复旦提出M2TR:首个多模态多尺度Transformer
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文授权转载自:我辈怎是蓬篙人(系粉丝投稿)
M2TR: 首个多模态多尺度Transformer
CNN?是模仿也是超越

文章地址 https://arxiv.org/abs/2104.09770
写在前面
这是第一次在自媒体平台介绍自己的工作,相比于之前的paper note,这篇文章的文字里会更多浸润和表达我对每一个模块设计时自己的思考与探索,所以与其说是一篇笔记,以下的内容更像是一段故事,至少可以讲,我们这篇工作不是炼丹、不是调参,而是针对Deepfake这个任务的亟待解决的一些问题,给出我们的思路和想法。
Motivation
Visual Transformer在最近可谓是热点中的热点,直接的表现就是在各种视觉任务上屠榜,但是transformer是否适合于所有的视觉任务呢?
想要对这个问题给出回答,我想首先聊一下我认为的transformer的具有的优势:
l信息整合,我称为information integration
l一致建模,我称为consistency modeling
二者看似矛盾其实相辅相成,不同patch之间相似度的计算是一种相对微观的操作对应于后者,但是对每个patch来说,加权求和对其他patch的注意力以及values值则是一种宏观的操作对应于前者。二者微妙结合,一开一合之间助力transformer在各类视觉任务上都能取得良好的表现。
对的没错,我就是全网第一川粉,不是trump的川,而是transformer的川。
那么是否transformer就是大家心中的白月光,没有任何缺点呢?这个问题需要回到需要回到CV任务的需要来回答、也需要回到transformer本身的架构上来回答。前者来说,transformer的特征提取能力如何、部分CV任务需要的多模态信息在transformer能否很好的融合呢?后者来说,transformer的结构相对固化,能否如CNN一样提取到丰富的、层次性的信息呢?
我们把这两个问题暂时搁置,回到我们的这篇工作。Deepfake在我心中是一个接地气的CV领域,前段时间”蚂蚁牙黑“在微博大火,背后蕴含的技术正是Deepfake生成,不过这股浪潮很快就被扑灭了,原因很简单,随之而来的不仅有法律风险更有对互联网信息真实度的挑战,所以Deepfake检测无疑是一个具有现实意义和迫切需求的研究方向。
那么Deepfake检测目前面临哪些难点呢?我想主要是四个方面的:
l缺乏高质量的数据集
我们借助文章里的一个图来理解:

这个是我从当前的Deepfake数据集里找到的伪造图像,可以看出这些图像具有明显的视觉artifacts,因此简单的网络就能进行识别,而互联网上流传的图像是特别逼真的,因此在这些数据集上训练的网络很难在高质量的伪造图像上取得好的检测准确率;
l多尺度特征提取
依然来看上面的图,不同的数据集,或者说不同的伪造方法所生成图像具有的伪造特征差距很大,比如第一行第二列的图artifacts是相对细微难以察觉的,而第二行第三列的图artifacts则是相对明显的,因此普通的卷积操作也好、transformer结构也好,都是在相同尺度上进行特征提取,即使通过特征金字塔那样网络层数的堆叠获得到了多尺度的特征,也依然会带来模型复杂度提升、容易过拟合、不同尺度特征难以融合等问题;
l对于图像压缩的鲁棒性
目前Deepfake检测方法的评估主要在FF++[1] 数据集上进行,这个数据集拥有三个版本:正常生成的RAW版本、对RAW进行低压缩率压缩的HQ版本、对RAW进行高压缩率压缩的LQ版本,大部分的方法包括我们采用的baseline EfficientNet等在RAW和HQ上都能达到很高的准确率,但是由于图像压缩带来的损失,一些伪造的artifacts在LQ上也被抹掉而导致在其上的性能很差。可以看一下我们paper里列出的一些数据:
