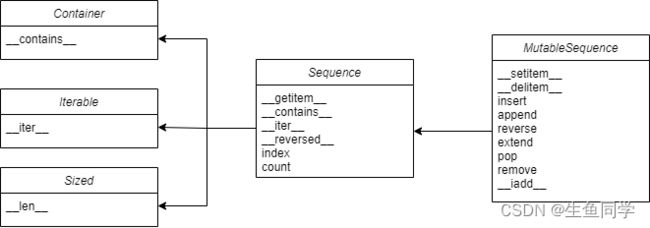
在上图中,继承从子类指向超类,可以看到可变序列(MutableSequence)继承了不可变序列(Sequence)的很多方法。与此同时,通过UML图我们也可以更直观的发现其不同的地方,这有助于我们了解后续的内置序列类型的差异。
列表推导与生成器表达式
列表推导
相信大家已经对基础的序列类型list有了初步的了解与认识,但当我们想要创建一个新的数组时,往往会想到使用for循环遍历生成。
其实在python中还存在一种构建列表的方法叫做列表推导(list comprehension),它是构建列表的快捷方式,同时也能够使你的代码更加易读与简洁。假设我们需要创建从0到10的一个列表,我们来看下面的两段代码:
# 不使用列表推导
example_list_01 = []
for i in range(10):
example_list_01.append(i)
print(example_list_01)
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 列表推导
example_list_01 = [i for i in range(10)]
print(example_list_01)
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
相信大部分人第一时间都会考虑使用第一种方法进行列表的创建,但明显使用了列表推导(生成器表达式推导列表)的例子看起来更加简便且易读。我们再来看一个更复杂的例子,假设我们想要寻找10以内的偶数,我们看下面两段代码:
# 不使用列表推导
example_list_02 = []
for i in range(10):
if i % 2 == 0:
example_list_02.append(i)
print(example_list_02)
# 列表推导
example_list_02 = [i for i in range(10) if i % 2 == 0]
print(example_list_02)
显然,下面的代码可读性更强且更为简单。另外,使用filter也能够完成上述的功能,但是可读性并不强。我们使用filter完成上述功能的代码如下:
example_list_03 = list(filter(lambda i: i % 2 == 0, range(10)))
print(example_list_03)
显然,这样的可读性并不强。
在列表推导中,我们还可以将自己的函数或者python内置函数直接对生成的数组进行处理,请看下面这个例子:
def deal(num):
return '处理过的' + str(num)
deal_list = [deal(i) for i in range(10)]
print(deal_list )
>>> ['处理过的0',
'处理过的1',
'处理过的2',
'处理过的3',
'处理过的4',
'处理过的5',
'处理过的6',
'处理过的7',
'处理过的8',
'处理过的9']
最后,我们再用列表推导表达式尝试计算笛卡尔积并与for循环完成的相同的功能做对比,请看下面的代码:
colors = ['红色','蓝色','绿色']
clothes = ['上衣','裤子','运动鞋']
clothes_list_01 = []
for color in colors:
for clothe in clothes:
clothes_list_01.append((color,clothe))
print('未使用列表推导:',clothes_list_01)
clothes_list_02 = [(color,clothe) for color in colors for clothe in clothes]
print('使用列表推导:',clothes_list_01)
结果如下:
未使用列表推导: [('红色', '上衣'), ('红色', '裤子'), ('红色', '运动鞋'),
('蓝色', '上衣'), ('蓝色', '裤子'), ('蓝色', '运动鞋'), ('绿色', '上衣'), ('绿色', '裤子'), ('绿色', '运动鞋')]
使用列表推导: [('红色', '上衣'), ('红色', '裤子'), ('红色', '运动鞋'),
('蓝色', '上衣'), ('蓝色', '裤子'), ('蓝色', '运动鞋'), ('绿色', '上衣'), ('绿色', '裤子'), ('绿色', '运动鞋')]
可以看到输出的结果是完全相同的,但是利用列表推导的代码更为简洁。
生成器表达式
虽然使用上述的列表推导语法也可以生成元组等其他类型的序列,但是使用生成器表达式会更好。生成器并不是先建立一个完整的列表再将其传递到某个构造函数内,而是逐个产出元素,这会更加的节省内存。
我们看下面几个例子,用来了解生成器表达式是如何生成字典与元组的。
# 使用生成器表达式构建字典
dict_transform_list = [('APPLE', '苹果'), ('BNANA', '香蕉'), ('PEAR', '梨子')]
dict_01 = {key: value for key,value in dict_transform_list}
>>>{'APPLE': '苹果', 'BNANA': '香蕉', 'PEAR': '梨子'}
# 使用生成器表达式构建元组
tuple_01 = tuple(i for i in range(10))
>>>(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
总结
在本文中,介绍了生成器与表达式的用法,帮助我们快速创建数组以及其他序列,解锁了python序列的新姿势。
在后续的更新中,我将继续对元组的高级姿势和玩法进行介绍。
如果你觉得本文对你有帮助的话,希望你点个收藏或帮我点个赞,如果有其他问题也可以私信我与我交流或在评论区与我讨论,我们下次再见。
