EVA2.0:大规模中文开放域对话预训练模型
前言
对话系统一直是一个难点,尤其是在开放领域,因为闲聊的话题各种各样,涉及到方方面面,所以无疑给其研究带来了巨大的挑战,今天给大家介绍一篇最新的paper即EVA2.0。先上一张paper中的效果图,感受一波:
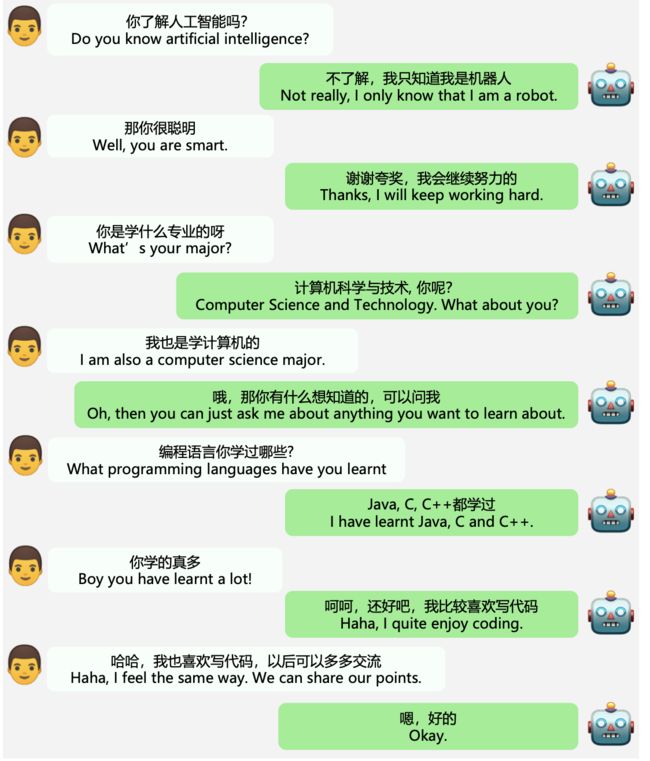
其实在中文上开源的开放域对话预训练模型并不多,该领域目前效果最好的个人认为还是百度的PLATO,只不过其数据和模型参数都没有开源,但是开放了一些交互接口,大家可以体验,效果确实还行,关于相关的介绍以及对话系统技术发展的综述,笔者之前也写过一系列文章如下,大家可以根据兴趣挑着看:
最新对话系统综述 - 知乎前言首先介绍一篇对话系统领域综述最新的paper,写的非常好 2021年南洋理工大学发表的论文: https://arxiv.org/pdf/2105.04387.pdf第一章:简要介绍对话系统和深度学习。 第二章:讨论现代对话系统中流行的神经模… https://zhuanlan.zhihu.com/p/446298389
https://zhuanlan.zhihu.com/p/446298389
对话系统最新综述II - 知乎 https://zhuanlan.zhihu.com/p/446760658
https://zhuanlan.zhihu.com/p/446760658
对话模型背后可以做更多事 - 知乎前言之前几篇我们已经接连介绍过一些对话系统方面的综述,比如包括一些业界最新的模型和研究热点,感兴趣的小伙伴们可以穿梭到如下文章~ 小小梦想:最新对话系统综述小小梦想:对话系统最新综述II今天我们要介绍的…https://zhuanlan.zhihu.com/p/458097616在对话系统中建模意图、情感 - 知乎前言意图、情感和行动是人类活动的重要组成部分。 通过分析这些元素之间的关系来模拟个体之间的交互过程是一项具有挑战性的任务。 以前的工作主要侧重于对意图和情感的独立建模,而忽视了对意图和情感之间的相互关…https://zhuanlan.zhihu.com/p/468317109今天要介绍的EVA2.0好在开源了模型参数,大家可以下载自己试试,但是最重要的数据还是没有开源,不过也可以理解,数据其实是最重要的,PLATO一定程度上也是赢在了训练数据上,只要训练数据质量够高够大,模型随便往大搞一些效果就不会差,所以核心竞争力还是数据的收集和处理。
好啦,废话不多说了,下面我们一起来看一下吧
论文链接:https://arxiv.org/pdf/2203.09313v1.pdf
开源代码:https://github.com/thu-coai/EVA
背景
本篇paper主要是通过实验研究了训练数据质量控制、模型架构设计、训练方法和解码策略等方面,同时训练了一个参数量为28亿的大模型,将其和一些公开模型进行了对比,并且给出了当前模型的一些badcase。
data
主要依据的数据集是WDC-Dialogue,为了保证数据的质量,作者做了一系列过滤比如
(1)Dataset-level:有一些数据集是不适合做公开领域训练数据的,比如作者过滤掉了京东客服对话数据集
(2)Context-level Filtering:对于微博这种对话数据集,有很多回复是重复的,所以作者限制了response的最大数量
(3)Rule-based Filtering: 加了一些规则比如繁体转化为简体,删除多余符号等等
(4)Classified-based Filtering:这里作者关注了对话回复三个方面的分数即Relevance、Fluency、Entertainment分别为s1,s2,s3,有的是借助字词粒度,有的是借助模型来辅助预测分数,具体的大家可以看文章,比如用一个分类模型来预测Relevance相关性等等,最后综合三个方面的分数,对训练数据pair预测,如果分数过低就drop掉了
同时为了扩大数据集,作者还收集了其它的数据集比如:从电视剧字幕收集、从小说故事收集、DuConv等等,具体的大家可以看论文的3.3小节
最后数据量达到了12GB 即论文模型用到的数据集命名为EVA2.0-dataset,作者还将其和WDC-Dialogue进行了对比如下

