剑指 Offer 浅刷浅刷(普通版)
剑指 Offer(普通版)
-
-
- 剑指 Offer 03. 数组中重复的数字
- 剑指 Offer 04. 二维数组中的查找
- 剑指 Offer 05. 替换空格
- 剑指 Offer 06. 从尾到头打印链表
- 剑指 Offer 07. 重建二叉树
- 剑指 Offer 09. 用两个栈实现队列
- 剑指 Offer 10- I. 斐波那契数列
- 剑指 Offer 10- II. 青蛙跳台阶问题
- 剑指 Offer 11. 旋转数组的最小数字
- 剑指 Offer 12. 矩阵中的路径
- 剑指 Offer 13. 机器人的运动范围
- 剑指 Offer 14- I. 剪绳子
- 剑指 Offer 14- II. 剪绳子 II
- 剑指 Offer 15. 二进制中1的个数
- 剑指 Offer 16. 数值的整数次方
- 剑指 Offer 17. 打印从1到最大的n位数
- 剑指 Offer 18. 删除链表的节点
- 剑指 Offer 19. 正则表达式匹配
- 剑指 Offer 20. 表示数值的字符串
- 剑指 Offer 21. 调整数组顺序使奇数位于偶数前面
- 剑指 Offer 22. 链表中倒数第k个节点
- 剑指 Offer 24. 反转链表
- 剑指 Offer 25. 合并两个排序的链表
- 剑指 Offer 26. 树的子结构
- 剑指 Offer 27. 二叉树的镜像
- 剑指 Offer 28. 对称的二叉树
- 剑指 Offer 29. 顺时针打印矩阵
- 剑指 Offer 30. 包含min函数的栈
- 剑指 Offer 31. 栈的压入、弹出序列
- 剑指 Offer 32 - I. 从上到下打印二叉树
- 剑指 Offer 32 - II. 从上到下打印二叉树 II
- 剑指 Offer 32 - III. 从上到下打印二叉树 III
- 剑指 Offer 33. 二叉搜索树的后序遍历序列
- 剑指 Offer 34. 二叉树中和为某一值的路径
- 剑指 Offer 35. 复杂链表的复制
- 剑指 Offer 36. 二叉搜索树与双向链表
- 剑指 Offer 37. 序列化二叉树
- 剑指 Offer 38. 字符串的排列
- 剑指 Offer 39. 数组中出现次数超过一半的数字
- 剑指 Offer 40. 最小的k个数
- 剑指 Offer 41. 数据流中的中位数
- 剑指 Offer 42. 连续子数组的最大和
- 剑指 Offer 43. 1~n 整数中 1 出现的次数
- 剑指 Offer 44. 数字序列中某一位的数字
- 剑指 Offer 45. 把数组排成最小的数
- 剑指 Offer 46. 把数字翻译成字符串
- 剑指 Offer 47. 礼物的最大价值
- 剑指 Offer 48. 最长不含重复字符的子字符串
- ### 剑指 Offer 49. 丑数
- 剑指 Offer 50. 第一个只出现一次的字符
- 剑指 Offer 51. 数组中的逆序对
- 剑指 Offer 52. 两个链表的第一个公共节点
- 剑指 Offer 53 - I. 在排序数组中查找数字 I
- 剑指 Offer 53 - II. 0~n-1中缺失的数字
- 剑指 Offer 54. 二叉搜索树的第k大节点
- 剑指 Offer 55 - I. 二叉树的深度
- 剑指 Offer 55 - II. 平衡二叉树
- 剑指 Offer 56 - I. 数组中数字出现的次数
- 剑指 Offer 56 - II. 数组中数字出现的次数 II
- 剑指 Offer 57. 和为s的两个数字
- 剑指 Offer 57 - II. 和为s的连续正数序列
- 剑指 Offer 58 - I. 翻转单词顺序
- 剑指 Offer 58 - II. 左旋转字符串
- 剑指 Offer 59 - I. 滑动窗口的最大值
- 剑指 Offer 59 - II. 队列的最大值
- 剑指 Offer 60. n个骰子的点数
- 剑指 Offer 61. 扑克牌中的顺子
- 剑指 Offer 62. 圆圈中最后剩下的数字
- 剑指 Offer 63. 股票的最大利润
- 剑指 Offer 64. 求1+2+…+n
- 剑指 Offer 65. 不用加减乘除做加法
- 剑指 Offer 66. 构建乘积数组
- 剑指 Offer 67. 把字符串转换成整数
- 剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
- 剑指 Offer 68 - II. 二叉树的最近公共祖先
-
剑指 Offer 03. 数组中重复的数字
//方法一:
class Solution {
public:
int findRepeatNumber(vector<int>& nums) {
unordered_map<int, int> map;
for (int i = 0; i < nums.size(); i++) {
if (map.find(nums[i]) != map.end()) { //没找到才会返回end的迭代器
return nums[i];
} else {
map[nums[i]] ++;
}
}
return -1;
}
};
//方法二:
class Solution {
public:
int findRepeatNumber(vector<int>& nums) {
sort(nums.begin(), nums.end());
for (int i = 0; i < nums.size() - 1; i++) {
if (nums[i] == nums[i + 1]) {
return nums[i];
}
}
return -1;
}
};
//方法三:
class Solution {
public:
int findRepeatNumber(vector<int>& nums) {
for (int i = 0; i < nums.size(); i++) {
while (nums[i] != i) {
if (nums[nums[i]] == nums[i]) { //即该值索引位已经为该值了
return nums[i];
}
int t = nums[i];
nums[i] = nums[t];
nums[t] = t;
}
}
return -1;
}
};
方法一:利用C++中自带的哈希表,通过键值访问,若已经有了则表示这个数字重复了。
方法二:直接进行排序,看相邻两个元素是否相同。
方法三:鸽巢原理,也就是相当于把原表当作哈希表,如果其相应数值索引位置存储的值等于这个索引值,那么就表示该值已经出现一次了,下次再出现就是重复值了。
剑指 Offer 04. 二维数组中的查找
class Solution {
public:
bool findNumberIn2DArray(vector<vector<int>>& matrix, int target) {
if (matrix.size() == 0) {
return false;
}
int row = 0, col = matrix[0].size() - 1;
while (row < matrix.size() && col >= 0) {
if (matrix[row][col] == target) {
return true;
} else if (matrix[row][col] > target) {
col--;
} else if (matrix[row][col] < target) {
row++;
}
}
return false;
}
};
因为每行的最后一个都是该行最大的,所以先从最后判断,若大于target就表示这一行都比target小,就到下一行重新判断,若小于target就表示这一行存在比它大的数和比它小的数,就在这行找就行了,找不到就返回false,注意没有东西的特殊情况。
剑指 Offer 05. 替换空格
//方法一:
class Solution {
public:
string replaceSpace(string s) {
for (int i = 0; i < s.size(); i++) {
if (s[i] == ' ') {
s = s.replace(i, 1, "%20");
}
}
return s;
}
};
//方法二:
class Solution {
public:
string replaceSpace(string s) {
while (s.find(" ") + 1) {
s = s.replace(s.find(' '), 1, "%20");
}
return s;
}
};
//find函数没找到就会返回-1.
没啥说的,找到后替换就行。
剑指 Offer 06. 从尾到头打印链表
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
vector<int> num;
stack<int> myStack;
ListNode *temp = head;
while (temp) {
myStack.push(temp->val);
temp = temp->next;
}
while (!myStack.empty()) {
num.push_back(myStack.top());
myStack.pop();
}
return num;
}
};
很简单的先用栈存储,然后再pop进vector数组就行了。
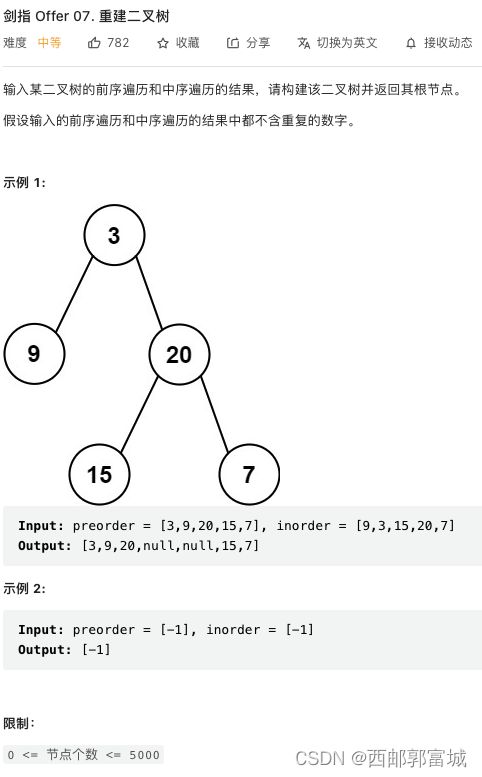
剑指 Offer 07. 重建二叉树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
// 递归解决:前序遍历是根左右,中序遍历是左根右,我们可以根据根来分别划分 前序数组和中序数组,然后递归处理划分的数组即可
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
//传递的数组位空说明就没有该节点
if (preorder.empty() || inorder.empty()) {
return nullptr;
}
// 1、建立根节点,然后根据根节点来划分 前序数组 和 中序数组,前序数组的第一个元素就是该根节点的值
TreeNode *root = new TreeNode(*preorder.begin());
// 2、来找到 中序数组 中该根节点的位置
auto it = find(inorder.begin(), inorder.end(), *preorder.begin());
// 3、划分中序数组,根据根节点的位置,因为中序数组根节点的左边为左子树,右边为右子树
vector<int> iLeft(inorder.begin(), it), iRight(it + 1, inorder.end());
// 4、划分前序数组,根据中序数组的左右子树的大小
int n = iLeft.size();
//通过刚才计算出来的左子树长度,来返回左右子树的前序和中序遍历数组
vector<int> pLeft(preorder.begin() + 1, preorder.begin() + 1 + n), pRight(preorder.begin() + 1 + n, preorder.end());
// 5、递归处理左右子树
root->left = buildTree(pLeft, iLeft);
root->right = buildTree(pRight, iRight);
// 6、返回该节点
return root;
}
};
构建二叉树,根据前序和中序遍历的结果构建一个二叉树。
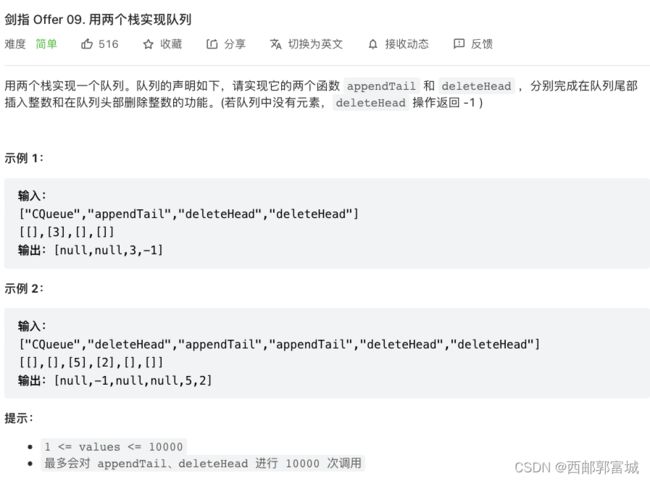
剑指 Offer 09. 用两个栈实现队列
class CQueue {
public:
stack <int> headStack;
stack <int> rearStack;
CQueue() {
}
void appendTail(int value) {
headStack.push(value);
}
int deleteHead() {
if (headStack.empty()) {
return -1;
} else {
while (!headStack.empty()) {
rearStack.push(headStack.top());
headStack.pop();
}
int value = rearStack.top();
rearStack.pop();
while (!rearStack.empty()) {
headStack.push(rearStack.top());
rearStack.pop();
}
return value;
}
}
};
/**
* Your CQueue object will be instantiated and called as such:
* CQueue* obj = new CQueue();
* obj->appendTail(value);
* int param_2 = obj->deleteHead();
*/
使用两个栈实现队列,无非就是一个栈用作队列存储(headStack),另一栈用作队列输出(rearStack),每次要出队的时候就让存储栈(headStack)将所有数据pop到输出栈(rearStack)上,然后输出输出栈的栈顶元素,最后再将剩下的元素pop回存储栈(headStack),每次都如此就完成两个栈实现一个队列了。
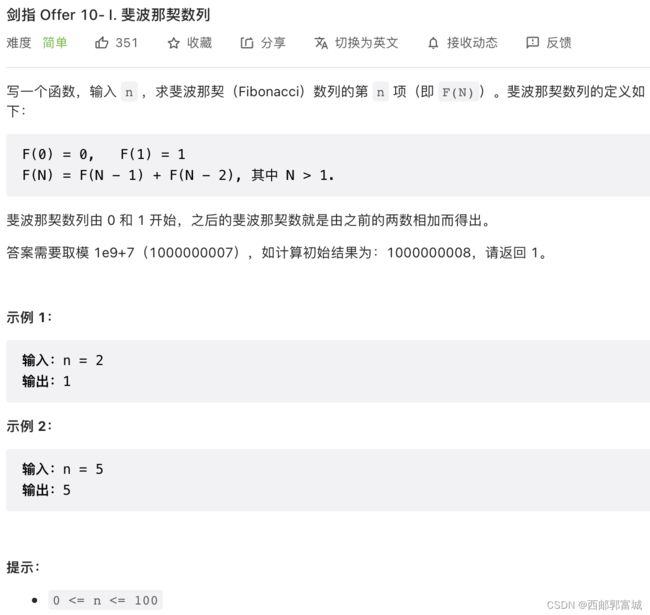
剑指 Offer 10- I. 斐波那契数列
class Solution {
public:
int fib(int n) {
if (n < 2) {
return n;
}
int f1 = 0, f2 = 1;
for (int i = 0; i < n - 1; i++) {
int t = f1 % 1000000007;
f1 = (f1 + f2) % 1000000007;
f2 = t;
}
return (f1 + f2) % 1000000007;
