机器学习笔记(吴恩达)——逻辑回归
假说表示

我们引入一个新的模型,逻辑回归,该模型的输出变量范围始终在0和1之间。 逻辑回归模型的假设是:
h θ ( x ) = g ( θ T X ) h_\theta \left( x \right)=g\left(\theta^{T}X \right) hθ(x)=g(θTX)
其中: X X X 代表特征向量 g g g 代表逻辑函数(logistic function)是一个常用的逻辑函数为S形函数(Sigmoid function),公式为: g ( z ) = 1 1 + e − z g\left( z \right)=\frac{1}{1+{{e}^{-z}}} g(z)=1+e−z1。
对模型的理解: g ( z ) = 1 1 + e − z g\left( z \right)=\frac{1}{1+{{e}^{-z}}} g(z)=1+e−z1。
h θ ( x ) h_\theta \left( x \right) hθ(x)的作用是,对于给定的输入变量,根据选择的参数计算输出变量=1的可能性(estimated probablity)即 h θ ( x ) = P ( y = 1 ∣ x ; θ ) h_\theta \left( x \right)=P\left( y=1|x;\theta \right) hθ(x)=P(y=1∣x;θ)
判定边界
现在假设我们有一个模型:
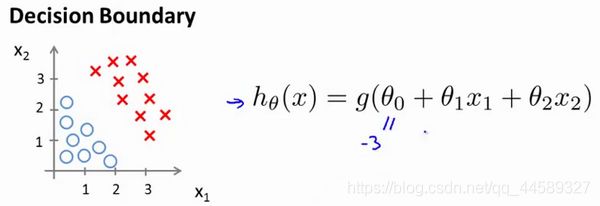
并且参数 θ \theta θ 是向量[-3 1 1]。 则当 − 3 + x 1 + x 2 ≥ 0 -3+{x_1}+{x_2} \geq 0 −3+x1+x2≥0,即 x 1 + x 2 ≥ 3 {x_1}+{x_2} \geq 3 x1+x2≥3时,模型将预测 y = 1 y=1 y=1。 我们可以绘制直线 x 1 + x 2 = 3 {x_1}+{x_2} = 3 x1+x2=3,这条线便是我们模型的分界线,将预测为1的区域和预测为 0的区域分隔开。
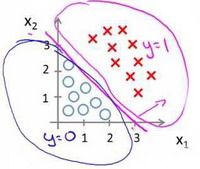
假使我们的数据呈现这样的分布情况,怎样的模型才能适合呢?

因为需要用曲线才能分隔 y = 0 y=0 y=0 的区域和 y = 1 y=1 y=1 的区域,我们需要二次方特征: h θ ( x ) = g ( θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 1 2 + θ 4 x 2 2 ) {h_\theta}\left( x \right)=g\left( {\theta_0}+{\theta_1}{x_1}+{\theta_{2}}{x_{2}}+{\theta_{3}}x_{1}^{2}+{\theta_{4}}x_{2}^{2} \right) hθ(x)=g(θ0+θ1x1+θ2x2+θ3x12+θ4x22)是[-1 0 0 1 1],则我们得到的判定边界恰好是圆点在原点且半径为1的圆形。
我们可以用非常复杂的模型来适应非常复杂形状的判定边界。
代价函数
对于线性回归模型,我们定义的代价函数是所有模型误差的平方和。理论上来说,我们也可以对逻辑回归模型沿用这个定义,但是问题在于,当我们将 h θ ( x ) = 1 1 + e − θ T x {h_\theta}\left( x \right)=\frac{1}{1+{e^{-\theta^{T}x}}} hθ(x)=1+e−θTx1带入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数(non-convexfunction)。

