flink-cdc写入hudi,使用hive或者spark-sql统计分析hudi的数据
一、环境准备:
flink1.12.2_2.11
hudi-0.9.0(master分支)
spark-2.4.5、hadoop-3.1.3、hive-3.1.2(选择的是阿里云emr-2.4.5)
二、flink-cdc写入hudi
1、mysql建表语句
create table users
(
id bigint auto_increment primary key,
name varchar(20) null,
birthday timestamp default CURRENT_TIMESTAMP not null,
ts timestamp default CURRENT_TIMESTAMP not null
);
// 随意插入几条数据
insert into users (name) values ('hello');
insert into users (name) values ('world');
insert into users (name) values ('iceberg');
insert into users (id,name) values (4,'spark');
insert into users (name) values ('hudi');
select * from users;
update users set name = 'hello spark' where id = 5;
delete from users where id = 5;
2、启动sql-client
$FLINK_HOME/bin/sql-client.sh embedded
1.创建 mysql-cdc
CREATE TABLE mysql_users (
id BIGINT PRIMARY KEY NOT ENFORCED ,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'server-time-zone' = 'Asia/Shanghai',
'database-name' = 'mydb',
'table-name' = 'users'
);
2.创建hudi表
CREATE TABLE hudi_users2
(
id BIGINT PRIMARY KEY NOT ENFORCED,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
`partition` VARCHAR(20)
) PARTITIONED BY (`partition`) WITH (
'connector' = 'hudi',
'table.type' = 'MERGE_ON_READ',
'path' = 'hdfs://localhost:9000/hudi/hudi_users2',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '1'
);
3.mysql-cdc 写入hudi ,会提交有一个flink任务
INSERT INTO hudi_users2 SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') FROM mysql_users;
3、flink任务提交成功后,可以查看任务界面。
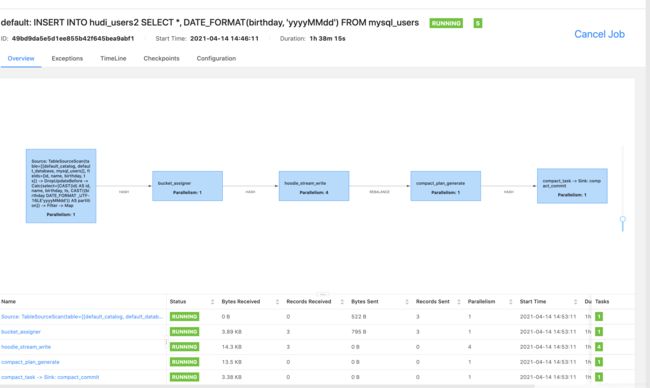
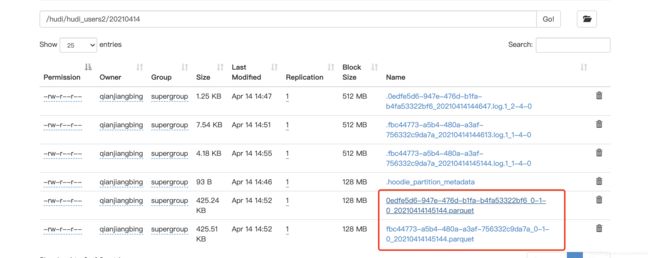
4、同时可以查看hdfs界面里面hudi数据路径,当然这里要等flink 5次checkpoint之后才能查看到这些目录,一开始只有.hoodie一个文件夹

5、在mysql执行insert、update、detelet等操作,等hudi里面的文件compact成parquet文件后就可以用hive/spark-sql/presto(本文只做了hive和spark-sql的测试)来查询啦,这里有个点要提下:如过没有生成parquet文件,我们建的parquet表是查询不出数据的
三、hive查询hudi的数据
1、cd $HIVE_HOME
2、mkdir auxlib
3、将hudi-hadoop-mr-bundle-0.9.0-SNAPSHOT.jar拷贝过来。

