算法入门(java)
想用Java快速入门算法?这篇文章你得看!
提示:本文章适合想要入门算法,并且想 “快速” 达到一定成果的同学们阅读~ (不定期补充笔记)
文章非常非常非常长!!! 阅读需先看 “前言” 部分!!!
文章目录
- 想用Java快速入门算法?这篇文章你得看!
- 前言
- 一、注意事项
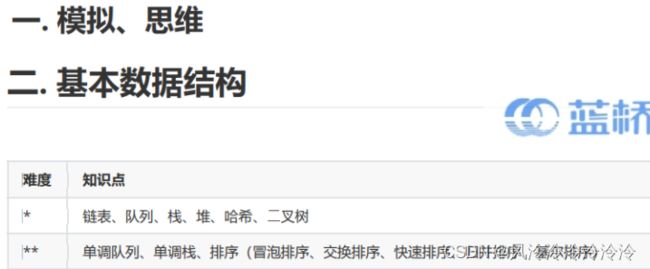
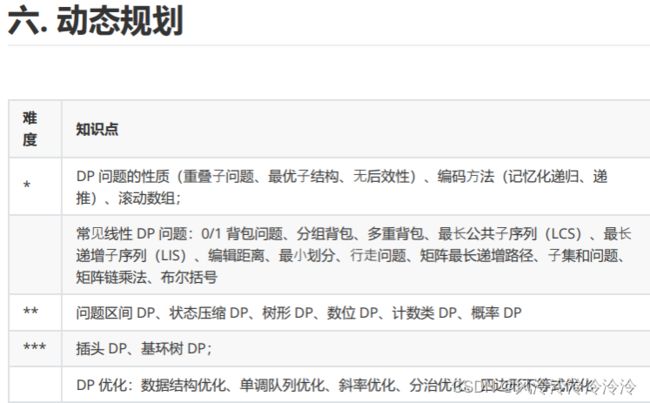
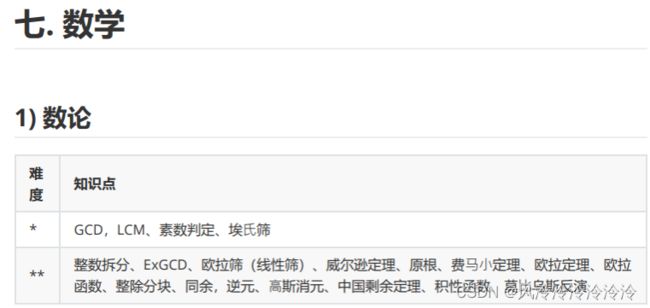
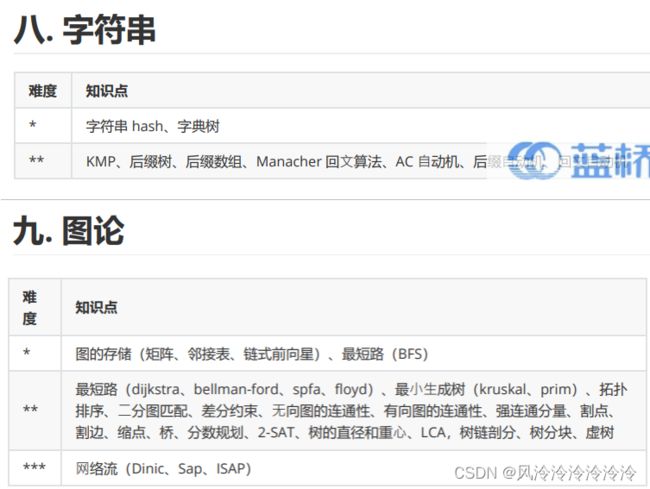
- 二、命题范围
- 三、快捷键系列
-
- Idea快捷键
- Eclipse快捷键
- 四、常用知识点、思想、套路(重点一)
-
- 多提取方法:
- double科学计数eN
- 流程控制
- Three_Dimensional_Array (三维数组)
- Scanner
-
- 0、无限输入,回车结束
- 1、输入整数、字符串数组
- 2、输入二维数组
- 3、输入字符串
- 4、输入字符串分割为数组
- 5、连续输入数字和字符串
- 6、换行输入数字和字符串
- 7、换行输入数字和字符串(需要包含空格)
- 日期类Date(时间戳)
- 日历类Calendar
- String
- Math
- 位运算
-
- 1.什么是位运算
- 2.位运算有哪些
- 3.常用的位运算操作
- 循环
- 类型
- Arrays类
- 数论
- 格式控制
- 输入字符数组
- 使用Iterator迭代器遍历容器ArrayList
- IO快速读写
- 无穷大的坑!
- 坐标存储小技巧
- 集合排序
-
- 排序操作
- 查找、替换
- Pattern类的使用(匹配正则表达式)
- 进制转换(x进制转10进制,10进制转y进制)
- 因子组合
- 五、Algorithm(重点二)
-
- 快速幂
- 素数筛法
-
- 埃氏筛
- 欧拉筛(最快)
- 双指针(链表)
- 前缀和 与 差分
-
- 前缀和(一维)
- 前缀和数组(二维)
- 前缀和的应用
- 二分(非递归)
- 递归
- DFS
-
- 八皇后问题
- 迷宫问题
- 马踏棋盘(贪心优化)
- BFS
-
- 走迷宫
- KMP
-
- KMP字符匹配
- 综合代码
- 动态规划(dp)
-
- 爬楼梯问题:
- 最大的子串(连续)和:
- 长的升序子序列(可以不连续):
- 01背包问题:
- 完全背包问题:
- 多重背包问题:
- 分治
- 贪心
- Prim(普利姆)最小生成树
- Kruskal(克鲁斯卡尔)最小生成树
- Dijkstra(迪杰斯特拉,得到某个点到各个点之间的最短距离)
-
- 朴素dijkstra(容易爆栈)
- 堆优化的dijkstra(链式前向星)
- Floyd(弗洛伊德,得到各个点到各个点之间的最短距离)
- 图论
-
- 图的深度优先遍历介绍深度优先遍历算法步骤
- 广度优先遍历算法步骤
- code
- 并查集
-
- 种类并查集
- 常用函数
- 常用容器
-
- ArrayList:底层是一个数组,擅长数据的查找(访问)
- LinkedList:底层链表,擅长数据的修改(包括数据添加和删除)
- Queue:队列
- HashSet:集合
- Map :键值对
- PriorityQueue:优先队列(堆)
-
- 1、PriorityQueue概述
- 2、常用方法总结
- 4、应用:topK问题
- Sort
-
- BubbleSort
- SelectSort
- QuickSort
- InsertSort
- HeapSort
- StackQueue
- 双指针
-
- TopK
- 总结
前言
本篇内容是我学了一段时间算法以后,自己总结的心得,可能有些地方没写的太好,请大家见谅!如有想深入了解的地方,直接搜索相关内容学习即可!
随着时代越来越卷,考验“算法”逐渐成为了求职、比赛等选拔的常用方式,而java开发的岗位也越来越多,虽然大佬们都用c++,但有时候我们不得不用java来写算法。
刚接触算法的时候没人带,大二参加过蓝桥杯,硬是用语法硬顶,拿了个省二。后来学了一段时间算法,参加“计算机能力挑战赛java程序设计”获得决赛一等奖。虽然这些比赛含金量不高,但我还是想把我辛苦记录的笔记分享给大家!如果对你有帮助,希望可以点个赞支持一下~
刷题的话,看你是哪种比赛了,蓝桥杯那种建议你先刷蓝桥里面的题试试,因为leetcode上面不会要求你输入数据来使用,都是直接给你数据,让你写出方法即可,但是蓝桥杯那一类的OI需要你对输入的数据有一定的处理能力,这点很重要。并且不要盲目刷题、不要盲目刷题、不要盲目刷题!!! 重要的事情说三遍!正确的做法是学一类刷一类,比如我最近两天刷dfs的,感觉差不多了再刷dp的,以此类推。
正片开始 ↓
一、注意事项
如果你是打蓝桥杯那种类型的比赛,一定要把样例代码复制完整、并且注意样例范围、巧用编辑器(word搜索、Excel表格等)
- 不过大多数情况不会给你太长的样例,但我还是踩过一次坑,不踩不知道,比赛时真踩到了就很伤。
- 注意样例范围,初学算法的时候大多数会想着暴力求解,这时候你就要思考用其他方式来过全部样例,例如朴素djisktra一般会爆栈,要进行堆优化等套路。
- word、excel、计算机都可以用,如果它们能帮到你,请务必使用。
二、命题范围
很多同学不知道命题范围有哪些,这里以一个不太起眼的比赛:“全国高校计算机能力挑战赛”为例,说一下命题范围。
- 数据结构:包括基础数据结构、树形结构、字符串、其他等。基本算法知识:包括基础算法、动态规划、搜索等。
- 图论:包括最短路径(单源、任意)、生成树、匹配问题、网络流、其他等。
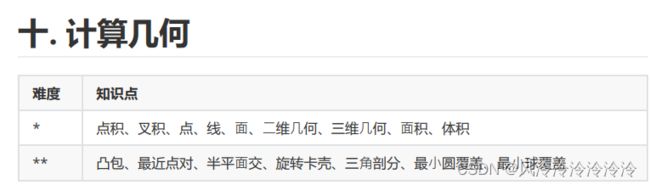
- 数学:包括数论、组合数学、计算方法、计算几何、其他等知识。
蓝桥云课上说得更详细,比较适合想拿国奖的同学深入学习:



三、快捷键系列
Idea快捷键
public class 快捷键 {
/**
* ctrl+shift+enter 代码结尾补全
* ctrl+shift+Alt+J 修改同名变量
* Alt + Enter 引入类
* Ctrl+F 和 Ctrl + R 查找和替换
* ctrl + Alt + L 代码格式格式换
* ctrl + D 复制本代码到下一行
* shift + Alt + ↑或↓ 代码上下移动
* 数组名.for 快速遍历数组
* Alt + Insert set/get; 构造方法; toString; 重写方法。。。
* Ctrl+Alt+T 将代码包在一个块中,例如 while, if, try/catch等
* psvm 主函数
* sout 输出语句
* 给一小段代码添加() {} [],只需要选中该部分代码,然后按( { [ 即可。
* 在()内直接按;可以在代码末尾添加;
*/
}
Eclipse快捷键
public class Zfast {
/**
* alt + ctrl + ↓ 复制当前行到下一行
* alt + ↓ 移动当前行到下一行
* ctrl + shift +f 格式化
* alt + shift + a 块选择
* ctrl + 1 创建对象等补全提示 new ArrayList<>();在这里按ctrl + 1
*/
}
四、常用知识点、思想、套路(重点一)
多提取方法:
因为每次创建并且执行某些相同的操作,同样会花费时间,将相同的代码单独提取出来使用,用空间换时间
double科学计数eN
只有浮点类型才可以使用科学计数法形式表示。
(例如51200是一个int类型的,而512E2则是一个浮点型)
流程控制
1、continue 提前进入下一个循环 ;
2、break 结束for循环;
3、return 直接结束方法。
Three_Dimensional_Array (三维数组)
public class Three_Dimensional_Array {
public static void main(String[] args) {
int[][][] array = new int[3][2][3];//有三层,每层是一个2行3列的二维数组
array = new int[][][]{ //创建并初始化数组
{{1, 2, 3}, {4, 5, 6}},
{{7, 8, 9}, {10, 11, 12}},
{{13, 14, 15}, {16, 17, 18}}
};
for (int i = 0; i < array.length; i++) {
System.out.println("这是第 " + i + " 层");
for (int j = 0; j < array[0].length; j++) {
for (int k = 0; k < array[0][0].length; k++) {
System.out.print(array[i][j][k] + " ");
}
System.out.println();
}
}
/* //foreach的遍历方式 ——每个循环的状态更直观
for (int[][] is : array) { //遍历数组
for (int[] is2 : is) {
for (int i : is2) {
System.out.print(i + "\t");
}
}
}*/
}
}
Scanner
0、无限输入,回车结束
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
while (true) {
String next = scanner.nextLine();
if (!next.equals("")) System.out.println("有效");
else break;
}
}
1、输入整数、字符串数组
第一行输入n, m
第二行输入n个整数
第三行输入m个字符串
//导入包
import java.util.Scanner;
import java.util.Arrays;
public class MyScanner {
public static void main(String[] args) {
//创建对象
Scanner sc = new Scanner(System.in);
System.out.println("输入数据:");
//多行输入
int n = sc.nextInt();
int m = sc.nextInt();
int[] arr = new int[n];
String[] str = new String[m];
//int等基本数据类型的数组,用nextInt(),同行或不同都可以
for(int i=0; i<n; i++) {
arr[i] = sc.nextInt();
}
//String字符串数组, 读取用next(),以空格划分
for(int i=0; i<m; i++) {
str[i] = sc.next();
}
//调用方法进行操作
TestSc(n, m, arr);
TestStr(str);
System.out.println("Test01 End");
//关闭
sc.close();
}
public static void TestSc(int n, int m, int[] arr) {
System.out.println("数据n:" + n + ", 数据m:" + m);
System.out.println(Arrays.toString(arr));
}
public static void TestStr(String[] str) {
System.out.println(Arrays.toString(str));
}
}
若输入的字符串中想要包含空格,使用scanner.nextLine()换行后用scanner.nextLine()进行读入,见情形7.
2、输入二维数组
第一行输入n, m
第二行开始输入二维数组。
import java.util.Arrays;
import java.util.Scanner;
public class MyScanner2 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("输入数据:");
//二维数组
int n = sc.nextInt();
int m = sc.nextInt();
int[][] arr2 = new int[n][m];
System.out.println("Test02 输入二维数组数据:");
//可以直接读入
for(int i=0; i<n; i++) {
for(int j=0; j<m; j++) {
arr2[i][j] = sc.nextInt();
}
}
TestSc(n, m, arr2);
//关闭
sc.close();
}
public static void TestSc(int n, int m, int[][] arr) {
System.out.println("数据n:" + n + ", 数据m:" + m);
for(int i=0; i<n; i++) {
System.out.println(Arrays.toString(arr[i]));
}
System.out.println("数组行数: arr.length= "+ arr.length);
System.out.println("数组列数: arr[0].length= "+ arr[0].length);
}
}
3、输入字符串
输入字符串,用空格隔开。
next()和nextLine()区别。
import java.util.Scanner;
/*
*next()读取到空白停止,在读取输入后将光标放在同一行中。
*nextLine()读取到回车停止 ,在读取输入后将光标放在下一行。
*/
public class MyScanner3 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("输入字符串:");
//next():只读取输入直到空格。
String str = sc.next();
//nextLine():读取输入,包括单词之间的空格和除回车以外的所有符号
String str2 = sc.nextLine();
System.out.println("str:" + str);
System.out.println("str2:" + str2);
//关闭
sc.close();
}
}
4、输入字符串分割为数组
先用scanner.nextLine()读入字符串,再将字符串分割为字符数组或字符串数组。
import java.util.*;
public class MyScanner4 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("输入字符串数组:");
String str;
str = sc.nextLine();
char[] ch = new char[str.length()];
for(int i=0; i<str.length(); i++) {
//用charAt();进行定位分隔
ch[i] = str.charAt(i);
System.out.println(ch[i] + " ");
}
System.out.println("END");
//读入字符串后,用空格分隔为数组
String[] strs = str.split(" ");
System.out.println(Arrays.toString(strs));
}
}
5、连续输入数字和字符串
区别于情形1,对于不能采用for循环的方式获取String。采用情形5,6用来处理。
采用while(scanner.hasNext()) 循环,实现连续输入。
格式:数字,空格,字符串。
或: 数字,回车,字符串
import java.util.Scanner;
public class MyScanner5 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while(sc.hasNext()) {
int n = sc.nextInt();
String str = sc.next();
Tes(n, str);
}
sc.close();
}
public static void Tes(int n, String str) {
System.out.println("n = " + n);
System.out.println("str = " + str);
System.out.println("str.length = " + str.length());
}
}
6、换行输入数字和字符串
也采用scanner.nextLine(),将光标移到下一行。再继续读入字符串。
第一行输入整数n,m,第二行开始输入字符串。或
第一行输入整数n,第二行输入m,第三行开始输入字符串。
import java.util.*;
public class MyScanner6 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
//注意!!!光标换到下一行
sc.nextLine();
String s = sc.nextLine();
String str = sc.nextLine();
System.out.println("n = " + n + " , m = " + m);
System.out.println("s = " + s);
System.out.println("str = " + str);
sc.close();
}
}
7、换行输入数字和字符串(需要包含空格)
采用scanner.nextLine(),将光标移到下一行。再继续读入字符串。
第一行输入n,
第二行开始输入n行字符串,字符串中包含空格。
import java.util.Scanner;
public class MyScanner7 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
String[] strs = new String[n];
sc.nextLine();
for(int i=0; i<n; i++) {
String str = sc.nextLine();
strs[i] = str;
}
Tes2(strs);
System.out.println("End");
sc.close();
}
public static void Tes2(String[] strs) {
for(int i=0; i<strs.length; i++) {
String str = strs[i];
System.out.println(str);
}
}
}
日期类Date(时间戳)
//抛出异常:throws ParseException
//定义日期类格式format:
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//按照format格式创建日期类,包含一个为format格式的String参数
Date date = format.parse(一个为format格式的String);
//通过date拿到当前时间戳,除以1000:将毫秒转换为秒,并强制转换为(int)类型
int s = (int) date.getTime() / 1000;
//Date类型转换成字符串
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = new Date();
String nowTime = format.format(date);
System.out.println("当前的时间::"+nowTime);//2022-11-13 10:19:06
SimpleDateFormat format2 = new SimpleDateFormat("yyyy年MM月dd日");
String nowTime2 = format2.format(date);
System.out.println("当前的时间::"+nowTime2);//2022年11月13日
SimpleDateFormat format3 = new SimpleDateFormat("yyyy年MM月dd日HH时mm分ss秒");
String nowTime3 = format3.format(date);
System.out.println("当前的时间::"+nowTime3);//2022年11月13日10时19分06秒
---------------------------------------------
控制台:
当前的时间::2022-11-13 10:19:06
当前的时间::2022年11月13日
当前的时间::2022年11月13日10时19分06秒
时间戳:
1、Date对象转换为时间戳
Date date = new Date();
long times = date.getTime();
System.out.println(times);
效果如下:
1508824283292
2、时间戳转换为Date日期对象
long times = System.currentTimeMillis();
Date date = new Date(times);
System.out.println(date);
效果如下:
Tue Oct 24 13:49:28 CST 2017
3、时间戳转换为指定日期格式
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
long times = System.currentTimeMillis();
String str = format.format(times);
System.out.println(str);
效果如下:
2017-10-24 13:50:46
4、时间字符串<年月日时分秒毫秒 >转为 时间戳
20180914150324转为1536908604990
代码:
//大写HH:24小时制,小写hh:12小时制
//毫秒:SSS
//指定转化前的格式
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmssSSS");
//转化后为Date日期格式
Date date = sdf.parse(sb.toString());
//Date转为时间戳long
long shootTime = date.getTime();
System.out.println(shootTime);
日历类Calendar
小贴士:
西方星期的开始为周日(1)周一(2),中国开始为周一,因此可以-1使用;注:需单独对0进行处理,0代表周日
int weekDay = calendar.get(Calendar.DAY_OF_WEEK) - 1;
if (weekDay == 0) {
System.out.println("7");
} else {
System.out.println(weekDay);
}
在Calendar类中,月份的表示是以0-11代表1-12月(可以+1使用)。
日期是有大小关系的,时间靠后,时间越大。
常用方法
根据Calendar类的API文档,常用方法有:
- public int get(int field):返回给定日历字段的值。
- public void set(int field, int value):将给定的日历字段设置为给定值。
- public abstract void add(int field, int amount):根据日历的规则,为给定的日历字段添加或减去指定的时间量。
- public Date getTime():返回一个表示此Calendar时间值(从历元到现在的毫秒偏移量)的Date对象。

// 创建Calendar对象
Calendar calendar = Calendar.getInstance();
// 获取年份
int year = calendar.get(Calendar.YEAR);
// 获取月份(月份是从0开始编号的)
int month = calendar.get(Calendar.MONTH) + 1;
// 获取具体日期(月中的第几天)
int dayOfMonth = calendar.get(Calendar.DAY_OF_MONTH);