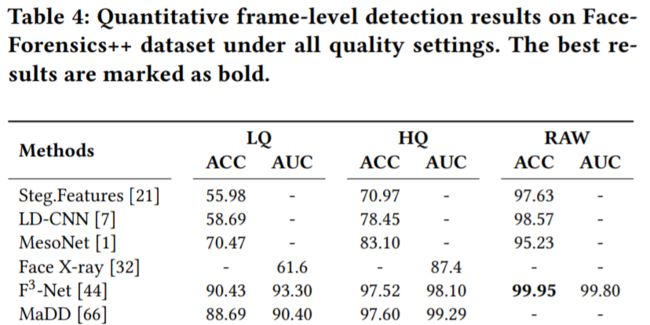
在RAW和HQ上能达到99%+的模型在LQ上大部分降到了80%以下。
l对于伪造方法的鲁棒性
不同的数据集生成的伪造图像所采用的伪造方法往往是不同的,甚至生成的图像可能会有较大差异,因此如何在有限的伪造数据上训练出一个对所有或者大部分伪造数据都能有良好检测性能的方法是一个重要的问题(也是检测方法能否真正应用的瓶颈所在)。
针对高质量训练数据缺乏问题,我们利用SOTA的人脸操作方法(facial manipulation methods)生成伪造图像、并利用了图像和谐化(image harminzation)的方法进行后处理,构造了一个较高质量的数据集。
针对多尺度特征提取,我们不妨战术性后撤一步,先思考一下如何捕捉单一尺度的伪造信息呢?首先我们思考这种所谓伪造特征的本质是什么?不妨做出这样的假设:假如让一个襁褓中的婴儿判断,ta能否找到哪些图是伪造的、哪些区域是伪造的?答案显然是否定的,那么原因呢?其实很简单,我们能识别出来,只是因为我们见过了大量普通的人脸应该具有的样子,基于这种记忆我们判断哪些区域比较异常。具体地在一张图像上,并不是所有的区域都是被伪造的,比如第一行第一列,视觉上来看只有嘴巴的位置具有artifacts,而其余面部都是正常的,因为这种伪造信号其实是一种上下文之间的consistency信息。consistency?这个词有点熟悉啊!没错,这个问题交给transformer来解决简直是天作之合。

问题又来了,传统的CNN可以有一万种方法提取多尺度特征(既可以水平方向并行用多个不同大小的卷积核、也可以垂直方向用不同深度的层),但是transformer输入的patch大小就是固定的怎么提取不同尺度的连续性信息呢?对,答案就在字面上,我们把输入划分成不同的patch大小就好了,大的patch来提取那些明显的语义不连贯、小的patch来提取细微的像素级不连贯。transformer的多头注意力,一直说不同的head提取到了不同的信息,其实还是让人难以接受的,既然如此,我们就直接在不同的head里用不同大小的patch作为输入,这个设计其实是对CNN的经典结构InceptionNet的致敬:
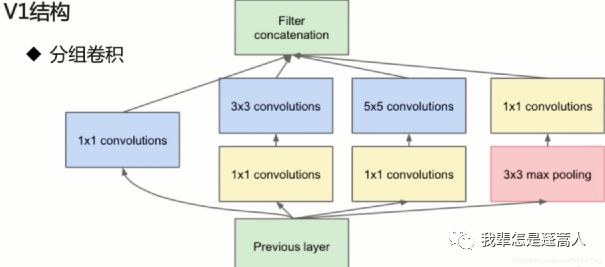
Inception可以并行地提取多尺度的特征,transformer也可以通过在不同head里用不同大小的patch实现这一点。
下面来看第三个问题对压缩算法的鲁棒性,其实这个问题乍一看是没有办法解决的,因为压缩导致的信息丢失似乎是决定了一张伪造的RGB图像里蕴含的信息上限,天花板在那里,再怎么努力跳也还是很难突破瓶颈。不过既然RGB图像的信息有上限,我们是不是可以寻求其他模态的特征辅助呢?那么哪个模态的特征有帮助呢?我们需要回到问题本身:图像压缩。图像压缩算法(比如JPEG)等都需要先进行DCT变换,巧合的是,之前有一系列工作探索了这个方向[2-5],他们的结果表明经过Deepfake生成的伪造图像会在频域留下一些不可磨灭的特征分布,所以我们将频率信息引入到了Deefake检测。
最后一个问题模型的泛化能力其实是当前Deepfake检测真正的痛点、也是难点,任何一个数据集囊括的伪造图像总是有限的,但是Deepfake的技术确实不断更新而无限的,泛化能力是深度学习一个长久的问题,在Deepfake检测领域则更甚。解决这个问题的思路部分来自于我这学期一门课的论文分享,我当时讲的是自监督领域的一篇经典文章MOCO,这种基于constrastive learning的方法一个很重要的问题在于尽可能穷举更多的负样本以帮助anchor特征学习,这一点其实和Deepfake有一种奇妙的联动:正样本也就是真实人脸数据的分布其实是固定的(人脸总是crop过),而负样本的分布则是非常丰富的,因为我们提出了一种constrastive loss:在特征空间里,缩小正样本到类中心的距离,拉大负样本到正样本类中心的距离,来实现压缩正样本空间且剥离正负样本空间的目的。