}
};
用两个存储F(N - 1)和F(N - 2)就行了,注意题上说的答案要取余。同时递归也可以写,但是递归实在是太慢了,会超时。
剑指 Offer 10- II. 青蛙跳台阶问题

class Solution {
public:
int numWays(int n) {
if (n == 0 || n == 1) {
return 1;
}
int f1 = 0, f2 = 1;
for (int i = 0; i < n; i++) {
int t = f1 % 1000000007;
f1 = (f1 + f2) % 1000000007;
f2 = t;
}
return (f1 + f2) % 1000000007;
}
};
这不就是斐波那契的变形嘛,难点就在于你啥时候能理解它的原理,哎嘘,就看这个大哥的讲解吧。

剑指 Offer 11. 旋转数组的最小数字
class Solution {
public:
int minArray(vector<int>& numbers) {
int left = 0, right = numbers.size() - 1;
int mid;
while (left < right) {
mid = (left + right) / 2;
if (numbers[right] > numbers[mid]) {
right = mid;
} else if (numbers[right] < numbers[mid]) {
left = mid + 1;
} else { //去重
right--;
}
}
return numbers[left];
}
};
只要右边比中间大,他就是顺序的,所以我们可以只通过右边对其进行判断。right比mid大说明mid到right都是顺序的就不用看了,令right到mid位置就行。right比mid小说明mid到right之间经过了旋转,则应该令left到mid位置,right不变继续进行查找。还有一种最重要的情况就是right和mid是相等的,那么我们就要对其进行去重处理,就得让right–。
剑指 Offer 12. 矩阵中的路径

class Solution {
public:
bool exist(vector<vector<char>>& board, string word) {
//若二维数组为空,就看word是否为空,是空就能匹配上,返回1,不是空就直接返回0
if (!board.size() || !board[0].size()) {
return !word.length();
}
for (int row = 0; row < board.size(); row++) {
for (int col = 0; col < board[0].size(); col++) {
//利用&&的特性,等该位置字符匹配上了才会调用后边的函数
if (board[row][col] == word[0] && backSearchResult(board, row, col, word, 0)) { //直到将word全部找到了条件才成立
return 1;
}
}
}
return 0;
}
private:
bool backSearchResult(vector<vector<char>>& board, int row, int col, string word, int idx) {
//索引和长度相同表示查询完成了
if (idx == word.size()) {
return 1;
}
//查询超界直接返回0
if (row < 0 || row >= board.size() || col < 0 || col >= board[0].size()) {
return 0;
}
//不匹配返回0
if (word[idx] != board[row][col]) {
return 0;
}
//该位置访问过了,做记号,因为上边的严格筛选条件,如果能走到这,那么一定就是该位置已经匹配上了,那么下次就不能用了
board[row][col] = '*';
//调用该函数继续向四个位置分别匹配查找下一个字符
if (backSearchResult(board, row - 1, col, word, idx + 1) || backSearchResult(board, row + 1, col, word, idx + 1) || backSearchResult(board, row, col - 1, word, idx + 1) || backSearchResult(board, row, col + 1, word, idx + 1)) {
return true;
}