//获取星期(周日是第一天,周六是最后一天)
int week = calendar.get(Calendar.DAY_OF_WEEK);
System.out.println(calendar.get(Calendar.YEAR) + "年" + (calendar.get(Calendar.MONTH) + 1) + "月" + calendar.get(Calendar.DAY_OF_MONTH) + "日" +"week"+ calendar.get(Calendar.DAY_OF_WEEK) );
//设置——set(){calendar是可变性的}
calendar.set(Calendar.DAY_OF_WEEK,2);//减1week
System.out.println(calendar.get(Calendar.YEAR) + "年" + (calendar.get(Calendar.MONTH) + 1) + "月" + calendar.get(Calendar.DAY_OF_MONTH) + "日" +"week"+ calendar.get(Calendar.DAY_OF_WEEK) );
//添加——add()
calendar.add(Calendar.DAY_OF_WEEK, 2);//加2week
calendar.add(Calendar.YEAR, -3); // 减3年
System.out.println(calendar.get(Calendar.YEAR) + "年" + (calendar.get(Calendar.MONTH) + 1) + "月" + calendar.get(Calendar.DAY_OF_MONTH) + "日" +"week"+ calendar.get(Calendar.DAY_OF_WEEK) );
控制台-----------------------------
2022年11月13日week1
2022年11月14日week2
2019年11月16日week7
-----------------------------
getTime方法:返回对应的Date对象
Calendar中的getTime方法并不是获取毫秒时刻,而是拿到对应的Date对象。
import java.util.Calendar;
import java.util.Date;
public class Demo {
public static void main(String[] args) {
Calendar cal = Calendar.getInstance();
Date date = cal.getTime();
System.out.println(date);
}
}
控制台-----------------------------
Sun Sep 20 08:44:18 CST 2020
String
str.trim(); //去掉首尾空格
str.replace(" “,”“); //去除所有空格,包括首尾、中间
str.replaceAll(” “, “”); //去掉所有空格,包括首尾、中间
str.replaceAll(” +“,”“); //去掉所有空格,包括首尾、中间 str.replaceAll(”\s*“, “”); //可以替换大部分空白字符, 不限于空格 ;
replace和replaceAll是JAVA中常用的替换字符的方法,它们的区别是:
(1) replace的参数是char和CharSequence,即可以支持字符的替换,也支持字符串的替换(CharSequence即字符串序列的意>思,说白了也就是字符串);
(2) replaceAll的参数是regex,即基于规则表达式的替换,比如,可以通过replaceAll(”\d", “*”)把一个字符串所有的数字字符都换>成星号;
相同点:都是全部替换,即把源字符串中的某一字符或字符串全部换成指定的字符或字符串,如果只想替换第一次出现的,可以使用 >。
replaceFirst(),这个方法也是基于规则表达式的替换,但与replaceAll()不同的时,只替换第一次出现的字符串。
length()返回字符串的长度 charAt(index)返回索引值的字符
concat(s1)字符串的拼接 trim()去掉字符串头和尾的空格
toUpperCase() toLowerCase()字符串的大小写转换
//str.startsWith(“s”)函数是用于判断str是否以“s”开头,返回一个布尔值
//str.substring(n1,n2) --> 包括头但不包括尾
例:discount = discount.substring(0, discount.length() - 1);
“88折”.substring(0, 3-1) returns “88” 截取,含头不含尾
Str.toCharArray(); 将字符串转换为字符数组;
int i = 123; String str =i+“”; char [] s = str.toCharArray(); 将数字拆分成字符数组
Math
- Math.sqrt()//计算平方根 Math.cbrt()//计算立方根
- Math.pow(底数,几次方) --> int c=(int)Math.pow(a,b)中添加了一个(int),这是强制类型转换,因为Math.pow(a,b) 的计算结果返回是double类型,double类型转换为int类型就需要用到。
- Math.random()是令系统随机选取大于等于 0.0 且小于 1.0 的伪随机 double 值
- // 由控制台接收两个整数作为范围,产生一个整数。Math.random()随机产生一个0-1之间的浮点数。
int r = a + (int)(Math.random()*(b-a+1));
//圆面积:double s = Math.PI * r * r; - next()
- next()方法在读取内容时,会过滤掉有效字符前面的无效字符,对输入有效字符之前遇到的空格键、Tab键或Enter键等结束符,next()方法会自动将其过滤掉;只有在读取到有效字符之后,next()方法才将其后的空格键、Tab键或Enter键等视为结束符;所以next()方法不能得到带空格的字符串。
- nextLine()方法字面上有扫描一整行的意思,它的结束符只能是Enter键,即nextLine()方法返回的是Enter键之前没有被读取的所有字符,它是可以得到带空格的字符串的。
- 对任何数x,都有xx=0,x0=x。
- 打印不换行,System.out.print();
位运算
- 如果要判断一个数的二进制中某一位(假设是第五位)是1还是0,将1左移四位,与该数进行&运算后,再右移四位,判断最终结果。
- 代码实现: (((num>>4)&1)==0?“第五位是0”:“第五位是1”);
- 用二进制的思想交换两个数:x=x^y; y=x^y ; x=x^y;
1.什么是位运算
位运算又称为位操作,指的是直接对二进制位进行的一系列操作。
2.位运算有哪些
AND( & )
按位与
1 & 1 = 1
1 & 0 = 0
0 & 0 = 0
1101 & 1100 = 1100
OR( | )
按位或
1 | 1 = 1
1 | 0 = 1
0 | 0 = 0
1001 | 1010 = 1011
XOR( ^ )
按位异或
1 ^ 1 = 0
0 ^ 0 = 0
1 ^ 0 = 1
0 ^ 1 = 1
1101 ^ 1100 = 0001
NOT( ~ )
取反
~1 = 0
~0 = 1
~0111 = 1000
另:& | ^ ~ 是c或类c的编程语言中所用的位操作符。 除了~是单目运算符
其余的三个都是双目运算符。
移位运算
左移运算符: <<
在二进制表示下把数字同时向左移, 低位以0填充, 高位越界后舍弃。
右移运算符: >>
右移运算又分为算术右移和逻辑右移。
算术右移:
在二进制补码表示下,把数字同时向右移位,高位以符号位填充,低位越界后舍弃。
对于 n >> 1 在C/C++中相当于 n/2 下取整。
逻辑右移:
在二进制补码表示下把数字同时向右移动,高位以0填充,低位越界后舍弃。
C++并没有规定右移的方式,所以编译器不同,可能实现的方式也不一样。
不过说了这么多,总结下来其实就是:
00001 << 2 = 00100
00100 >> 2 = 00001
3.常用的位运算操作
- (n>>k) &1 取出整数n在二进制表示下的第k位
- n & ((1 << k) - 1) 取出整数n在二进制表示下的第0~k-1位(后k位)
- n ^ (1 << k) 把整数n在二进制表示下的第k位取反
- n | (1 << k) 把整数n在二进制表示下的第k位赋值为1
- n & (~(1 << k)) 把整数n在二进制表示下的第k位赋值为0
- n ^ (1 << k) = n - (1<
- 除以2
a / 2 = a >> 1
(a + b) / 2 == a + b >> 1 ( + - 运算的优先级高于 <<, >> )- 判断奇偶
一个数的二进制数的最低位如果是1 则该数一定是奇数 否则一定是偶数
所以 用 a & 1 检测最低为是否位1 - 除以2
if(a & 1) cout<<"奇数";
else cout<<"偶数"
- 快速幂
- 状态压缩
以一个二进制数表示一个状态集合。
如 n = 1100 S = {2, 3} S表示状态所有为1的集合。 - 成对变换
当n 为偶数时 n ^ 1 = n + 1
当n为奇数时 n ^ 1 = n - 1
所以
(0,1) (2, 3) (4, 5)… 关于 ^1 运算 构成“成对变换”
这一性质常用于图论邻接表中边集的存储。在具有无向边(双向边)的图中把一对正反方向的边分别存储在邻接表数组中的第n和第n+1位置(n为偶数),就可以通过^1
的运算获得与当前边(x, y) 反向的边(y, x)的存储位置。
摘自<<算法竞赛进阶指南>> - lowbit运算
lowbit(n) 定义为非负整数n在二进制表示下"最低为1及其后边所有0"构成的数值. 例如 n = 10
的二进制表示为(1010)2, 则lowbit(n) = 2 = (10)2 .
lowbit(n) = n & (~n + 1) = n&(-n)
摘自<<算法竞赛进阶指南>>
循环
- 多重循环要学会,外层循环控制行,内层循环控制列。
- 不确定次数、多个控制变量、控制变量的初始化必须放在循环外面的时候---->用while更合适
类型
- byte、char、short型参与运算时自动提升为int型。
如果一个操作数为long、float、double型,则整个表达式提升为long、float、double型 - int result = 27/3; double result = 27/3.0;
- long timeMillis = System.currentTimeMillis();
当接收到的数比如:52345678912(五百亿+),这时需要手动转为long类型,即在末尾加上L,表示是long类型
System.out.println((timeMillis/3600000)%24+8);//返回当前小时数 - // 由控制台接收两个整数作为范围,产生一个整数。Math.random()随机产生一个0-1之间的浮点数。
int r = a + (int)(Math.random()*(b-a+1));
//圆面积:double s = Math.PI * r * r;
Arrays类
(1) Arrays.toString(); //返回数组的字符串形式
(2) Arrays.sort(); //排序(自然排序 和 定制排序)
顺序可以直接用sort排序,逆序见下面的两种排序方法
//1. 因为数组是引用类型,所以通过sort排序后,会直接影响到实参(即进行排序的数组)
//2. sort方法是重载的,也可以通过传入一个接口 Comparator 实现定制排序
Arrays.sort(a,num1,num2);
–> Integer型数组名,num1 起始索引值;num2终止索引值,并且num2不能取到。
–>[num1,num2)
=========================两种方法实现int数组逆序排序================================
①顺序排序,逆向赋值(简单、推荐)
public static void main(String[] args) throws IOException {
int[] nums = {1, 4, 7, 2, 5, 6};
int[] res = new int[nums.length];
Arrays.sort(nums);
for (int i = nums.length - 1; i >= 0; i--) {
res[nums.length - 1 - i] = nums[i];
}
for (int r : res) {
System.out.println(r);
}
}
②数组流(相对繁琐,不好记)
public class demoTest {
public static void main(String[] args) throws IOException {
int[] nums = {1, 4, 7, 2, 5, 6};
//将int数组转换为数值流,流中的元素全部装箱,转换为Integer流,再将流转换为数组
Integer[] array = Arrays.stream(nums).boxed().toArray(Integer[]::new);
Arrays.sort(array, Collections.reverseOrder());
for (int i = 0; i < array.length; i++) {
nums[i] = array[i];
}
for (int num : nums) {
System.out.println(num);
}
}
(3)Arrays.binarySearch(int[] a,int key); //参数:a - 要搜索的数组,key - 要搜索的值
//使用二进制搜索算法在指定的整数数组中搜索指定的值。
//注意!:在进行此调用之前,必须对数组进行排序(如通过sort(int[])方法)。
//如果数组中不存在该元素,就返回一个负数: return -(low + 1);
(low即是该元素应该出现的索引位置)
(4)Arrays.copyOf(int[] original, int newLength );
//从 original 数组中 拷贝 newLength 个元素到 新的数组中
//参数:original – 要复制的数组
newLength – 要返回的副本的长度
(5)Arrays.fill(int[] a, int val); //数组元素的填充
//将指定的 int 值分配给指定的 int 数组的每个元素。
//参数:a - 要填充的数组 val – 要存储在数组所有元素中的值
(6)Arrays.equals(); //如果两个指定的 int 数组彼此相等,则返回true 。
(7)Arrays.asList( ); //会将输入的数据转成一个List集合
例如:List list = Arrays.asList(3,6,888,99);
数论
- 欧几里得(辗转相除法)求最大公约数:
static int gcd(int a, int b) { //最大公约数
if(b==0) return a;
else return gcd(b,a%b);
} - 最小公倍数 = 两数相乘 ÷ 两数的最大公约数.
static int lcm(int a , int b) {
return a * b / gcd(a,b);
} - 判断奇偶数:
将这个数与1做&运算。 原因:二进制中奇数最后一位为1,偶数最后一位为0. - 判断闰年:
①、普通年能被4整除且不能被100整除的为闰年. ②、世纪年能被400整除的是闰年 - 用2得到8最快的方法:
2<<2。 原因:二进制中左移n位相当于乘以2的n次方. - 分解质因数:
例1:
public class demo_数论_分解质因数 {
/**
* 根据算术基本定理又称唯─分解定理,对于任何一个合数,我们都可以用几个质数的幂的乘积来表示。
* 如:
* 12 = 2^2 * 3
* 20 = 2^2 * 5
* 30 = 2 * 3 * 5
* 接下来我们利用这个公式分解质因数。
* 设一个质数为p,如果 n % p == 0,那么p就是n的一个质因数,
* 接下来就是求p的指数,我们让n = n / p , 这样就从n中剔除了一个p,
* 接着重复上述两步,直到 n % p != 0
*/
public static void prime(int n) {
for (int i = 2; i <= n / i; i++) {//即i*i<=n
int a = 0, b = 0;
while (n % i == 0) {
a = i;
n /= i;
b++;
}
if (b > 0)
System.out.println("质因数之一: " + a + " 的 " + b + " 次方");
}
if (n > 1) System.out.println("有一个大于根号n 的质因数:" + n);
}
/**
* 注意:以上代码中for循环的结束条件也是i <= n / i,因为根据公式,最多只可能有一个质因数是大于 根号n,
* 因为有两个的话,乘积肯定超过n了。所以当for循环结束后判断n是否大于1,如果大于就说明有一个大于 根号n 的质因数。
*/
public static void main(String[] args) {
prime(30);
}
}
例2:
import java.util.*;
/**
* 1. 编程将一个正整数n分解质因数。
* 输入输出示例1:
* 请输入一个数:90
* 90=2*3*3*5
* 输入输出示例2:
* 请输入一个数:50
* 50=2*5*5
*/
public class demo01 {
public static void main(String[] args) {
Queue<Integer> queue = new LinkedList<>();
Scanner scanner = new Scanner(System.in);
int num = scanner.nextInt();
int org = num;
for (int i = 2; i < num; i++) {
int a = 0, b = 0;
while (num % i == 0) {
a = i;
num /= i;
b++;
}
if (b != 0)
while (b-- > 0) {
queue.add(a);
}
}
if (num > 1)
queue.add(num);
System.out.print(org+"=");
while (!queue.isEmpty()){
System.out.print(queue.poll());
if (!queue.isEmpty())
System.out.print("*");
}
}
}
" 快速幂" && “素数筛法” 见后文的 --> Algorithm
格式控制
- String.format(“%02d”, year)
year格式化为至少2位十进制整数 --> int year = 5;结果为05 - double ans=0.11111111;
作格式转换 String.format(“%.nf”, ans)
作输出 System.out.printf(“%.nf”,ans);
System.out.printf(“%.2f”, (double) lcm(4, 2)); 输出—> 4.00
–> n为小数点后保留的位数。
===========================================================================
输入字符数组
c[i] = scan.nextLine().toCharArray();
===========================================================================
使用Iterator迭代器遍历容器ArrayList
示例:
List<Integer> ArrayList = new ArrayList<>();
ArrayList.add(1);
ArrayList.add(2);
ArrayList.add(2);
//1、获取迭代器
Iterator iter = ArrayList.iterator();
//2、通过循环迭代
//hasNext():判断是否存在下一个元素
while(iter.hasNext()) {
//如果存在,则调用next实现迭代
//Object-->Integer-->int
System.out.println((int)iter.next());//把Object型强转成int型
}
IO快速读写
import java.io.*;
//①StreamTokenizer
static StreamTokenizer scanner = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
public static int nextInt() throws IOException {
scanner.nextToken();
return (int) scanner.nval;
}
int a = nextInt();
//②BufferedReader------>推荐使用!!!!!
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
bw.write(String.valueOf(i + " "));
bw.flush();
bw.close();
br.close();
public static void main(String[] args) throws IOException {
String s[] = br.readLine().split(" ");
int a = Integer.valueOf(s[0]),b = Integer.valueOf(s[1]);
char c = Character.valueOf(s[2].charAt(0));
System.out.println(c);
bw.flush();//把缓冲区的内容强制的写出。
bf.close();
bw.close();
测试类
import java.io.*;
import java.util.*;
public class Main{
static BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter out = new BufferedWriter(new OutputStreamWriter(System.out));
public static void main(String[] args) throws IOException{
//测试writr 不能直接输出int类型
int a = 65;
out.write(a);
out.write("\n");
out.write(a + "\n"); // 使用 + 号拼接个字符串 使参数整体为一个字符串
out.write(Integer.toString(a)); // 输出a的字符串形式
out.write("\n");
//测试 read() 和 readLine();
int b = in.read(); // read()只读取一个字符
int c = in.read(); // 吸收 \n
int x = in.read(); // 吸收 \r
// String e = in.readLine();
String d = in.readLine();
out.write("\n");
out.write(b + "\n");
out.write(c + "\n");
out.write(x + "\n");
out.write(d + "\n");
//out.write(e);
out.flush();
}
}

一共输入了:
1 (按回车键)
ABC DEF
然后下面输出了
49(1的ASCii码)
13(回车键的ACSii码)
10 (换行键的ASCII码)
ABC DEF
无穷大的坑!
