SparkSQL项目实战:TopN
文章目录
-
- 数据准备
- 需求描述
数据准备
这次Spark-SQL操作所有的数据均来自 Hive,所以首先需要在Hive中创建表,并导入数据。一共有3张表: 1张用户行为表,1 张产品表,1张城市表
-- 用户行为表
CREATE TABLE `user_visit_action`(
`date` string,
`user_id` bigint,
`session_id` string,
`page_id` bigint,
`action_time` string,
`search_keyword` string,
`click_category_id` bigint,
`click_product_id` bigint,
`order_category_ids` string,
`order_product_ids` string,
`pay_category_ids` string,
`pay_product_ids` string,
`city_id` bigint)
row format delimited fields terminated by '\t';
load data local inpath '/opt/modules/input/user_visit_action.txt' into table default.user_visit_action;
-- 产品表
CREATE TABLE `product_info`(
`product_id` bigint,
`product_name` string,
`extend_info` string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/modules/input/product_info.txt' into table default.product_info;
-- 城市表
CREATE TABLE `city_info`(
`city_id` bigint,
`city_name` string,
`area` string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/modules/input/city_info.txt' into table default.city_info;
3张表数据下载连接
需求描述
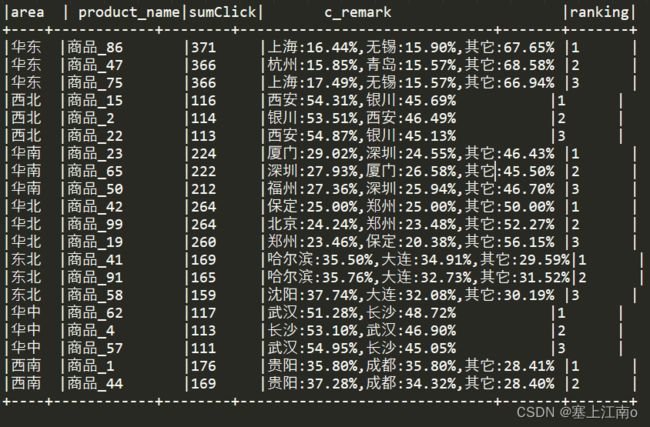
计算各个区域TOP3热门商品,并备注上每个商品在主要城市中的分布比例,超过两个城市用其他显示

思路分析:使用 SQL来实现每个地区TOPN,使用UDAF 函数实现城市备注
解释一下为什么使用UDAF 函数实现城市备注?
如果用SQL,一般会有这样的思路
- 按照地区进行开窗,在每个窗口内求出TOPN商品,和TOPN商品总点击次数
- 按照地区和商品进行开窗,在每个窗口内求出TOPN城市,TOPN城市的商品总点击次数,用这些城市商品的总点击次数 / 每个地区商品的总点击次数 = 百分比
- 步骤1,2都很简单,但是你怎么把
城市+百分比形式的数据汇总到一行(SQL做不到),所以需要使用UDAF函数来实现
先给出SQL求TOPN商品的大致思路
1 查询出来所有的点击记录,并与 city_info 表连接,得到每个城市所在的地区,在与 product_info 表连接得到产品名称
2 按照地区和商品名称分组,统计出每个商品在每个地区的总点击次数
3 每个地区内按照点击次数降序排列
4 只取前三名,并把结果保存在数据库中
SQL实现:部分需求
select ci.area,
pi.product_name,
count(if(uva.click_product_id != -1, 1, null)) as sumClick,
remark(ci.city_name) as c_remark,
row_number() over (partition by ci.area order by count(if(uva.click_product_id != -1, 1, null)) desc ) as ranking
from user_visit_action uva
join product_info pi on uva.click_product_id = pi.product_id
join city_info ci on uva.city_id = ci.city_id
group by ci.area, pi.product_name
select t1.area,
t1.product_name,
t1.sumClick,
t1.c_remark,
t1.ranking
from (select ci.area,
pi.product_name,
count(if(uva.click_product_id != -1, 1, null)) as sumClick,
remark(ci.city_name) as c_remark,
row_number() over (partition by ci.area order by count(if(uva.click_product_id != -1, 1, null)) desc ) as ranking
from user_visit_action uva
join product_info pi on uva.click_product_id = pi.product_id
join city_info ci on uva.city_id = ci.city_id
group by ci.area, pi.product_name)t1;
| area | product_name | cnt | ranking |
|---|---|---|---|
| 东北 | 商品_41 | 169 | 1 |
| 东北 | 商品_91 | 165 | 2 |
| 东北 | 商品_93 | 159 | 3 |
| 华东 | 商品_86 | 371 | 1 |
| 华东 | 商品_75 | 366 | 2 |
| 华东 | 商品_47 | 366 | 3 |
| 华中 | 商品_62 | 117 | 1 |
| 华中 | 商品_4 | 113 | 2 |
| 华中 | 商品_29 | 111 | 3 |
| 华北 | 商品_42 | 264 | 1 |
| 华北 | 商品_99 | 264 | 2 |
| 华北 | 商品_19 | 260 | 3 |
| 华南 | 商品_23 | 224 | 1 |
| 华南 | 商品_65 | 222 | 2 |
| 华南 | 商品_50 | 212 | 3 |
| 西北 | 商品_15 | 116 | 1 |
| 西北 | 商品_2 | 114 | 2 |
| 西北 | 商品_22 | 113 | 3 |
| 西南 | 商品_1 | 176 | 1 |
| 西南 | 商品_44 | 169 | 2 |
| 西南 | 商品_60 | 163 | 3 |
代码实现:全部需求(主要是用来搞城市备注的),思路代码里有
使用idea连接hive时,需要配置环境
以下将定义一个UDAF函数:remark来实现城市备注
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, MapType, StringType, StructField, StructType}
