顾客使用天猫优惠劵预测python实战
顾客使用天猫优惠劵预测
“天猫”(Tmall)原名淘宝商城,是一个综合性购物网站,是马云淘宝网全新打造的B2C(Business-to-Coustomer,商业零售)品牌。其整合数千家品牌商,生产商,为商家和消费者之间提供一站式解决方案,提供100%品质保证的商品,7天无理由退货的售后服务,以及购物积分返现等优质服务。
问题:基于所给的数据,利用Python进行数据分析和建立逻辑回归模型,对顾客是否使用优惠劵进行预测。
数据表的主要字段:
ID:记录编号
age:年龄
job:职业
marital:婚姻状态
default:花呗是否有违约(类别型变量)
returned:是否有过退货(类别型变量)
loan:是否使用花呗结账(类别型变量)。
coupon_used_in_last6_month:过去6个月使用的优惠劵数量
coupon_used_in_last_month:过去1个月使用的优惠劵数量
coupon_ind:该次活动中是否有使用优惠劵(预测目标)
打开python,开始敲代码
首先导入相关的库和数据文件
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
get_ipython().run_line_magic('matplotlib', 'inline')
#解决中文和负号不正常显示的问题
plt.rcParams['font.sans-serif']='SimHei'
plt.rcParams['axes.unicode_minus']=False
df=pd.read_csv(r'Tmall.csv')
#查看数据概括
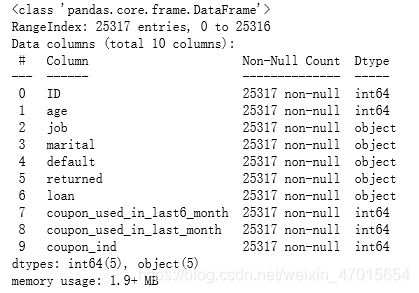
df.info()
#查看前5行数据
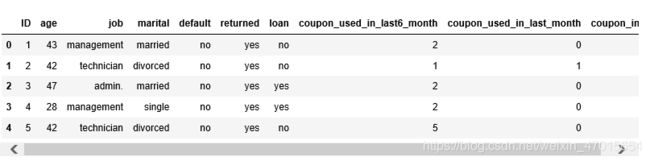
df.head()
#查看job变量的所有不重复值
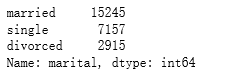
df.job.value_counts()

#查看marital变量的所有不重复值
df.marital.value_counts()
对于类别型变量,需要进行哑变量处理。我个人认为job和marital变量不需要进行哑变量处理。job变量的非重复值太多了,经过哑变量处理会使数据显得冗余。marital变量有3个非重复值,可以用下文的相关性分析,没有必要进行哑变量处理。
需要进行哑变量处理的变量为:default,returned,loan。(都是2分类变量)
#把default、returned、loan三个变量单独取出来进行哑变量处理get_dummies()。
df1=df[['default','returned','loan']]
df1=pd.get_dummies(df1)
df1.head()
#把处理后的表格和原表进行拼接concat()
df=pd.concat([df,df1],axis=1)
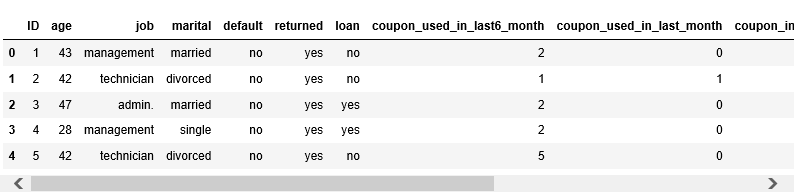
df.head()
#删除不需要用到的变量(删除列)
df.drop(['default','default_no','returned','returned_no','loan','loan_no','ID'],axis=1,inplace=True)
#为了方便,重命名coupon_ind为flag
df=df.rename(columns={'coupon_ind':'flag'})
df.head()
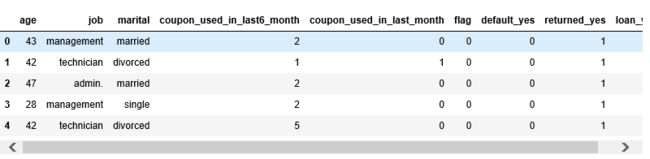
数据预处理完成,然后对于关键预测变量进行分析。
df.flag.value_counts()
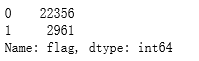
df.flag.value_counts(1)
#观察均值大小
#对于数据为0和1的数据,观察均值的大小有利于了解该变量在flag上的分布情况
summary=df.groupby('flag')
summary.mean()

然后实现数据可视化以及相关性分析。
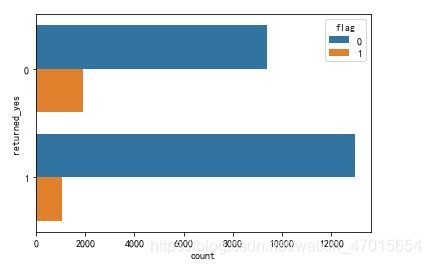
#return_yes(1,有。0,无)是否有过退货和flag的关系图
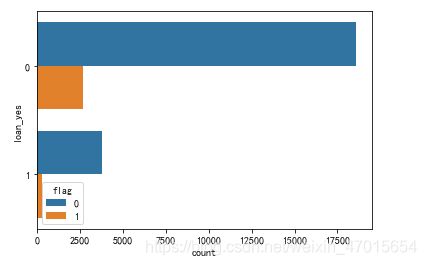
sns.countplot(y='returned_yes',hue='flag',data=df)
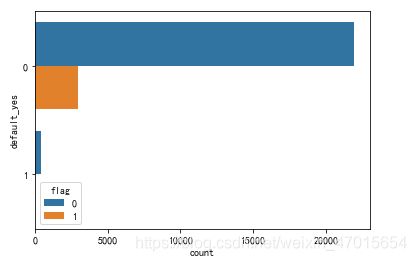
sns.countplot(y='default_yes',hue='flag',data=df)
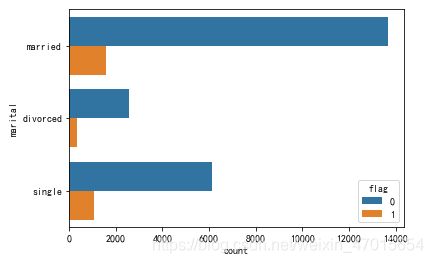
sns.countplot(y='marital',hue='flag',data=df)
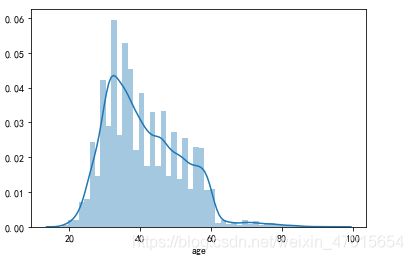
sns.distplot(df['age'])
#对于年龄进行快速分组,探究各个年龄段对于是否使用优惠劵的影响
#df.age.value_count().sort_values() 这里如何按照年龄大小进行排列???
bins=[0,20,40,60,80,100]
labels=['0-20','20-40','40-60','60-80','80-100']
df['age_new']=pd.cut(df.age,bins,right=False,labels=labels)
df.groupby(['age_new'])['age'].describe()
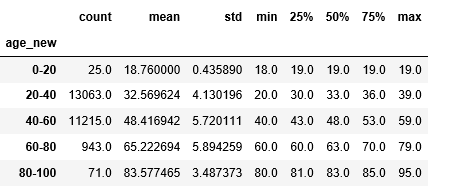
age_new_counts=df['age_new'].value_counts()
print(age_new_counts)

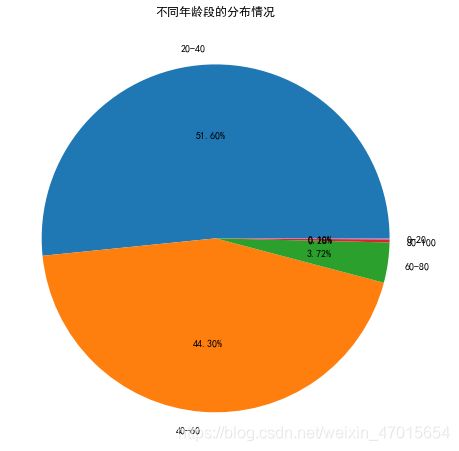
#绘制年龄的饼图
plt.figure(figsize=(8,8))
plt.title('不同年龄段的分布情况')
plt.pie(age_new_counts,labels=['20-40','40-60','60-80','80-100','0-20'],autopct='%1.2f%%')
plt.show()
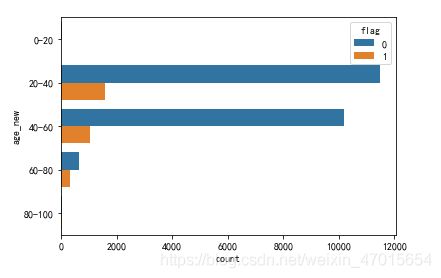
#不同年龄段和是否使用优惠劵的关系图
sns.countplot(y='age_new',hue='flag',data=df)
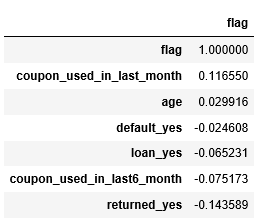
#查看相关系数
df.corr()[['flag']].sort_values('flag',ascending=False)
结论:
1,天猫优惠劵的使用率明显较低,只有小部分的顾客会使用天猫优惠劵。
2,相比于有过退货记录的顾客,没有退货记录的顾客使用优惠劵的概率较高。
相比于有花呗违约记录的顾客,没有花呗违约记录的顾客使用优惠劵的概率较高。
3,使用天猫优惠劵的总人数:已婚顾客>单身顾客>未知婚姻状态的顾客。
使用天猫优惠劵的顾客比例:单身顾客>=未知婚姻状态的顾客>已婚顾客。
4,20-40岁和40-60岁的顾客占大部分,占比高达95.9%。60-80岁的顾客使用优惠劵的比例最高。
5,coupon_used_in_last_month和age变量和flag变量是正相关关系,剩余变量和flag变量是负相关关系。
接着建立逻辑回归分类模型
y=df['flag']
x=df[['default_yes','loan_yes','returned_yes']]
#划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=100)
#建模
from sklearn import linear_model
lr=linear_model.LogisticRegression()
lr.fit(x_train,y_train)

#输出截距和相关系数
print(lr.intercept_)
print(lr.coef_)
![]()
#进行预测
y_train_pred=lr.predict(x_train)
y_test_pred=lr.predict(x_test)
#评估模型效果
import sklearn.metrics as metrics
metrics.confusion_matrix(y_train,y_train_pred)
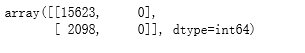
#计算准确率(训练集)
metrics.accuracy_score(y_train,y_train_pred)
![]()
#计算准确率(测试集)
metrics.accuracy_score(y_test,y_test_pred)
![]()
模型的优化
通过调整模型测试集和训练集的划分比例test_size进行优化,重新跑一下结果,比较准确率的大小。准确率越大,模型效果越好。