System.out.println(Integer.MIN_VALUE - 1);//2147483647
System.out.println(Integer.MAX_VALUE);//2147483647
System.out.println(Integer.MIN_VALUE);//-2147483648
最好是都右移一位避免过于极端
System.out.println(Integer.MAX_VALUE >> 1);//1073741823
System.out.println(Integer.MIN_VALUE >> 1);//-1073741824
坐标存储小技巧
保存经过的每一个点位置信息,采用(x)*m+y的公式表示(x,y);m:大于最长边的随便一个数
private static Queue location = new LinkedList<>();
int x, y;//当前位置坐标
location.add(x * m + y);
int l = location.poll();//获取当前位置的坐标
x = l / 50;//获取当前位置x
y = l % 50;//获取当前位置y
集合排序
ArrayList<Integer> list = new ArrayList<>();
list.add(2);
list.add(0);
list.add(5);
list.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);//0 2 5 前后 --> 从小到大
}
});
把上面的代码可以使用lambda表达式进一步简化
升序:
list.sort((a,b)->{
return Integer.compare(a,b);
});
list.sort(Integer::compare);
直接调用list.sort(Comparator.naturalOrder());
降序:
list.sort((a,b) ->{
return Integer.compare(b,a);
});
直接调用list.sort(Comparator.reverseOrder());
===========================================================================
Collection工具类的使用
排序操作
reverse(List):反转 List 中元素的顺序
shuffle(List):对 List 集合元素进行随机排序
sort(List):根据元素的自然顺序对指定 List 集合元素升序排序
sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
@Test
public void test1() {
List list = new ArrayList();
list.add(123);
list.add(43);
list.add(765);
list.add(-97);
list.add(0);
System.out.println(list);//[123, 43, 765, -97, 0]
//reverse(List):反转 List 中元素的顺序
Collections.reverse(list);
System.out.println(list);//[0, -97, 765, 43, 123]
//shuffle(List):对 List 集合元素进行随机排序
Collections.shuffle(list);
System.out.println(list);//[765, -97, 123, 0, 43]
//sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
Collections.sort(list);
System.out.println(list);//[-97, 0, 43, 123, 765]
//swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
Collections.swap(list,1,4);
System.out.println(list);//[-97, 765, 43, 123, 0]
}
查找、替换
Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
Object min(Collection)
Object min(Collection,Comparator)
int frequency(Collection,Object):返回指定集合中指定元素的出现次数
void copy(List dest,List src):将src中的内容复制到dest中
boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所旧值
@Test
public void test2(){
List list = new ArrayList();
list.add(123);
list.add(123);
list.add(123);
list.add(43);
list.add(765);
list.add(-97);
list.add(0);
System.out.println(list);//[123, 43, 765, -97, 0]
//Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
Comparable max = Collections.max(list);
System.out.println(max);//765
//Object min(Collection)
Comparable min = Collections.min(list);
System.out.println(min);//-97
//int frequency(Collection,Object):返回指定集合中指定元素的出现次数
int frequency = Collections.frequency(list,123);
System.out.println(frequency);//3
//void copy(List dest,List src):将src中的内容复制到dest中
List dest = Arrays.asList(new Object[list.size()]);
System.out.println(dest.size());//7
Collections.copy(dest,list);
System.out.println(dest);//[123, 123, 123, 43, 765, -97, 0]
//boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
}
Pattern类的使用(匹配正则表达式)

//根据匹配不同的内容返回不同的数值;
//注意:这里的匹配指的是 " 仅含有 ",
//所以,如果要判断一个字符串中是否包含多种字符,可以采用顺序拼接,也可以采用逐个判断
//拼接是这样写:Pattern.matches("^[a-z]+[\\d]+$", str),如果是a4一类的,则为true,很局限...
//所以,这道题采用逐个判断
public class demo04 {
private static int teShu(String str) {
if (Pattern.matches("^[@#!%*$~]+$", str))
return 1;
if (Pattern.matches("[\\d]+", str))
return 2;
if (Pattern.matches("^[a-z]+$", str))
return 3;
if (Pattern.matches("^[A-Z]+$", str))
return 4;
return 0;
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String str = scanner.nextLine();
if (str.length() < 8) {
System.out.println("NG");
return;
}
String[] split = str.split("");
int[] kinds = new int[5];
for (String s : split) {
if (kinds[1] == 1 && kinds[2] == 1 && kinds[3] == 1 && kinds[4] == 1)
break;
if (teShu(s) == 1) {
kinds[1] = 1;
} else if (teShu(s) == 2) {
kinds[2] = 1;
} else if (teShu(s) == 3) {
kinds[3] = 1;
} else if (teShu(s) == 4) {
kinds[4] = 1;
}
}
int count = kinds[1] + kinds[2] + kinds[3] + kinds[4];
if (count <= 1) {
System.out.println("NG");
} else if (count == 2) {
System.out.println("MG");
} else if (count == 3) {
System.out.println("VG");
} else if (count == 4) {
System.out.println("EG");
}
}
}
进制转换(x进制转10进制,10进制转y进制)
// 如果题目要进行转化的进制在2~36之间的话直接调用库函数就行了。
String s = in.readLine();
int a = Integer.parseInt(s, 16) // 将16进制的字符串转化十进制数
//BigInteger a = new BigInteger(s, 16);// 高精度数
out.write(Integer.toString(a, 8)); // 转化为8进制输出
//out.write(a.toString(8));
out.flush();
因子组合
这类题和快速幂等思想一样,从已知条件入手,排除掉无关的内容,从而优化循环,降低复杂度
解题思路:
由于因子只含有3,5,7,所以满足该条件的数一定是由 : 3的某次方 * 5的某次方 * 7的某次方 构成,而这样组成的数相对于全部的数,它们只占少部分,则可以直接暴力求解!
定义三个变量,三个变量都由0出发,因为一个数的0次方法等于1,相乘不会影响结果,但需要注意的是,要排除掉1这个数字,并且给定的那个数是需要取到的,所以我们列出公式:
for (int x = 0; Math.pow(3, x) <= num; x++)
for (int y = 0; Math.pow(5, y) <= num; y++)
for (int z = 0; Math.pow(7, z) <= num; z++)
这样就能遍历出全部的“幸运数字”,然后加以判断,只要“幸运数字”是<=number的,就追加个数,代码如下:
/**
* 到 X 星球旅行的游客都被发给一个整数,作为游客编号。
* X 星的国王有个怪癖,他只喜欢数字 3,5 和 7。
* 国王规定,游客的编号如果只含有因子:3,5,7 就可以获得一份奖品。
* 我们来看前 10 个幸运数字是:
* 3 5 7 9 15 21 25 27 35 45
* 因而第 11 个幸运数字是: 49
* 小明领到了一个幸运数字 59084709587505,他去领奖的时候,人家要求他准确地说出这是第几个幸运数字,否则领不到奖品。
* 请你帮小明计算一下,59084709587505 是第几个幸运数字。
*/
public class demo85_数论3_因子组合_幸运数字 {
public static void main(String[] args) {
long num = 59084709587505L;
int count = 0;
for (int x = 0; Math.pow(3, x) <= num; x++)
for (int y = 0; Math.pow(5, y) <= num; y++)
for (int z = 0; Math.pow(7, z) <= num; z++)
if (Math.pow(3, x) * Math.pow(5, y) * Math.pow(7, z) <= num)
count++;
System.out.println(count - 1);
}
}
五、Algorithm(重点二)
快速幂
快速幂的思想是:
①把指数想象成二进制的表示方式;
②如果指数不等于0,则判断最后一位是否为1(&),如果是,则用结果变量result 乘 底数 并取模(根据题意设定模的大小),否则不能乘,因为0 * result = 0;
③每进行一次,底数 = 底数 * 底数 % 模 (将指数表示为二进制之后,底数应该对应每次的指数),
即 a的1次 a的2次 a的4次 a的8次 (同底数相乘,指数相加,正好对应二进制的每一位),
例如:20的3次方(3的二进制为11)= 20的(2的1次方)次方 * 20的(2的0次方)次方;
④将指数往右边移动一位,方便进行下一次的判断
⑤其实到这里,快速幂的思想分析已然结束,但是格外的取模操作让人感到不太理解(不考虑数据溢出的情况下可以不取模),为什么每次都可以取模?其实只要是乘法,不论何时取模都是一样的,可以参考 以下公式:
例如:(a * b)% c = (a % c) * (b % c); --> (5 * 6) % 4 = ( 5 % 4) * (6 % 4) = 2
下面以一道省赛例题为例,在不清楚数据是否会溢出的情况下,推荐使用快速幂:

import java.io.*;
public class Main {
static BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
static int mod = 7;
public static void main(String[] args) throws IOException {
bw.write(String.valueOf(FastPower(20, 22) + 6));
bw.flush();
bw.close();
}
public static int FastPower(int a, int b) {
int res = 1;
while (b != 0) {
if ((b & 1) == 1) {
res = res * a % mod;
}
//无论如何,a都要不断倍增,b都要不断右移
a *= a % mod;
b = b >> 1;
}
return res;
}
}
素数筛法
埃氏筛
其思想就是:筛掉质数的倍数
package java_Algorithm;
public class demo85_数论2_埃氏筛 {
static final int N = (int) (1e7 + 5);
static int[] st = new int[N];
public static void E_sieve(int n) {
for (int i = 2; i <= n / i; i++)
if (st[i] == 0)
for (int j = i * i; j <= n; j += i)
st[j] = 1; // j是i的一个倍数,j是合数,筛掉。
}
}
欧拉筛(最快)
欧拉筛,又称为线性筛,时间复杂度为O ( n ) O(n)O(n)。
先看下代码再看解析:
public class Main {
static final int N = (int) (1e7 + 5);
static int count = 0;
static int[] status = new int[N], primes = new int[N];
static void ola(int n) {
for (int i = 2; i <= n; i++) {
if (status[i] == 0)
primes[count++] = i;//将质数存到primes中
for (int j = 0; primes[j] <= n / i; j++) {//要确保质数的第i倍是小于等于n的。
status[primes[j] * i] = 1;
if (i % primes[j] == 0)
break;//欧拉筛的核心思想就是确保每个合数只被最小质因数筛掉。或者说是被合数的最大因子筛掉。
}
}
}
public static void main(String[] args) {
ola(8);
for (int i = 0; i < count; i++) {
System.out.println(primes[i]);
}
}
}


欧拉筛的核心思想就是确保每个合数只被最小质因数筛掉。或者说是被合数的最大因子筛掉。
例题:
筛质数
代码:
package java_Algorithm;
public class 欧拉筛 {
static final int N = (int) (1e7 + 5);
static int cnt = 0;
static int[] st = new int[N], primes = new int[N];
static void ola(int n) {
for (int i = 2; i <= n; i++) {
if (st[i] == 0) primes[cnt++] = i;//将质数存到primes中
for (int j = 0; primes[j] <= n / i; j++) {//要确保质数的第i倍是小于等于n的。
st[primes[j] * i] = 1;
if (i % primes[j] == 0) break;
}
}
}
public static void main(String[] args) {
ola(8);
for (int i = 0; i < cnt; i++) {
System.out.println(primes[i]);
}
}
}
双指针(链表)
如果有环,fast一定会追上slow,如果没有环,fast跑完之后就会return false。
//判断是否有环 --- 双指针!!!
public static boolean isCycle(LinkedNode head) {
LinkedNode fast = head;
LinkedNode slow = head;
while (fast != null && fast.next != null) {
slow = slow.next;//必须保证 :fast != null
fast = fast.next.next;//必须保证 :fast.next != null
if (fast == slow) {
return true;
}
}
return false;
}
完整的链表代码
//判断是否有环 — 双指针!!!
//返回倒数第k个节点的值(无环)
//合并两个有序无环单链表,返回新链表的头结点
package java_wuji.JXY.algorithm;
public class LinkedListTest {
public static class LinkedNode {
public int value;
public LinkedNode next;
}
public static void print(LinkedNode head) {
while (head != null) {
System.out.print(head.value + " ");
head = head.next;
}
System.out.println();
}
//判断是否有环 --- 双指针!!!
public static boolean isCycle(LinkedNode head) {
LinkedNode fast = head;
LinkedNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) {
return true;
}
}
return false;
}
//返回倒数第k个节点的值(无环)
public static int getNthFromEnd(LinkedNode head, int k) {
LinkedNode fast = head;
LinkedNode slow = head;
//先让他们间隔k-1个距离,即:规定好初始时的间隔
for (int i = 0; i < k - 1; i++) {
fast = fast.next;
}
//当fast指向最后一个结点时结束循环
while (fast.next != null) {
fast = fast.next;
slow = slow.next;
}
return slow.value;
}
//合并两个有序无环单链表,返回新链表的头结点
public static LinkedNode mergedTwoSortedLinkedList(LinkedNode l1, LinkedNode l2) {
LinkedNode preHead = new LinkedNode();
LinkedNode prev = preHead;
while (l1 != null && l2 != null) {
if (l1.value <= l2.value) {
prev.next = l1;
l1 = l1.next;
} else {
prev.next = l2;
l2 = l2.next;
}
prev = prev.next;
}
// 合并后 l1 和 l2 最多只有一个还未被合并完,我们直接将链表末尾指向未合并完的链表即可
prev.next = l1 == null ? l2 : l1;
return preHead.next;
}
public static void main(String[] args) {
LinkedNode node1 = new LinkedNode();
node1.value = 1;
LinkedNode node2 = new LinkedNode();
node2.value = 2;
LinkedNode node3 = new LinkedNode();
node3.value = 3;
LinkedNode node4 = new LinkedNode();
node4.value = 4;
node1.next = node2;
// node2.next = node3;
node3.next = node4;
// node4.next = node1;//形成环
// print(node1);
// System.out.println(isCycle(node1));
// System.out.println(getNthFromEnd(node1, 2));
LinkedNode node = mergedTwoSortedLinkedList(node1, node3);
print(node);
}
}
前缀和 与 差分
前缀和(一维)

高中时曾学过数列的前n项和Sn,即若存在一组数列{ a1,a2,a3,…,an },则Sn = a1+a2+a3+…+an,在计算机领域,我们把Sn称为“前缀和”。
我们知道,对于m(m
根据该公式,我们便找到了解决上面提出的问题的一种方法,即定义一个数组prefix[ ]用以保存数列中的前n项和(此时,prefix[1]=S1,prefix[2]=S2,…,prefix[n]=Sn),这样就可以在求区间[L,R]里的数列之和时直接用prefix[R] - prefix[L-1]得到。而构造前缀数组的方法如下(为了方便起见,通常要求前缀数组中的索引从1开始):
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
int N = (int) (1e7 + 5);
int[] prefix = new int[N];
int[] arr = new int[N];
int n = 3;
for (int i = 1; i <= n; i++) {
arr[i] = scanner.nextInt();
prefix[i] = prefix[i - 1] + arr[i];
}
for (int i = 1; i <= n; i++) {
System.out.print(prefix[i] + " ");
}
}
差分

差分与前缀和实际上是刚好相反的两个概念(若设原数组为ary[ ],前缀和为prefix[ ],差分为subfix[ ])。则前缀和的当前项等于原数组中的当前项再加上前缀和的前一项,即prefix[i] = ary[i] + prefix[i-1];而差分的当前项则等于原数组中的当前项减去原数组中的前一项,即:subfix[i] = ary[i] - ary[i-1]。于是可以得到构造差分数组的方法如下(其索引也是从1开始)。
int subfix[N],ary[N];
for(int i=1;i<=n;i++)
{
cin>>ary[i];
subfix[i]=ary[i]-ary[i-1];
}
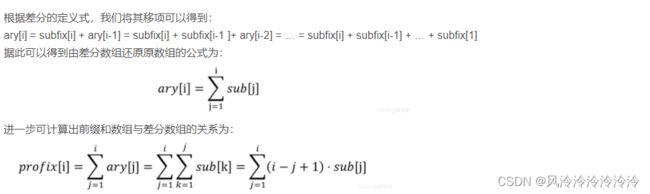
接下来举个例子以直观地认识差分数组:
设数组ary[ ]={1,2,4,3,6,2},那么其对应的差分数组subfix[ ]={1,1,2,-1,3,-4}。现在若我们对原数组中区间为[2,4]的元素都加上2的话,则原数组变为ary[ ]={1,4,6,5,6,2},差分数组变为subfix[ ]={1,3,2,-1,1,-4}。我们发现,subfix[ ]中只有subfix[2]和subfix[5]发生了改变。这是因为区间[2,4]中的元素是同时加上2的,所以在区间[2,4]中的元素之差并未发生改变。同样地,其外部非端点部分的元素之差也不会发生改变。但是在给定区间的起始端点处(索引为2),由于该元素增加了2,故其相对其前一个元素而言增加了2,因此该处subfix[2]的值就增加了2;相反,在给定区间的结束端点处(索引为4),由于该元素增加了2,故其相对其后一个元素而言增加了2,因此在其后的subfix[5]的值就减少了2。
根据差分数组的此特性,我们可以先通过原数组来构建一个差分数组,此过程的时间复杂度为O(n)。然后再把上述问题中于每次操作里需要修改值的某段区间[L,R]优化为仅仅只对区间的两个端点进行修改,这样就可以把修改操作的时间复杂度降低到常数级,进而使得这m个操作的时间复杂度降至O(m)。最终计算区间[L,R]内的数列之和时,仅需要再调用一次SumOfSection函数便可得到,该算法的平均时间复杂的为O(m)。此时,整个程序的时间复杂度将降低至max{ O(m), O(n) }。下面给出求解上述问题的完整代码:
#include<iostream>
using namespace std;
const int N=100010; // 数组的最大阈值
int n,m,ans; // 数列长度、操作次数、最终答案
int l,r,value; // m次操作的左右边界与Value
int ary[N]; // 原数组
int subfix[N]; // 差分数组
int main()
{
cin>>n>>m;
// 输入原数组
for(int i=1;i<=n;i++) cin>>ary[i];
// 构建subfix数组
for(int i=1;i<=n;i++) subfix[i] = ary[i] - ary[i-1];
// 执行m次操作
for(int i=m;i>0;i--){
cin>>l>>r>>value;
subfix[l] += value;
subfix[r+1] -= value;
}
// 还原原数组
for(int i=1;i<=n;i++) ary[i] = ary[i-1] + subfix[i];
cin>>l>>r;
// 计算最终询问给出的区间之和
for(int i=l;i<=r;i++) ans += ary[i];
cout<<ans<<endl;
return 0;
}
小明的彩灯
import java.io.*;
public class demo78_差分_小明的彩灯 {
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static final int N = 500005;
static long[] arr = new long[N];
static long[] sub = new long[N];
public static void main(String[] args) throws IOException {
String[] firstLine = br.readLine().split(" ");
int n = Integer.parseInt(firstLine[0]);
int m = Integer.parseInt(firstLine[1]);
String[] nextLine = br.readLine().split(" ");
for (int i = 1; i <= n; i++) {
arr[i] = Long.parseLong(nextLine[i - 1]);
sub[i] = arr[i] - arr[i - 1];
}
while (m-- > 0) {
String[] subLine = br.readLine().split(" ");
sub[Integer.parseInt(subLine[0])] += Long.parseLong(subLine[2]);
sub[Integer.parseInt(subLine[1]) + 1] -= Long.parseLong(subLine[2]);
}
for (int i = 1; i <= n; i++) {
arr[i] = arr[i - 1] + sub[i];
if (arr[i] < 0) System.out.print(0 + " ");
else System.out.print(arr[i] + " ");
}
}
}
前缀和数组(二维)
“二维前缀和” 模板:
S[i, j] = 第i行j列格子左上部分所有元素的和
S[i, j] = S[i-1,j] + s[i,j-1] - S[i-1,j-1] + a[i,j](表示当前的数)(双重for循环构建)
以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵的和为:
S[x2, y2] - S[x1-1,y2] - S[x2,y1-1] + S[x1-1,y1-1]
int matrix[M][N], prefix[M][N]; // M、N分别表示二维矩阵的高度和宽度
void CreatePrefix(int m, int n) {
for(int i=1;i<=m;i++) // 二维矩阵的录入以及二维前缀和数组的构建
for(int j=1;j<=n;j++){
cin>>matrix[i][j];
prefix[i][j] = prefix[i-1][j]+ prefix[i][j-1]- prefix[i-1][j-1]+matrix[i][j];
}
}
//在给定了两个序数对(x1, y1)、(x2, y2)后,
//通过二维前缀和数组求解指定子阵元素和的公式为:
S=prefix[x2][y2] - prefix[x1 - 1][y2] - prefix[x2][y1 -1] + prefix[x1 -1][y1 -1]
一维前缀和的主要用处是对一维数组的子区间进行快速求和,因此在面对矩阵时便失去了其作用。比如对于如下二维表:
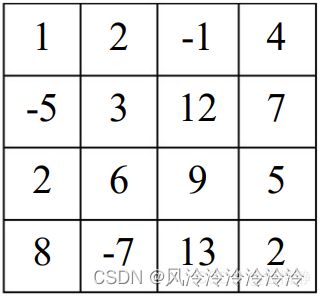
若现在有w组询问,每组询问给出两个序数对(x1, y1),(x2, y2)(两个序数对满足x1
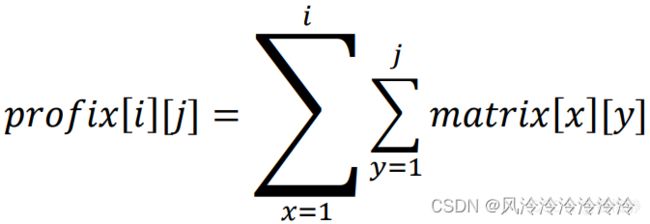
它表示从位置matrix[1][1]到matrix[i][j]这之间所有元素的总和。下面我们来关注一下如何通过一个二维数组来构建二维前缀和(这就需要我们寻找二维前缀和的迭代公式)。
如下图所示,prefix[2][3]表示图中黄色部分的所有元素之和。

由该图易知,prefix[2][3] = matrix[1][1] + matrix[1][2] + matrix[1][3] + matrix[2][1] + matrix[2][2] + matrix[2][3] = prefix[2][2] + matrix[1][3] + matrix[2][3]。
如下图所示,prefix[3][2]表示图中蓝色部分的所有元素之和。
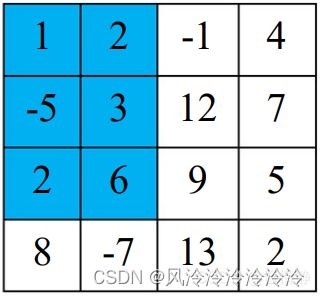
由该图易知,prefix[3][2] = matrix[1][1] + matrix[1][2] + matrix[2][1] + matrix[2][2] + matrix[3][1] + matrix[3][2] = prefix[2][2] + matrix[3][1] + matrix[3][2]。
由于prefix [2][3] + prefix [3][2] = 2 * prefix [2][2] + matrix[1][3] + matrix[2][3] + matrix[3][1] + matrix[3][2]。也就是说将这两幅图进行重叠得到的效果如图3.1.4所示(其中绿色部分,即prefix [2][2]占了两份):
那么如果我们要用原数组和前缀和数组得到prefix[3][3]的话,则公式为:
prefix[3][3] = prefix[2][3] + prefix[3][2] - pfofix[2][2] + matrix[3][3]
实际上,上式正是二维前缀数组递推式的一个实例。根据斥容原理,我们也不难得出二维前缀数组的递推式为:
prefix[i][j] = prefix [i-1][j] + prefix [i][j-1] - prefix [i-1][j-1] + matrix[i][j]
由该式,我们可以直接写出构建二维前缀数组的代码:
int matrix[M][N], prefix[M][N]; // M、N分别表示二维矩阵的高度和宽度
void CreatePrefix(int m, int n) {
for(int i=1;i<=m;i++) // 二维矩阵的录入以及二维前缀和数组的构建
for(int j=1;j<=n;j++){
cin>>matrix[i][j];
prefix[i][j] = prefix[i-1][j]+ prefix[i][j-1]- prefix[i-1][j-1]+matrix[i][j];
}
}
接下来我们来讨论如何利用二位前缀数组来求解最初的问题。
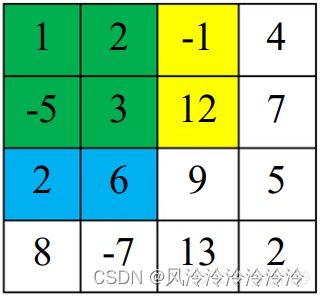
假设现在给出两个序数对(2, 2)和(4, 4)(下图中红色部分),我们要怎么利用二维前缀数组来求出这两点所确定的子矩阵元素之和呢(图中红色与黄色的共同组成部分)?