聊完motivation,这篇文章其实已经讲的差不多了,下面是一些具体的是实现,彩蛋应该主要在RGB模态和频率模态的融合上。
Method

M2TR
我们首先利用EfficientNet作为backbone提取了网络的浅层特征(这个做法呼应了上文提到的,我对于transformer的理解更多是建模全局信息与一致性信息,特征提取还是交给CNN完成,不过ViT也会对patch进行embedding,我们与之的区别只是在二维图像embedding还是一维展平的patch上embedding),然后利用Multi-scale Transformer进行多尺度特征提取和Cross Modality Fusion进行双模态融合。
Multi-scale Transformer
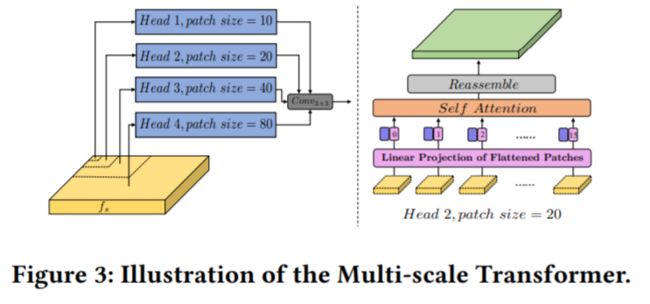
区别于ViT的地方有三点:
1.不是在图像取patch而是在feature map上
2.不同head里取的patch size不同
3.patch被flatten成一维经过了self-attention之后会被重新reassemble成二维得到3D feature map
Cross Modality Fusion
首先我们对图像做DCT变换,得到了频率分布图,DCT变换具有良好的性质:高频集中在左上角而低频在右下角,因此我们手动对其进行划分,得到了高、中、低三个频段的频率分量,但是频率图不具有RGB图像的视觉特征,也没有办法利用CNN进行特征提取,为此我们对三个分量进行逆DCT变换,重新得到了RGB域的表示,但是这个表示是frequency-aware的,然后利用卷积层进行特征提取。
双模态融合是一个长久的问题,如何良好的嵌入到transformer更是关键,一种最简单的做法、也是现在很多利用频率信息的做法就是对RGB和Frequency采用一种two-stream的双流结结构,平行操作然后在中间或者输出的地方进行融合,这种做法我不是非常赞同,因为并行结构的一个重要前提是两个模态的地位或者信息量是均衡的,但是对于Deepfake来说,频率的信息其实还是具有噪声的,比如人脸的一些部分如头发等在频率也可能集中在高频区域里,因此合适的做法是把频域作为一种辅助模态。
基于这种想法、同时受启发于transformer的query-key-value的设计,我们提出了一种QKV的方法来融合两个模态:把RGB模态作为query、frequency模态作为memory,这样的设计一方面能突出RGB的作用,另一方面能更好地发掘frequency分布里的异常区域。
另外值得一提的是,为了提高我们模型的鲁棒性、避免overfit,我们采用multi-task的方式,讲multi-scale transformer的输出经过一个decoder进行人脸操作区域的预测。
SR-DF
接下来介绍我们的数据集,先说名字的来源,SR-DF来自于face Swapping and facial Reenactment DeepFake dataset,顾名思义使用的Deepfake生成技术既包含了换脸也包含了重演(前者是把一个人的脸换成另一个人的,后者是按照一个人的表情让另一个人生成同样的表情),我们采用了四种SOTA的方法:FaceShifter[6]、FSGAN[7]、First-order-motion[8]和IcFace[9]。
值得一提的是,现有的Deepfake生成方法都是在crop过的人脸上进行的,也就是完整的Deepfake人脸图像生成需要经过整图->抠人脸->换脸/重演->贴回背景,这个过程中会导致最后一步贴回的时候有颜色不一致和明显边界框的问题,为了解决这个问题,我们采用了image harmonization的方法DoveNet进行平滑后处理。
除此之外,Deepfake领域目前没有一套衡量数据集质量的指标,为此我们希望从四个角度出发,构造一整套完整、无偏的衡量体系:
l身份保留度:换脸之后是否保留了原始的身份信息,我们分割出人脸区域,并与原图计算SSIM,也就是Mask-SSIM。
l人脸真实度:生成人脸的视觉感官真实度,我们计算人脸区域生成图像和原始图像的perceptual loss。以上两个都是从inpainting的工作中得到的启发。
l时序光滑度:生成的视频序列时序上的一致程度,我们计算帧之间的Ewarp,具体就是计算光流并warp前一帧,然后与后一帧计算L1 loss,这个是从[11]这篇做视频生成一致性的工作中得到的启发。
l分布多样性:Celeb-DF[12]这个数据集在以上的指标中都取得了很好的表现,但是它有一个很大的缺点是用一个统一的方法生成所有伪造视频,而且都是换脸没有重演,因此虽然视觉质量较高但是数据分布单一,为了更全面地衡量数据集质量,我们利用ImageNet上pretrain的resnet50对数据集里的图像进行特征提取,然后用t-SNE进行降维并可视化。
Experiment
我们首先在FF++ / Celeb-DF / SR-DF上分别验证模型在frame-level的性能:
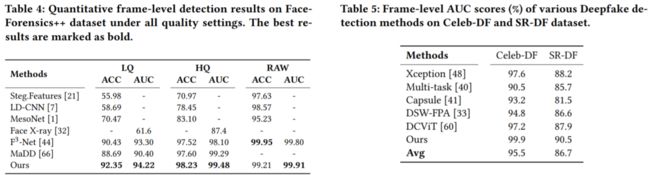
我们的方法在三个数据集都取得了SOTA,值得一提的是在FF++ (raw)上性能提升比较明显,这得益于frequency模态的引入以及transformer通过小的patch捕捉细微的artifacts的能力。
然后我们在Video level上做了测试,为了更好的捕捉时序特征,我们用frame-level训练好的模型提取每个帧的特征,然后把每帧作为一个patch输入到ViT那样的vanilla transformer里,构成了一种spatial-temporal transformer的结构:
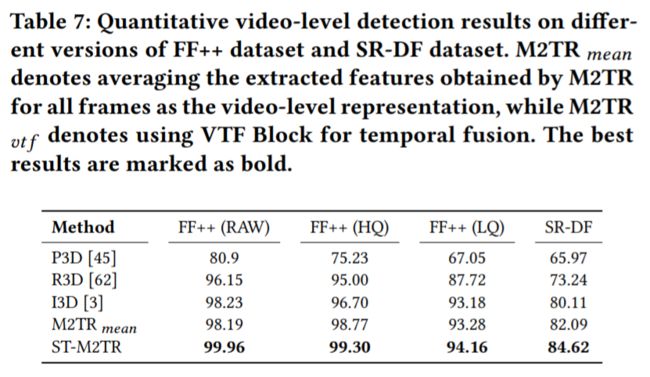
接下来是泛化性能力的验证:
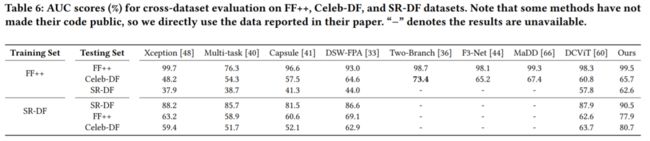
可以看出,得益于模型本身的特征提取能力、以及constrastive loss的应用,我们的方法具有良好的泛化能力。
最后是两组ablation study,分别对multi-scale transformer、CMF、不同patch size的single-scale transformer进行了消融实验:
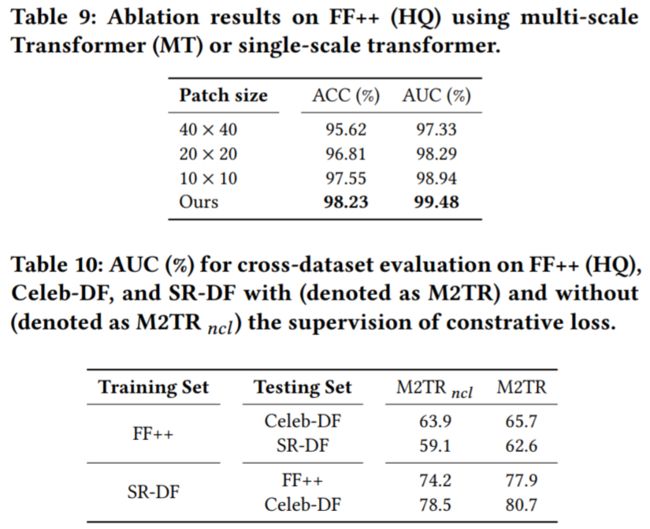
总的来说,我们的模型用一个统一的框架,解决了Deepfake检测里四个棘手的问题。
后记
在最后想解释一下题目里为什么说我们的M2TR对CNN既是一种模仿也是超越:模仿的地方在于我们希望借鉴InceptionNet这个CNN里的经典结构并行提取多尺度的特征,也希望像CNN里的two-branch等结构一样,为transformer里的多模态融合提供一种通用的架构,超越则体现在了更强的全局特征融合能力、以及局部不一致的捕捉能力。
代码和数据集后续会在github开源,希望大家可以关注、交流、引用三连。
引用
[1]Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. 2019. Faceforensics++: Learning to detect manipulated facial images. In ICCV
