机器学习特征处理详解与 tensorflow feature_column 接口实战
机器学习特征处理详解与 tensorflow feature_column 接口实战
书接上文,在 模型手把手系列 的 前两篇 文章 中,我们 已经 详细介绍 了 python、spark 和 java 生成TFrecord 和 六种方法构建读入batch样本 ,按照 常规 机器学习模型 pipline 的 流程 来说,我们应该在 使用 dataset 构建好的 batch 数据上开始 分别 对 读入的各个特征进行处理 例如 特征数值化、取embeding 等操作,然后 输入模型 的 过程 了,那么 本文 就从 这里开始 吧~
因为本系列 开发的模型 主要 使用的是 tensorflow ,而 tensorflow 官方 有着 自己实现的特征处理接口 feature_column ,非常好用 且 业界使用 的 非常广泛,这里 强烈 安利 下~ 。本文 这里 不欲对 feature_column 接口的 参数 做解释 ,而是 更侧重于 在 每一步得到 的 数据形式 做一些 说明,方便 我们 灵活对 数据 输入 进行定制 和 debug .
feature_column 接口 本来是 Google 为了 适配 tensorflow estimator 这个 模型训练 的 高阶接口 使用 的,但它 既然 能 方便处理特征 ,并且 特征处理 殊途同归 ,当然 我们也 可以将 feature_column 接口 配合 tensorflow keras 开发模型使用, 亲测 也 非常好用 哦。这里要 重点推荐 一下 estimator 接口,使用 estimator 开发的 单机版模型可以直接适配分布式 模型 训练,代码 无需怎么 改动,非常强大!!! 在本系列 后期 我们 也会写 几篇关于 使用 estimator 搭建 模型的文章,感兴趣 得 同学可以 关注下 后续的 文章 哦 ~
闲言少叙,下面 就让 我们 开始 本文的 机器学习 特征处理方法 介绍吧~
(1) 特征处理基础说明
在 深入浅出理解word2vec模型 (理论与源码分析) 文章中,我们说过 自从 2013年 embeding 诞生 以来 就被 业界的 深度学习模型 进行了 深入而广泛 的 应用,特别是在 高维稀疏的sparse ID 类特征 应用 特别 广泛。从 常规意义 上来 说,对于 推荐系统或广告算法 系统,百分之80 的 特征 均是以 高维稀疏 的 ID类 特征 的形式 出现的。所以 我们 开发 DNN 模型的时候,对于 高维稀疏 的 ID类特征 甚至是 用户历史 行为序列 特征,我们 总是 会 先以某种 方式 去 取得 该 ID 的 embeding , 然后 进行 加减乘或则拼接、求attention 等 花样的 骚操作。
在 企业级机器学习 Pipline - 特征feature处理 - part 1 文章中,我们 列出了 搜广推算法 中 经常用到 的 一些特征的 设计方法 包括: 交叉特征、序列特征、实时特征 等,错过 以前文章 的 同学,可以 戳进去 看看 哦 。从 上文中 我们 知道了 有哪些特征 可以用,但是 在 模型设计 中 真正的把 数据 以合适的格式 读进去 适配 模型设计 的需要,则是 有着 道与术 的 鸿沟。而 其实 在 模型开发 中,我们 大多数 时间 均是 花在了 模型 的 数据处理 上。
一般意义 上来说,对于 浮点数 特征,我们 可以用 一些方式 (例如 log / xgboost ) 进行 分桶 离散化 然后求 embeding 扔进 模型 里,或则 直接 读入 浮点数 将 它和 其它特征的 embeding 拼接后 传入网络 等。 但是 目前的 实验 来看,统计类的浮点数特征直接扔进模型效果提升总是不太明显。
而在 实际操作 中,对于 一些类别类型 的 category特征 ,我们 通常会 构建特有的 embeding matrix, 当然 我们 也可以 多个特征 共用一个 embeding matrix, 就像 后文 要介绍的 tf.feature_column.shared_embeddings。我们 可以将 用户 刚下载的 Appid 和 用户 最近3天打开过 的 appid 用一个 embeding 去训练 也是 一种 不错的选择 ,其可以 有效缓解 因 数据稀疏 导致的 训练不充分 的问题。