//这个写法很妙,走到这,说明上面的这个条件没有成立,即四周没有匹配到下一个字符,那么就回溯,把这之前给该位置赋值的‘*’换回原来的字符
board[row][col] = word[idx];
return 0;
}
};
利用回溯的写法,对先查找二维数组中与word第一个字符匹配的位置,然后利用backSearchResult对上下左右四个方向对idx位字符进行匹配,能匹配上了再将这个位置传给下一个该函数再次进行下一个字符(idx + 1)的匹配,一直到匹配完成。
看看别的大哥的思路吧:

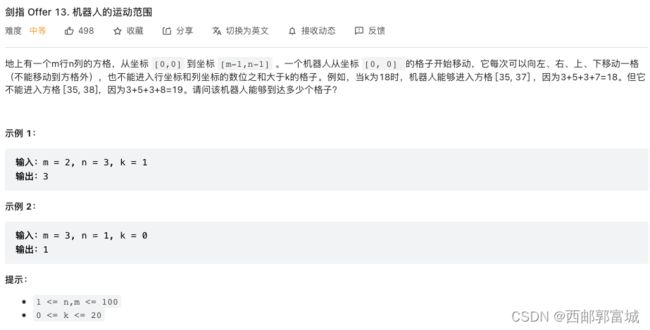
剑指 Offer 13. 机器人的运动范围
class Solution {
public:
int movingCount(int m, int n, int k) {
vector<vector<int>> myVector(m, vector<int>(n, 0));
int num = 0;
judgeMoving(m, n, k, 0, 0, myVector);
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (myVector[i][j]) {
num++;
}
}
}
return num;
}
private:
bool judgeMoving(int m, int n, int k, int row, int col, vector<vector<int>> &myVector) {
if (row < 0 || row >= m || col < 0 || col >= n) {
return 0;
}
//判断该位置是否可以
int temp = 0;
int tempRow = row, tempCol = col;
while (tempRow || tempCol) {
temp += tempRow % 10;
tempRow /= 10;
temp += tempCol % 10;
tempCol /= 10;
}
if (temp > k || myVector[row][col]) {
return 0;
}
//能过就给该位置赋1
myVector[row][col] = 1;
if (judgeMoving(m, n, k, row - 1, col, myVector) || judgeMoving(m, n, k, row + 1, col, myVector) || judgeMoving(m, n, k, row, col - 1, myVector) || judgeMoving(m, n, k, row, col + 1, myVector)) {
return 1;
}
return 0;
}
};
递归+回溯,用一个二维的数组存放机器人是否能到达,初始化为0,若能到达就将该位置的值改为1,最后加以判断,等递归结束,再便利这个二维数组,统计有多少个1就行了。因为初始位置都是(0, 0),所以不需要架循环,直接就从该位置开始,逐步便利其上下左右,当周围能走完的地方都走了之后,它就会返回,此时统计就行。
剑指 Offer 14- I. 剪绳子
class Solution {
public:
int cuttingRope(int n) {
return n <= 3 ? n - 1 : pow(3, n / 3) * 4 / (4 - n % 3);
}
};
//或者
class Solution {
public:
int cuttingRope(int n) {
if (n <= 3) {
return n - 1;
}
if (n % 3 == 1) {
return 4 * pow(3, n / 3 - 1);
} else if (n % 3 == 2) {
return 2 * pow(3, n / 3);
} else {
return pow(3, n / 3);
}
}
};
经大数据计算,3最多的时候值是最大的,最优3,次优2,最后才是1。
剑指 Offer 14- II. 剪绳子 II
class Solution {
public:
int cuttingRope(int n) {
if (n <= 3) {
return n - 1;
}
long int res = 1;
while (n > 4) {
res *= 3;
res = res % 1000000007;
n -= 3;
}
return (res * n) % 1000000007;
}
};
这道题是剪绳子的升级版,它的n可以到1000,所以我们得考虑存不存的下的问题,就不能直接使用pow函数了,所以这里我们使用循环相乘,通过n的大小判断,最终再返回乘积与n再相乘的结果,注意要时刻取余,不然容易超界。