这意味着我们的代价函数有许多局部最小值,这将影响梯度下降算法寻找全局最小值。
线性回归的代价函数为:
J ( θ ) = 1 m ∑ i = 1 m 1 2 ( h θ ( x ( i ) ) − y ( i ) ) 2 J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{\frac{1}{2}{{\left( {h_\theta}\left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}} J(θ)=m1i=1∑m21(hθ(x(i))−y(i))2
我们重新定义逻辑回归的代价函数为:
J ( θ ) = 1 m ∑ i = 1 m C o s t ( h θ ( x ( i ) ) , y ( i ) ) J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{{Cost}\left( {h_\theta}\left( {x}^{\left( i \right)} \right),{y}^{\left( i \right)} \right)} J(θ)=m1i=1∑mCost(hθ(x(i)),y(i)),
其中
cost ( h θ ( x ) , y ) = { − log ( h θ ( x ) ) if y = 1 − log ( 1 − h θ ( x ) ) if y = 0 \operatorname{cost}\left(h_{\theta}(x), y\right)=\left\{\begin{aligned} -\log \left(h_{\theta}(x)\right) & \text { if } y=1 \\ -\log \left(1-h_{\theta}(x)\right) & \text { if } y=0 \end{aligned}\right. cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x)) if y=1 if y=0
这样构建的 C o s t ( h θ ( x ) , y ) Cost\left( {h_\theta}\left( x \right),y \right) Cost(hθ(x),y)函数的特点是:
当实际的 y = 1 y=1 y=1 且 h θ ( x ) {h_\theta}\left( x \right) hθ(x)也为 1 时误差为 0,
当 y = 1 y=1 y=1 但 h θ ( x ) {h_\theta}\left( x \right) hθ(x)不为1时误差随着 h θ ( x ) {h_\theta}\left( x \right) hθ(x)变小而变大;
当实际的 y = 0 y=0 y=0 且 h θ ( x ) {h_\theta}\left( x \right) hθ(x)也为 0 时代价为 0,
当 y = 0 y=0 y=0 但 h θ ( x ) {h_\theta}\left( x \right) hθ(x)不为 0时误差随着 h θ ( x ) {h_\theta}\left( x \right) hθ(x)的变大而变大。
将构建的 C o s t ( h θ ( x ) , y ) Cost\left( {h_\theta}\left( x \right),y \right) Cost(hθ(x),y)简化如下:
C o s t ( h θ ( x ) , y ) = − y × l o g ( h θ ( x ) ) − ( 1 − y ) × l o g ( 1 − h θ ( x ) ) Cost\left( {h_\theta}\left( x \right),y \right)=-y\times log\left( {h_\theta}\left( x \right) \right)-(1-y)\times log\left( 1-{h_\theta}\left( x \right) \right) Cost(hθ(x),y)=−y×log(hθ(x))−(1−y)×log(1−hθ(x))
带入代价函数得到:
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{[-{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)-\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]} J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]
即: J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) log ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J\left( \theta \right)=-\frac{1}{m}\sum\limits_{i=1}^{m}{[{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)+\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]} J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
在得到这样一个代价函数以后,我们便可以用梯度下降算法来求得能使代价函数最小的参数了。算法为:
Repeat { θ j : = θ j − α ∂ ∂ θ j J ( θ ) \theta_j := \theta_j - \alpha \frac{\partial}{\partial\theta_j} J(\theta) θj:=θj−α∂θj∂J(θ) (simultaneously update all ) }
求导后得到:
Repeat { θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_j := \theta_j - \alpha \frac{1}{m}\sum\limits_{i=1}^{m}{{\left( {h_\theta}\left( \mathop{x}^{\left( i \right)} \right)-\mathop{y}^{\left( i \right)} \right)}}\mathop{x}_{j}^{(i)} θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i) (simultaneously update all ) }
在这个视频中,我们定义了单训练样本的代价函数,凸性分析的内容是超出这门课的范围的,但是可以证明我们所选的代价值函数会给我们一个凸优化问题。代价函数 J ( θ ) J(\theta) J(θ)会是一个凸函数,并且没有局部最优值。
多类别分类
现在我们有一个训练集,好比上图表示的有3个类别,我们用三角形表示 y = 1 y=1 y=1,方框表示 y = 2 y=2 y=2,叉叉表示 y = 3 y=3 y=3。我们下面要做的就是使用一个训练集,将其分成3个二元分类问题。
我们先从用三角形代表的类别1开始,实际上我们可以创建一个,新的"伪"训练集,类型2和类型3定为负类,类型1设定为正类,我们创建一个新的训练集,如下图所示的那样,我们要拟合出一个合适的分类器。

为了能实现这样的转变,我们将多个类中的一个类标记为正向类( y = 1 y=1 y=1),然后将其他所有类都标记为负向类,这个模型记作 h θ ( 1 ) ( x ) h_\theta^{\left( 1 \right)}\left( x \right) hθ(1)(x)。接着,类似地第我们选择另一个类标记为正向类( y = 2 y=2 y=2),再将其它类都标记为负向类,将这个模型记作 h θ ( 2 ) ( x ) h_\theta^{\left( 2 \right)}\left( x \right) hθ(2)(x),依此类推。 最后我们得到一系列的模型简记为: h θ ( i ) ( x ) = p ( y = i ∣ x ; θ ) h_\theta^{\left( i \right)}\left( x \right)=p\left( y=i|x;\theta \right) hθ(i)(x)=p(y=i∣x;θ)其中: i = ( 1 , 2 , 3.... k ) i=\left( 1,2,3....k \right) i=(1,2,3....k)
最后,在我们需要做预测时,我们将所有的分类机都运行一遍,然后对每一个输入变量,都选择最高可能性的输出变量。
总之,我们已经把要做的做完了,现在要做的就是训练这个逻辑回归分类器: h θ ( i ) ( x ) h_\theta^{\left( i \right)}\left( x \right) hθ(i)(x), 其中 i i i 对应每一个可能的 y = i y=i y=i,最后,为了做出预测,我们给出输入一个新的 x x x 值,用这个做预测。我们要做的就是在我们三个分类器里面输入 x x x,然后我们选择一个让 h θ ( i ) ( x ) h_\theta^{\left( i \right)}\left( x \right) hθ(i)(x) 最大的 i i i,即
max i h θ ( i ) ( x ) \max _{i} h_{\theta}^{(i)}(x) imaxhθ(i)(x)
正则化
这样的结果是得到了一个较为简单的能防止过拟合问题的假设:
J ( θ ) = 1 2 m [ ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ ∑ j = 1 n θ j 2 ] J\left( \theta \right)=\frac{1}{2m}[\sum\limits_{i=1}^{m}{{{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})}^{2}}+\lambda \sum\limits_{j=1}^{n}{\theta_{j}^{2}}]} J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]
其中 λ \lambda λ又称为正则化参数(Regularization Parameter)。 注:根据惯例,我们不对 θ 0 {\theta_{0}} θ0 进行惩罚。经过正则化处理的模型与原模型的可能对比如下图所示:

如果选择的正则化参数 λ \lambda λ 过大,则会把所有的参数都最小化了,导致模型变成 h θ ( x ) = θ 0 {h_\theta}\left( x \right)={\theta_{0}} hθ(x)=θ0,也就是上图中红色直线所示的情况,造成欠拟合。 那为什么增加的一项 λ = ∑ j = 1 n θ j 2 \lambda =\sum\limits_{j=1}^{n}{\theta_j^{2}} λ=j=1∑nθj2 可以使 θ \theta θ的值减小呢? 因为如果我们令 λ \lambda λ 的值很大的话,为了使Cost Function 尽可能的小,所有的 θ \theta θ 的值(不包括 θ 0 {\theta_{0}} θ0)都会在一定程度上减小。 但若 λ \lambda λ 的值太大了,那么 θ \theta θ(不包括 θ 0 {\theta_{0}} θ0)都会趋近于0,这样我们所得到的只能是一条平行于 x x x轴的直线。 所以对于正则化,我们要取一个合理的 λ \lambda λ 的值,这样才能更好的应用正则化。 回顾一下代价函数,为了使用正则化,让我们把这些概念应用到到线性回归和逻辑回归中去,那么我们就可以让他们避免过度拟合了。
正则化线性回归的代价函数为:
J ( θ ) = 1 2 m ∑ i = 1 m [ ( ( h θ ( x ( i ) ) − y ( i ) ) 2 + λ ∑ j = 1 n θ j 2 ) ] J\left( \theta \right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{[({{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})}^{2}}+\lambda \sum\limits_{j=1}^{n}{\theta _{j}^{2}})]} J(θ)=2m1i=1∑m[((hθ(x(i))−y(i))2+λj=1∑nθj2)]
如果我们要使用梯度下降法令这个代价函数最小化,因为我们未对 θ 0 \theta_0 θ0进行正则化,所以梯度下降算法将分两种情形:
R e p e a t Repeat Repeat u n t i l until until c o n v e r g e n c e convergence convergence{
θ 0 : = θ 0 − a 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i ) ) {\theta_0}:={\theta_0}-a\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{0}^{(i)}}) θ0:=θ0−am1i=1∑m((hθ(x(i))−y(i))x0(i))
θ j : = θ j − a [ 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m θ j ] {\theta_j}:={\theta_j}-a[\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{\left( i \right)}}+\frac{\lambda }{m}{\theta_j}] θj:=θj−a[m1i=1∑m((hθ(x(i))−y(i))xj(i)+mλθj]
f o r for for j = 1 , 2 , . . . n j=1,2,...n j=1,2,...n
}
对上面的算法中$ j=1,2,…,n$ 时的更新式子进行调整可得:
θ j : = θ j ( 1 − a λ m ) − a 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) {\theta_j}:={\theta_j}(1-a\frac{\lambda }{m})-a\frac{1}{m}\sum\limits_{i=1}^{m}{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{\left( i \right)}} θj:=θj(1−amλ)−am1i=1∑m(hθ(x(i))−y(i))xj(i) 可以看出,正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令$\theta $值减少了一个额外的值。
我们同样也可以利用正规方程来求解正则化线性回归模型,方法如下所示:
