突破硬件瓶颈(二):存储架构和协议瓶颈
Linux系统设计之初,采用了分级、分层设计方式,用户调用底层设备,需要切换到内核态,由系统进行调用,这种方式适合硬盘速度远低于CPU的场景。
然而随着存储速度越来越快,以及网络存储的兴起,这种设计逐渐成为了存储的瓶颈。另外,本地硬盘协议,以及网络协议,也都成为了提高性能的绊脚石。
本文是突破硬件瓶颈系列文章的第二篇,上一篇主要Intel体系架构主讲述本地和网络存储架构,以及网络协议带来的瓶颈。
硬盘的瓶颈
1 AHCI到NVMe
虽然这并不是重点,但是作为基础,我们必须要提一下。
传统的HDD机械硬盘因为结构原因,速度和延迟均难以令人满意,且提升空间不大,而SATA接口的固态硬盘尽管提高了读写速度,也远没能释放闪存的性能。
SATA/SAS接口多数由RAID卡或是PCH扩展而来,并非CPU直接控制,造成了很高的延迟,而且接口本身的速度上限是6/12Gbps,难以进一步提高。
这两点均限制了硬盘本身性能的上限。早期存储设备发展缓慢,CPU速度远比硬盘快,因此有较多的不合理设计,在近些年存储设备快速发展后显得“格格不入”。
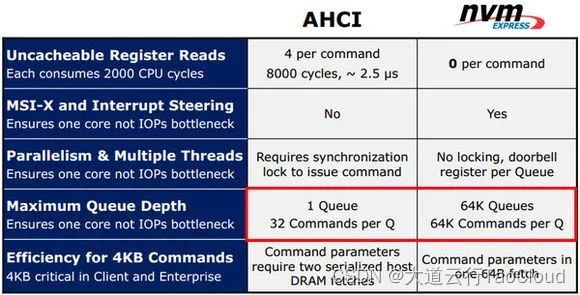
AHCI只设计了一个队列,且队列深度为64,现有的高速硬盘已经几乎将他占满,遥想当年,对于机械硬盘,32深度似乎已经“绰绰有余”了。
NVMe拥有更低的延迟,支持更高级的MSI-X中断,并且充分考虑到了未来存储设备的发展,预留了64K个队列,且队列深度上限是64K,这种设计下,目前的硬盘连十万分之一都无法发挥,为Optane或更远未来的新兴存储介质做好了伏笔。
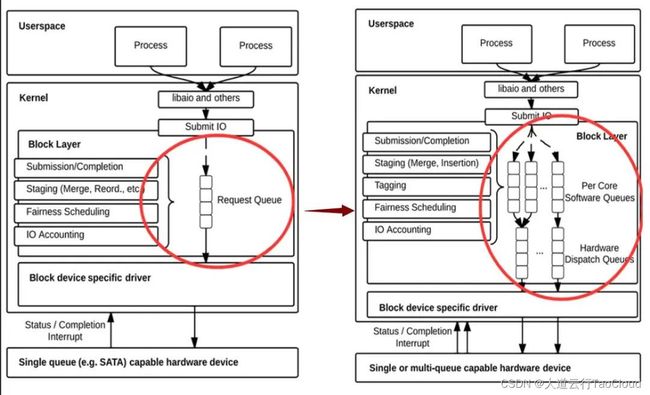
在linux 3.13内核中,也加入了IO Multi-Queue机制,和NVMe的多队列相辅相成。
SATA、SAS的速度受限于接口,速度只有6/12Gbps,而NVMe硬盘采用U.2\M.2\PCI-E Slot等介面,速度可以轻松达到32/64Gbps甚至更高。
因此,采用NVMe硬盘,是提高存储性能的必要途径。
FASS在支持传统的SATA硬盘的同时,更建议用户采用全NVMe硬盘,以获得更高的性能。
然而,仅仅是本地提升并不能解决所有问题,就如SCSI有iSCSI用于网络传输一样,NVMe同样也应该有它的网络传输协议。
2 iSCSI到NVMe-oF
NVMe委员会并不会闲着,他们很快起草并通过审核了NVMe 1.4规范,包含众多新特性,其中对于NVMe over Fabrics(下简称为NVMe-oF)的支持受到了广泛关注。
大约90%的基于fabric的NVMe协议与本地NVMe协议相同。
对于用户而言,他可以简单理解为NVMe的iSCSI,允许共享和挂载远端的NVMe设备。
 在标识上,NVMe-oF也参考了iSCSI的IQN,采用了NQN,命名规则与之相似。
在标识上,NVMe-oF也参考了iSCSI的IQN,采用了NQN,命名规则与之相似。
毫无疑问,以高性能为目标的FASS分布式存储,采用了NVMe-oF技术。
网络传输协议瓶颈
目前分布式存储已经是主流,在容量需求已经得到相对满足的今天,性能需求越来越迫切。
然而性能的提升异常艰难,我们被迫要推翻某些Linux早期的设计,这也代表存储性能发展,终于超出了前辈们的设想,或许这也代表了我们存储人的成就。
1 Linux原始设计
如何降低提交和进行网络传输过程中所产生的延迟,是提升性能的关键,他们主要来自于内存拷贝、上下文切换、以及中断。
发生上下文切换时,CPU需要将寄存器中的用户态(user context)的指令位置保存起来,停止并转而执行内核态(kernel context)的代码,CPU寄存器需要更新为内核态的新位置,最后跳转到内核态执行内核调用。调用完成后,再恢复之前的用户态。
我们以将一个文件,从用户端通过网络发送到存储端为例。这个过程,可以分解为客户端的发送和服务端的接收。
( 此处仅说明客户端发送的过程,而服务端的接收同理。)

1、用户处于用户态,进行上下文切换到内核态,这是第一次上下文切换,计为S1。
2、将文件从硬盘读取到内核态的内存缓冲区(kernel buffer),发生1次拷贝,记为C1,这次拷贝因为是慢介质(硬盘)向快介质(内存)拷贝,速度受限于慢介质。
3、将文件从内核态的内存区域拷贝到用户态的内存区域,发生C2,这次拷贝是快介质(内存)向快介质(内存)拷贝,由CPU内IMC直接调用,速度较快。
4、拷贝完成,从内核态切换回用户态,发生S2。
至此,用户仅仅拿到了属于自己的文件而已,接下来,他需要将数据送到网卡发送。
5、进行上下文切换,由用户态转换为内核态,发生S3
6、调用内核函数,将文件从用户态内存拷贝到内核态的Socket缓存,发生C3。
7、将文件拷贝到网卡缓存,这里是异步发送,不一定成功,发生C4。
8、最后切换回用户态,发生S4。
至此,发生四次上下文切换,四次内存拷贝,仅仅将数据发送出去而已。而服务器端的情况与客户端类似,同样有四次上下文切换和内存拷贝。
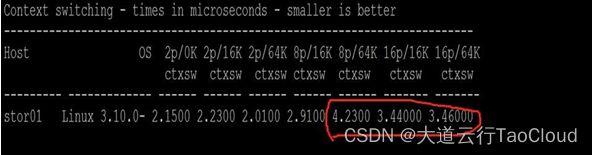 一次文件传输需要8次的上下文切换和内存拷贝,严重浪费了CPU和内存,造成了大量延迟。
一次文件传输需要8次的上下文切换和内存拷贝,严重浪费了CPU和内存,造成了大量延迟。
经过测试,上下文切换时间是3us左右,我们可以通过一个典型场景计算上下文切换的造成的巨大性能损失。
如某节点目标提供100万IOPS,为了简便计算,我们假设每次IOPS需要8次上下文切换,每次3us,那么每秒造成的上下文切换为800万次,单核需要执行24秒。
换句话说,我们需要24颗CPU核心专门满足上下文切换的开销,才能跟得上IOPS。
类似的,内存拷贝也会造成延迟和速度降低,我们大可以从宏观量化内存拷贝造成的速度降低,八倍的内存拷贝相比于一次,乐观估计也要降低八倍的速度。
内存的延迟为60-80ns左右,8次拷贝就会造成640ns的延迟,这些延迟相比于上下文切换并不大,但是内存拷贝却造成了明显的速度瓶颈。
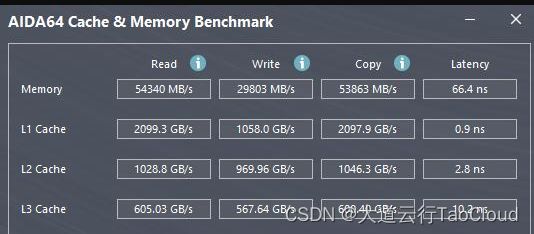
内存的读写速度为数十GB/S(图中测试条件为双通道,内存频率3733),如果进行任何的读写都需要在本地内存进行八次拷贝,那代表即便网络和硬盘写入瞬间完成,带宽极限也只有内存的八分之一,如果再考虑从硬盘读取和写入降低的速度,以及网络的传输,速度会进一步降低。
对于单块硬盘,这个速度是可以接受的,但是对于多块NVMe硬盘的存储服务器来说,这个速度就远低于理想值了,即便服务器端的libaio可以缓解这个问题,但是客户端的延迟仍然无法解决。
2 RDMA技术的引入
绕过无意义的内存拷贝和上下文切换成了提高存储性能的当务之急。RDMA就是为了解决这个问题而生,其中InfiniBand网络下的RDMA的性能最为优秀。
RDMA直接建立两端用户态内存数据的传输,在服务端和客户端各省去了一半的内存拷贝和上下文切换。
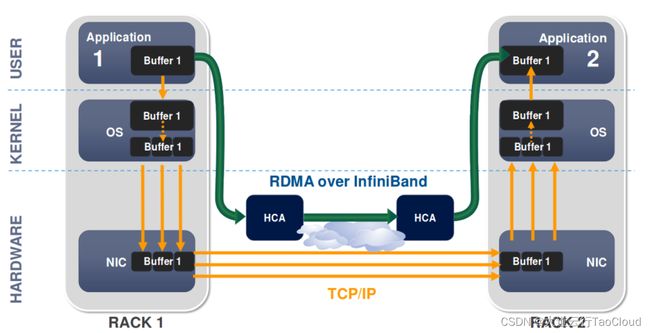 此外,RDMA将负载转移到NIC上,不需要CPU参与和计算,避免了CPU开销,还躲过了CPU中断造成的延迟增加。
此外,RDMA将负载转移到NIC上,不需要CPU参与和计算,避免了CPU开销,还躲过了CPU中断造成的延迟增加。
但是RDMA技术仅相当于完成了网络传输的任务,他并没有解决本地延迟的问题。
以客户端为例,本地硬盘的文件,要拷贝到RDMA IB网卡对应的内存区,仍然需要2次内存拷贝和2次上下文切换,之后才能“享受”RDMA技术直接传输到服务端内存区域的待遇。
为了解决这个问题,我们还需要另一项技术的帮助。
3 SPDK
SPDK(Storage Performance Development Kit),由Intel开发并开源,包含一套驱动程序,以及一整套端到端的存储参考架构。
SPDK的目标是能够把硬件平台的计算、网络、存储的最新性能进展充分发挥出来。自芯片而上进行设计优化,SPDK已展示出超高的性能指标。
它的高性能实际上来自于两项核心技术:第一个是用户态运行,第二个是轮询(polling)模式驱动。前者是显著降低延迟的原因,而后者则和FASS的高性能理念不谋而合。按照SPDK官方文档描述,他能将一次任务提交的延迟从5800ns降低到600ns左右。

5800ns的延迟主要来自于2次上下文切换和2次内存拷贝,SPDK可以将硬盘驱动在用户态运行,省去了所有的上下文切换,仅进行一次由硬盘到内存的拷贝,达到了600ns的惊人成绩。
SPDK在网络上完美对接RDMA,降低了延迟,并且提供了丰富的本地接口,完善了从硬盘设备驱动,到NVMe-oF Target等操作在用户态下完成的方法。
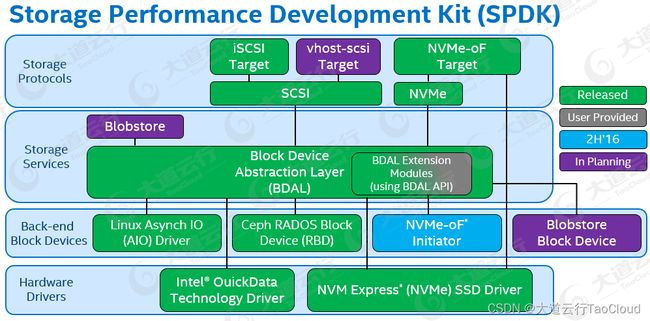
上图为SPDK的架构图,FASS采用了SPDK的少数组件,自己实现了其余部分。
我们分层讲述FASS所采用的SPDK部分。
硬件驱动层:
NVMe Driver:SPDK的基础组件,这个高优化无锁的NVMe硬盘驱动提供了高扩展性,高效性和高性能,采用UIO技术,在用户空间运行。
后端块设备层:
NVMe over Fabrics initiator:NVMe-oF本地客户端启动器,从程序员的角度来看,本地SPDK NVMe驱动和NVMe-oF启动器共享一套API命令。这意味着本地到远程的拷贝就像本地拷贝一样,非常容易实现。
绕过了最后的上下文切换,FASS真正实现了将能节省的延迟,全部节省掉。
总结
由以上分析,得出存储架构和协议瓶颈以及解决方式如下:

当然,即便是运用如此多的技术,想要获得理想的性能,仍然还有许多工作要做,这部分内容将在系列文章的后续中为您讲述。