实例分割综述 | 近两年的SOTA汇总
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
全监督
YOLACT
YOLACT 主要贡献一是在 MS COCO 数据集上做出了第一个实时的实例分割模型;二是对模型的各种表现进行了评估;此外还提出了比 NMS 算法更快的 Fast NMS;
YOLACT 为了保证速度,设计了2个分支网络,并行地进行以下操作:
1、Prediction Head 分支生成各候选框的类别 confidence、anchor 的 location 和 prototype mask 的 coefficient;
2、Protonet 为每张图片生成 k 个 prototype mask。在代码中 k = 32。Prototype mask 和 coefficients 的数量相等。

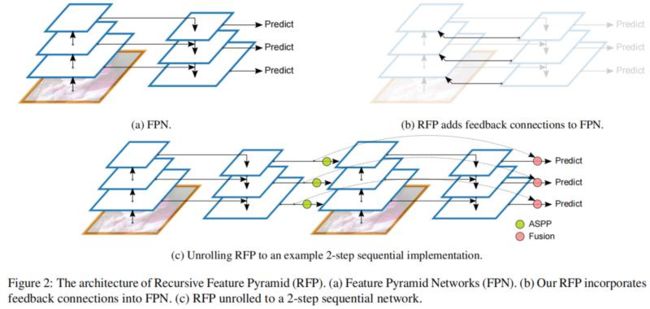
DetectoRS
许多目标检测器通过使用两次观察和思考的机制表现出出色的性能。在本文中,作者在目标检测的主干设计中探索了这种机制。
在宏观层面,提出了 Recursive Feature Pyramid,它将来自特征金字塔网络的额外反馈连接合并到自下而上的主干层中;
在微观层面,提出了 Switchable Atrous Convolution,它对不同 Atrous 率的特征进行卷积,并使用 Switch 函数收集结果。
将它们结合起来会产生 DetectoRS,它显着提高了目标检测的性能。
在 COCO test-dev 上,DetectoRS 实现了最先进的 55.7% 的Box AP,48.5% 的Mask AP,以及 50.0% PQ。
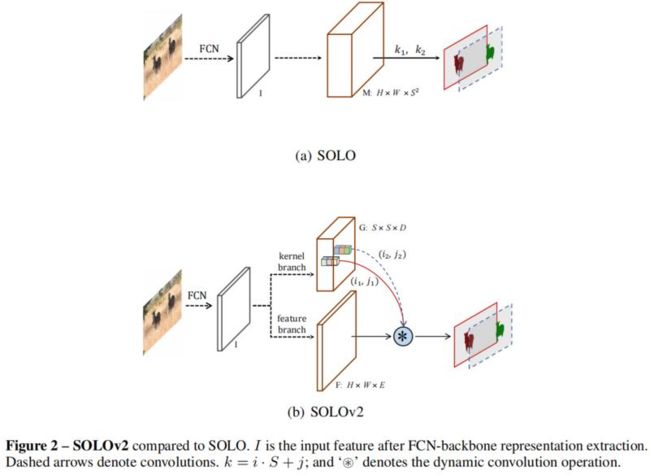
SOLOv2
SOLO(Segmenting Objects by Locations)算法的核心思想是将分割问题转化为位置分类问题,从而做到不需要 anchor(锚框)及 bounding box,而是根据实例的位置和大小,对每个实例的像素点赋予一个类别从而达到对实例对象进行分割的效果。
具体而言,就是如果物体的中心落在了某个网格内,该网格就负责预测该物体的语义类别,并给每个像素点赋一个位置类别。
在 SOLOv1 中有两个分支:类别分支和 mask 分支。类别分支预测语义类别;mask 分支则分割物体实例。同时,使用 FPN 来支持多尺度预测,FPN 的每一个特征图后都接上述两个并行的分支。
SOLOv2 继承了 SOLOv1 中的一些设定,将原来的 mask 分支解耦为 mask 核分支和 mask 特征分支,分别预测卷积核和卷积特征。
输入为 H×W×E 的特征,E 是输入特征的通道数,输出为卷积核 S×S×D,其中 S 是划分的网格数目。Mask 核分支位于预测 head 内,平行的有语义类别分支。预测 head 的输入是 FPN 输出的特征图。Head 内的 2 个分支都有 4 个卷积层来提取特征,和 1 个最终的卷积层做预测。Head 的权重在不同的特征图层级上共享。同时作者在 kernel 分支上增加了空间性,做法是在第一个卷积内加入了 CoordConv,即输入后面跟着两个额外的通道。
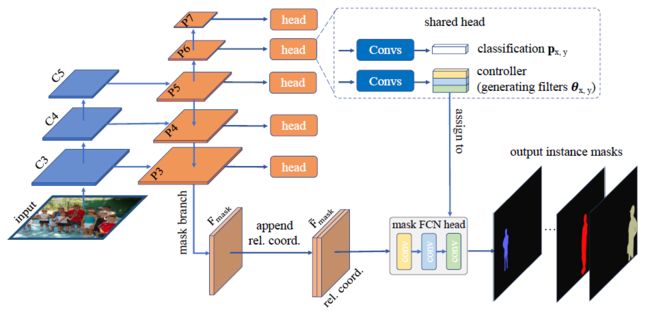
CondInst
CondInst有两个优点:
1)实例分割采用全卷积网络,消除了ROI裁剪和特征比对的需要。
2)由于动态生成条件卷积的容量大大提高,掩模前端可以非常紧凑(例如,3个卷积层,每个只有8个通道),从而大大加快推理速度。CondInst是一种更简单的实例分割方法,它可以在准确性和推理速度上都得到提高。在COCO数据集上,CondInst表现优于一些最近的方法,包括调优的Mask R-CNN,而不需要更长的训练时间。
本文主要贡献:
1)提出了CondInst实例分割框架,该框架比掩模R-CNN等现有方法的实例分割性能有所提高,同时速度更快。在精度和速度上都优于最近的最新技术。
2)CondInst是完全卷积的,在现有的许多方法中避免了调整大小的操作,因为CondInst不依赖于ROI操作。无需调整feature map的大小,就可以获得具有更精确边缘的高分辨率实例掩模。
3)与之前的方法不同,在掩模前端的过滤器对于所有实例在训练时是固定的,是动态生成和条件的实例。由于滤波器只需要预测一个实例的掩码,这在很大程度上减轻了学习要求,从而降低了滤波器的负载。因此,掩码前端可以非常轻,大大缩短了每个实例的推理时间。与bounding-box检测器FCOS相比,CondInst只需要增加10%的计算时间,甚至可以处理每幅图像的最大实例数(即100实例)。
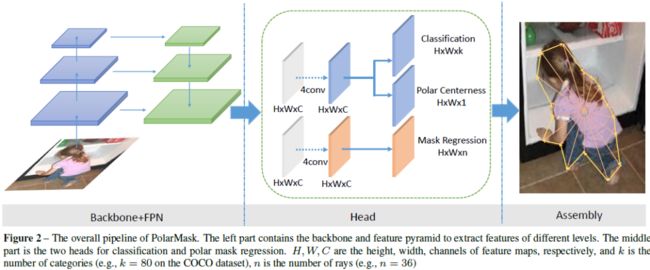
PolarMask
PolarMask 基于极坐标系建模轮廓,把实例分割问题转化为实例中心点分类(instance center classification)问题和密集距离回归(dense distance regression)问题。同时,本文还提出了两个有效的方法,用来优化high-quality正样本采样和dense distance regression的损失函数优化,分别是Polar CenterNess和 Polar IoU Loss。没有使用任何trick(多尺度训练,延长训练时间等),PolarMask 在ResNext 101的配置下 在coco test-dev上取得了32.9的mAP。这是首次证明了更复杂的实例分割问题,可以在网络设计和计算复杂度上,和anchor free物体检测一样简单。
MEInst
MEInst将掩码提炼为紧凑且固定的维度表示。通过使用 PCA 进行简单的线性变换,MEInst 能够将 28x28 的局部掩码压缩为 60 维的特征向量。该论文还尝试在FCOS上直接回归 28x28=784-dim 特征向量,并且在 1 到 2 个 AP 点下降的情况下也得到了合理的结果。