更细致 的说,要想 得到 某 ID 的 embeding, 我们通常 需要 根据索引 (ids)去 embeding matrix 中 查找(look_up) ,这里 我们 就 需要 先有这个 id,一般 这个id是数值 int型 的,而 我们 常规使用 的 高维稀疏 特征 大多 是 字符串 类型的sparse ID , 所以 常规情况 下我们 需要 去对 每一列特征 对应的 去维护 一个索引id ,id 和 该 特征 的 取值unique 个数 一一对应,一般 这个 过程 又称为 特征取值ID化 。我们 取出 该特征 对应的ID 对应的 embeding , 将 高维sparse特征转化为低维的embedding ,则可以 进行 模型 数据 的 语义计算 了。
如 上文 所说 ,在 特征取值ID化 这一步,如果 我们的 模型 中 特征的取值个数 和 特征种类个数 非常多 的话,我们 就需要 每天 去对 每列特征 的 旧的ID集合上 加上 新增的 特征取值 并 重新构建索引 输入模型 中 训练,多个特征 均 需要 如此,对于 搜广推模型 上 动则上亿 的 稀疏特征 来说,可以想象 这是一个 非常复杂 且 难以 持久维护 的 工程,而 早期的 很多大厂 的 dnn 模型均是如此处理的,可怕 ~
好在 tensorflow 中提供了 feature_column 接口,它可以 支持 将 每个 特征hash 后 快速得到 一定数值的 索引id , 该特征 空间大小 可以 自行定制。既然是 hash ,肯定 避免不了冲突,这里 我们 不在展开,自己根据 业务 调整 hash空间大小 即可。 类似的 特征ID化 工具,我知道 百度 的 paddelpaddle 深度学习框架 中 也有 类似的 hash函数 的 设计。
既然是说 feture_column ,我们就不得不祭出这张图了。
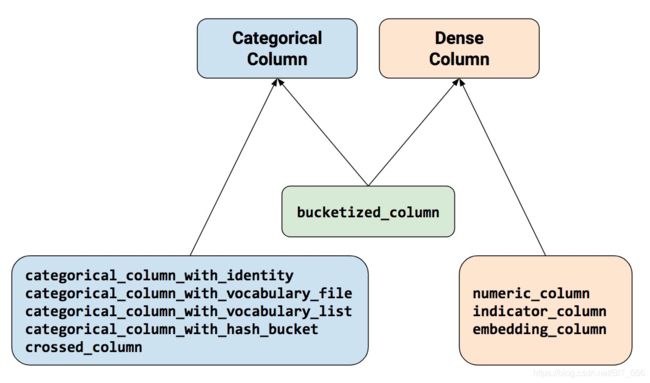
从 上图中 我们 可以知道,feature column 处理特征 可以分为 Categorical Column 和 Dense Column 两大类,这其实 和 我们 前面介绍 的 特征总共 分成 dense 和 sparse 两类特征 是 一个意思。 当然,图中的 一些接口 在 某些场景 里 需要 组合使用 ,也和我们上文 介绍的 特征处理 流程 差不太多。而一列特征要想接入DNN模型,则需要 先转化 为 DenseColumn 才可以。至于 如何组合 ,在下文 我们 会 进行 一些说明,但是从 数据取值类型 和 我们 自己的 先验知识 ,推断 出来 某个位置 取值 应该是 什么 类型 和 形状 也是 不难 的~
当然 除了 图中 的 一些接口 之外,feature_column 还有一些 以 sequences开头 的 处理序列特征 的接口,我们的 文章中,一直 强调了 序列特征 的 重要性,因为 序列特征 的 出现 让我们 不再是 孤立的 看待 用户的行为,而是在 时间序列 上 连续的 建模用户的 特性和偏好,用 历史的、发展的,普遍联系 的 眼光 来 分析 用户,在 工业实践 中 具有 举足轻重 的意义。后面 我们 也会写 一些 介绍序列建模 的 文章,感兴趣 的 同学可以 持续关注 下哦。
这里 需要注意 的一点是:feature_column 接口在tensorflow 1.x 系列和 2.x 系列 均有支持,但是也有一些 细微的 差别。对于普通特征,在 tensorflow 1.x 中,我们可以 通过 tf.feature_column.input_layer 处理 features 得到 dense feature,而 序列特征 可以使用 tf.feature_column.sequence_input_layer。但是在 2.x 中,该 接口 均不在支持 。在2.x 中 改为了 通过 tf.keras.layers.DenseFeatures 处理 features 得到 dense feature,序列 特征 可以 通过 tf.keras.experimental.SequenceFeatures 来 得到。而我们 下文的 代码 均是 基于 tensorflow 2.x 开发的。
其实要想对 tensorflow 的 使用 与 设计思想 进行 更深入 的了解,我们 可以 直接 去看 源码 ,源码 的 说明非常详细 ,并且 对 参数进行了 保姆级 的 说明,还列举出了 使用的demo。 具体路径见下面这2个链接:
源码地址 tensorflow源码
接口介绍 feature_column接口介绍
好吧,文字部分 就 这些吧,代码才是硬通货,接下来 就让 我们 一起开始 接口 的 更进一步 的 代码介绍吧~
(2) 代码时光之 feature_column使用说明
我们 这里 只挑一些常用 的 接口说明,主要涵盖 数值特征处理接口、类别特征hash化 接口、序列特征和dataset结合使用 方法、特征交叉、embedding共享等,而其他 的 类似接口 则 可以 常规类比推算 过去哈。
毕竟 万变不离其宗,掌握 数据的流程以及各阶段数据的形式比会用多少接口更加重要 。我们 会在 介绍接口 的时候 说明 该接口 的 适用场景,注意 看旁白 哦~
(2.1)numeric_column
@ 欢迎关注作者公众号 算法全栈之路
import tensorflow as tf
number = tf.feature_column.numeric_column("price")
price_feature_dict = {"price": [[2.0],[3.0],[4.0]]}
# 用这种数据解析方法来解析dict数据
# 这里感觉更像是定义了一种数据解析方法
output = tf.keras.layers.DenseFeatures(number)(price_feature_dict)
print(output)
从名字 我们 就可以 numeric_column 可以读入 数值类型 的特征 ,我们输入 统计类的浮点数 特征或则 其他 不需要 分桶、且 也不需要 embeding 的 特征 可以 使用。
这里我们可以重点看一下:output 返回的就是一个 浮点数tensor, 维度 没有 改变。
我们使用 tf.feature_column.numeric_column 接口 定义了 处理 price 列 字段 的方法,这个方法 返回的值,我们可以通过 tf.keras.layers.DenseFeatures 接口( tensorflow 2.x 支持 ) 来查看。而 tf.keras.layers.DenseFeatures(number) 到 这里 整体( 包括((number)) )其实 就定义了 对 该列特征 的 处理方法, 后面括号 里的 (price_feature_dict) 是 这个方法 的 输入参数 。
这里我们 刻意 把分行的 写法 合并在了一起,方便理解:注意 两个括号 的 连接,第一个括号 是 给方法用的,是 处理方法 的 一部分。第二个括号 才是 根据输入 得到 具体的值 ,并用 前面定义的方法 来 处理该输入值 。整体 来看 就是: 对输入特征的某个字段定义了一种什么处理方法。
因为 tensorflow 2.x 支持 eager 模式,所以输出 变量取值 就和 python一样,直接 打印变量 就 OK。
这里 插入一个深坑, 可能 引起 bug 的 地方 就是: 我们 使用 简单 自定义数据 测试接口 和 使用 dataset 数据 测试的 时候,略有不同 。注意看:代码里的 price_feature_dict 就是 我们 输入 的特征,这里要 注意 每一个元素都是被[]包裹着的([2.0]), 是一个数组,而我们上一篇文章 tensorflow 六种方法构建读入batch样本(含序列特征处理),踩坑经验值得收藏 介绍的 batch 数据里,每一列 特征 都是 仅仅 只有数值,不被 [] 包裹,在 tensor 的 世界里也就是 维度上少了一维 。
解决方法 就是:在上一篇文章里介绍的 train_raw_dataset 后面 可以接入 这段代码 就可以在 dateset 上 测试代码 运行通过:
@ 欢迎关注作者公众号 算法全栈之路
final_dataset = train_raw_dataset
.apply(tf.data.experimental.ignore_errors())
.shuffle(2).
.batch(BATCH_SIZE, drop_remainder=True)
.repeat(NUM_EPOCHS)
.prefetch(tf.data.experimental.AUTOTUNE)
上面是 一个插曲,仅仅 是 为了说明 批量跑模型的时候,数据格式 略有不同 而已。如果你 不用 dataset 读入 数据 来测试 这个接口 则不用关注。
上面 打印的 output 输出的 最后 返回数据 长这样:

(2.2) bucketized_column
@ 欢迎关注作者公众号 算法全栈之路
import tensorflow as tf
age_feature_dict = {"age": [[2.0],[3.0],[4.0]]}
age_bucket = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column(key='age', shape=(1,),default_value=0,dtype=tf.dtypes.float32),boundaries=[20, 40, 50, 60])
feature_layer = tf.keras.layers.DenseFeatures(age_bucket)
output = feature_layer(age_feature_dict)
print(output)
# 返回的是onehot值,维度改变
这里的 bucketized_column 接口 很好理解,就是 根据 接口限定 的 边界(boundaries) 进行分桶。对于 浮点数类型 的 特征,我们 需要分桶的,这里 给定分桶边界 就 可以 了。
注意 分桶 是 基于 数组比较 的,所以 这个 接口 需要先将 输入数据 确定为 数值 才能 进行 比较分桶,所以 只能 和 2.1 介绍的 numeric_column 一起 组合使用。 接口 一起组合 使用 在 feature_column 处理 接口 中是 非常常见 的。
这里 我们要 更详细 的 赘述 一下: bucketized_column 返回的 是 和 boundaries 维度 大小 相同的 onehot 数组。数值 落在 哪个区间,则 那个维度 的 取值为 1,其他维度 为0 。
拿到了 onehot 之后,当然我们后边也可以在接入 embeding_column 得到 embeding之后, 通过 DenseFeatures 将 具体的 embeding 展示 出来。这里没有接入 embeding_column 而直接接了 DenseFeatures ,所以返回的是 onehot 。
(2.3) categorical_column_with_identity
@ 欢迎关注作者公众号 算法全栈之路
import tensorflow as tf
features = {'video_id': tf.sparse.from_dense([[2, 85, 0, 0, 0],[33,78, 2, 73, 1]])}
video_id = tf.feature_column.categorical_column_with_identity(
key='video_id', num_buckets=100,default_value=0)
# 说明 sparse tensor 可以直接传入categorical_column_with_identity
# 后面直接接入 embedinig
columns = [tf.feature_column.embedding_column(video_id, 9)]
input_layer = tf.keras.layers.DenseFeatures(columns)
dense_tensor = input_layer(features)
print(dense_tensor)
categorical_column_with_identity 可以 返回 onehot 数据,我们使用 dd=tf.feature_column.indicator_column(video_id) 将 dd 塞入 DenseFeatures 中查看。这里是 序列数据,所以 返回的是 multI hot 形式 的数据。 这个 接口 使用的 非常广泛, identity 属于 直接类型 , 无需 映射 ,直接 输入 类别。
这里我们可以看到 tf.sparse.from_dense 是将 输入的 dense 数据 转成了 sparse tensor 的 格式。 我们知道:sparse 和 dense 其实描述的是同一份数据,只是用的是不同的形式。
从 上面的 代码 我们 也可以 看出:sparse tensor 可以直接传入categorical_column_with_identity 。这就 非常强大 了,因为 我们在 很多时候用 tf.string_split() 返回的就是 sparse tensor 的格式,这样 我们 就可以 处理 变长字符串 了。用 tf.string_split() 切割 字符串,然后 扔进
categorical_column_with_identity ,后面 再 接入 embeding_column 拿到 embedinig ,这 数据不是 处理的 一气呵成,非常丝滑 吗 ~
同时 sparse tensor 数据也可以直接接入 tf.keras.embeding 哦,非常好用哦!!!
