类ChatGPT开源项目的部署与微调:从LLaMA到ChatGLM-6B
前言
近期,除了研究ChatGPT背后的各种技术细节 不断看论文(至少100篇,100篇目录见此:ChatGPT相关技术必读论文100篇),还开始研究一系列开源模型(包括各自对应的模型架构、训练方法、训练数据、本地私有化部署、硬件配置要求、微调等细节)
本文一开始是作为此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》的第4部分,但随着研究深入 为避免该文篇幅又过长,将把『第4部分 开源项目』抽取出来 独立成本文,然后不断续写本文到最终2万字左右(3.22日7000余字)
毕竟我上半年的目标之一,便是把ChatGPT涉及的所有一切关键技术细节,以及相关的开源项目都研究的透透的,故过程中会不断产出一篇篇新文章出来,比如:
- 微积分和概率统计极简入门
- 一文通透优化算法
- 强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO
- ChatGPT技术原理解析(本系列核心主体,也是同类解读里最清晰、全面、细致的一篇)
- ChatGPT相关技术论文100篇
- 类ChatGPT开源项目
- CV多模态模型发展史(23年4月发布),详述GPT4背后多模态的能力起源与发展历史,包括但不限于DTER、DDPM、Vision Transformer、CLIP、Swin Transformer、DALL·E 2、Stable Diffusion、BEiT-3、Visual ChatGPT、GPT4等.
第一部分 Colossal-AI、PaLM-rlhf-pytorch、Open-Assistant等
虽说GPT3在2020年就出来了,但OpenAI并未开源,所以直到一年半后以后才有国内外各个团队比如DeepMind等陆续复现出来,这些大厂的复现代码我们自然无法窥知一二,毕竟人家也未开源出来
再到后来基于GPT3的InstructGPT、基于GPT3.5ChatGPT初版(GPT3.5的参数规模也尚无准确定论)、GPT4均未开源,OpenAI不再open,好在Meta等公司或研究者开源出了一系列类ChatGPT项目,本部分针对其中部分做下简要推荐(根据发布顺序排序)
1.1 基于Colossal-AI低成本实现类ChatGPT迷你版的训练过程
2.15,很多朋友在GitHub上发现了一个基于Colossal-AI低成本实现类ChatGPT迷你版训练过程的开源项目(基于OPT + RLHF + PPO),虽是类似GPT3的开源项目与RLHF的结合,但可以增进我们对ChatGPT的理解,该项目有几个不错的特点
- 很多同学一看到DL,便会想到大数据,而数据量一大,还用CPU处理的话很可能训练一个小任务都得半天,而如果用GPU跑,可能一两分钟就出来了。于此,在深度学习大火的那几年,特别是AlphaGo出来的16年起,我司七月在线便分别为VIP、AI系统大课、在职提升大课、求职/论文/申博/留学1V1辅导提供GPU云平台进行实战训练
但如果想训练那种千亿参数规模的开源模型,就不只是有GPU就完事了,比如1750亿参数规模这种得用64张AI 100(即便经过一系列内存开销上的优化,也得至少32张AI 100,单张AI 100售价10万以上,且现在还经常没货),这样的硬件要求是大部分个人是无法具备的,所以该开源项目提供了单GPU、独立4/8-GPUs 的版本 - 如下代码所示,启动简单
from chatgpt.nn import GPTActor, GPTCritic, RewardModel from chatgpt.trainer import PPOTrainer from chatgpt.trainer.strategies import ColossalAIStrategy strategy = ColossalAIStrategy(stage=3, placement_policy='cuda') with strategy.model_init_context(): actor = GPTActor().cuda() critic = GPTCritic().cuda() initial_model = deepcopy(actor).cuda() reward_model = RewardModel(deepcopy(critic.model)).cuda() trainer = PPOTrainer(strategy, actor, critic, reward_model, initial_model, ...) trainer.fit(prompts) - 训练过程明确清晰,如下图(由于上文已经详细介绍过ChatGPT的训练步骤,故不再赘述)
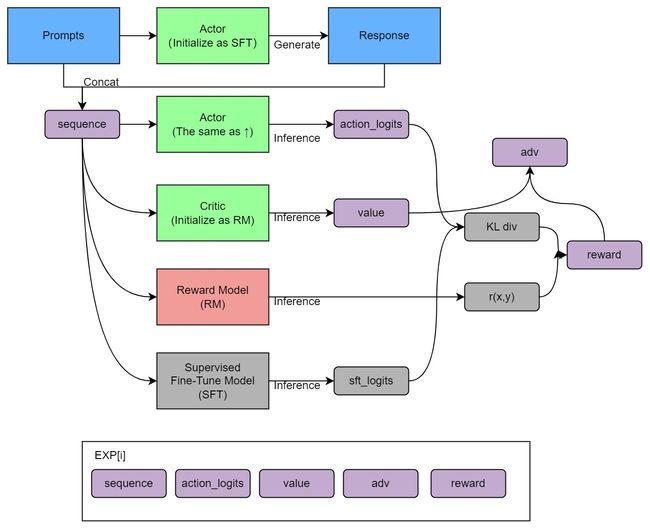
此外,据钟博士在我所维护的『Machine Learning读书会群』里所说,Colossal-AI的并行效率确实不错,是新加坡的一个初创团队推出的,但目前尚没有团队采用Colossal-AI框架来做主训练框架训练175b级别的超大模型,可以再了解下Meta家训练OPT用的Metaseq
1.2 PaLM-rlhf-pytorch、Open-Assistant等项目
此外,GitHub上还有这些项目
- PaLM-rlhf-pytorch
该项目是在PaLM架构之上实现RLHF,可以理解为基于PaLM的ChatGPT - Open-Assistant
它旨在让每一个人都可以访问基于聊天的大语言模型,项目作者希望借此在语言创新方面掀起一场革命,就像 stable diffusion 帮助世界以新的方式创造艺术和图像一样
项目作者计划收集高质量人工生成指令执行样本(指示 + 响应),目标大于 50k,对于收集到的每个指示,他们将采样多个补全结果,之后进入基于指示和奖励模型的RLHF训练阶段
第二部分 从Meta发布的LLaMA到基于LLaMA微调的斯坦福Alpaca
2.1 Meta发布大语言模型LLaMA:参数少但多数任务的效果好于GPT3
一直致力于LLM模型研究的国外TOP 3大厂除了OpenAI、Google,便是Meta(原来的Facebook)
Meta曾第一个发布了基于LLM的聊天机器人——BlenderBot 3,但输出不够安全,很快下线。再后来,Meta发布一个专门为科学研究设计的模型Galactica,但用户期望过高,发布三天后又下线
2.24日,Meta通过论文《LLaMA: Open and Efficient Foundation Language Models》发布了自家的大型语言模型LLaMA,有多个参数规模的版本(7B 13B 33B 65B)
LLaMA只使用公开的数据(CommonCrawl的数据占比67%,C4数据占比15%,Github Wikipedia Books这三项数据均各自占比4.5%,ArXiv占比2.5%,StackExchange占比2%),论文中提到
When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM.
This means that training over our dataset containing 1.4T tokens takes approximately 21 days
且试图证明小模型在足够多的的数据上训练后,也能达到甚至超过大模型的效果
- 比如130亿参数的版本在多项基准上测试的效果好于2020年的参数规模达1750亿的GPT-3
- 而对于650亿参数的LLaMA,则可与DeepMind的Chinchilla(700亿参数)和谷歌的PaLM(5400亿参数)旗鼓相当
- 且Meta还尝试使用了论文「Scaling Instruction-Finetuned Language Models」中介绍的指令微调方法,由此产生的模型LLaMA-I,在MMLU(Massive Multitask Language Understanding,大型多任务语言理解)上要优于Google的指令微调模型Flan-PaLM-cont(620亿)
模型结构上,除了继续基于Transformer这个架构外
- 为了提高训练的稳定性,对每个transformer子层的输入进行归一化,而不是对输出进行归一化
且使用由Zhang和Sennrich(2019)提出的RMSNorm归一化函数 - 用Shazeer(2020)提出的SwiGLU替代ReLU
- 删除absolute positional embeddings, 在网络的每一层添加RoPE
LLaMA发布不久后,一些研究者基于它做了不少工作
- 一开始最小参数7B的模型也需要近30GB的GPU才能运行,但通过比特和字节库进行浮点优化,能够让模型在单个NVIDIA RTX 3060上运行
