Hadoop大数据存算分离下,如何解决新旧存储共存?

在传统的Apache Hadoop集群系统中,计算和存储资源是紧密耦合的,HDFS为大数据存储带来便利的同时,也面临着一些挑战:
当存储空间或计算资源不足时,只能同时对两者进行扩容。假设用户对存储资源的需求远大于对计算资源的需求,那么同时扩容计算和存储后,新扩容的计算资源就被浪费了,反之,存储资源被浪费。
这导致扩容的经济效率较低,额外增加成本。而独立扩展的计算和存储则更加灵活,同时可显著降低成本。
现在Hadoop采用存算分离的架构的趋势越来越明显。
XSKY HDFS Client是为XEOS存储集群和Hadoop计算集群量身打造的连接器。通过XSKY HDFS Client,Hadoop应用可以访问存储在XEOS中的所有数据。
但是,在引入XEOS存储后,会出现原有HDFS与XEOS共存的情况,如何将两套存储集群都利用起来是需要解决的问题。
1
数据跨集群拷贝
一般情况下,计算应用需要访问的数据,如果保存在不同的集群中,那么应该将其中一个集群的数据拷贝到另一个集群上。一般情况下使用Hadoop自带的DistCp工具,对数据进行跨集群的拷贝。
这种方式虽然在一定程度上可以解决数据合并的问题,但如果数据量比较大,并且机房带宽有限制的情况下,可能拷贝数据的时间会非常长。还有一个就是在拷贝过程中原始数据发生改动,就还需要考虑增量同步的问题。
2
联邦HDFS和ViewFS
在Hadoop 2.x发行版中引入了联邦HDFS功能,期望可以解决NameNode的内存问题。联邦HDFS允许系统通过添加多个NameNode来实现扩展,其中每个NameNode管理文件系统命名空间中的一部分。
但是,在实际应用中,系统管理员需要维护多个NameNodes(所有NameNode都需要高可用)和负载均衡服务,这又增加了管理成本。所以HDFS的联邦方案并没有被生产环境所采用。
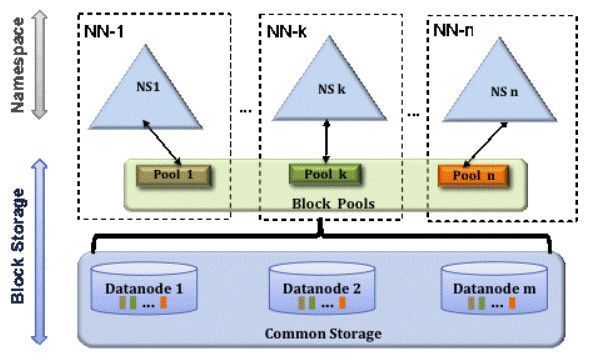
在提供联邦HDFS方案同时,Hadoop 2.x还提供了ViewFS,用来管理所有多个命名空间视图。
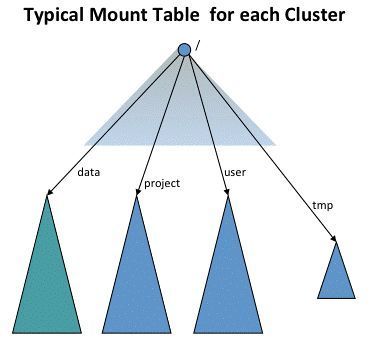
虽然联邦HDFS方案并没有被大规模应用,但ViewFS却可以用来解决XEOS与HDFS共存问题。
03
ViewFS的实现
ViewFS全称是ViewFileSystem,它不是一个新的文件系统,只是逻辑上的一个视图文件系统,它实现了标准的Hadoop FileSystem接口。但是,真实的请求处理还是在各自真实的存储集群上。