[2] Ricard Durall, Margret Keuper, Franz-Josef Pfreundt, and Janis Keuper. 2019. Unmasking deepfakes with simple features. arXiv preprint arXiv:1911.00686 (2019).
[3] Ying Huang, Wenwei Zhang, and Jinzhuo Wang. 2020. Deep frequent spatial temporal learning for face anti-spoofing. arXiv preprint arXiv:2002.03723 (2020).
[4] Yuyang Qian, Guojun Yin, Lu Sheng, Zixuan Chen, and Jing Shao. 2020. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In ECCV.
[5] Ning Yu, Larry S Davis, and Mario Fritz. 2019. Attributing fake images to gans: Learning and analyzing gan fingerprints. In ICCV.
[6] Lingzhi Li, Jianmin Bao, Hao Yang, Dong Chen, and Fang Wen. 2019. Faceshifter: Towards high fidelity and occlusion aware face swapping. arXiv preprint arXiv:1912.13457 (2019).
[7] Yuval Nirkin, Yosi Keller, and Tal Hassner. 2019. Fsgan: Subject agnostic face swapping and reenactment. In ICCV.
[8] Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. 2020. First order motion model for image animation. arXiv preprint arXiv:2003.00196 (2020).
[9] Soumya Tripathy, Juho Kannala, and Esa Rahtu. 2020. Icface: Interpretable and controllable face reenactment using gans. In WACV.
[10] Wenyan Cong, Jianfu Zhang, Li Niu, Liu Liu, Zhixin Ling, Weiyuan Li, and Liqing Zhang. 2020. DoveNet: Deep Image Harmonization via Domain Verification. In CVPR.
[11] Chenyang Lei, Yazhou Xing, and Qifeng Chen. 2020. Blind video temporal consistency via deep video prior. arXiv preprint arXiv:2010.11838 (2020).
[12] Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. 2020. Celeb-df: A large-scale challenging dataset for deepfake forensics. In CVPR.
论文PDF和代码下载
后台回复:M2TR,即可下载上述论文
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看