java基础-HashMap
HashMap主要用于存储键值对,是最常用的java集合之一。
Map map = new HashMap<>(); HashMap在JDK1.7和JDK1.8的实现是不一样的。
JDK1.7中的HashMap实现:
数据结构:数组+链表
Map map = new HashMap<>(5);
map.put("name","heidan");
map.put("age","21"); 使用数组+链表解释一下上面的代码:
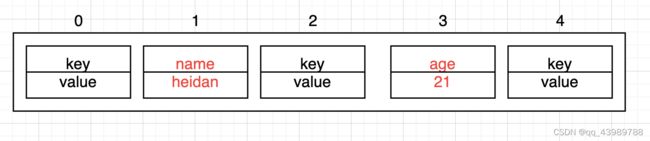
1、初始化一个容量为5的数组:

hashMap的key和value都可以是null,但key唯一,value的值可以是重复的。
2、往数组中添加第一个键值对:map.put("name","heidan");
首先根据key,也就是"name",通过hash(Object key)方法计算出key的hash值:源码如下:

假如计算出来的"name"的hash值为hashValue,那么再通过index = (n-1)&hashValue这个公式,计算出index(下标)的值,这里的n是数组的长度,最后将("name","heidan")的键值对插入到数组中下标为index的位置:
假设最后计算出的index = 1

这里额外说一下,由index = (n-1)&hashValue可以发现,我们最后计算出来的index是强依赖于数组长度的,那么当HashMap扩容(扩容机制在下面,请读者耐心往下)之后,所有元素在数组中的下标也就是index是需要重新计算的。
以上是HashMap的数组结构,那么链表呢?
我们现在添加第二个键值对:map.put("age","21");
和上面的方法一样,先根据"age"计算index,这里计算出的index有两种情况:
- index = 1(和"name"计算出来的hash值相等,因此index也相等),发生了hash冲突,index=1的位置已经有元素,这个时候不会再另外计算一次index,而是用链表的形式插入到index=1的位置。【这里使用的是头插法,在JDK8之后改成了尾插法】

- index = 0/2/3/4,这个时候直接将("age","21")添加到数组中index的位置。假设index = 3
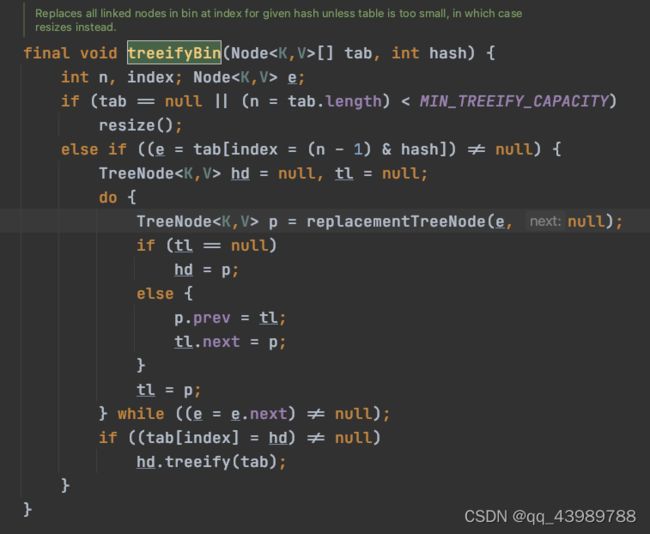
JDK1.8的HashMap的数据结构:数组+链表+红黑树
JDK1.8之后HashMap在处理hash冲突的问题上做了改变:引入了红黑树。
每发生一次hash冲突,链表的长度都会+1,当链表的长度大于8时,会先调用treeifyBin()方法。这个方法会根据数据的长度来决定是否将链表转为红黑树:当HashMap的数组长度大于等于64的情况下,会将链表转为红黑树,增加检索的效率;如果数组长度小于64的话,执行resize()方法对数组进行扩容。以下为treeifbBin()的源码:
好了,以上是对HashMap的数据结构的分析。
那么HashMap是如何扩容的呢?
HashMap根据两个属性进行扩容:
- capacity:HashMap的默认容量是16,源码中用的位运算:1<<4

- loadFactor:负载因子,源码中默认0.75f

在默认情况下,16*0.75 = 12,当我们往map中添加第13个元素的时候,就会进行扩容:扩容之后的容量是原来容量的2倍。
注意:我上面说过的,扩容之后需要重新计算每个元素的index,因为index = (n-1)&hashValue
值得一提的是,在HashMap中遇见hash冲突形成链表的时候,jdk1.7和jdk1.8的实现是不同的。
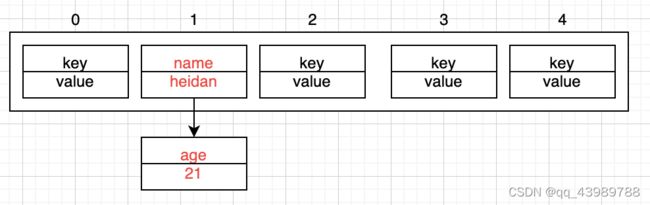
在jdk1.7中,往链表上添加元素使用的是【头插法】,而在jdk1.8中改成了尾插法:
两个元素:("name","heidan")是先插入的,("age","21")是后插入的:
在jdk1.7中:
在jdk1.8中:
再jdk8的时候为什么要改成尾插法呢?
因为在多线程的情况下可能会出现环形链的情况,因为HashMap在扩容之后是会重新计算每个元素的位置的,元素的位置改变说明各个元素之前的引用就会改变,所以在多线程下操作jdk1.7的HashMap的时候可能会出现死循环。而该用jdk8的尾插法,元素之前的引用顺序不会改变,也就不会引起死循环。
再来说一下HashMap的put方法吧: