【目标检测 DeformableDETR】通俗理解 DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION,值得一看。
文章目录
- DeformableDETR
-
- 1. 引言
-
- 1.1 E to E
- 1.2 远近高低各不同
- 1.3 先CNN,在DETR
- 1.4 DETR未解决的问题
- 2. 背景知识
-
- 2.1 NMS
- 2.2 transformer
- 2.3 FPN
- 2.2 高分辨率
- 2.3 收敛速度
-
- 2.3.1 大量的位置编码
- 2.3.2 大量的注意力计算
- 2.5 Deformable 原理
- 3. 方法
-
- 3.1 attention modules
- 3.2 稀疏空间位置
- 4.3 自适应卷积模块(Adaptive Convolution Module,ACM)
- 5. 代码讲解
- 6. 实验结果
- 7. 讨论和结论
DeformableDETR
论文下载地址:https://arxiv.org/pdf/2010.04159.pdf
对应源码链接:
https://github.com/fundamentalvision/Deformable-DETR
1. 引言
1.1 E to E
YOLO系列会有前后小模块,前有Anchor、后有NMS,DETR系列不需要Anchor、NMS,是真正意义的端到端。
1.2 远近高低各不同
multi-sacle,由于多尺度,多尺度 小目标不再是小目标。
1.3 先CNN,在DETR
所有的DETR也都是先通过CNN进行特征提取,transformer 需要大量的数据去迭代,并且开始初始化很小。因为参数量是 640*640 再 平方 。
1.4 DETR未解决的问题
由于 Transformer 模块在处理图像特征图时 收敛速度慢、特征空间分辨率有限。DeformableDETR 主要解决以上问题,并且在小目标检测方面有着较好的提升。
2. 背景知识
2.1 NMS
DETR 等基于Transformer的模型等不需要使用NMS,因为预测框不再是一组带有置信度的边界框,而是一个集合,每个元素表示一个类别的存在性和位置,从而进行二分匹配。
2.2 transformer
通过3个FC层得到Q/K/V。
2.3 FPN
在 FPN 中,自下而上的路径从底层特征图开始,逐步上采样到更高的分辨率。自上而下的路径则从顶层特征图开始,逐步下采样到更低的分辨率。在自上而下的路径中,每个上采样层的特征图都与自下而上的路径中的特征图相加,这样就形成了一个金字塔状的特征图结构。
由于来自不同层级的特征图在大小和通道数上不同,因此需要进行对齐操作。在 FPN 中,对齐操作主要采用了一种叫做 “自适应池化”(Adaptive Pooling)的方法,将大小不同的特征图对齐成相同的大小。
而对于通道数的对齐,FPN 使用的是简单的拼接操作,将来自不同层级的特征图的通道数直接拼接在一起。因此,可以说 FPN 对于特征图的对齐主要是在大小方面进行了处理,而在通道数方面则没有进行对齐。
2.2 高分辨率
在DETR中,Transformer Decoder的输入序列长度是固定的,即使图像尺寸不同,输入序列的长度也是相同的,这就意味着对于高分辨率的图像,输入序列的长度将会非常大,从而导致模型的计算复杂度和内存需求大大增加。
此外,高分辨率的图像也会使得目标物体变得更加细节化,这会导致目标的数量增加,从而使得模型更难以准确地检测到所有目标。在这种情况下,可能需要增加模型的训练数据集,或者调整模型的超参数来适应更大、更复杂的图像。
2.3 收敛速度
2.3.1 大量的位置编码
DETR引入了位置编码来帮助网络理解目标的空间位置信息。这些位置编码要求网络在学习目标检测任务的同时,还要学习如何使用位置编码来定位目标。因此,这些位置编码增加了网络的复杂性,导致模型收敛速度变慢。
2.3.2 大量的注意力计算
对于每一个 q u e r y query query 和 每一个键值对,计算注意力权重需要对所有像素点进行加权求和。在输入张量大小为 H × W × C H \times W \times C H×W×C,查询向量数为 M M M,键值对个数为 N N N 的情况下,注意力权重计算的复杂度是 O ( M N H W ) O(M N H W) O(MNHW),其中 H W H W HW 是像素点的数量。因此,注意力计算的时间复杂度与像素点的数量有关。
DETR中的Transformer模块需要大量的自注意力计算来捕捉目标之间的交互信息。这些计算需要在每个通道和每个位置进行,这使得模型需要更多的时间来训练。
2.5 Deformable 原理
M 是多头自注意力,K是采样点的个数。
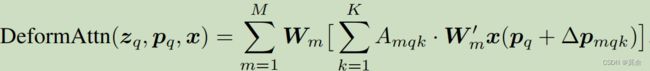
K是4个点组成的。
p q p_q pq 是根据哪个点,地铁上的3个小姐姐。
δ p m q k δp_{mqk} δpmqk 是偏移量、需要训练的。 A m q k A_{mqk} Amqk 为attention weight。
预测得到的偏移量,反向传播的时候更新FC的w和b。
z q z_q zq 通过 FC层 得到偏移量的。
3. 方法
3.1 attention modules
原来的DETR需要很多个 epoch 才能找到特征,在Deformable DTER中可以更快。
Reference Point 一个固定的坐标值,比如说在一个特征图中,就相当于一个点Query Feature z q z_q zq。Query Feature z q z_q zq 通过FC层不是预测偏移量,而是更好的保持这个特征 V 。
Query Feature z q z_q zq:一部分得到采样点的特征,一部分得到采样点特征所贡献的权重。然后进行加法,分别得到3个头的特征。