import java.text.DecimalFormat
object SparkSQL10_TopN {
def main(args: Array[String]): Unit = {
// 创建SparkSession对象
val spark: SparkSession = SparkSession
.builder()
.enableHiveSupport()
.master("local[*]")
.appName("")
.getOrCreate()
// 选择使用hive的哪个库
spark.sql("use default")
// 注册一个自定义函数
spark.udf.register("remark", new CityClickUDAF)
spark.sql(
"""
|select ci.area,
| pi.product_name,
| count(if(uva.click_product_id != -1, 1, null)) as sumClick,
| remark(ci.city_name) as c_remark,
| row_number() over (partition by ci.area order by count(if(uva.click_product_id != -1, 1, null)) desc ) as ranking
| from user_visit_action uva
| join product_info pi on uva.click_product_id = pi.product_id
| join city_info ci on uva.city_id = ci.city_id
| group by ci.area, pi.product_name
|""".stripMargin).createOrReplaceTempView("t1")
spark.sql(
"""
|select t1.area,
| t1.product_name,
| t1.sumClick,
| t1.c_remark,
| t1.ranking
|from t1
|where t1.ranking <= 3
|""".stripMargin).show(false)
//释放资源
spark.stop()
}
}
// 自定义一个UDAF聚合函数,完成城市点击量统计
class CityClickUDAF extends UserDefinedAggregateFunction {
// 输入数据类型
override def inputSchema: StructType = {
StructType(Array(StructField("city_name", StringType)))
}
//缓存的数据类型 用Map缓存城市以及该城市点击数 :北京->2,天津->3;总的点击量Long:北京2 + 天津3 = 5
override def bufferSchema: StructType = {
StructType(Array(
StructField("city_count", MapType(StringType, LongType))
, StructField("total_count", LongType)))
}
// 输出的数据类型 北京21.2%,天津13.2%,其他65.6%
override def dataType: DataType = StringType
// 稳定性
override def deterministic: Boolean = false
// 为缓存数据进行初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = Map[String, Long]()
buffer(1) = 0L
}
// 对缓存数据进行更新
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
val cityName: String = input.getAs[String](0)
// 取数据时,需要指定数据的格式
val map: Map[String, Long] = buffer.getAs[Map[String, Long]](0)
// 取出不可变集合里面的值,加1,再放回不可变集合,然后放回内存缓存区中
buffer(0) = map + (cityName -> (map.getOrElse(cityName, 0L) + 1L)) // 城市点击量 + 1
buffer(1) = buffer.getAs[Long](1) + 1L // 总点击量 + 1
}
// 分区间的缓存合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
// 获取每一个节点城市点击缓存Map
val map1 = buffer1.getAs[Map[String, Long]](0)
val map2 = buffer2.getAs[Map[String, Long]](0)
// 合并两个节点上的城市点击
buffer1(0) = map1.foldLeft(map2) {
case (map2, (k, v)) => {
map2 + (k -> (map2.getOrElse(k, 0L) + v))
}
}
// 合并两个节点上的总点击数
buffer1(1) = buffer1.getAs[Long](1) + buffer2.getAs[Long](1)
}
// 得到最终的输出效果 北京21.2%,天津13.2%,其他65.6%
override def evaluate(buffer: Row): Any = {
// 取出缓存中的数据
val map = buffer.getAs[Map[String, Long]](0)
val totalCount: Long = buffer.getAs[Long](1)
// 对Map集合中城市点击记录进行降序排序,取前2个
val sortList: List[(String, Long)] = map.toList.sortWith((left, right) => {
left._2 > right._2
}).take(2)
// 计算排名前2的点击率
var citRatio: List[CityRemark] = sortList.map {
case (cityName, cnt) => {
CityRemark(cityName, cnt.toDouble / totalCount)
}
}
//如果城市的个数超过2个,那么其它情况的处理
if (map.size > 2) {
citRatio = citRatio :+ CityRemark("其它", citRatio.foldLeft(1D)(_ - _.cityRatio))
}
citRatio.mkString(",")
}
}
case class CityRemark(cityName: String, cityRatio: Double) {
val formatter = new DecimalFormat("0.00%")
override def toString: String = s"$cityName:${formatter.format(cityRatio)}"
}