这意味着直接预测高维掩码并非完全不可能,但很难优化。掩码的紧凑表示使其更容易优化,并且在推理时运行速度也更快。它与 Mask RCNN 最相似,可以直接与大多数其他目标检测算法一起使用。
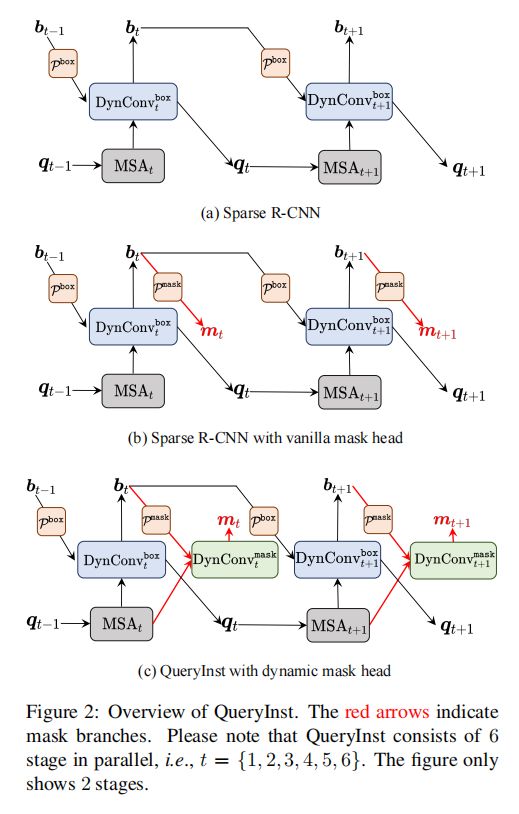
QueryInst
之前得分比较高的例如Cascade Mask R-CNN 、 HTC这类non-query范例如果直接放到以query为基准的检测器下是效率很差。
在这篇文章中作者提出了QueryInst,基于query的实例分割,通过在动态mask heads上并行监督驱动,使得mask 的梯度不仅可以回溯到骨架网络的特征提取器中,并且对于目标query而言,它也可以在不同阶段本质上是一一对应。这些queries隐式携带了多阶的mask信息,这些信息会在最终的mask生成器中被动态mask头里的ROI特征提取器所使用。并且,在不同阶段不同子任务例如目标检测和实力分割当中,queries不仅可以互相分享而且可以互相利用的,使得这种query将协调合作的机制充分发挥了。
总而言之,整个思路有以下优点:成功地在基于query的端到端检测框架中使用并行动态mask头的新角度解决实例分割问题;成功地通过利用共享query和多头自注意力设计为基于查询的目标检测和实例分割建立了任务联合范式;将QueryInst延展到例如YouTube-VIS数据集上,表现SOTA。
SOLQ
在本文中,作者提出了一个端到端的实例分割框架。基于最近引入的 DETR,本文的方法称为 SOLQ,通过学习统一query来分割对象。
在 SOLQ 中,每个query代表一个对象并具有多种表示形式:类、位置和掩码。学习到的对象query以统一的向量形式同时执行分类、框回归和掩码编码。
在训练阶段,编码的掩码向量由原始空间掩码的压缩编码监督。
在推理时,产生的掩码向量可以通过压缩编码的逆过程直接转换为空间掩码。
实验结果表明,SOLQ 可以实现最先进的性能,超越大多数现有方法。此外,统一query表示的联合学习可以大大提高DETR的检测性能。

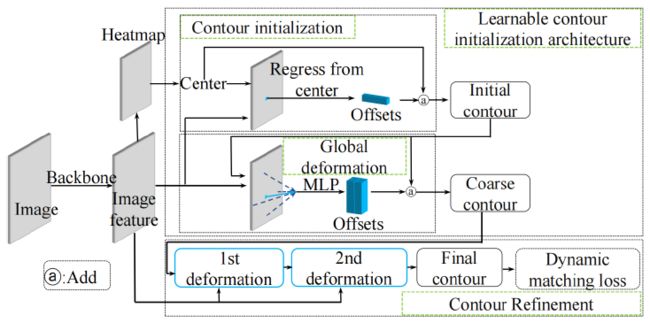
E2EC
基于轮廓的实例分割方法近年来得到了快速发展,但是由于特征粗糙和手工制作的轮廓初始化,限制了模型的性能,而需要经验的以及固定的后续预测-标签点配对又增加了学习难度。
论文提出了一种基于轮廓的高质量图像分割方法E2EC 。
1)首先,E2EC采用一种可学习的轮廓初始化体系来代替手工的轮廓初始化;
2)其次,本文提出了一种新的标签抽样方案,称为多方向配准,以减少学习困难;
3)第三,为了提高边界层的质量,本文动态匹配最合适的预测真值点对,并提出相应的损失函数,称为动态匹配损失。