3.2 稀疏空间位置
deformable convolution :突出特征,传统的卷积太慢了
Self-Attention: q1/q2/q3…q1是北极熊,由于比较大,q1就把q2给占了。

4.3 自适应卷积模块(Adaptive Convolution Module,ACM)
DeformableDETR使用了一个ACM,来对齐不同特征层之间的通道数。
ACM将输入特征图分成多个通道组,对每个通道组中的通道数进行自适应调整。具体来说,对于每个通道组,ACM使用自适应平均池化来计算出该通道组的平均通道数,并将所有通道组的平均通道数求和得到一个标量。
然后,对于每个通道组,ACM使用一个可学习的1x1卷积来将通道数调整为该通道组的平均通道数与总平均通道数的比例乘以目标通道数。
5. 代码讲解
Deformable DETR 的代码可以很轻松就能运行起来,推荐使用mmdetection框架,分分钟运行起来。
6. 实验结果
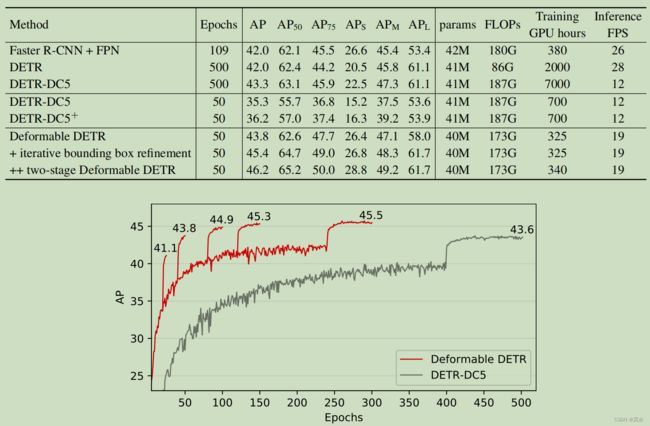

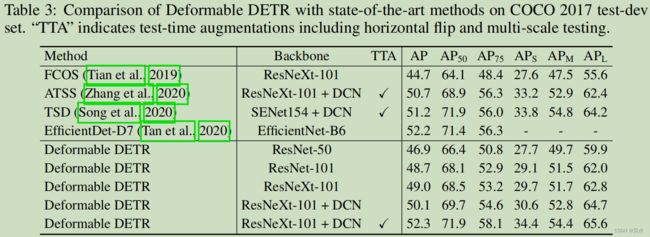
7. 讨论和结论
采样点个数可以增加,采样策略可以更改。