如果仅仅是用prefix[4][4] - prefix [2][2],得到的结果如下图中黄色部分所示:
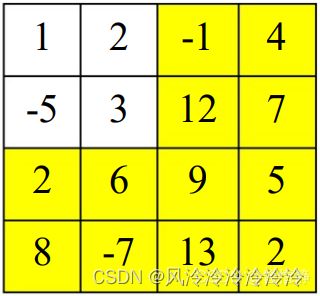
显然这个结果并不是我们所预想的。此时我们可以从二维前缀和的定义式中寻找突破。如果我们将所求子阵单独隔离出去,来观察剩余元素的位置特征,如下图所示(有色背景部分):
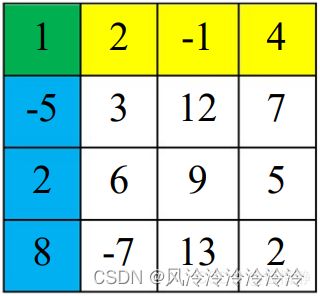
若设图中黄色部分的子阵为S1,蓝色部分的子阵为S2,绿色部分的子阵为S3(=prefix[1][1]),待求子阵为S。那么我们可以很容易地得到:
S = prefix[4][4] - ( S1 + S2 + S3 )
= prefix[4][4] - ( (S1+S3) + (S2+S3) - S3 )
= prefix[4][4] - ( prefix[1][4] + prefix[4][1] - prefix[1][1] )
= prefix[4][4] - prefix[1][4] - prefix[4][1] + prefix[1][1]
实际上,在给定了两个序数对(x1, y1)、(x2, y2)后,通过二维前缀和数组求解指定子阵元素和的公式为:
S = prefix[x2][y2] - prefix[x1 - 1][y2] - prefix[x2][y1 -1] + prefix[x1 -1][y1 -1]
前缀和的应用
【洛谷】 P1115 最大子段和
public class demo79_前缀和_最大子段和 {
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
//sum用于记录前缀和,max用于记录最大值,now用于记录当前输入的值
int n, sum, max, now;
n = scanner.nextInt(); //将输入序列的第一个值作为sum
scanner.nextLine(); //将sum的值作为max的初始值
sum = scanner.nextInt();
max = sum;
while (--n > 0) {
now = scanner.nextInt();
sum = Math.max(sum, 0); //判断sum的正负以决定是否保留该序列
sum += now; //无论怎样,都加上当前输入的值以对比max
max = Math.max(max,sum);
}
System.out.println(max);
}
}
子矩阵的和
public class demo79_前缀和数组_子矩阵的和 {
static int N = 1005;
static int n, m, q;
static int[][] map = new int[N][N];
static int[][] prefix = new int[N][N];
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
m = scanner.nextInt();
q = scanner.nextInt();
scanner.nextLine();
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
map[i][j] = scanner.nextInt();
prefix[i][j] = prefix[i - 1][j] + prefix[i][j - 1] - prefix[i - 1][j - 1] + map[i][j];
}
}
int x1, y1, x2, y2;
while (q-- > 0) {
x1 = scanner.nextInt();
y1 = scanner.nextInt();
x2 = scanner.nextInt();
y2 = scanner.nextInt();
System.out.println(prefix[x2][y2] - prefix[x1 - 1][y2] - prefix[x2][y1 - 1] + prefix[x1 - 1][y1 - 1]);
}
}
}
二分(非递归)
public class BinarySearchNoRecur {
public static void main(String[] args) {
//测试
int[] arr = {1,3, 8, 10, 11, 67, 100};
int index = binarySearch(arr, 100);
System.out.println("index=" + index);//
}
//二分查找的非递归实现
/**
*
* @param arr 待查找的数组, arr是升序排序
* @param target 需要查找的数
* @return 返回对应下标,-1表示没有找到
*/
public static int binarySearch(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while(left <= right) { //说明继续查找
int mid = (left + right) / 2;
if(arr[mid] == target) {
return mid;
} else if ( arr[mid] > target) {
right = mid - 1;//需要向左边查找
} else {
left = mid + 1; //需要向右边查找
}
}
return -1;
}
}
递归
递归的含义很好理解,就是一个函数调用自身,难就难在如何确定一个题目的递归式,这就需要多刷题了。 一个完整的递归函数包含两个部分:
- 递归式
- 递归出口
以斐波那契数列为例:
int f(int n){
if(n == 1 || n == 2) return 1; // 递归出口
return f(n-1) + f(n-2); // 递归式
}
递归式用来递归计算我们想要得到的值, 递归出口用来结束递归。
如果没有递归出口,那么就会一直递归下去,就造成了死循环。
那么什么题会用到递归呢? 子问题和原问题求解方式完全相同的,可以用递归。
练习题目
下面的练习题目是几类常见的递归题目。
1. 递归实现指数型枚举
import java.io.*;
import java.util.*;
public class Main{
static int n;
static Scanner in = new Scanner(new BufferedReader(new InputStreamReader(System.in)));
static BufferedWriter out = new BufferedWriter(new OutputStreamWriter(System.out));
public static void f(int u, int state) throws IOException{
if(u == n){
for(int i = 1; i <= n; i++){
if((state & (1<<i)) > 0){
out.write(i+" ");
}
}
out.write("\n");
return ;
}
f(u+1, state);
f(u+1, state | (1 << (u+1)));
}
public static void main(String[] args) throws IOException{
n = in.nextInt();
f(0, 0);
out.flush();
}
}
- 递归实现组合型枚举
import java.io.*;
import java.util.*;
public class Main{
static int n, m;
static Scanner in = new Scanner(new BufferedReader(new InputStreamReader(System.in)));
static BufferedWriter out = new BufferedWriter(new OutputStreamWriter(System.out));
public static void f(int v, int u, int state) throws IOException{
if(u > n) return ;
if(v == m){
for(int i = 1; i <= n; i++){
if((state>>i & 1) == 1)
out.write(i+" ");
}
out.write("\n");
out.flush();
return ;
}
f(v+1, u+1, state | (1<<(u+1)));
f(v, u+1, state);
}
public static void main(String[] agrs)throws IOException{
n = in.nextInt();
m = in.nextInt();
f(0, 0, 0);
out.flush();
}
}
- 递归实现排列型枚举
import java.io.*;
public class Main {
static BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter out = new BufferedWriter(new OutputStreamWriter(System.out));
static int arr[] = new int[10];
static int n = 0;
public static void dfs(int i, int state) throws IOException{
if(i == n + 1){
for(int j = 1; j <= n; j++){
out.write(arr[j]+" ");
}
out.write("\n");
out.flush();
}
for(int j = 1; j <= n; j ++){
if((state >> j & 1) != 1){
arr[i] = j;
dfs(i+1, state | 1<<j);
}
}
}
public static void main(String[] args) throws IOException{
String s = in.readLine();
n = Integer.parseInt(s);
dfs(1, 1);
out.flush();
}
}
- n-皇后 问题
import java.io.*;
public class Main {
static BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter out = new BufferedWriter(new OutputStreamWriter(System.out));
static final int N = 10;
static int a[] = new int[N];
static int dg[] = new int[2*N];
static int udg[] = new int[2*N];
static int n = 0;
public static void dfs(int i, int state) throws IOException{
if(i == n + 1){
for(int j = 1; j <= n; j++){
for(int l = 1; l <= n; l++){
if(l != a[j]) out.write(".");
else out.write("Q");
}
out.write("\n");
}
out.write("\n");
out.flush();
return;
}
for(int j = 1; j <= n; j ++){
if((state >> j & 1) != 1 && dg[i+j] != 1 && udg[j-i+n] != 1){
a[i] = j;
dg[i+j] = 1;
udg[j-i+n] = 1;
dfs(i+1, state | 1<<j);
dg[i+j] = 0;
udg[j-i+n] = 0;
}
}
}
public static void main(String[] args) throws IOException{
String s = in.readLine();
n = Integer.parseInt(s);
dfs(1, 1);
out.flush();
}
}
DFS
八皇后问题
public class Queue8Simple {
static int max = 8;//定义一个max表示共有多少个皇后
//定义数组array, 保存皇后放置位置的结果,比如
//arr = {0 , 4, 7, 5, 2, 6, 1, 3} ----数字表示列
static int[] array = new int[max];
static int count = 0;//解法数目
public static void main(String[] args) {
dfs(0);
System.out.printf("一共有%d解法", count);
}
//编写一个方法,放置第n个皇后
//特别注意: dfs 是 每一次递归时,进入到dfs中都有
//for(int i = 0; i < max; i++),因此会有回溯
private static void dfs(int n) {
if (n == max) { //n = 8 , 其实8个皇后就既然放好
return;
}
//依次放入皇后每一列(i),并判断是否冲突
//如果冲突,就继续循环,看下一列是否能成功放置皇后
for (int i = 0; i < max; i++) {
//i的值代表皇后在第几列
array[n] = i;
//判断当放置第n个皇后到i列时,是否冲突
for (int j = 0; j < n; j++) {
if (!(array[j] == array[n] || Math.abs(n - j) == Math.abs(array[n] - array[j]))) {
dfs(n + 1);
}
}
}
}
}
迷宫问题
题目大意就是从起始位置@开始走,只能走在 . (黑砖)上面, 不能走在#(红砖)上面,问从@开始最多可以走几块 .(黑砖)。
将每个可以到达的点当作一个状态,搜索所有的状态,就可以得到答案啦。
怎么搜索呢, 只要我们得到下个点的坐标就可以了, 可以朝四个方向走,
当前坐标 + (0,1) 就是向右走, + (1,0)就是向下走, + (0,-1)就是向左走, +(-1, 0)就是向上走。
判断一下个点是否超出边界是红砖还是黑砖,如果是黑砖,就搜索下一点,也就是DFS下一个点。
本题也可BFS。
本题坑点: @点也算一个答案。
import java.io.*;
import java.util.Arrays;
public class Main{
static BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter out = new BufferedWriter(new OutputStreamWriter(System.out));
static char[][] map = new char[30][30];
static int[][] vis = new int[30][30];
static int[][] ne = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
static int n, m, res = 0;
public static void dfs(int x, int y){
vis[x][y] = 1;
for(int i = 0; i < 4; i++){ //四个方向
int nx = x + ne[i][0];
int ny = y + ne[i][1];
if(nx < 0 || nx >= m || ny < 0 || ny >= n
|| map[nx][ny] == '#' || vis[nx][ny] == 1){
continue;
}
res++;
dfs(nx,ny);
}
}
public static void main(String[] args) throws IOException{
while(true){
String s[] = in.readLine().split(" ");
n = Integer.parseInt(s[0]);
m = Integer.parseInt(s[1]);
if(n==0||m==0) break;
int x = 0, y = 0;
res = 0;
for(int i = 0; i < vis.length; i++)
Arrays.fill(vis[i], 0);
for(int i = 0; i < m; i++){
String s1 = in.readLine();
if(s1.indexOf('@') != -1){
x = i;
y = s1.indexOf('@');
}
map[i] = s1.toCharArray();
}
dfs(x, y);
out.write((res+1)+"\n");
out.flush();
}
}
}
马踏棋盘(贪心优化)
这里值得一提的有两个地方:
①用到了awt包中的Point类,类似于平时自己构建的Node,具体方法查看源码
②运用贪心算法的思想,每次选择可走路线最少的路去走,最大程度减少回溯
import java.awt.Point;
import java.util.ArrayList;
import java.util.Comparator;
public class HorseChessboard {
private static int X; // 棋盘的列数
private static int Y; // 棋盘的行数
//创建一个数组,标记棋盘的各个位置是否被访问过
private static boolean[] visited;
//使用一个属性,标记是否棋盘的所有位置都被访问
private static boolean finished; // 如果为true,表示成功
public static void main(String[] args) {
System.out.println("骑士周游算法,开始运行~~");
//测试骑士周游算法是否正确
X = 8;
Y = 8;
int row = 1; //马儿初始位置的行,从1开始编号
int column = 1; //马儿初始位置的列,从1开始编号
//创建棋盘
int[][] chessboard = new int[X][Y];
visited = new boolean[X * Y];//初始值都是false
//测试一下耗时
long start = System.currentTimeMillis();
dfs(chessboard, row - 1, column - 1, 1);
long end = System.currentTimeMillis();
System.out.println("共耗时: " + (end - start) + " 毫秒");
//输出棋盘的最后情况
for(int[] rows : chessboard) {
for(int step: rows) {
System.out.print(step + "\t");
}
System.out.println();
}
}
/**
* 完成骑士周游问题的算法
* @param chessboard 棋盘
* @param row 马儿当前的位置的行 从0开始
* @param column 马儿当前的位置的列 从0开始
* @param step 是第几步 ,初始位置就是第1步
*/
public static void dfs(int[][] chessboard, int row, int column, int step) {
chessboard[row][column] = step;
//这里是把二维数组降维为一维数组,通过加上前面的行数和当前的列数,得到现在是第几个元素
visited[row * X + column] = true; //标记该位置已经访问
//获取当前位置可以走的下一个位置的集合
//-----------不能把这个list写在外面!每次递归都需要一个单独的list对象,表示每层递归中下一次可以走的点的集合
ArrayList<Point> ps = next(new Point(column, row));
//对ps进行排序,排序的规则就是对ps的所有的Point对象的下一步的位置的数目,进行非递减排序
//-----------下面这句话是贪心的体现,并且要注意:
// ---------------不要直接在这里面写比较器,因为每次创建并且执行这样的操作,也会花费时间,单独写一个方法来比较,用空间换时间
sort(ps);
//遍历 ps
while(!ps.isEmpty()) {
Point p = ps.remove(0);//取出下一个可以走的位置
//判断该点是否已经访问过
//-----------这里把x 看成列,y 看成行,模拟坐标中的(x,y)
if(!visited[p.y * X + p.x]) {//说明还没有访问过
dfs(chessboard, p.y, p.x, step + 1);
}
}
//判断马儿是否完成了任务,使用 step 和应该走的步数比较 ,
//如果没有达到数量,则表示没有完成任务,将整个棋盘置0
//说明: step < X * Y 成立的情况有两种
//1. 棋盘到目前位置,仍然没有走完
//2. 棋盘处于一个回溯过程
//------这里是回溯的过程,从dfs的最深处开始回溯,如果没有走完,把状态重置,以免影响下一次的递归
if(step < X * Y && !finished ) {
chessboard[row][column] = 0;
visited[row * X + column] = false;
} else {
finished = true;
}
}
/**
* 功能: 根据当前位置(Point对象),计算马儿还能走哪些位置(Point),并放入到一个集合中(ArrayList), 最多有8个位置
* @param curPoint
* @return
*/
public static ArrayList<Point> next(Point curPoint) {
//创建一个ArrayList
ArrayList<Point> ps = new ArrayList<>();
//创建一个Point
Point p1 = new Point();
//表示马儿可以走5这个位置
if((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y -1) >= 0) {
ps.add(new Point(p1));
}
//判断马儿可以走6这个位置
if((p1.x = curPoint.x - 1) >=0 && (p1.y=curPoint.y-2)>=0) {
ps.add(new Point(p1));
}
//判断马儿可以走7这个位置
if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y - 2) >= 0) {
ps.add(new Point(p1));
}
//判断马儿可以走0这个位置
if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y - 1) >= 0) {
ps.add(new Point(p1));
}
//判断马儿可以走1这个位置
if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y + 1) < Y) {
ps.add(new Point(p1));
}
//判断马儿可以走2这个位置
if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y + 2) < Y) {
ps.add(new Point(p1));
}
//判断马儿可以走3这个位置
if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y + 2) < Y) {
ps.add(new Point(p1));
}
//判断马儿可以走4这个位置
if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y + 1) < Y) {
ps.add(new Point(p1));
}
return ps;
}
//根据当前这个一步的所有的下一步的选择位置,进行非递减排序, 减少回溯的次数
public static void sort(ArrayList<Point> ps) {
ps.sort(new Comparator<Point>() {
@Override
public int compare(Point o1, Point o2) {
//获取到o1的下一步的所有位置个数
int count1 = next(o1).size();
//获取到o2的下一步的所有位置个数
int count2 = next(o2).size();
if(count1 < count2) {
return -1;
} else if (count1 == count2) {
return 0;
} else {
return 1;
}
}
});
}
}
BFS
BFS要先搜索当前状态可以直接到达的所有状态。因为一次只能处理一个状态,所以我们需要按照先后顺序,先将可以到达的所有状态点全部存起来,因为需要满足先后的顺序,所以正好可以利用队列先进先出的特性来存储。
static int dir[][] = {{0, -1}, {1, 0}, {-1, 0}, {0, 1}};//路径有时候很重要
模板
public static void bfs(int x, int y){
q.add(x, y); //将起点入队
vis[x][y] = 1; // 标记已经走过
while(!q.isEmpty()){ // 当队列不空
x = q.peek().x; //取出队头元素
y = q.peek().y;
q.poll(); //删除队头元素
if(x == n-1 && n == m-1) return; // 到达终点
for(int i = 0; i < 4; i++){ // 当前点可以到达的下四个方向
int nx = x + dx[i]; // 下个点的坐标
int ny = y + dy[i];
if(nx < 0 || nx >= n || ny < 0 || ny >= m || vis[nx][ny] == 1 ) continue; // 下个点不合法
else{
q.add(new pair(nx,ny)); //下个点合法,入队存储
vis[nx][ny] = 1; // 标记该点已经走过
}
}
}
}
走迷宫
给定一个n’m的二维整数数组,用来表示一个迷宫,数组中只包含0或1,其中0表示可以走的路,1表示不可通过的墙壁。
最初,有一个人位于左上角(1,1)处,已知该人每次可以向上、下、左、右任意一个方向移动一个位置。请问,该人从左上角移动至右下角(n, m)处,至少需要移动多少次。
数据保证(1,1)处和(n, m)处的数字为0,且一定至少存在一条通路。输入格式
第一行包含两个整数n和m。
接下来n行,每行包含m个整数(O或1),表示完整的二维数组迷宫。输出格式
输出一个整数,表示从左上角移动至右下角的最少移动次数。
import java.io.*;
import java.util.*;
class pair{
public int x,y;
pair(int a, int b){
x = a;
y = b;
}
}
public class Main{
static BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter out = new BufferedWriter(new OutputStreamWriter(System.out));
static final int N = 1000;
static String[][] arr = new String[N][N];
static int[][] pren = new int[N][N];
static int[][] vis = new int[N][N];
static int[][] res = new int[N][N];
static int[] dx = {-1, 0, 1, 0};
static int[] dy = {0, 1, 0, -1};
static int n, m = 0;
static Queue<pair> q = new LinkedList<>();
public static int Int(String s){ return Integer.parseInt(s);}
public static void read() throws IOException{
for(int i = 0; i < n; i++){
arr[i] = in.readLine().split(" ");
}
}
public static void bfs(int x, int y)throws Exception{
q.add(new pair(x, y));
vis[x][y] = 1;
res[x][y] = 0;
while(!q.isEmpty()){
x = q.peek().x;
y = q.peek().y;
q.poll();
for(int i = 0; i < 4; i++){
int nx = x + dx[i];
int ny = y + dy[i];
if(nx < 0 || nx >= n || ny < 0 || ny >= m || vis[nx][ny] == 1 || arr[nx][ny].compareTo("1") == 0) continue;
else{
res[nx][ny] = res[x][y] + 1;
q.add(new pair(nx,ny));
vis[nx][ny] = 1;
if(nx == n-1 && ny == m-1) return;
}
}
}
}
public static void main(String[] args) throws Exception{
String s[] = in.readLine().split(" ");
n = Int(s[0]);
m = Int(s[1]);
read();
bfs(0,0);
out.write(res[n-1][m-1]+"\n");
out.flush();
}
}
KMP
KMP字符匹配
步骤
- 先写kmp创建部分匹配表的方法:public static int[] kmpNext(String dest)
- 再写出kmp的搜索方法:public static int kmpSearch(String str1, String str2, int[] next)
- 在主函数中:
- 先定义主字符串str1和要匹配的字符串str2
- 将str2作为参数,调用kmpNext(str2)方法得到部分匹配表,并用int[] next接收
- 将str1、str2、next作为参数,调用kmpSearch(str1, str2, next),并用int index接收
- 输出index,即为匹配到的第一个下标,若没有匹配到的,则返回index的值为-1
kmpNext() 注意是next[ j - 1 ]
public static int[] kmpNext(String dest) {
int[] next = new int[dest.length()];
int j = 0;
for(int i = 1; i < dest.length(); i++) {
while(j > 0 && dest.charAt(i) != dest.charAt(j)) {
j = next[j-1];
}
if(dest.charAt(i) == dest.charAt(j)) {
j++;
}
next[i] = j;
}
return next;
}
kmpSearch() 注意while里面的i 和 j、str1和str2 ,不要写错了
public static int kmpSearch(String str1, String str2, int[] next) {
int j = 0;
for (int i = 0; i < str1.length(); i++) {
while (j > 0 && str1.charAt(i) != str2.charAt(j)) {
j = next[j - 1];
}
if (str1.charAt(i) == str2.charAt(j)) {
j++;
}
if (j == str2.length()) {
return i - j + 1;
}
}
return -1;
}
综合代码
public class KMPAlgorithm {
/*//KMP算法核心点, 可以验证...!!!!!!!!!!!!!!!!