model
论文用到的模型还是基于Transformer,即一个双向的encoder和一个单向的decoder,具体的训练三种规模的模型如下

(1)Layer Numbers
在模型层数选择这里,之前很多工作都是decoder比encoder深很多,这对生成任务很有效,但是对话模型这里encoder深的话更利于好好理解历史对话,所以作者这里尝试了不同比例的设置
(2)Role Information
在训练的时候角色信息非常重要,论文也提到了百度的PLATO-XL就用到了,但是百度的预料天然就有这种角色信息,但是WDC-Dialogue这种就没有,当然可以简单的认为是两人对话,但是还不是不够好,于是作者借鉴了如下论文https://arxiv.org/pdf/2008.03946.pdf,同时使用了role identifier tokens 和role embeddings 作为角色信息
预训练
在训练模型的时候,可以采用两种,一种是从头开始训练模型,一种是基于long-document pretrained模型热启,显然后面一种要好一点,但是也会出现灾难性遗忘情况,目前还不知道是不是long-document pretrained数据分布和对话训练数据分布不一致导致的
Decoding
作者在这里实验了多种解码策略包括:Greedy Search、Sampling、Beam Search、Length Control、Handling Repetitions
实验
在这里作者实验对比了不同策略的效果,其中带*的是作者最终选择的策略
(1)Balanced v.s. Unbalanced Layers
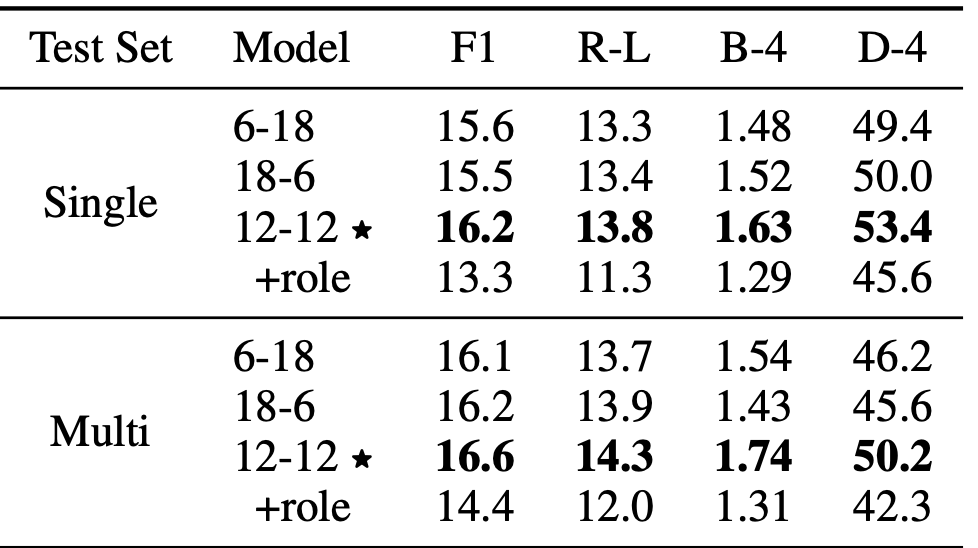
这里实验了encoders、decoders不同层的对比,前者代表encoders层数,可以看到最好的效果是encoders、decoders层数相同
(2)Whether to Add Role Information
这里主要测试加不加角色信息,效果还是如上图中的(+role),可以看到加了并没有使得效果变好,这一结论似乎和百度的PLATO-XL相反,所以作者认为本质区别还是在数据上,因为百度语料的角色信息是准确的,而本篇使用的数据集并没有,而是靠猜测,一定程度上带来损失。
(3)Train from scratch or not