剑指 Offer 15. 二进制中1的个数

//方法一:
class Solution {
public:
int hammingWeight(uint32_t n) {
int num = 0;
while (n) {
if (n & 1) {
num += 1;
}
n = n >> 1;
}
return num;
}
};
//方法二:
class Solution {
public:
int hammingWeight(uint32_t n) {
if (!n) {
return 0;
}
return (n & 1) + hammingWeight(n >> 1);
}
};
方法一:每一位直接和1进行&运算,然后再让n左移一位,一直到为0,结束循环并返回统计数。
方法二:方法一的升级版,递归,学以致用。
剑指 Offer 16. 数值的整数次方

//方法一:
class Solution {
public:
double fastMultiplication(double x, int n) {
if (n == 0) {
return 1;
}
double y = fastMultiplication(x, n / 2);
return n % 2 ? y * y * x : y * y;
}
double myPow(double x, int n) {
if (n < 0) {
return 1 / fastMultiplication(x, n);
} else {
return fastMultiplication(x, n);
}
}
};
方法一:快速幂 + 递归,很牛逼。

剑指 Offer 17. 打印从1到最大的n位数
class Solution {
public:
vector<int> printNumbers(int n) {
vector<int> myVector;
for (int i = 1; i < pow(10, n); i++) {
myVector.push_back(i);
}
return myVector;
}
};
这种题面试的时候应该不会考,太没有水准了,应该考虑的是有大数问题的,返回为string类型的vector,这种问题就的使用全排列进行解答了,对每一位进行0~9的定位,同时要注意的是去零操作。
剑指 Offer 18. 删除链表的节点

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteNode(ListNode* head, int val) {
if (head->val == val) {
return head->next;
}
ListNode *t = head;
while (t->next != NULL) {
if (t->next->val == val) {
t->next = t->next->next;
break;
} else {
t = t->next;
}
}
return head;
}
};
简单的删除节点,没啥好说的,不过没用双指针。
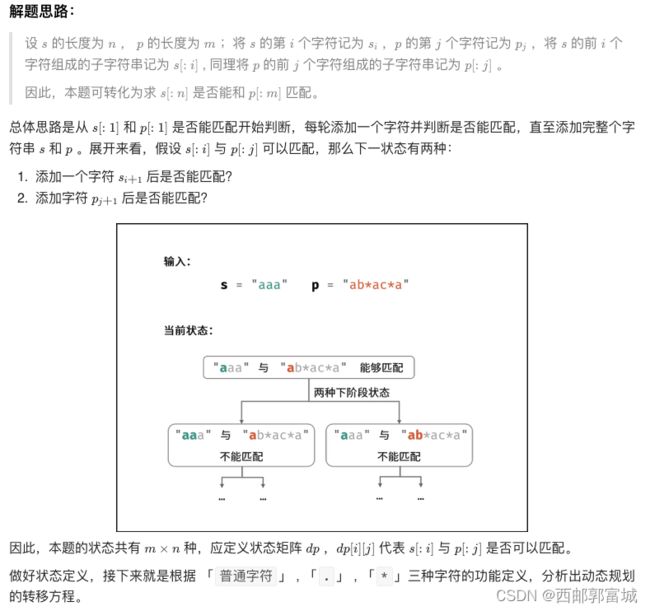
剑指 Offer 19. 正则表达式匹配
class Solution {
public:
bool isMatch(string s, string p) {
int m = s.size() + 1, n = p.size() + 1;
vector<vector<bool>> dp(m, vector<bool>(n, false));
dp[0][0] = true;
// 初始化首行
for(int j = 2; j < n; j += 2)
dp[0][j] = dp[0][j - 2] && p[j - 1] == '*';
// 状态转移
for(int i = 1; i < m; i++) {
for(int j = 1; j < n; j++) {
if(p[j - 1] == '*') {
if(dp[i][j - 2]) dp[i][j] = true; // 1.
else if(dp[i - 1][j] && s[i - 1] == p[j - 2]) dp[i][j] = true; // 2.
else if(dp[i - 1][j] && p[j - 2] == '.') dp[i][j] = true; // 3.
} else {
if(dp[i - 1][j - 1] && s[i - 1] == p[j - 1]) dp[i][j] = true; // 1.
else if(dp[i - 1][j - 1] && p[j - 1] == '.') dp[i][j] = true; // 2.