(2.4) categorical_column_with_hash_bucket
@ 欢迎关注作者公众号 算法全栈之路
hash_word = tf.feature_column.embedding_column(
tf.feature_column.categorical_column_with_hash_bucket(key='adid',
hash_bucket_size=100, dtype=tf.dtypes.string),4)
feature_dict = {"adid": ["20", "127", "51", "3"]}
feature_layer = tf.keras.layers.DenseFeatures(hash_word)
output = feature_layer(feature_dict)
print(output)
# 在这里将 embedding_column 换成 indicator_column 列将能看到返回的是 onthot
这个 接口 应该是 算法工程师们 使用的 最多 的 接口 了, 顾名思义 ,将 类别id类 的 特征hash数值化 。在这里 tf.feature_column.categorical_column_with_hash_bucket 返回的 是 onehot 或则 sparse tensor 。onehot 或则 sparse tensor 在 这里 并没有 严格的区分,均可以 打印 出来 查看 格式。
本事例中,output 最后输出embeding 长这样:

这些 接口中 ,不带 sequences开头 的接口,一般都是 使用 单列 特征 定长 的 使用,并且 大多数时候 一列特征都是一个取值。categorical_column_with_hash_bucket 这个接口 比较强大 的一个 功能 就是 他也可以处理 多个取值的 multi hot 的类别特征,或则 称为 序列特征。 我们可以使用下面的代码来进行验证:
@ 欢迎关注作者公众号 算法全栈之路
hash_word = tf.feature_column.indicator_column(
tf.feature_column.categorical_column_with_hash_bucket(key='id',
hash_bucket_size=10, dtype=tf.dtypes.string))
feature_dict = {"id": [["20","21"],["127","128"] ,["51",'52'], ["3","4"]]}
feature_layer = tf.keras.layers.DenseFeatures(hash_word)
output = feature_layer(feature_dict)
print(output)
# 在这里将 indicator_column 换成embedding_column 列将能看到返回的是和 onehot 一样格式embeding .
这里,我们直接使用 indicator_column 返回了 categorical_column_with_hash_bucket 处理多取值 list 返回的 multi hot ,长这样:

在这里将 indicator_column 换成 embedding_column 列 将 能看到 返回的 是 和 上面事例代码的单列一个特征的数据一样格式embeding 。

这里明明 id 里输入 了多个取值,也返回了 multihot , 为啥 最后 返回得 embeding 确是 和 onehot 维度一样呢? 原来是因为: embedding_column 默认对多个取值返回的 embeding 进行了combine, 默认的 combine 方式 是 mean.
(2.5) categorical_column_with_vocabulary_file
@ 欢迎关注作者公众号 算法全栈之路
import tensorflow as tf
features = {'sex': tf.sparse.from_dense([["male"],["female"]])}
sex_col = tf.feature_column.categorical_column_with_vocabulary_file(
key='sex', vocabulary_file='./voc.txt', vocabulary_size=2,
num_oov_buckets=5)
sex_emb=tf.feature_column.embedding_column(sex_col, 4)
columns = [sex_emb]
input_layer = tf.keras.layers.DenseFeatures(columns)
dense_tensor = input_layer(features)
print(dense_tensor)
这里除了使用 hash 的方式 进行 特征取值id化 之外,我们也可以使用 categorical_column_with_vocabulary_file 手动的 维护 一个 字典文件 ,达到 和 上文 最初 介绍的 手动维护 id索引 的 古老做法 类似 的 功能。在 voc.txt 字典 文件 中,我们 只要 每一行放入一个特征的原始取值 即可,这个 接口 会 自动 将 原始特征 的 取值 映射 成 索引ID ,非常强大 哦,在 某些场景 下,我们还是 使用 的 非常多 的。
当然,这里的 文件路径 不仅 可以是 单机版本 的 pc路径,也可以是 保存 在 大数据集群 上的 hdfs路径 哦 。
对于 feature_column 众多接口中,以 *_with_vocabulary_file 结尾 的 接口, 均可以 使用 这里 说明 的 类似的 做法 进行操作,其他的接口 我就 不在赘述 了。
(2.5) sequence_categorical_column_with_hash_bucket
@ 欢迎关注作者公众号 算法全栈之路
import tensorflow as tf
# 定义特征列
click_history_feature_col = tf.feature_column.sequence_categorical_column_with_hash_bucket('click_list', hash_bucket_size=100, dtype=tf.int64)
click_history_embedding_col = tf.feature_column.embedding_column(click_history_feature_col, dimension=16)
columns = [click_history_embedding_col]
# 定义特征层
list_layer = tf.keras.experimental.SequenceFeatures(columns)
max_len=5
# 对于每个特征需要构建一个dict
list_dict = dict()
list_dict["click_list"]=tf.keras.Input(shape=(max_len,), dtype=tf.int64,name="click_list")
# dict里只有一个元素,然后可以
sequence_input, sequence_length=list_layer(list_dict)
sequence_length_mask = tf.sequence_mask(sequence_length)
print("sequence_input:",sequence_input.shape)
print("sequence_length_mask:",sequence_length_mask)
# reduce_mean 的时候,要注意考虑 batch_size 的维度为0,后面第一层括号的维度为1
embeding_mean = tf.reduce_mean(sequence_input,1)
print("embeding_mean:",embeding_mean)
#接一层全链接层
den = tf.keras.layers.Dense(10, activation="relu", name="dense1")(embeding_mean)
model_outputs = tf.keras.layers.Dense(1, activation="sigmoid", name="final_sigmoid")(den)
model = tf.keras.Model(inputs=[list_dict["click_list"]],outputs=model_outputs)
# model.summary()
model.compile(optimizer='adam',loss="binary_crossentropy",metrics=['accuracy'])
model.fit(final_dataset, epochs=2)
顾名思义,这个接口 是以 sequence_categorical_column_* 开头的,就是 feature_column 提供的 众多 处理序列特征 的 接口中 的一个。 序列特征 表示 特征的取值 是一个 list或则 数组 。
上面的代码是一个 feature_column 和 tensorflow keras 结合使用 进行 特征处理 和 模型开发 的 完美样例代码。对于这个 事例,我将 keras 的 数据读入 也接 进来了。
中间一个隐藏的深坑是 :使用 tf.keras.Input 和 input_layer 结合 将 特征数据 进行 固定形式 的 处理 的 时候,要求 input_layer 后面 跟着的 keras_input 数据 必须是一个 字典类型 。按照上面 我 提供 的 demo 的 同样做法,字典里仅仅放入了一个字段,然后作为参数传递给 特征处理输入层 input_layer , 他大爷的,深坑啊!!!当初 花了老大时间解决 这个问题, 写到 这里 希望确实 可以 帮到 还在 困惑中 的 老哥,觉得有用 就帮忙 关注转发 一下 吧~
demo 里 我们 直接接入了 上面所说的 final_dataset 的 dataset ,是一个 相对完整的工程实例 。我们 通过 batch 数据来训练 模型,在dataset 的 click_list 列,我输入的是一个python 数组。
这里要 注意 到是: click_list 我是padding 之后的,填充得最大长度是 5 , 是 定长的list .所以这里也是5 , 代码里是 tf.keras.Input(shape=(max_len,)。
中间部分,我们使用了 tf.keras.experimental.SequenceFeatures 来 将 embeding_col 接入网络,取代了以前 tensorflow 1.x 系列 的 tf.feature_column.sequence_input_layer,和 前面开篇 的 时候说 的 是一个意思。
(2.6) shared_embeddings
在某些场景下,我们 也许有 多列的 field 的特征 需要 **共用一个 shared_embeding&& , feature_column接口 下的 shared_embeddings 可以帮助我们实现。
@ 欢迎关注作者公众号 算法全栈之路
# tf.enable_eager_execution()
# 在tensorflow 2.x 中需要关闭eager
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
tf.compat.v1.reset_default_graph()
# 特征数据
features = {
'department': ['sport', 'good', 'drawing', 'gardening', 'travelling'],