- 之后,GitHub 上的一名研究人员甚至能够在Ryzen 7900X CPU上运行LLM的7B 版本,每秒能推断出几个单词
- 再之后,有研究者推出了llama.cpp,无需 GPU,就能运行 LLaMA
llama.cpp 项目实现了在MacBook上运行 LLaMA,还有开发者成功的在 4GB RAM 的树莓派上运行了 LLaMA 7B,总结而言,即使开发者没有GPU ,也能运行 LLaMA 模型 - 再之后,初创公司 Nebuly AI开源了RLHF版的LLaMA,即ChatLLaMA的训练方法
由于LLaMA没有使用RLHF方法,因此ChatLLaMA的训练过程类似 ChatGPT,该项目允许基于预训练的 LLaMA 模型构建 ChatGPT 形式的服务
与 ChatGPT 相比,LLaMA 架构更小,但训练过程和单GPU推理速度更快,成本更低
且该库还支持所有的 LLaMA 模型架构(7B/13B/33B/65B),因此用户可以根据训练时间和推理性能偏好对模型进行微调
2.2 斯坦福Alpaca:人人都可微调Meta家70亿参数的LLaMA大模型
3月中旬,斯坦福发布Alpaca:号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B),通过52k指令数据、8个80GB A100上训练了3个小时,性能比肩GPT-3.5(text-davinci-003)
- 论文《Alpaca: A Strong Open-Source Instruction-Following Model》
- 代码地址:https://github.com/tatsu-lab/stanford_alpaca
而斯坦福团队微调LLaMA 7B的方法,便是来自华盛顿大学Yizhong Wang等22年12月通过这篇论文《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》提出的Self-Instruct

具体而言,论文中提出
- 人工设计175个任务,每个任务都有对应的{指令 输入 输出/实例}或{指令 输出/实例},将这175个任务数据作为种子集
- 然后提示模型比如GPT3对应的text-davinci-001 (不是像某些文章写的用text-davinci-003,because their newer engines are trained with the latest user data and are likely to already see the SUPERNI evaluation set),使用种子集作为上下文示例来生成更多新的指令
- 对该模型生成的指令判断是否分类任务
- 使用模型生成实例
- 对上述模型生成的数据{指令 输入 输出/实例}过滤掉低质量或相似度高的
- 将经过过滤和后处理的数据添加到种子池中
一直重复上述2-6步直到种子池有足够多的数据
而斯坦福的Alpaca,就是花了不到500美元使用OpenAI API生成了5.2万个这样的示例微调LLaMA搞出来的,个人觉得可以取名为 instructLLaMA-7B,^_^
第三部分 国内的GLM与类ChatGPT项目ChatGLM-6B
3.1 GLM: General Language Model Pretraining with Autoregressive Blank Infilling
在2022年上半年,当时主流的预训练框架可以分为三种:
- autoregressive,自回归模型的代表是单向的GPT,本质上是一个从左到右的语言模型,常用于无条件生成任务(unconditional generation),缺点是无法利用到下文的信息
- autoencoding,自编码模型是通过某个降噪目标(如掩码语言模型,简单理解就是通过挖洞,训练模型做完形填空的能力)训练的语言编码器,如双向的BERT、ALBERT、RoBERTa、DeBERTa
自编码模型擅长自然语言理解任务(natural language understanding tasks),常被用来生成句子的上下文表示,缺点是不适合生成任务 - encoder-decoder,则是一个完整的Transformer结构,包含一个编码器和一个解码器,以T5、BART为代表,常用于有条件的生成任务 (conditional generation)