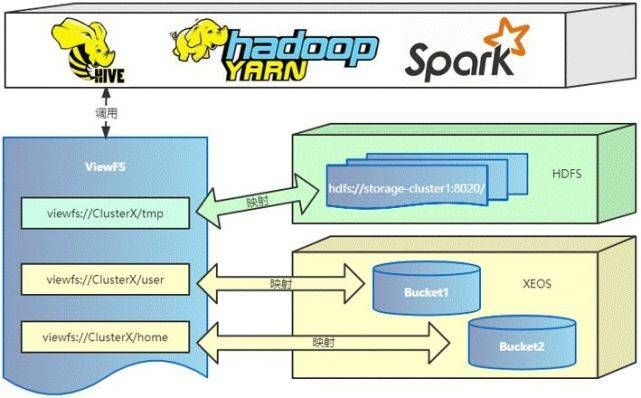
ViewFS会维护一个mount-table,主要是viewfs的逻辑目录与实际底层存储的映射关系。在接收到应用的调用时,ViewFS会解析用户的访问请求,并通过mount-table找到对应的底层存储目录,转发相应的请求到底层存储。
ViewFS会把所有应用层的FileSystem调用透传到底层真实文件系统中。由于ViewFs实现了Hadoop文件系统接口,因此使用它透明地运行Hadoop工具。例如,所有shell命令都可以与HDFS和本地文件系统一起使用ViewFS。
在集群的core-site配置中,fs.defaultFS被设置为ViewFS的root目录,也就是指定的mount-table。
在集群的配置中增加ViewFS的mount-table配置,示例如下:

Hadoop系统将在Hadoop配置文件中查找名称为 “ClusterX” 的mount-table。将所有gateway和server配置包含“ClusterX”,如上示例。
4
ViewFS的应用场景
ViewFS可以在如下场景中使用:
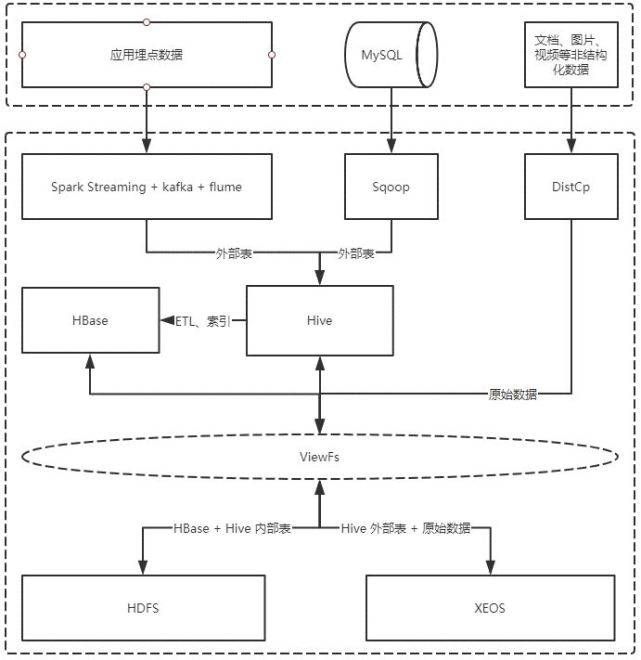
非结构化的原始数据可以通过DistCp等工具直接存储在XEOS上,业务数据库结构化数据和应用买点数据可以通过ETL以Hive的外部表方式存储到XEOS中。HBase和Hive继续在原有的HDFS上面运行,也就是HBase表数据和Hive内部表数据仍然通过HDFS来存储。
这样的好处是海量非结构化数据,甚至是海量小文件都可以用XEOS来承载,减轻HBase的压力,同时Hive新增数据全部通过XEOS来存储,后续扩容容量仅扩展XEOS存储集群即可。
5
XEOS配置ViewFS
大数据平台基于CDH 6.3.2。HDFS core-site.xml 增加如下配置:
Hadoop FS命令行:
执行wordcount测试结果如下:
6
小结
XSKY通过ViewFS的方式,在不改变用户使用习惯的前提下,将原有HDFS数据与新增XEOS数据打通,解决了原有HDFS集群与新XEOS集群的共存问题。原有的HDFS数据可以继续使用,而XEOS可以用于承载新生成的数据。
这种方式不仅可以充分利用旧有设备,达到节约成本的目的。同时,能够借助XEOS横向扩展能力,实现存储单独扩容。