while( j > 0 && str1.charAt(i) != str2.charAt(j)) {
j = next[j-1];
}*/
public static void main(String[] args) {
String str1 = "BBC ABCDAB ABCDABCDABDE";
String str2 = "ABCDABD";
//String str2 = "BBC";
int[] next = kmpNext("ABCDABD"); //[0, 1, 2, 0]
System.out.println("next=" + Arrays.toString(next));
int index = kmpSearch(str1, str2, next);
System.out.println("index=" + index); // 15了
}
//写出我们的kmp搜索算法
/**
* @param str1 源字符串
* @param str2 子串
* @param next 部分匹配表, 是子串对应的部分匹配表
* @return 如果是-1就是没有匹配到,否则返回第一个匹配的位置
*/
public static int kmpSearch(String str1, String str2, int[] next) {
//遍历
for(int i = 0, j = 0; i < str1.length(); i++) {
//需要处理 str1.charAt(i) != str2.charAt(j), 去调整j的大小
//KMP算法核心点, 可以验证...
while( j > 0 && str1.charAt(i) != str2.charAt(j)) {
j = next[j-1];
}
if(str1.charAt(i) == str2.charAt(j)) {
j++;
}
if(j == str2.length()) {//找到了 // j = 3 i
return i - j + 1;
}
}
return -1;
}
//获取到一个字符串(子串) 的部分匹配值表
public static int[] kmpNext(String dest) {
//创建一个next 数组保存部分匹配值
int[] next = new int[dest.length()];
next[0] = 0; //如果字符串是长度为1 部分匹配值就是0
for(int i = 1, j = 0; i < dest.length(); i++) {
//当dest.charAt(i) != dest.charAt(j) ,我们需要从next[j-1]获取新的j
//直到我们发现 有 dest.charAt(i) == dest.charAt(j)成立才退出
//这是kmp算法的核心点
while(j > 0 && dest.charAt(i) != dest.charAt(j)) {
j = next[j-1];
}
//当dest.charAt(i) == dest.charAt(j) 满足时,部分匹配值就是+1
if(dest.charAt(i) == dest.charAt(j)) {
j++;
}
next[i] = j;
}
return next;
}
}
题目:小明的字符串
package java_code_lxr;
import java.util.Scanner;
//https://www.lanqiao.cn/problems/1203/learning/
public class demo81_KMP_小明的字符串 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String str1 = scanner.nextLine();
String str2 = scanner.nextLine();
int[] next = kmpNext(str2);
int temp;
for (int i = str2.length(); i > 0; i--) {
temp = kmpSearch(str1, str2.substring(0, i), next);
if (temp != -1) {
System.out.println(temp);
break;
}
}
}
private static int kmpSearch(String str1, String str2, int[] next) {
int j = 0;
for (int i = 0; i < str1.length(); i++) {
while (j > 0 && str1.charAt(i) != str2.charAt(j))
j = next[j - 1];
if (str1.charAt(i) == str2.charAt(j))
j++;
if (j == str2.length()) return str2.length();
}
return -1;
}
private static int[] kmpNext(String str2) {
int[] next = new int[str2.length()];
int j = 0;
for (int i = 1; i < str2.length(); i++) {
while (j > 0 && str2.charAt(i) != str2.charAt(j))
j = next[j - 1];
if (str2.charAt(i) == str2.charAt(j))
j++;
next[i] = j;
}
return next;
}
}
动态规划(dp)
/**
* 凡是dp问题,记住一句话:当前的结果都是由之前的过程推导出来的。
* 我们要把之前推导的过程列出来,从而知道当前结果是怎么推导出来的(画表格),
* 进而写出递推方程式
* 找出base情况
* 根据方程式计算出 dp 中其他内容
*/
爬楼梯问题:
//N级台阶,每次爬一级或者爬两级,爬上去一共有多少种不同的办法?
public class dp_ClimbStairs {
public static void main(String[] args) {
int n = 5;
int[] dp = new int[n + 1];
// 定义动态方程式
// 在第i级台阶时,有多少种不同的办法?
// dp[i] = dp[i-1]+dp[i-2]
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
System.out.println(dp[n]);
}
}
最大的子串(连续)和:
/**
* 【最大的子串(连续)和是多少】
* array = [-2,1,-3,4,-1,2,1,-5,4]
*
* 4,-1,2,1 =》6
* dp[i] => 以第i位为结尾的子串,最大的和是多少?
*/
/**
* dp[i] => 查看前面的数字
* (1)如果dp[i-1]是正数,把前面的加起来
* (2)如果dp[i-1]是负数,用自己当一个子串
* if(dp[i-1]<0) => dp[i] = dp[i]
* else => dp[i] = num[i] + dp[i-1]
* 动态方程式:dp[i] = Math.max(dp[i], num[i]+dp[i-1])
*/
public class dp_MaxSubArray {
public static void main(String[] args) {
int[] array = new int[]{-2, 1, -3, 4, -1, 2, 1, -5, 4};
int n = array.length;
int[] dp = new int[n];
// base: 每一位都是自己为一个子串
for (int i = 0; i < n; i++) {
dp[i] = array[i];
}
int max = Integer.MIN_VALUE;
for (int i = 1; i < n; i++) {
// 如果前面为正数进行累加,如果为负数就用自己当子串
dp[i] = Math.max(array[i] + dp[i - 1], dp[i]);
max = Math.max(max, dp[i]);
}
System.out.println(max);
}
}
长的升序子序列(可以不连续):
/**
* 【最长的升序子序列(可以不连续)的长度是多少?】
* array=[1,2,10,5,20,100,30]
*
* 1,2,10,20,100 => 5
* 1,2,5,20,100 => 5
* 1,2,5,20,30 => 5
*
* dp[i] => 以第i位为结尾的升序子序列,最长的长度是什么?
*/
import java.util.Arrays;
public class dp_IncreasingSubSqu {
public static void main(String[] args) {
int[] array = new int[]{1, 2, 10, 5, 20, 100, 30};
int n = array.length;
int[] dp = new int[n];
// base:每一位都用自己当一个子序列
Arrays.fill(dp, 1);
int max = dp[0];
// i代表当前这一个数字
for (int i = 0; i < n; i++) {
// 查看i前面范围内,能否把自己放上去
for (int j = 0; j < i; j++) {
if (array[i] > array[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
max = Math.max(max, dp[i]);
}
}
}
System.out.println(max);
}
}
01背包问题:
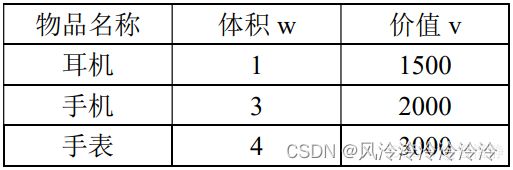

dp[i][j] = max( 上方单元格的价值,剩余空间的价值 + 当前商品的价值 )
= max( dp[i-1][j],dp[i-1][j-当前商品的体积] + 当前商品的价值 )
= max( dp[i-1][j],dp[i-1][j-w[i]] + v[i] )
其中,dp[i][j]表示表格中的第i行第j列单元格中的值
01降维
dp[j] = max( dp[j] , v[i] + dp[j - w[i]] )
public class demo73采药01dp {
static int M = 105;//开出的空间比给出范围大一点
static int N = 1005;//开出的空间比给出范围大一点
static int m, n;//m行(每行代表一种物品) n列(每列代表一个时间点)
static int[][] dp = new int[M][N];//创建动态表格
static int[] t = new int[M];//存时间(对应背包中的物品重量)
static int[] v = new int[M];//存价值
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
m = scanner.nextInt();
scanner.nextLine();
for (int i = 1; i <= m; i++) {
t[i] = scanner.nextInt();
v[i] = scanner.nextInt();
scanner.nextLine();
}
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++)
if (j >= t[i])//如果当前表格的时间大于采摘第i个药品所需要的时间(即能装下)
dp[i][j] = Math.max(dp[i - 1][j], (v[i] + dp[i - 1][j - t[i]]));//前者为不拿当前物品的价值,后者为装入当前物品的价值+剩余容量再上一次中能拿到的最大价值
else//表示当前物品的容量超出了当前表格的容量 --> 直接将上一层中同容量的数据填入表格
dp[i][j] = dp[i - 1][j];
System.out.println(dp[m][n]);
}
}
上述代码是一个满分代码,但是不够完美。因为此算法存在一个显著缺陷:dp[M][N]数组在M或N取值较大时可能会出现爆内存的现象。因此,我们需要设法进行降维。从哪儿降呢?要么变成dp[M],要么变成dp[N]。如果是保留dp[M],这意味着在进行状态转移时,是以草药的种类来进行的(即在二维表格中填表时按列进行),这和前面我们采取的填表方式相悖;而如果是保留dp[N],那么我们在进行状态转移时就是以背包容量来进行的(即在二维表格中填表时按行进行),这和前面采取的填表方式一致。这就提示我们,可以将药的种类省略,而仅用一个和背包容量相当的一位数组dp[N]来进行状态转移。此时,我们可以利用一个循环,来将输入的数据不断与前面的数据进行计算、比较,并将最新结果保存至dp[N]中。据此,可以得到新的递推式为:
dp[j] = max(dp[j] , dp[j - w[i]] + v[i])
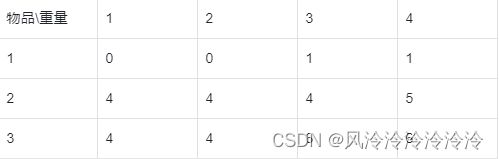
但是这里有个新问题,当在一维数组中从左至右更新dp[N]数组时,由于dp[j - w[i]] + v[i]总是大于dp[j],因此这将使得某个物品被反复拿多次。以上面的例子举例(在以下物品中拿最大价值,背包总容量为4):

那么在利用递推式:
dp[j] = max(dp[j] , dp[j - w[i]] + v[i])
1
进行动态转移时,其更新过程如下(注:dp[N]数组在初始情况下的所单元格中的值均为0):
第一个单元格,此时dp[1]=max(dp[1], dp[1-1]+1500)=max(0, 0+1500)=1500;
第二个单元格,此时dp[2]=max(dp[2], dp[2-1]+1500)=max(dp[2], dp[1]+1500)=max(0, 1500+1500)=3000;
第三个单元格,此时dp[3]=max(dp[3], dp[3-1]+1500)=max(dp[3], dp[2]+1500)=max(0, 3000+1500)=4500;
第四个单元格,此时dp[4]=max(dp[4], dp[4-1]+1500)=max(dp[4], dp[3]+1500)=max(0, 4500+1500)=6000;
……
可以发现,从第2个单元格开始,后面将一直错下去,因为这之后的每次更新都会利用前面的计算结果(实际上,这样的执行流程在逻辑上表示重复取当前物品,即某件物品不再是被拿了一次,而是被拿了多次)。
备注:这里的“错误”做法,洽洽又是后面完全背包问题的正确处理办法。
这又该如何处理呢?我们来分析出现这种情况的原因。由于大容量的背包在存放物品时可能不仅能存放前面已经存放的,或许还会因为大容量而使得其能拿更多的物品,从而出现反复拿小体积物品的情况。因此在自左向右更新的过程中,由于取 max(dp[j] , dp[j - w[i]] + v[i]) 而使得后面的数组在更新时不断利用前面已经保留好的结果来进行状态转转移,进而不断出错(即对某件物品反复拿取)。
虽然如此,但这个递推公式本身是正确的,只是在使用过程中由于更新方向而出现了一些错误。试想,如果从右向左对数组进行更新是否可行呢?在这种情况下,当用到:
dp[j] = max(dp[j] , dp[j - w[i]] + v[i])
时,由于dp[j - w[i]]指向的数组还未进行更新,此时其存放的结果是在前一种情况下(只能拿前一种及其更之前的物品时),对应容量背包所能存放的最大价值。故此时max(dp[j] , dp[j - w[i]] + v[i]) 表示的含义正是:“在当前背包容量下,怎样的拿取方案具有更大价值:延续上一种拿取方案 or 拿当前物品再加上除开当前物品体积后剩余背包容量所具有的最大价值后的总价值”。这和我们所期望的效果是一致的。下面给出改进后(降维使用滚动数组)的完整代码:
public class demo73采药01dp_降维 {
//这里只写降维后需要注意的地方,其余注释见二维的代码
static int M = 105;
static int N = 1005;
static int m, n;
static int[] dp = new int[N];//创建降维的动态表格,第几次存就代表存的第几行,一共N列
static int[] t = new int[M];
static int[] v = new int[M];
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
m = scanner.nextInt();
scanner.nextLine();
for (int i = 1; i <= m; i++) {
t[i] = scanner.nextInt();
v[i] = scanner.nextInt();
scanner.nextLine();
}
for (int i = 1; i <= m; i++)
for (int j = n; j >= t[i]; j--)//如果当前表格的时间大于采摘第i个药品所需要的时间(即能装下),否则不作处理,代表沿用上一次的数据
if (j >= t[i])
dp[j] = Math.max(dp[j], (v[i] + dp[j - t[i]]));
System.out.println(dp[n]);
}
}
完全背包问题:
实际上,完全背包问题就是在01背包问题的基础上,将每种物品的数量由1个变为无限个。
因此,完全背包问题中的递推式也将随之发生改变。在01背包问题中,其递推式为:
dp[i][j] = max( dp[i-1][j] , dp[i-1][j - w[i]] + v[i] )
基于以上公式在填表的第一行时,其结果如下:
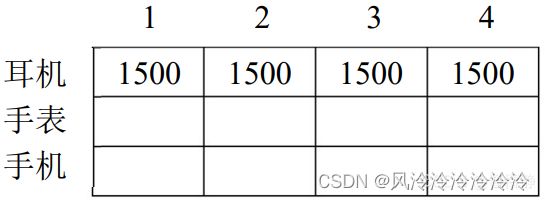
可以看出,在填写第一行的第2、3、4列时,尽管背包容量增加了,但是由于耳机只有一个,所以后面背包的最大值一直未发生变化,其取值始终为一个耳机的价值。但是现在的情况有所不同,我们可以在不超过背包容量的前提下,多拿几个耳机。此时,填表的结果应该如下:
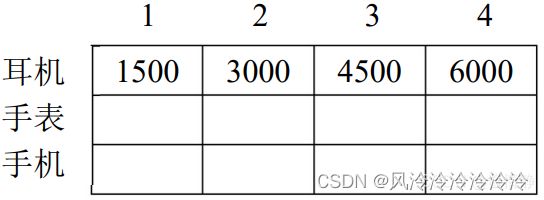
基于此,我们可以很自然地想到在01背包问题的算法中,于最内层再加一重循环,这层循环用于确定当前单元格(即dp[i][j])到底取多少个物品会使得当前价值最大(但不能超过背包容量)。于是此时的状态转移方程就变成了(其中,k表示当前物品拿了多少个):
dp[i][j] = max( dp[i-1][j] , dp[i-1][ j - k*w[i] ] + k*v[i] )
这便是完全背包问题中最关键的递推式了,下面我们同样以一个实际例题来练练手
public class demo74_疯狂的采药完全dp {
static int M = 105;
static int N = 1005;
static int m, n;
static int maxValue, temp;//组合寻找每一个格子的最大价值
static int[][] dp = new int[M][N];
static int[] t = new int[M];
static int[] v = new int[M];
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
m = scanner.nextInt();
scanner.nextLine();
for (int i = 1; i <= m; i++) {
t[i] = scanner.nextInt();
v[i] = scanner.nextInt();
scanner.nextLine();
}
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++) {
maxValue = 0;//用于记录当前格中的最大值
for (int k = 0; k * t[i] <= j; k++) {//k表示当前物品拿了多少个。当k = 0时,表示不拿当前物品,即沿用上一层的数据
temp = k * v[i] + dp[i - 1][j - k * t[i]];//此时的价值 = k个当前物品的价值 + 剩余容量在上一层中对应的最大价值
if (temp > maxValue) maxValue = temp;//更新当前格中的最大价值
}
dp[i][j] = maxValue;//记录该格中的最大价值
}
System.out.println(dp[m][n]);
}
}
上述代码确实解决了完全背包问题,但是新问题也随之引出:
① 程序中使用了二维数组,在数据范围过大的情况下连编译都过不了;
② 程序中使用了三重循环,在数据范围稍大的情况下会超时。
接下来我们就着手对上面的问题进行优化。首先是降维,那就需要把状态转移方程变为:
dp[j] = max( dp[j] , dp[j - k*w[i]] + k*v[i] )
维度是降低了,但是更新方向呢?此时,我们突然想起某件事!!!在前面01背包问题中我们讨论降维时,出现了一个有趣的现象——如果更新dp数组时采用自左向右的方向,那么在后面进行更新时,其执行逻辑是“可重复拿取某件物品”!巧了,现在我们所作的假设就是所有物品都有无数件(即可重复拿),这不正好就可以拿来用了么?换言之,现在我们不再需要用最里面的那层k循环来确定某个网格到底拿多少物品才能使得背包总价值最大,而是通过采取和01背包问题中相反的更新dp数组方向来实现。
下面给出经过优化后的完整满分代码:
public class demo74_疯狂的采药_降维 {
static int M = 100005;
static int N = 10005;
static int m, n;
static int[] dp = new int[N];
static int[] t = new int[M];
static int[] v = new int[M];
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
m = scanner.nextInt();
scanner.nextLine();
for (int i = 1; i <= m; i++) {
t[i] = scanner.nextInt();
v[i] = scanner.nextInt();
scanner.nextLine();
}
/**
* 回顾01降维过程:
* 第一个单元格,此时dp[1]=max(dp[1], dp[1-1]+1500)=max(0, 0+1500)=1500;
* 第二个单元格,此时dp[2]=max(dp[2], dp[2-1]+1500)=max(dp[2], dp[1]+1500)=max(0, 1500+1500)=3000;
* 第三个单元格,此时dp[3]=max(dp[3], dp[3-1]+1500)=max(dp[3], dp[2]+1500)=max(0, 3000+1500)=4500;
* 第四个单元格,此时dp[4]=max(dp[4], dp[4-1]+1500)=max(dp[4], dp[3]+1500)=max(0, 4500+1500)=6000;
*/
for (int i = 1; i <= m; i++)
for (int j = t[i]; j <= n; j++) {
//如果正向拿取,正好达到重复拿取某一种物品的效果
dp[j] = Math.max(dp[j], v[i] + dp[j - t[i]]);
}
System.out.println(dp[n]);
}
}
多重背包问题:
一个正整数n,可以被分解成1,2,4,…,2(k-1),n-2k+1的形式。
在每一次的循环中,把拆分后的数不断重新组合并将每种组合的最大价值记录在滚动数组对应的位置,在最后一次循环的时,恰好列举出了拿该种物品1~number次每次的最大价值!值得深思与记忆!
问题描述
有容积为V的背包,给定一些物品,每种物品包含体积 w、价值 v、和数量 k,求用该背包能装下的最大价值总量。
算法分析
01背包问题与完全背包问题实际上是两种极端,而多重背包问题则正是介于这两者之间的一种情况。基于此,我们可以将多重背包问题转化为01背包或完全背包问题来进行求解。
① 可以把某种物品中的k个视为k种不同物品,此时再对所有物品按照01背包问题来进行处理。这样的转化当然是成立的,但是仅在数据范围较小时才适用,一旦每种物品的数量稍大一点,在时间上必然有超时的风险。此时,对于某种物品(假设有k个),若我们采用一种更精炼的划分方案,就会使得该物品分类下来的组数大大减少。比如可以采用二进制的拆分将原来的k个物品分为:{ 1、2、4、……、k - 2i + 1 } 这些组,以替代最初的分类:{ 1、1、1、……、1 } 这些组,这是一个log2(n)级别的数量优化。
② 若存在某个物品,其数量k乘以其单位体积大于背包总容量(即k*w[i] > V),那么此时对于该物品而言,它与背包之间是完全背包问题。
上述两点分别从01背包和完全背包的角度对多重背包问题进行了转化,而多重背包正好也是介于01背包和完全背包之间的问题。正是这两点,使得我们能设计出一个可以与“单调队列优化”分庭抗衡的算法。下面还是用一个实际例题来练手,以巩固理解。
public class demo75_超市里的狂欢夜_多重dp {
static int N = 100005;
static int M = 10005;
static int n, m;//m行 n列
static int[] dp = new int[N];
static int[] w = new int[M];
static int[] v = new int[M];
static int[] num = new int[M];
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();//列
m = scanner.nextInt();//行
scanner.nextLine();
for (int i = 1; i < m; i++) {
w[i] = scanner.nextInt();
v[i] = scanner.nextInt();
num[i] = scanner.nextInt();
scanner.nextLine();
}
for (int i = 1; i <= m; i++) {
MultiplePack(w[i], v[i], num[i]);
}
System.out.println(dp[n]);
}
static void ZeroOnePack(int weight, int value) { //01背包模型
for (int i = n; i >= weight; i--)//逆向
dp[i] = Math.max(dp[i], dp[i - weight] + value);
}
static void CompletePack(int weight, int value) { //完全背包模型
for (int i = weight; i <= n; i++)//正向
dp[i] = Math.max(dp[i], dp[i - weight] + value);
}
static void MultiplePack(int weight, int value, int number) { //多重背包模型
if (number * weight > n) {//如果总容量比这个物品的容量要小,那就退化为完全背包
CompletePack(weight, value);
} else {//否则就将其转化为01背包(并利用二进制的拆分来优化){ 1、2、4、……、k - 2i + 1 } 最后一个为一个常数c
int k = 1;
while (k <= number) {
ZeroOnePack(k * weight, k * value);
number -= k;
k = k << 2;
}
//对余下的常数c进行处理
if (number != 0) ZeroOnePack(number * weight, number * value);
}
}
}
//韩顺平——01背包问题
public class KnapsackProblem {
public static void main(String[] args) {
int[] w = {1, 4, 3};//物品的重量
int[] val = {1500, 3000, 2000}; //物品的价值 这里val[i] 就是前面讲的v[i]
int m = 4; //背包的容量
int n = val.length; //物品的个数
//创建二维数组,
//v[i][j] 表示在前i个物品中能够装入容量为j的背包中的最大价值
int[][] v = new int[n + 1][m + 1];//第一行和第一列全为0
//为了记录放入商品的情况,我们定一个二维数组
int[][] path = new int[n + 1][m + 1];
//初始化第一行和第一列, 这里在本程序中,可以不去处理,因为默认就是0
for (int i = 0; i < v.length; i++) {
v[i][0] = 0; //将第一列设置为0
}
/*for(int i=0; i < v[0].length; i++) {
v[0][i] = 0; //将第一行设置0
}*/
Arrays.fill(v[0], 0);
//根据前面得到公式来动态规划处理
for (int i = 1; i < v.length; i++) { //不处理第一行 i是从1开始的
for (int j = 1; j < v[0].length; j++) {//不处理第一列, j是从1开始的
//公式
if (w[i - 1] > j) { // 因为我们程序i 是从1开始的,因此原来公式中的 w[i] 修改成 w[i-1]
v[i][j] = v[i - 1][j];
} else {
/*说明:
因为我们的i 从1开始的, 因此公式需要调整成
v[i][j]=Math.max(v[i-1][j], val[i-1]+v[i-1][j-w[i-1]]);*/
//v[i][j] = Math.max(v[i - 1][j], val[i - 1] + v[i - 1][j - w[i - 1]]);
//为了记录商品存放到背包的情况,我们不能直接的使用上面的公式,需要使用if-else来体现公式
if (v[i - 1][j] < val[i - 1] + v[i - 1][j - w[i - 1]]) {
v[i][j] = val[i - 1] + v[i - 1][j - w[i - 1]];
//把当前的情况记录到path
path[i][j] = 1;
} else {
v[i][j] = v[i - 1][j];
}
}
}
}
//输出一下v 看看目前的情况
for (int i = 0; i < v.length; i++) {
for (int j = 0; j < v[i].length; j++) {
System.out.print(v[i][j] + " ");
}
System.out.println();
}
System.out.println("============================");
//输出最后我们是放入的哪些商品
//遍历path, 这样输出会把所有的放入情况都得到, 其实我们只需要最后的放入
// for(int i = 0; i < path.length; i++) {
// for(int j=0; j < path[i].length; j++) {
// if(path[i][j] == 1) {
// System.out.printf("第%d个商品放入到背包\n", i);
// }
// }
// }
//动脑筋
int i = path.length - 1; //行的最大下标
int j = path[0].length - 1; //列的最大下标
while (i > 0 && j > 0) { //从path的最后开始找
if (path[i][j] == 1) {
System.out.printf("第%d个商品放入到背包\n", i);
j -= w[i - 1]; //w[i-1] 剩余容量
}
i--;
}
}
}
分治
//汉诺塔————子问题于父问题没有关联
public class Hanoitower {
public static void main(String[] args) {
hanoiTower(10, 'A', 'B', 'C');
}
/**
* 分治————处理汉诺塔的移动
* -------------------------写递归不要去细想子问题的过程,因为里面的参数会随之改变,绕起来很麻烦,你只需要想清楚最底层的那一步该怎么走,
* -------------------------即:只需要想清楚“最子“的那个问题的所有情况该怎么处理,则其他父问题就和该问题一样得到解决,最终完成所有步骤
* -------------------------如:汉诺塔的”最子“问题就是:把所有的盘看成两个盘,“最下面的盘”和 ”其余的盘“ ,处理好这个问题后,其余问题随之解决
* -------------------------注意:递归程序一定要写好递归出口,其余步骤交给递归程序来完成
* @param num 需要移动的塔盘数目
* @param a 起点
* @param b 中转
* @param c 终点
*/
public static void hanoiTower(int num, char a, char b, char c) {
//如果只有一个盘
if(num == 1) {
System.out.println("第1个盘从 " + a + "->" + c);
} else {
//如果我们有 n >= 2 情况,我们总是可以看做是两个盘 1.最下边的一个盘 2. 上面的所有盘
//1. 先把 上面的所有盘(num - 1个)从A->B, 移动过程会使用到 c
hanoiTower(num - 1, a, c, b);
//2. 把最下边的盘 A->C
System.out.println("第" + num + "个盘从 " + a + "->" + c);
//3. 把B塔的所有盘 从 B->C , 移动过程使用到 a塔
hanoiTower(num - 1, b, a, c);
}
}
}
贪心
//以覆盖问题为例
public class GreedyAlgorithm {
public static void main(String[] args) {
//创建广播电台,放入到Map
HashMap<String, HashSet<String>> broadcasts = new HashMap<>();
//将各个电台放入到broadcasts
HashSet<String> hashSet1 = new HashSet<>();
hashSet1.add("北京");
hashSet1.add("上海");
hashSet1.add("天津");
HashSet<String> hashSet2 = new HashSet<>();
hashSet2.add("广州");
hashSet2.add("北京");
hashSet2.add("深圳");
HashSet<String> hashSet3 = new HashSet<>();
hashSet3.add("成都");
hashSet3.add("上海");
hashSet3.add("杭州");
HashSet<String> hashSet4 = new HashSet<>();
hashSet4.add("上海");
hashSet4.add("天津");
HashSet<String> hashSet5 = new HashSet<>();
hashSet5.add("杭州");
hashSet5.add("大连");
//加入到map
broadcasts.put("K1", hashSet1);
broadcasts.put("K2", hashSet2);
broadcasts.put("K3", hashSet3);
broadcasts.put("K4", hashSet4);
broadcasts.put("K5", hashSet5);
//allAreas 存放所有的地区
HashSet<String> allAreas = new HashSet<>();
for (HashSet<String> value : broadcasts.values()) {
allAreas.addAll(value);
}
//创建ArrayList, 存放选择的电台集合
List<String> selects = new ArrayList<>();
//定义一个临时的集合, 在遍历的过程中,存放遍历过程中的电台覆盖的地区和当前还没有覆盖的地区的交集
HashSet<String> tempSet = new HashSet<>();
//定义给maxKey , 保存在一次遍历过程中,能够覆盖最大未覆盖的地区对应的电台的key
//如果maxKey 不为null , 则会加入到 selects
String maxKey;
while (allAreas.size() != 0) { // 如果allAreas 不为0, 则表示还没有覆盖到所有的地区
//每进行一次while,需要
maxKey = null;
//遍历 broadcasts, 取出对应key
for (String key : broadcasts.keySet()) {
//每进行一次for
tempSet.clear();
//当前这个key能够覆盖的地区
HashSet<String> areas = broadcasts.get(key);
tempSet.addAll(areas);
//求出tempSet 和 allAreas 集合的交集, 交集会赋给 tempSet
tempSet.retainAll(allAreas);
//如果当前这个集合包含的未覆盖地区的数量,比maxKey指向的集合地区还多
//就需要重置maxKey
// tempSet.size() >broadcasts.get(maxKey).size()) 体现出贪心算法的特点,每次都选择最优的
if (tempSet.size() > 0 &&
(maxKey == null || tempSet.size() > broadcasts.get(maxKey).size())) {
maxKey = key;
}
}
//maxKey != null, 就应该将maxKey 加入selects
if (maxKey != null) {
selects.add(maxKey);
//将maxKey指向的广播电台覆盖的地区,从 allAreas 去掉
allAreas.removeAll(broadcasts.get(maxKey));
}
}
System.out.println("得到的选择结果是" + selects);//[K1,K2,K3,K5]
}
}
Prim(普利姆)最小生成树
普利姆(Prim)算法求最小生成树,也就是在包含n个顶点的连通图中,找出只有(n-1)条边包含所有n个顶点的连通子图,也就是所谓的极小连通子图
普利姆的算法如下:
- 设G=(V,E)是连通网,T=(u,D)是最小生成树,v,u是顶点集合,E,D是边的集合。
- 若从顶点u开始构造最小生成树,则从集合v中取出顶点u放入集合u中,标记顶点v的visited[u]=1。
- 若集合u中顶点ui与集合v-u中的顶点vj之间存在边,则寻找这些边中权值最小的边,但不能构成回路,将顶点vj加入集合u中,将边(ui,vj)加入集合D中,标记visited[vj]=1。
- 重复步骤②,直到u与v相等,即所有顶点都被标记为访问过,此时D中有n-1条边(5)提示:单独看步骤很难理解,我们通过代码来讲解,比较好理解。
自我理解:
- 创建一个空的存储顶点的点;
- 先确定一个点,将这个顶点和与它相邻的、还没访问过的顶点进行处理;
- “处理”:比较满足条件的各个边,找出最小的边,将这个顶点加入刚才的顶点集合中;
- 再重复上面的操作,直到这个顶点集合中的顶点包含了图中的全部顶点。
//修路问题(最小生成树)
public class PrimAlgorithmSimple {
public static char[] data;
public static int[][] matrix;
public static boolean[] visited;
public static final int N = Integer.MAX_VALUE;
public static void main(String[] args) {
data = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};
matrix = new int[][]{
{N, 5, 7, N, N, N, 2},
{5, N, N, 9, N, N, 3},
{7, N, N, N, 8, N, N},
{N, 9, N, N, N, 4, N},
{N, N, 8, N, N, 5, 4},
{N, N, N, 4, 5, N, 6},
{2, 3, N, N, 4, 6, N}
};
visited = new boolean[data.length];
prim(1);
}
public static void prim(int startIndex) {
visited[startIndex] = true;
int isVisited = -1;
int notVisited = -1;
int minMatrix = Integer.MAX_VALUE;
for (int k = 1; k < data.length; k++) {//一共需要length-1条边
for (int i = 0; i < data.length; i++)//查找已访问过的结点
for (int j = 0; j < data.length; j++)//查找未访问过的结点
if (visited[i] && !visited[j] && matrix[i][j] < minMatrix) {//找到权值最小的边,并记录这两个顶点
minMatrix = matrix[i][j];
isVisited = i;
notVisited = j;
}
System.out.println("边<" + data[isVisited] + "," + data[notVisited] + "> 权值:" + minMatrix);
visited[notVisited] = true;//标记访问过
minMatrix = Integer.MAX_VALUE;//重置
}
}
}
Kruskal(克鲁斯卡尔)最小生成树
克鲁斯卡尔(Kruskal)算法,是用来求加权连通图的最小生成树的算法。
基本思想
按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路。
具体做法
首先构造一个只含n个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止。
- 问题一:对图的所有边按照权值大小进行排序。
- 问题二:将边添加到最小生成树中时,怎么样判断是否形成了回路。
- 问题一很好解决,采用排序算法进行排序即可。
- 问题二的处理方式是:记录顶点在"最小生成树"中的终点,顶点的终点是"在最小生成树中与它连通的最大顶点"。然后每次需要将一条边添加到最小生存树时,判断该边的两个顶点的终点是否重合,重合的话则会构成回路。
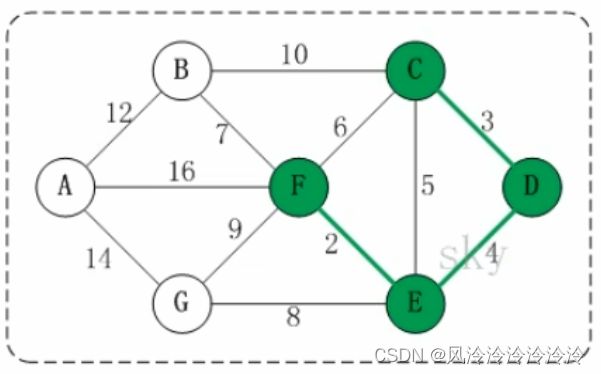
在将
- (01)C的终点是F。
- (02)D的终点是F。
- (03)E的终点是F。
- (04)F的终点是F。
关于终点的说明:(类似并查集)
- 1)就是将所有顶点按照从小到大的顺序排列好之后;某个顶点的终点就是"与它连通的最大顶点”"。
- 2)因此,接下来,虽然
//公交问题(最小生成树)
public class KruskalCaseSimple {
private static int edgeNum; //边的个数
private static char[] vertexes; //顶点数组
private static int[][] matrix; //邻接矩阵
private static int[] ends; //用于保存"已有最小生成树" 中的每个顶点在最小生成树中的终点
private static final int INF = Integer.MAX_VALUE;
public static void main(String[] args) {
vertexes = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};
matrix = new int[][]{
{0, 12, INF, INF, INF, 16, 14},
{12, 0, 10, INF, INF, 7, INF},
{INF, 10, 0, 3, 5, 6, INF},
{INF, INF, 3, 0, 4, INF, INF},
{INF, INF, 5, 4, 0, 2, 8},
{16, 7, 6, INF, 2, 0, 9},
{14, INF, INF, INF, 8, 9, 0}};
//统计边的数目