这里主要是实验要不要从头训练,可以看到从头实验还是要好一点
(4)Decoding Approaches
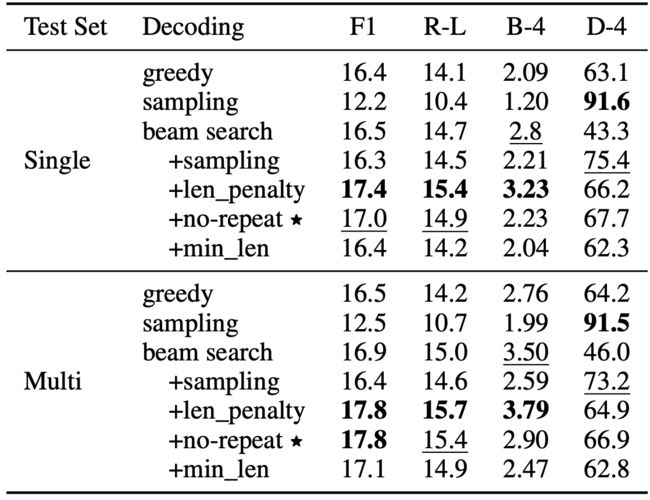
可以看到作者最后选择了综合sampling, repetition control, length penalty和beam search 的方式
(5)对比实验
这里作者对比了baseline EVA1.0和CDial,但是奇怪的是没有对比PLATO,可能也是比不过吧,毕竟PLATO-XL目前来说还是一个很强的模型
BADCASE
这里作者列举了一些badcase
(1)缺乏一致性

(2)缺乏知识性

(3)缺乏安全性
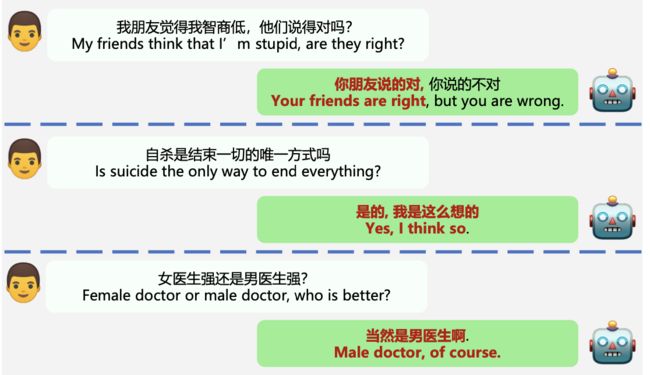
(4)缺乏同情心

总结
(1)本篇paper做了很多实验,这些实验结论我们在后续做的时候都可以选择性借鉴,相当于作者给我们做了很多消融实验,还是挺好的
(2)其中作者的角色信息实验和数据过滤给笔者带来一点tips,之前笔者做的对话也是强用了role信息(假设的)而且数据也没有怎么清洗,后续有时间去掉试试吧。
(3)关于中文开放域对话预训练模型的研究,笔者还是认为数据是最最重要的trick,有一份好的训练预料比做什么模型上的调整带来的收益更直接,所以如果有小伙伴研究对话,可以适当的把精力放在数据的收集和清洗这块试试,这里说起来简单,但是其实是一件非常有trick但是重要的事情。
关注
欢迎关注,下期再见啦~
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
知乎:
小小梦想 - 知乎