'display': ['sport', 'yellow', 'light', 'sex', 'bad'],
}
# 特征列
department_hash = tf.feature_column.categorical_column_with_hash_bucket('department', 10, dtype=tf.string)
display_hash=tf.feature_column.categorical_column_with_hash_bucket('display', 10, dtype=tf.string)
# print(department_hash)
columns = [department_hash,display_hash]
share_columns = tf.feature_column.shared_embeddings(columns, dimension=4,shared_embedding_collection_name="share_embeding")
# 这里2个 ids 共同构建了一个 share embeding column, 查找的时候,使用公共的variable 查找值。
share_input_layer = tf.keras.layers.DenseFeatures(share_columns)
dense_tensor = share_input_layer(features)
print(dense_tensor)
这里 需要 注意 的 tensorflow 2.x 使用 shared_embeddings 得话,需要 关闭 eager 模式,源码里有说明,应该是 底层有冲突 吧。我们 可以使用 tf.compat.v1.disable_eager_execution() 方法 关闭eager 模式。

并且 需要注意 的一点 是:最后返回的 dense_tensor 得维度,在我们的例子中是:Tensor("dense_features/concat:0", shape=(5, 8), dtype=float32)。
对 组合 成 共享embeding 集合的每一个元素,均 返回一个embeding , 因为 department_hash 和 display_hash 在batch size 一致,这里均是5,而 8 则是因为 shared_embeddings 得 每一条 embeding 是 拼接了 2类 得2个 dim =4 的embeding . 用源码里的解释是:

返回 embeding 顺序 和 输入的 categorical_column 时候 顺序 致 。
(2.7) crossed_column
@ 欢迎关注作者公众号 算法全栈之路
# 这里要求我们输入特征名称,而不能是categorical_column_with_hash_bucket,官方解释说是会增加冲突。
cross_column = tf.feature_column.crossed_column(["department","display"], 100)
cross_emb=tf.feature_column.embedding_column(cross_column, 4)
# sparsetensor 直接接入 denseFeatures
cross_input_layer = tf.keras.layers.DenseFeatures(cross_emb)
dense_tensor = cross_input_layer(features)
print(dense_tensor)
我们 知道 单列特征 仅仅 从 一个维度 刻画用户,而 交叉特征 则是可以 从 交叉的 多列特征中 综合 刻画用户行为 ,例如 刻画情人节 这个日期 和 情趣内衣裤 的 购买记录 之间的 关系,是不是 更能描述 和 反映 某位美女 帅哥 对 某件衣服 的 购买意愿 呢。
在 搜广推算法 的 实际 使用场景 中,我们 会 遇到 大量的交叉特征 。对于 交叉特征列,我们 可以 输入原始单列特征 得到 embeding 之后,使用 embeding 相乘 或则 对位乘 或则 别的 什么做法 达到 综合 两个特征 建模的 目的,我们 也可以 在 离线 使用 spark 进行简单 的 字符串拼接 来达到 高维离散 特征 特征交叉 的目的。本文这里 介绍 了 tensorflow 提供的 一种新的 解决 方案 。

feature_column 里 提供的 特征交叉接口 crossed_column ,看官方 介绍是 将 特征取值之间做了 笛卡尔积 之后在对 组合好的字符串进行hash操作,将交叉的操作放在了tensorlfow 自己的特征处理过程中,在大数据之后,模型之前。
注意,这个接口 返回的 是一个 交叉特征列类 (_CrossedColumn), 后面 依然 需要 接 indicator 或则 embeding 层 输入 后面 的 模型。这个 接口 最后 底层 调用的 是 sparse_cross_hashed 这个 方法 做的 交叉操作,感兴趣 的可以 去 前面提供 的 源码地址 去 一层一层 点开 看看 哦。
本文到这里,本文共介绍了 7种 tensorflow feature_column 提供的 常用接口,中间 也穿插 介绍了 很多 特征处理 技巧 和 踩坑 经验,具有 很高的 参考价值 哦。如果 你 还有问题,欢迎 关注作者 的 公众号 留言 一起讨论 哦 ~
到这里,机器学习特征处理详解与 tensorflow feature_column 接口实战 的 全文 就 写完 了。本文代码 每个模块 均 可以 独立 跑 成功, 中间序列特征 处理模块 是一个完整的 feature_column结合keras 开发模型 的 优秀 式例,希望 可以 对 你 有 参考作用 ~
码字不易,觉得有收获就动动小手转载一下吧,你的支持是我写下去的最大动力 ~
更多更全更新内容,欢迎关注作者的公众号: 算法全栈之路