实验结果表明,E2EC可以在KITTI实例数据集、Semantic边界数据集、Cityscapes数据集和COCO数据集上实现最先进的性能。此外,E2EC在实时应用中也很价值。
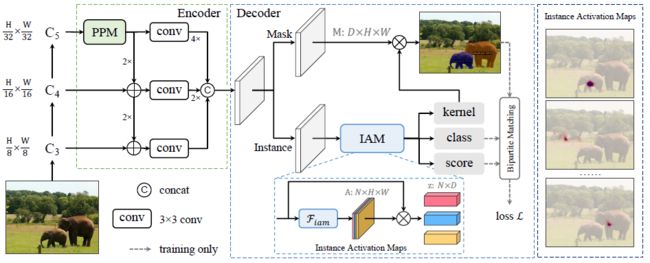
SparseInst
以前,大多数实例分割方法严重依赖于基于边界框或密集中心的对象检测和掩码预测。
本文创新点:论文提出了一种概念新颖、高效且完全卷积的实时图像分割框架,提出了一组稀疏的实例激活映射,作为一种新的对象表示,用于每个前景对象的高亮度信息区域。然后根据突出显示的区域聚合特征,获得实例级特征,用于识别和分割。此外,基于二分匹配,实例激活映射可以以一对一的方式预测对象,从而避免了后处理中的非最大抑制(NMS)。
实验结果:由于具有实例激活图的简单而有效的设计,SparseInst的推理速度非常快,在COCO基准上达到40 FPS和37.9 AP,在速度和准确性方面有明显优势。
弱监督
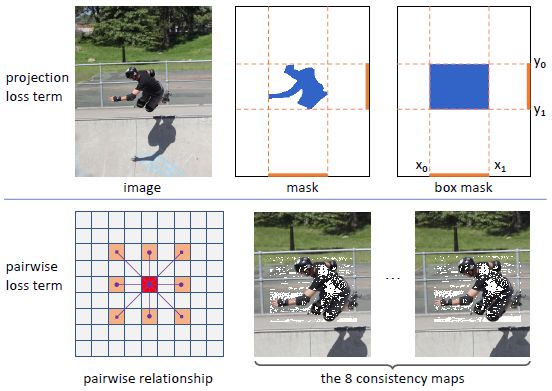
BoxInst
使用只有bbox标注的数据进行实例分割的训练。
Core idea:重新设计实例分割中learning mask的loss设计,没有对分割网络进行改进。
新的loss可以监督mask的训练,并且不会依赖于mask的annotation。
两个loss项:
1)最小化gt box的投影和pred mask之间的差异
2)Pair-wise Loss,利用先验:具有相似颜色的相邻像素之间很有可能来自于同一类。
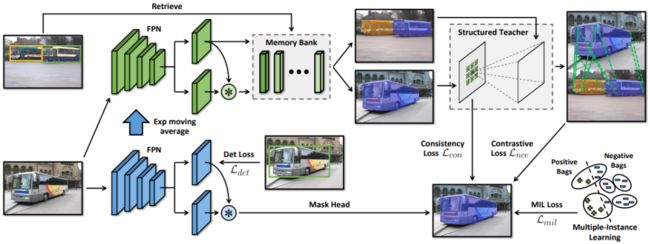
DiscoBox
为了加快注释过程, NVIDIA 研究人员开发了 DiscoBox 框架。该解决方案使用了一种弱监督学习算法,可以在训练期间输出高质量的实例分割,而无需掩码注释。
该框架直接从边界框监督生成实例Mask,而不是使用掩码注释直接监督任务。边界框作为一种基本的标注形式被引入,用于训练目标检测器。每个box对目标的定位、大小和类别信息进行编码。
边界框标注是工业计算机视觉应用的最佳选择。它包含丰富的图像信息,并且非常容易得到,使得在标注大量数据时,它更经济、更具可扩展性。然而,它本身不提供像素级信息,不能直接用于训练实例分割。
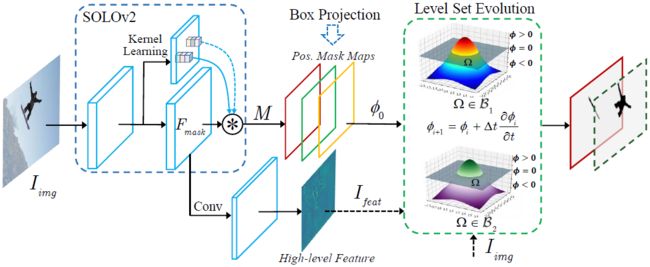
Box-supervised Instance Segmentation with Level Set Evolution
基于SOLOv2按位置动态分割目标并预测全图大小的实例Mask,为了促进框监督实例分割,本文将每个实例Mask视为其对应目标的水平集函数 φ。此外,本文利用输入图像和深层特征作为输入来进化水平集,其中使用框投影函数来鼓励网络在每一步自动估计初始水平集 φ0。每个实例的水平集都在框内迭代优化。
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