for (int i = 0; i < vertexes.length; i++)
for (int j = i + 1; j < vertexes.length; j++)
if (matrix[i][j] != INF)
edgeNum++;
ends = new int[edgeNum];
kruskal(edgeNum);
}
private static void kruskal(int number) {
int index = 0;
EDataSimple[] rets = new EDataSimple[number];//最小生成树
EDataSimple[] edges = getEdges();
//排序
sortEdges(edges);
//加入
for (int i = 0; i < number; i++) {
int m = getEnd(ends, getPosition(edges[i].start));
int n = getEnd(ends, getPosition(edges[i].end));
if (m != n) {
ends[m] = n;
rets[index++] = edges[i];
}
}
System.out.println("最小生成树:");
for (int i = 0; i < index; i++)
System.out.println(rets[i]);
}
private static void sortEdges(EDataSimple[] edges) {//冒泡
for (int i = 0; i < edges.length - 1; i++)
for (int j = 0; j < edges.length - 1 - i; j++)
if (edges[j].weight > edges[j + 1].weight) {
EDataSimple tmp = edges[j];
edges[j] = edges[j + 1];
edges[j + 1] = tmp;
}
}
private static int getPosition(char ch) {//返回顶点对应的下标,如果找不到,返回-1
for (int i = 0; i < vertexes.length; i++)
if (vertexes[i] == ch)
return i;
return -1;
}
private static EDataSimple[] getEdges() {
int index = 0;
EDataSimple[] edges = new EDataSimple[edgeNum];
for (int i = 0; i < vertexes.length; i++)
for (int j = i + 1; j < vertexes.length; j++)
if (matrix[i][j] != INF)
edges[index++] = new EDataSimple(vertexes[i], vertexes[j], matrix[i][j]);
return edges;
}
private static int getEnd(int[] ends, int i) {//获取下标为i的顶点的终点(), 用于后面判断两个顶点的终点是否相同
while (ends[i] != 0)
i = ends[i];
return i;//如果为0,返回自己
}
static class EDataSimple {//边
char start;
char end;
int weight;
public EDataSimple(char start, char end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
@Override
public String toString() {
return "EDataSimple{" +
"start=" + start +
", end=" + end +
", weight=" + weight +
'}';
}
}
}
Dijkstra(迪杰斯特拉,得到某个点到各个点之间的最短距离)
朴素dijkstra(容易爆栈)
import java.util.Arrays;
public class DijkstraAlgorithmSimpleMost {
public static char[] vertex;
public static int[][] matrix;
public static final int N = Integer.MAX_VALUE >> 1;
public static boolean[] visitedArr;
public static int[] preArr;
public static int[] disArr;
public static void main(String[] args) {
vertex = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};
matrix = new int[vertex.length][vertex.length];
matrix = new int[][]{
{N, 5, 7, N, N, N, 2},
{5, N, N, 9, N, N, 3},
{7, N, N, N, 8, N, N},
{N, 9, N, N, N, 4, N},
{N, N, 8, N, N, 5, 4},
{N, N, N, 4, 5, N, 6},
{2, 3, N, N, 4, 6, N}};
visitedArr = new boolean[vertex.length];
preArr = new int[vertex.length];
disArr = new int[vertex.length];
Arrays.fill(disArr, Integer.MAX_VALUE >> 1);
dijkstra(2);
show();
}
//广度优先寻找最短路径。与bfs一样,设置一个起点并对其进行操作,遍历出其余符合条件的结点,并依次对其进行同样的操作
public static void dijkstra(int index) {
visitedArr[index] = true;
disArr[index] = 0;
updatePreAndDis(index);
for (int j = 1; j < vertex.length; j++) {
index = updateIndex();
updatePreAndDis(index);
}
}
//比较各个顶点通过index到自己与出发点到自己的距离,如果更小则设置index为自己的前驱,并更新出发点到自己的距离
private static void updatePreAndDis(int index) {
int len;
for (int j = 0; j < matrix[index].length; j++) {
len = disArr[index] + matrix[index][j];
if (!visitedArr[j] && len < disArr[j]) {
preArr[j] = index;
disArr[j] = len;
}
}
}
//寻找当前未被访问过、并且距离出发点路程最短的结点,返回该结点的下标
public static int updateIndex() {
int min = N, index = 0;
for (int i = 0; i < visitedArr.length; i++)
if (!visitedArr[i] && disArr[i] < min) {
min = disArr[i];
index = i;
}
visitedArr[index] = true;
return index;
}
public static void show() {
char[] vertex = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
int count = 0;
for (int i : disArr) {
if (i != Integer.MAX_VALUE >> 1) {
System.out.print(vertex[count] + "(" + i + ") ");
} else {
System.out.println("N ");
}
count++;
}
System.out.println();
}
}
堆优化的dijkstra(链式前向星)
点击上方蓝色字体,看我另外一篇文章,详细讲解链式前向星。
用堆优化来降低时间复杂度
时间复杂度降到nlogn+m
堆优化了每次找离起点最近的点的时间复杂度。
邻接表优化了对于每一个基点,更新它的所有邻边的时间复杂度(上面那个就是1扫到n,很花时间)
链式前向星+优先队列
蓝桥王国
public class demo84_堆优化dijkstra_蓝桥王国 {
static int[] head, next, ends;
static long[] weights, dis;//权值和结果集
static int n, m, total = 0;//n个顶点,m条边,++total:从第一条边到最后一条边
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
head = new int[m + 1];//表示以 i 为起点的最后一条边的编号
next = new int[m + 1];//存储与当前边起点相同的上一条边的编号
ends = new int[m + 1];//存储边的终点
weights = new long[m + 1];//存储边的权值
dis = new long[n + 1];//存储最终结果
Arrays.fill(head, -1);//初始化
for (int i = 0; i < m; i++) {
int start = sc.nextInt();
int end = sc.nextInt();
long weight = sc.nextLong();
add(start, end, weight);
}
dijkstra(1);
for (int i = 1; i <= n; i++)
if (dis[i] == Long.MAX_VALUE)
System.out.print(-1 + " ");
else
System.out.print(dis[i] + " ");
}
private static void dijkstra(int startPoint) {
for (int i = 1; i <= n; i++) {
dis[i] = Long.MAX_VALUE;
}
Queue<Integer> queue = new LinkedList<>();
queue.add(startPoint);
dis[startPoint] = 0;
while (!queue.isEmpty()) {
int x = queue.poll();
//链式前向星的遍历方法,遍历出以x为起点的所有边
for (int i = head[x]; i != -1; i = next[i]) {//i表示:第 i 条边
int j = ends[i];//第 i 条边的终点
if (dis[j] > dis[x] + weights[i]) {//如果length(起点-->终点) > length(起点 --> 当前点) + length(当前点 --> 终点)
dis[j] = dis[x] + weights[i];//更新起点到终点的最短距离
queue.add(j);//并将这个终点入队,以便之后通过该点访问其他顶点
}
}
}
}
private static void add(int start, int end, long weight) {//链式前向星的创建方法
ends[++total] = end;
weights[total] = weight;
next[total] = head[start];//以start为起点的上一条边的编号,即:与这个边起点相同的上一条边的编号
head[start] = total;//更新以start为起点的上一条边的编号
}
}
Floyd(弗洛伊德,得到各个点到各个点之间的最短距离)
import java.util.Arrays;
public class FloydAlgorithmSimple {
public static char[] vertex;
public static int[][] pre;
public static int[][] matrix;
public static final int N = Integer.MAX_VALUE >> 1;
public static void main(String[] args) {
vertex = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};
pre = new int[vertex.length][vertex.length];
matrix = new int[][]{
{0, 5, 7, N, N, N, 2},
{5, 0, N, 9, N, N, 3},
{7, N, 0, N, 8, N, N},
{N, 9, N, 0, N, 4, N},
{N, N, 8, N, 0, 5, 4},
{N, N, N, 4, 5, 0, 6},
{2, 3, N, N, 4, 6, 0}
};
for (int i = 0; i < vertex.length; i++)
Arrays.fill(pre[i], i);
floyd();
show();
}
public static void floyd() {
int len;
for (int k = 0; k < matrix.length; k++)
for (int i = 0; i < matrix.length; i++)
for (int j = 0; j < matrix.length; j++) {
len = matrix[i][k] + matrix[k][j];
if (len < matrix[i][j]) {
matrix[i][j] = len;
pre[i][j] = pre[k][j];
}
}
}
public static void show() {
for (int k = 0; k < matrix.length; k++) {
for (int i = 0; i < matrix.length; i++)
System.out.print(vertex[pre[k][i]] + " ");
System.out.println();
for (int i = 0; i < matrix.length; i++)
System.out.print("(" + vertex[k] + "到" + vertex[i] + "的最短路径是" + matrix[k][i] + ") ");
System.out.println();
}
}
}
图论
图的深度优先遍历介绍深度优先遍历算法步骤
1)访问初始结点v,并标记结点v为已访问。2)查找结点v的第一个邻接结点w。
3)若w存在,则继续执行4,如果w不存在,则回到第1步,将从v的下一个结点继续。
4)若w未被访问,对w进行深度优先遍历递归(即把w当做另一个v,然后进行步骤123
5)查找结点v的w邻接结点的下一个邻接结点,转到步骤3。
图的广度优先遍历基本思想
类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来访问这些结点的邻接结点
广度优先遍历算法步骤
1)访问初始结点v并标记结点v为己访问。
2)结点v入队列
3)当队列非空时,继续执行,否则算法结束。4)出队列,取得队头结点u。
5)查找结点u的第一个邻接结点w。
6)若结点u的邻接结点w不存在,则转到步骤3;否则循环执行以下三个步骤:
6.1若结点w尚未被访问,则访问结点w并标记为已访问。
6.2结点w入队列
6.3查找结点u的继w邻接结点后的下一个邻接结点w,转到步骤6。
code
//图的遍历bfs dfs
public class Graph {
private static final int MAX_VERTS = 20;
private Vertex vertexList[];// 顶点数组
private int adjMat[][];// 邻接矩阵
private int nVerts;// 当前顶点总数
private Stack theStack;
private ArrayDeque theQueue;
public static void main(String[] args) {
Graph theGraph = new Graph(MAX_VERTS);
theGraph.addVertex('A');
theGraph.addVertex('B');
theGraph.addVertex('C');
theGraph.addVertex('D');
theGraph.addVertex('E');
theGraph.addEdge(0, 1);
theGraph.addEdge(1, 2);
theGraph.addEdge(0, 3);
theGraph.addEdge(3, 4);
System.out.print("visits:");
theGraph.dfs();
// theGraph.bfs();
System.out.println();
}
public Graph() {
}
public Graph(int vertexLength) {// 通过构造函数来构造图
vertexList = new Vertex[vertexLength];
adjMat = new int[vertexLength][vertexLength];
nVerts = 0;
for (int i = 0; i < vertexLength; i++) {
for (int j = 0; j < vertexLength; j++) {
adjMat[i][j] = 0;
}
}
theStack = new Stack();
theQueue = new ArrayDeque();
}
public void addVertex(char lab) {// 添加顶点
vertexList[nVerts++] = new Vertex(lab);
}
public void addEdge(int start, int end) {// 添加边
adjMat[start][end] = 1;
adjMat[end][start] = 1;
}
public void displayVertex(int v) {// 打印数组中v位置下的顶点名
System.out.print(vertexList[v].lable);
}
public int getAdjUnvisitedVertex(int v) {// 获取和v邻接的未访问的顶点
for (int i = 0; i < nVerts; i++) {
// if (adjMat[v][i] == 1 && vertexList[i].wasVisited == false) {
if (adjMat[v][i] == 1 && !vertexList[i].wasVisited) {
return i;
}
}
return -1;
}
public void dfs() {// 深度优先遍历
vertexList[0].wasVisited = true;
displayVertex(0);
theStack.push(0);
while (!theStack.isEmpty()) {
int v = getAdjUnvisitedVertex((Integer) theStack.peek());
if (v == -1) {
theStack.pop();
} else {
vertexList[v].wasVisited = true;
displayVertex(v);
theStack.push(v);
}
}
for (int i = 0; i < nVerts; i++) {
vertexList[i].wasVisited = false;// 重置,防止后边再次使用dfs时出错
}
}
public void bfs() {// 广度优先遍历
vertexList[0].wasVisited = true;
displayVertex(0);
theQueue.add(0);
int v2;
while (!theQueue.isEmpty()) {
int v1 = (int) theQueue.remove();
while ((v2 = getAdjUnvisitedVertex(v1)) != -1) {
vertexList[v2].wasVisited = true;
displayVertex(v2);
theQueue.add(v2);
}
}
for (int j = 0; j < nVerts; j++) {
vertexList[j].wasVisited = false;// 重置,防止后边再次使用bfs时出错
}
}
}
class Vertex {
public char lable;// 名字
public boolean wasVisited;
public Vertex(char lab) {
lable = lab;
wasVisited = false;
}
}
并查集
点击蓝字,了解详情!
种类并查集
概念
一.什么是种类并查集?
顾名思义就是把一个集合中的元素根据他们不同的关系进行分类与合并。朋友的朋友就是朋友(普通并查集)
,但敌人的敌人也是朋友(维护这种关系就是种类并查集了)。例如:有一伙人他们要拔河(分成两个队),如果小a与小b是敌对关系,那么就不能在一个队,如果小a与小c是朋友,那么他们就在一个队;(朋友的朋友就是朋友,敌人的敌人也是朋友。
) 种类并查集的作用就是不让两个有敌对关系的人在同一个队伍
二.种类并查集的应用
把朋友放在同一集合里,把敌人放另一集合里。放一起会打架 开两倍pre数组,一倍放朋友,二倍放敌人。 如果关系再多点那就再开大点呗。
例题:蓝桥侦探(middle)
import java.io.*;
public class demo77_种类并查集_蓝桥侦探 {
static int N = 500000;
static int M = 500000;
static int n, m;
static int[] pre = new int[2 * N + 5];
static int[] rank = new int[2 * N + 5];
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
public static void main(String[] args) throws IOException {
String[] first = br.readLine().split(" ");
n = Integer.parseInt(first[0]);//大臣的数量
m = Integer.parseInt(first[1]);//口供的数量
init(n);
int x, y;
for (int i = 0; i < m; i++) {
String[] temp = br.readLine().split(" ");
x = Integer.parseInt(temp[0]);
y = Integer.parseInt(temp[1]);
if (find(x) != find(y)) {
join(x, y + n);
join(x + n, y);
} else {
System.out.println(x);
break;
}
}
}
static void init(int n) {
for (int i = 0; i < 2 * n + 5; i++) {//两种关系 --> 开两倍
pre[i] = i;
rank[i] = i;
}
}
static int find(int x) {
if (pre[x] == x) return x;
return pre[x] = find(pre[x]);
}
static void join(int x, int y) {
x = find(x);
y = find(y);
if (rank[x] > rank[y]) pre[y] = x;
else {
if (rank[x] == rank[y]) rank[y]++;
pre[x] = y;
}
}
}
常用函数
1.Integer.toString(int par1,int par2),par1表示要转成字符串的数字,par2表示要转成的进制表示
Integer.toString(22),表示把22转成10进制表示的字符串
Integer.toString(22,2),表示把22转成2进制表示的字符串
2. Integer.parseInt(String)
将String字符类型数据转换为Integer整型数据,遇到一些不能被转换为整型的字符时,会抛出异常。
3. String.valueOf()
用法如下:
int i = 10;
String str = String.valueOf(i);
这时候 str 就会是 "10"
(1)String.valueOf(Object obj) : 将 obj 对象转换成 字符串, 等于 obj.toString()
// int、float、double、char、boolean、long类型等
(2)String.valueOf(char[] data) : 将 char 数组 data 转换成字符串
(3)String.valueOf(char[] data, int offset, int count) : 将 char 数组 data 中 由 data[offset] 开始取 count 个元素 转换成字符串
4.str.charAt(i);的作用
String str = "leetcode";
则 str.charAt(0) 为"l"
str.charAt(1) 为"e"
str.charAt(2) 为"e"
常用容器
迭代器遍历
//例如:
PriorityQueue<Integer> collection = new PriorityQueue<>((a, b) -> a - b);
Iterator iterator = collection.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
你会发现,所有容器几乎都是 add或者push添加元素,pop或者remove之类的删除元素 , find()之类的查找元素 ,只不过底层实现可能不同
ArrayList:底层是一个数组,擅长数据的查找(访问)
LinkedList:底层链表,擅长数据的修改(包括数据添加和删除)
Queue:队列
Queue queue = new LinkedList<>();
队列常用方法
add 增加一个元索 如果队列已满,则抛出一个IIIegaISlabEepeplian异常
remove 移除并返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
element 返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
offer 添加一个元素并返回true 如果队列已满,则返回false
poll 移除并返问队列头部的元素 如果队列为空,则返回null
peek 返回队列头部的元素 如果队列为空,则返回null
put 添加一个元素 如果队列满,则阻塞
take 移除并返回队列头部的元素 如果队列为空,则阻塞
drainTo(list) 一次性取出队列所有元素
知识点: remove、element、offer 、poll、peek 其实是属于Queue接口。
HashSet:集合
public boolean retainAll(Collection c)
此方法将集合c作为包含要从该集合保留的元素的参数。
例如:
tempSet.retainAll(allAreas);//求出tempSet 和 allAreas 集合的交集, 交集会赋给 tempSet
Map :键值对
元素查询的操作:
Object get(Object key):获取指定key对应的value
boolean containsKey(Object key):是否包含指定的key
boolean containsValue(Object value):是否包含指定的value
int size():返回map中key-value对的个数
boolean isEmpty():判断当前map是否为空
boolean equals(Object obj):判断当前map和参数对象obj是否相等
@Test
public void test2() {
Map map = new HashMap();
map.put("AA", 123);
map.put("ZZ", 251);
map.put("CC", 110);
map.put("RR", 124);
map.put("FF", 662);
System.out.println(map);//{AA=123, ZZ=251, CC=110, RR=124, FF=662}
//Object get(Object key):获取指定key对应的value
System.out.println(map.get("AA"));//123
//boolean containsKey(Object key):是否包含指定的key
System.out.println(map.containsKey("ZZ"));//true
//boolean containsValue(Object value):是否包含指定的value
System.out.println(map.containsValue(123));//true
//int size():返回map中key-value对的个数
System.out.println(map.size());//5
//boolean isEmpty():判断当前map是否为空
System.out.println(map.isEmpty());//false
//boolean equals(Object obj):判断当前map和参数对象obj是否相等
Map map1 = new HashMap();
map1.put("AA", 123);
map1.put("ZZ", 251);
map1.put("CC", 110);
map1.put("RR", 124);
map1.put("FF", 662);
System.out.println(map.equals(map1));//true
}
- 将map集合中的所有value取出,放入Collection集合中
//Collection中Type的类型,取决于map中value的类型
Collection values = map.values();
System.out.println(values);//[女儿国国王, 黑熊精, 黄毛怪, 黑熊精] - map集合的迭代
/**方式一:
* 遍历map中的数据,但是map本身没有迭代器,所以需要先转换成set集合
* Set:把map中的所有key值存入到set集合当中--keySet()*/
//4.1将map集合中的key值取出存入set集合中,集合的泛型就是key的类型Integer
Set<Integer> keySet = map.keySet();
//4.2想要遍历集合就需要获取集合的迭代器
Iterator<Integer> it = keySet.iterator();
//4.3循环迭代集合中的所有元素
while(it.hasNext()){//判断是否有下一个元素可以迭代
Integer key = it.next();//拿到本轮循环中获取到的map的key
String value = map.get(key);
System.out.println("{"+key+","+value+"}");
}
/**方式二:
* 遍历map集合,需要把map集合先转成set集合
* 是把map中的一对键值对key&value作为一个Entry整体放入set
* 一对K,V就是一个Entry*/
Set<Map.Entry<Integer, String>> entrySet = map.entrySet();
//获取迭代器
Iterator<Map.Entry<Integer, String>> it2 = entrySet.iterator();
while(it2.hasNext()){//判断是否有下一个元素可迭代
//本轮遍历到的一个Entry对象
Map.Entry<Integer, String> entry = it2.next();
Integer key = entry.getKey();//获取Entry中的key
// Integer key2 = it2.next().getKey();//效果同上
String value = entry.getValue();//获取Entry中的value
System.out.println("{"+key+","+value+"}");
}
PriorityQueue:优先队列(堆)
PriorityQueue<Integer> heap = new PriorityQueue<>();// 默认情况下是小根堆
//也可以用比较器来改变排序方法,从而达到自定义大小根堆的目的
PriorityQueue<Integer> smallHeap = new PriorityQueue<>((a, b) -> a - b);
PriorityQueue<Integer> bigHeap = new PriorityQueue<>((a, b) -> b - a);
//接下来遍历堆,大根堆是从大到小的,小跟堆是从小到大的
for (Integer integer : heap) {
System.out.print(integer + " ");
}
1、PriorityQueue概述
Java PriorityQueue 实现了 Queue 接口,不允许放入 null 元素;其通过堆实现,具体说是
通过完全二叉树(complete binary tree)实现的小顶堆(任意一个非叶子节点的权值,都不
大于其左右子节点的权值),也就意味着可以通过数组来作为PriorityQueue 的底层实现,
数组初始大小为11;也可以用一棵完全二叉树表示。
优先队列的作用是能保证每次取出的元素都是队列中权值最小的(Java的优先队列每次
取最小元素,C++的优先队列每次取最大元素)。这里牵涉到了大小关系,元素大小的评判
可以通过元素本身的自然顺序(natural ordering),也可以通过构造时传入的比较
(Comparator,类似于C++的仿函数)。
2、常用方法总结
public boolean add(E e); //在队尾插入元素,插入失败时抛出异常,并调整堆结构
public boolean offer(E e); //在队尾插入元素,插入失败时抛出false,并调整堆结构
public E remove(); //获取队头元素并删除,并返回,失败时前者抛出异常,再调整堆结构
public E poll(); //获取队头元素并删除,并返回,失败时前者抛出null,再调整堆结构
public E element(); //返回队头元素(不删除),失败时前者抛出异常
public E peek();//返回队头元素(不删除),失败时前者抛出null
public boolean isEmpty(); //判断队列是否为空
public int size(); //获取队列中元素个数
public void clear(); //清空队列
public boolean contains(Object o); //判断队列中是否包含指定元素(从队头到队尾遍历)
public Iterator<E> iterator(); //迭代器
3、堆结构调整
每次插入或删除元素后,都对队列进行调整,使得队列始终构成最小堆(或最大堆)。
具体调整如下:
- 插入元素后,从堆底到堆顶调整堆;
- 删除元素后,将队尾元素复制到队头,并从堆顶到堆底调整堆。
小根堆结构调整
插入( add()和offer()方法 )元素后,向上调整堆:
//siftUp()
private void siftUp(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;//parentNo = (nodeNo-1)/2
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)//调用比较器的比较方法
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
删除( remove()和poll()方法 )元素后,向下调整堆:
//siftDown()
private void siftDown(int k, E x) {
int half = size >>> 1;
while (k < half) {
//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
int child = (k << 1) + 1;//leftNo = parentNo*2+1
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;//然后用c取代原来的值
k = child;
}
queue[k] = x;
}
4、应用:topK问题
topK问题是指:从海量数据中寻找最大的前k个数据,比如从1亿个数据中,寻找最大的1万个数。
使用优先队列,能够很好的解决这个问题。先使用前1万个数构建最小优先队列,以后每取
一个数,都与队头元素进行比较,若大于队头元素,就将队头元素删除,并将该元素添加到
优先队列中;若小于队头元素,则将该元素丢弃掉。如此往复,直至所有元素都访问完。最
后优先队列中的1万个元素就是最大的1万个元素。
例1: 给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。你需要找的是数组
排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4 输出: 4
public class Main {
public static void main(String[] args) {
//int[] arr = new int[]{3,2,1,5,6,4};
int[] arr = new int[]{3,2,3,1,2,4,5,5,6};
int k = 4;
test(arr,k);
}
/**
* 方法三:PriorityQueue 优先队列思想
* 返回数组第k个最大数据
* @param nums
* @param k
*/
public static int findKthLargest3(int[] nums, int k){ //时间复杂度:O(NlogK),遍历数据 O(N),堆内元素调整 O(K),空间复杂度:O(K)
int len = nums.length;
// 使用一个含有 k 个元素的最小堆
// k 堆的初始容量,(a,b) -> a -b 比较器
PriorityQueue<Integer> minTop = new PriorityQueue<>(k,(a, b) -> a -b);
for (int i = 0; i < k; i++){
minTop.add(nums[i]);
}
for (int i = k; i < len; i++){
Integer topEle = minTop.peek(); // 返回队头元素(不删除),失败时前者抛出null
// 只要当前遍历的元素比堆顶元素大,堆顶弹出,遍历的元素进去
if (nums[i] > topEle){
minTop.poll(); // 获取队头元素并删除,并返回,失败时前者抛出null,再调整堆结构
minTop.offer(nums[i]); // 在队尾插入元素,插入失败时抛出false,并调整堆结构
}
}
return minTop.peek();
}
public static void test(int[] input,int key){
long begin = System.currentTimeMillis();
int result = findKthLargest3(input,key);
System.out.println("result = " + result);
long end = System.currentTimeMillis();
System.out.println();
System.out.println("耗时:" + (end - begin) + "ms");
System.out.println("--------------------");
}
}
运行结果:

例2:
求 数组nums={6,14,71,21,9,18,1,4,23,0,45,66} 中最大的5个数
import java.util.PriorityQueue;
public class Main {
static int[] nums={6,14,71,21,9,18,7,4,23,0,45,66};
public static void main(String[] args) {
topK();
}
public static void topK() {
PriorityQueue<Integer> queue = new PriorityQueue<Integer>();
for(int i=0; i<5; i++) {
queue.add(nums[i]);
}
for(int i=5; i<12; i++) {
if(nums[i] > queue.element()) {
queue.remove();
queue.add(nums[i]);
}
}
while(!queue.isEmpty()) {
int Ele=queue.remove();
System.out.print(Ele+" ");
}
}
}
运行结果:
![[图片]](http://img.e-com-net.com/image/info8/eabec126ae07427f8e389241c9abf5c9.jpg)
Sort
1.2.3 时间复杂度为O(n^2),4和5的时间复杂度是O(n lgN)
(1)冒泡排序:每一轮都会把大的数字往后挪
(2)插入排序:每一轮把当前的元素往前比较,然后插入到对应的位置
(3)选择排序:每一轮找到剩下空间中最小的值,然后把它放到区间的最前面
(4)堆排序:每次弹出堆顶元素,然后用剩下的元素调整堆,不停重复这个过程
(5)快速排序
- 每一轮找到一个基准位置(一般选择最开头的元素),然后把比基准大的元素放到基准的右边,把比基准小的元素放到基准的左边,这样的话就会以基准为界,形成两个区间
- 对这两个区间,重复上面的操作
- 不停的递归,最终形成数组有序
BubbleSort
package java_wuji.JXY.algorithm;
import java.util.Arrays;
public class BubbleSort {
public static void main(String[] args) {
int[] arr = {3, 9, -1, 10, 20};
//测试冒泡排序
bubbleSort(arr);
System.out.println(Arrays.toString(arr));
}
public static void bubbleSort(int[] arr) {
// 冒泡排序 的时间复杂度 O(n^2), 自己写出
int temp; // 临时变量
boolean flag = false; // 标识变量,表示是否进行过交换
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
// 如果前面的数比后面的数大,则交换
if (arr[j] > arr[j + 1]) {
flag = true;
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
if (!flag) { // 在一趟排序中,一次交换都没有发生过
break;
} else {
flag = false; // 重置flag!!!, 进行下次判断
}
}
}
}
SelectSort
package java_wuji.JXY.algorithm;
import java.util.Arrays;
//选择排序
public class SelectSort {
public static void main(String[] args) {
int[] arr = {101, 34, 119, 1, -1, 90, 123};
selectSort(arr);
}
//选择排序
public static void selectSort(int[] arr) {
//选择排序时间复杂度是 O(n^2)
for (int i = 0; i < arr.length - 1; i++) {//length - 1 是因为,当倒数第二次排序时,最后一个一定是最大值
int minIndex = i;
int min = arr[i];
for (int j = i + 1; j < arr.length; j++) {
if (min > arr[j]) { // 说明假定的最小值,并不是最小
min = arr[j]; // 重置min
minIndex = j; // 重置minIndex
}
}
// 将最小值,放在arr[i], 即交换
if (minIndex != i) {
arr[minIndex] = arr[i];
arr[i] = min;
}
System.out.println("第" + (i + 1) + "轮后~~");
System.out.println(Arrays.toString(arr));
}
}
}
QuickSort
package java_wuji.JXY.algorithm;
import java.util.Arrays;
public class QuickSort {
public static void main(String[] args) {
int[] arr = {-9, 78, 0, 23, -567, 70, -1, 900, 4561};
quickSort(arr, 0, arr.length - 1);
System.out.println("arr=" + Arrays.toString(arr));
}
public static void quickSort(int[] arr, int left, int right) {
int l = left; //左下标
int r = right; //右下标
int mid = arr[(left + right) / 2];
int temp; //临时变量,作为交换时使用
//while循环的目的是让比mid 值小放到左边
//比mid 值大放到右边
while (l < r) {
while (arr[l] < mid) l += 1;//在mid的左边一直找,找到大于等于mid值,才退出,最坏的情况就是找到mid本身
while (arr[r] > mid) r -= 1;//在mid的右边一直找,找到小于等于mid值,才退出
if (l >= r) break;//如果l >= r说明mid 的左右两的值,已经按照左边全部是小于等于mid值,右边全部是大于等于mid值 --> 满足,break
temp = arr[l];//找到两个需要交换的数 --> 交换
arr[l] = arr[r];
arr[r] = temp;
//以下两个判断:由于上面的l += 1操作,如果交换完毕后,l/r下标等于中轴了,代表左/右边已经全部小/大于中轴值,则让r/l一直前/后移与中轴值进行比较
//如果交换完后,发现这个arr[l] == mid值 相等 r--, 前移 形成l>=r的条件,以便退出循环
if (arr[l] == mid) r--;
//如果交换完后,发现这个arr[r] == mid值 相等 l++, 后移 形成l>=r的条件,以便退出循环
if (arr[r] == mid) l++;
}
// 如果 l == r, 必须l++, r--, 否则为出现栈溢出!!!!!!!!!!因为相等的话会跳过while循环,无限递归
if (l == r) {
l += 1;
r -= 1;
}
//向左递归
if (left < r) quickSort(arr, left, r);
//向右递归
if (right > l) quickSort(arr, l, right);
}
}
InsertSort
package java_wuji.JXY.algorithm;
import java.util.Arrays;
public class InsertSort {
public static void main(String[] args) {
int[] arr = {101, 34, 119, 1, -1, 89};
System.out.println("从下标为1的数开始进行插入排序,每次向前找插入点,未满足条件的往后面覆盖(移动),过程如下:");
insertSort(arr); //调用插入排序算法
// System.out.println(Arrays.toString(arr));
}
//插入排序 向前比较
public static void insertSort(int[] arr) {
int insertVal, insertIndex;
for (int i = 1; i < arr.length; i++) {
insertVal = arr[i];//定义待插入的数
insertIndex = i - 1; // 即arr[i]前面这个数的下标
/*
给insertVal 找到插入的位置,说明:
1. insertIndex >= 0 保证在给insertVal 找插入位置,不越界
2. insertVal < arr[insertIndex] 待插入的数,还没有找到插入位置
3. 就需要将 arr[insertIndex] 后移
*/
while (insertIndex >= 0 && insertVal < arr[insertIndex]) {
arr[insertIndex + 1] = arr[insertIndex];// arr[insertIndex] 没找到要插入的点,把当前的值覆盖掉后面的值(移动)
insertIndex--;//继续向前找
}
// 当退出while循环时,说明插入的位置找到, insertIndex + 1
//这里我们判断是否需要赋值
if (insertIndex + 1 != i) arr[insertIndex + 1] = insertVal;
System.out.println("第" + i + "轮插入");
System.out.println(Arrays.toString(arr));
}
}
}
HeapSort
package java_wuji.JXY.algorithm;
import java.util.PriorityQueue;
public class HeapSort {
public static void main(String[] args) {
int[] arr = {101, 34, 119, 1, -1, 90, 123};
heapSort(arr);
}
//堆排序
public static void heapSort(int[] arr) {
//选择排序时间复杂度是 O(nlogN)
PriorityQueue<Integer> heap = new PriorityQueue<>(arr.length, (a, b) -> (b - a));//大根堆
for (int i : arr)
heap.offer(i);
while (!heap.isEmpty())
System.out.print(heap.poll()+" ");
}
}
StackQueue
用栈来实现队列
package java_wuji.JXY.algorithm;
import java.util.Stack;
public class StackQueue {
static Stack<Integer> inStack = new Stack<>();
static Stack<Integer> outStack = new Stack<>();
// 入队
static void push(int value) {
inStack.push(value);
}
// 出队
// (1)outStack为空,把inStack里的所有元素倒入到outStack内,然后pop,注意不需要倒回去!!
// (2) outStack不为空,直接从outStack里pop
static int pop() {
if (outStack.isEmpty())
while (!(inStack.isEmpty()))
outStack.push(inStack.pop());
return outStack.pop();
}
public static void main(String[] args) {
StackQueue sq = new StackQueue();
sq.push(1);
sq.push(2);
sq.push(3);
System.out.println(sq.pop());//1
sq.push(4);
System.out.println(sq.pop());//2
}
}
双指针
public class LinkedListTest {
public static class LinkedNode {
public int value;
public LinkedNode next;
}
public static void print(LinkedNode head) {
while (head != null) {
System.out.print(head.value + " ");
head = head.next;
}
System.out.println();
}
//判断是否有环 --- 双指针!!!
public static boolean isCycle(LinkedNode head) {
LinkedNode fast = head;
LinkedNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) {
return true;
}
}
return false;
}
//返回倒数第k个节点的值(无环)
public static int getNthFromEnd(LinkedNode head, int k) {
LinkedNode fast = head;
LinkedNode slow = head;
//先让他们间隔k-1个距离,即:规定好初始时的间隔
for (int i = 0; i < k - 1; i++) {
fast = fast.next;
}
//当fast指向最后一个结点时结束循环
while (fast.next != null) {
fast = fast.next;
slow = slow.next;
}
return slow.value;
}
//合并两个有序无环单链表,返回新链表的头结点
public static LinkedNode mergedTwoSortedLinkedList(LinkedNode l1, LinkedNode l2) {
LinkedNode preHead = new LinkedNode();
LinkedNode prev = preHead;
while (l1 != null && l2 != null) {
if (l1.value <= l2.value) {
prev.next = l1;
l1 = l1.next;
} else {
prev.next = l2;
l2 = l2.next;
}
prev = prev.next;
}
// 合并后 l1 和 l2 最多只有一个还未被合并完,我们直接将链表末尾指向未合并完的链表即可
prev.next = l1 == null ? l2 : l1;
return preHead.next;
}
public static void main(String[] args) {
LinkedNode node1 = new LinkedNode();
node1.value = 1;
LinkedNode node2 = new LinkedNode();
node2.value = 2;
LinkedNode node3 = new LinkedNode();
node3.value = 3;
LinkedNode node4 = new LinkedNode();
node4.value = 4;
node1.next = node2;
// node2.next = node3;
node3.next = node4;
// node4.next = node1;//形成环
// print(node1);
// System.out.println(isCycle(node1));
// System.out.println(getNthFromEnd(node1, 2));
LinkedNode node = mergedTwoSortedLinkedList(node1, node3);
print(node);
}
}
TopK
package java_wuji.JXY.algorithm;
import java.util.PriorityQueue;
public class HeapTopK {
public static void main(String[] args) {
//int[] arr = new int[]{3,2,1,5,6,4};
int[] arr = new int[]{3, 2, 3, 1, 2, 4, 5, 5, 6};
int k = 4;
test(arr, k);
}
/**
* 方法三:PriorityQueue 优先队列思想
* 返回数组第k个最大数据
*
* @param nums
* @param k
*/
public static int findKthLargest3(int[] nums, int k) { //时间复杂度:O(NlogK),遍历数据 O(N),堆内元素调整 O(K),空间复杂度:O(K)
int len = nums.length;
// 使用一个含有 k 个元素的最小堆
// k 堆的初始容量,(a,b) -> a -b 比较器
PriorityQueue<Integer> minTop = new PriorityQueue<>(k, (a, b) -> a - b);
for (int i = 0; i < k; i++) {
minTop.add(nums[i]);
}
for (int i = k; i < len; i++) {
Integer topEle = minTop.peek(); // 返回队头元素(不删除),失败时前者抛出null
// 只要当前遍历的元素比堆顶元素大,堆顶弹出,遍历的元素进去
if (nums[i] > topEle) {
minTop.poll(); // 获取队头元素并删除,并返回,失败时前者抛出null,再调整堆结构
minTop.offer(nums[i]); // 在队尾插入元素,插入失败时抛出false,并调整堆结构
}
}
return minTop.peek();
}
public static void test(int[] input, int key) {
long begin = System.currentTimeMillis();
int result = findKthLargest3(input, key);
System.out.println("result = " + result);
long end = System.currentTimeMillis();
System.out.println();
System.out.println("耗时:" + (end - begin) + "ms");
System.out.println("--------------------");
}
}
总结
算法路漫漫,最难的是坚持,希望本文能帮助到大家!
参考文献不太好例举,因为这些内容是平时日积月累下来的,
如有侵权请联系删除!