细致来说,T5的编码器中的注意力是双向,解码器中的注意力是单向的,因此可同时应用于自然语言理解任务和生成任务。但T5为了达到和RoBERTa和DeBERTa相似的性能,往往需要更多的参数量
这三种预训练模型各自称霸一方,那么问题来了,可否结合三种预训练模型,以成天下之一统?这便是2022年5月发表的这篇论文《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》的出发点,它提出了GLM架构(这是张义策关于GLM论文的解读之一,下面三小节的内容主要参考自该篇解读)
3.1.1 如何将生成模型GPT和掩码语言模型BERT结合在一起
首先,考虑到三类预训练模型的训练目标
- GPT的训练目标是从左到右的文本生成
- BERT的训练目标是对文本进行随机掩码,然后预测被掩码的词
- T5则是接受一段文本,从左到右的生成另一段文本
为了大一统,我们必须在结构和训练目标上兼容这三种预训练模型。如何实现呢?文章给出的解决方法
- 结构上,只需要GLM中同时存在单向注意力和双向注意力即可
在原本的Transformer模型中,这两种注意力机制是通过修改attention mask实现的
当attention_mask是全1矩阵的时候,这时注意力是双向的
当attention_mask是三角矩阵的时候(如下图),注意力就是单向
类似地,我们可以在只使用Transformer编码器的情况下,自定义attention mask来兼容三种模型结构
- 训练目标上,这篇文章提出一个自回归空格填充的任务(Autoregressive Blank Infifilling),来兼容三种预训练目标
自回归填充有些类似掩码语言模型,首先采样输入文本中部分片段,将其替换为[MASK]标记,然后预测[MASK]所对应的文本片段,与掩码语言模型不同的是,预测的过程是采用自回归的方式
具体来说,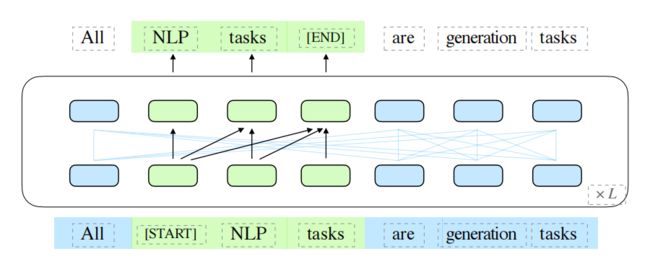
 当被掩码的片段长度为1的时候,空格填充任务等价于掩码语言建模,类似BERT 当将文本1和文本2拼接在一起,然后将文本2整体掩码掉,空格填充任务就等价于条件语言生成任务,类似T5/BART 当全部的文本都被掩码时,空格填充任务就等价于无条件语言生成任务,类似GPT
当被掩码的片段长度为1的时候,空格填充任务等价于掩码语言建模,类似BERT 当将文本1和文本2拼接在一起,然后将文本2整体掩码掉,空格填充任务就等价于条件语言生成任务,类似T5/BART 当全部的文本都被掩码时,空格填充任务就等价于无条件语言生成任务,类似GPT
3.1.2 如何理解GLM的自回归空格填充任务
假设原始的文本序列为![]() ,采样的两个文本片段为
,采样的两个文本片段为  和
和 ![]() ,那么掩码后的文本序列为
,那么掩码后的文本序列为 ![]() (以下简称Part A),如上图所示,拆解图中的三块分别可得
(以下简称Part A),如上图所示,拆解图中的三块分别可得

- 我们要根据第一个
![[M]](http://img.e-com-net.com/image/info8/95a20fd0449d4f869c8aa71a837d70d4.gif) 解码出 ,根据第二个依次解码出
解码出 ,根据第二个依次解码出 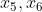 ,那怎么从 处解码出变长的序列吗?这就需要用到开始标记
,那怎么从 处解码出变长的序列吗?这就需要用到开始标记 ![[S]](http://img.e-com-net.com/image/info8/2e72eed974d046adb65495a7237552be.gif) 和结束标记
和结束标记 ![[E]](http://img.e-com-net.com/image/info8/0ee860405aab42e194f0dd2dd08a7485.gif) 了
了 - 我们从开始标记 开始依次解码出被掩码的文本片段,直至结束标记 。通过本博客内的Transformer笔记可知,Transformer中的位置信息是通过位置向量来记录的
在GLM中,位置向量有两个,一个 用来记录Part A中的相对顺序,一个 用来记录被掩码的文本片段(简称为Part B)中的相对顺序 - 此外,还需要通过自定义自注意掩码(attention mask)来达到以下目的: 双向编码器Part A中的词彼此可见,即图(d)中蓝色框中的区域 单向解码器Part B中的词单向可见,即图(d)黄色框的区域 Part B可见Part A 其余不可见,即图(d)中灰色的区域
需要说明的是,Part B包含所有被掩码的文本片段,但是文本片段的相对顺序是随机打乱的
3.1.3 GLM的预训练和微调
作者使用了两个预训练目标来优化GLM,两个目标交替进行:
- 文档级别的预测/生成:从文档中随机采样一个文本片段进行掩码,片段的长度为文档长度的50%-100%
- 句子级别的预测/生成:从文档中随机掩码若干文本片段,每个文本片段必须为完整的句子,被掩码的词数量为整个文档长度的15%
尽管GLM是BERT、GPT、T5三者的结合,但是在预训练时,为了适应预训练的目标,作者还是选择掩码较长的文本片段,以确保GLM的文本生成能力,并在微调的时候将自然语言理解任务也转化为生成任务,如情感分类任务转化为填充空白的任务
- 输入:{Sentence},prompt:It is really ,对应的标签为good和bad
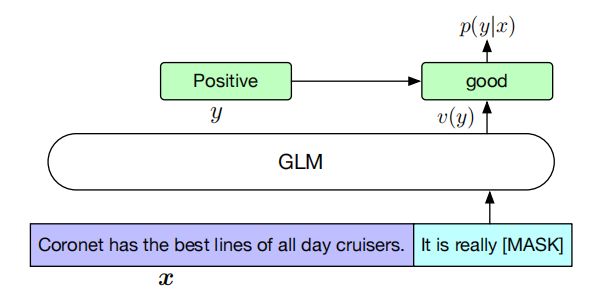
此外,模型架构层面,除了整体基于Transformer之外
- 重新排列了层归一化和残差连接的顺序
- 针对token的输出预测使用单一线性层
- 用GeLU替换ReLU激活函数
3.2 GLM-130B:国内为数不多的可比肩GPT3的大模型之一
2022年8月,清华背景的智谱AI基于GLM框架,正式推出拥有1300亿参数的中英双语稠密模型 GLM-130B(论文地址、代码地址,论文解读之一,GLM-130B is trained on a cluster of 96 DGX-A100 GPU (8×40G) servers with a 60-day,可以较好的支持2048个token的上下文窗口)
其在一些任务上的表现优于GPT3-175B,是国内与2020年5月的GPT3在综合能力上差不多的模型之一(即便放到23年年初也并不多),这是它的一些重要特点

3.3 类ChatGPT开源项目ChatGLM-6B的训练框架与部署步骤
ChatGLM-6B(介绍页面、代码地址),是智谱 AI 开源、支持中英双语的对话语言模型,其
- 基于General Language Model(GLM)架构,具有62亿参数,支持在单张 2080Ti 上进行推理使用(且INT4量化级别下最低只需 6GB显存)
- ChatGLM-6B参考了 ChatGPT 的设计思路,在千亿基座模型GLM-130B中注入了代码预训练,通过监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式等技术实现人类意图对齐,并针对中文问答和对话进行优化
- 最终经过约 1T 标识符的中英双语训练,生成符合人类偏好的回答
虽尚有很多不足(比如因为6B的大小限制,导致模型的记忆能力、编码、推理能力皆有限),但在6B这个参数量级下不错了,部署也非常简单,我七月在线的同事朝阳花了一两个小时即部署好了(主要时间花在模型下载上,实际的部署操作很快)
以下是具体的部署过程(机器用的七月的GPU服务器,显存大小为16G的P100,最终占用13G)
- 配置环境:pip install -r requirements.txt(特别注意torch版本大于1.10,transformers大于4.23)
torch的安装命令参考pytorch官网:https://pytorch.org/ - 下载项目仓库:
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B - 下载ChatGLM-6B模型文件
下载地址:https://huggingface.co/THUDM/chatglm-6b - 有两种运行方式,一种是基于Gradio,一种是基于streamlit
基于Gradio:
运行web_demo.py即可(注意可以设置share=True,便于公网访问):python web_demo.py(注意运行前确认下模型文件路径)
基于streamlit:
pip install streamlit
pip install streamlit-chat
streamlit run web_demo2.py --server.port 6006(可以将6006端口放出,便于公网访问)
此外,据介绍,GLM团队正在内测130B参数的ChatGLM,相信从6B到130B,效果应该能提升很多