4、使用beeline去登录hive
beeline -u jdbc:hive2://localhost:10000 -n hadoop hadoop5、创建外部表关联hudi路径,有两种建表方式
方式一:INPUTFORMAT是org.apache.hudi.hadoop.HoodieParquetInputFormat
这种方式只会查询出来parquet数据文件中的内容,但是刚刚更新或者删除的数据不能查出来
// 创建外部表
CREATE EXTERNAL TABLE `hudi_users_2`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,
`name` string,
`birthday` bigint,
`ts` bigint)
PARTITIONED BY (
`partition` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://localhost:9000/hudi/hudi_users2';
方式二:INPUTFORMAT是org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
// 这种方式是能够实时读出来写入的数据,也就是Merge On Write,会将基于Parquet的基础列式文件、和基于行的Avro日志文件合并在一起呈现给用户。
CREATE EXTERNAL TABLE `hudi_users_2_mor`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,
`name` string,
`birthday` bigint,
`ts` bigint)
PARTITIONED BY (
`partition` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://localhost:9000/hudi/hudi_users2';
// 添加分区
alter table hudi_users_2 add if not exists partition(`partition`='20210414') location 'hdfs://localhost:9000/hudi/hudi_users2/20210414';
alter table hudi_users_2_mor add if not exists partition(`partition`='20210414') location 'hdfs://localhost:9000/hudi/hudi_users2/20210414';
// 查询分区的数据
select * from hudi_users_2 where `partition`=20210414;
select * from hudi_users_2_mor where `partition`=20210414;
6、INPUTFORMAT是org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat格式的表在hive3.1.2里面是不能够执行统计操作的
执行 select count(1) from hudi_users3_mor where `partition`='20210414';
![]()
查看hive日志 tail -fn 100 hiveserver2.log

set hive.input.format = org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat ;怎么知道这么设置的,看这个issue:https://github.com/apache/hudi/issues/2813,当然阿里的技术文档里面也能找到,只是当时没找到:https://help.aliyun.com/document_detail/193310.html?utm_content=g_1000230851&spm=5176.20966629.toubu.3.f2991ddcpxxvD1#title-ves-82n-odd
再执行一遍还是报错,

但是我在本地用hive-2.3.8执行成功了,社群里面的同学测试1.1版本的也报同样的错误,目前只能猜测是hive版本兼容性导致的吧

四、spark-sql查看分析hudi的表
将hudi-spark-bundle_2.11-0.9.0-SNAPSHOT.jark拷贝到$SPAKR_HOME/jars,每个节点都拷贝一份
将hudi-hadoop-mr-bundle-0.9.0-SNAPSHOT.jar $HADOOP_HOME/share/hadoop/hdfs下,每个节点都拷贝一份
重启hadoop
1、创建表,同样有两种方式
CREATE EXTERNAL TABLE `hudi_users3_spark`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,
`name` string,
`birthday` bigint,
`ts` bigint)
PARTITIONED BY (
`partition` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://localhost:9000/hudi/hudi_users3';
alter table hudi_users3_spark add if not exists partition(`partition`='20210414') location 'hdfs://localhost:9000/hudi/hudi_users3/20210414';
select * from hudi_users3_spark where `partition`='20210414';
// 创建可以实时读表数据的格式
CREATE EXTERNAL TABLE `hudi_users3_spark_mor`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,
`name` string,
`birthday` bigint,
`ts` bigint)
PARTITIONED BY (
`partition` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
LOCATION
'hdfs://localhost:9000/hudi/hudi_users3';
alter table hudi_users3_spark_mor add if not exists partition(`partition`='20210414') location 'hdfs://localhost:9000/hudi/hudi_users3/20210414';
select * from hudi_users3_spark_mor where `partition`='20210414';
spark-sql想读到实时的hudi数据,必须 set spark.sql.hive.convertMetastoreParquet=false;

这里有个坑,如何创建表的时候字段类型不对会报错
比如
CREATE EXTERNAL TABLE `hudi_users3_spark_mor`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` string,
`name` string,
`birthday` string,
`ts` string)
PARTITIONED BY (
`partition` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
LOCATION
'hdfs://localhost:9000/hudi/hudi_users3'; id 、ts、birthday都设置为String,会报下面的错误,看来spark-sql想读取hudi的数据,字段类型要严格的设置一下
五、后续
目前都是小规模数据在测试,后面我们准备用生产数据来走一波,看看flink-cdc写入hudi的性能和稳定性
六、参考
1、https://mp.weixin.qq.com/s/5h6VnXXPvEY3Brhb03ohBA
2、https://github.com/MyLanPangzi/flink-demo/blob/main/docs/%E5%A2%9E%E9%87%8F%E5%9E%8B%E6%95%B0%E4%BB%93%E6%8E%A2%E7%B4%A2%EF%BC%9AFlink%20+%20Hudi.md
3、https://blog.csdn.net/u010848845/article/details/115373576?spm=1001.2014.3001.5501
4、https://otime.top/2021/01/hudi01-start/
5、https://otime.top/2021/01/hudi03-write-query/