}
}
}
return dp[m - 1][n - 1];
}
};
//写的是真的牛,看了好长时间才理解了人家的思路。
//他是使用 * 来分开的两种情况,再加上dp动态规划的思路dp[0][0]就表示串为空的情况,实际上是从dp[1][1]开始的,dp[i][j]表示s[i]和p[j]的匹配情况
//第一种 p[j] 是 *,下列任一情况都是true
/*
1.dp[i][j - 2]: 即使用 * 的可以将前边字符看作出现0次的特性,就表示删去字符 p[j - 2] 和 * 看删去这两个字符后之前的字符还能否匹配;
2.dp[i - 1][j] 且 s[i - 1] = p[j - 2]: 即使用 * 让字符 p[j - 2] 多出现 1 次时,看是否还能匹配;
3.dp[i - 1][j] 且 p[j - 2] = '.': 即使用 * 让万能字符 '.' 多出现 1 次时,看是否还能匹配;
*/
//第二种 p[j] 不是 *,下列任一情况都是true
/*
1.dp[i - 1][j - 1] 且 s[i - 1] = p[j - 1]: 即在上一次字符匹配成功的前提下,再进行新的匹配,看其能否匹配;
2.dp[i - 1][j - 1] 且 p[j - 1] = '.': 即因为 . 是万能字符,所以只要上一次匹配成功了,然后这次要匹配的 p[j - 1] 字符是否是 . 这个万能符,是就表示再次匹配成功;
*/
这种题还得看大佬的题解,哎嘘,人麻了。

剑指 Offer 20. 表示数值的字符串

class Solution {
public:
bool isNumber(string s) {
bool isvalid = false; //初始认为这个字符串不表示数值
int dot_C = 0; //记录小数点出现的次数
int E_C = 0; //记录e出现的次数
int i= 0; //字符串s的下标
//过滤字符串前面部分的空格
while (s[i] == ' ') {
i++;
}
//如果第一个不为空格的字符是符号,下标自增跳过
if (s[i] == '+' || s[i] == '-') {
i++;
}
//遍历
for ( ; i < s.size(); i++) {
//出现数字,认为是数值
if (s[i] >= '0' && s[i] <= '9') {
isvalid = true;
continue;
}
//出现小数点
if (s[i] == '.') {
//小数点只能出现一次,并且要在e出现之前,若不符合返回false
if (dot_C < 1 && E_C < 1) {
dot_C++;
continue;
} else {
return false;
}
}
//出现e
if (s[i] == 'e' || s[i] == 'E') {
//e只能出现一次,并且e出现之前必须满足数值要求(是一个合法的整数或者小数)。
if (E_C < 1 && isvalid) {
E_C++;
} else {
return false;
}
//同时e的后面至少能够存放一个字符,如果越界返回false
if (i + 1 <s.size()) {
//可能会出现符号,如果是符号,下标自增跳过
if (s[i + 1] == '+' || s[i + 1] == '-') {
i++;
}
//需要重新判断e后面是否合法
isvalid = false;
continue;
}
return false;
}
//第二次出现空格,需要判断空格是否一直出现到字符串结束
while (s[i] == ' ') {
i++;
}
//如果空格一直到字符串末尾,返回结果
if (i >= s.size()) {
return isvalid;
}
//不符合上述所有情况,说明这肯定不是一个合法的数值
return false;
}
//字符串遍历结束,返回结果
return isvalid;
}
};
这题做着真没啥意思,无聊的很,没有技术含量,纯纯脑瘫题,就记录灭次的状态就行了。
剑指 Offer 21. 调整数组顺序使奇数位于偶数前面
class Solution {
public:
vector<int> exchange(vector<int>& nums) {
int start = 0, end = nums.size() - 1;
while (start < end) {
while (nums[start] % 2 == 1 && start < end) {
start++;
}
while (nums[end] % 2 == 0 && start < end) {
end--;
}
if (start < end) { //能到这一定就是左指偶数右指奇数了,要么就是超界了
int t = nums[start];
nums[start] = nums[end];
nums[end] = t;
}
}
return nums;
}
};
双指针而已,左右开工,左找到偶数,右找到奇数,直接交换就over。
剑指 Offer 22. 链表中倒数第k个节点
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* getKthFromEnd(ListNode* head, int k) {
ListNode *fast = head;
ListNode *slow = head;
while (fast) {
if (k) {
k--;
} else {
slow = slow->next;
}
fast = fast->next;
}
return slow;
}
};
两个指针,一个快一个慢,让快的先走k次,然后慢的再开始,等快的走完了,慢的就是返回节点的位置了。
剑指 Offer 24. 反转链表

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode *newHead, *rear, *temp;
newHead = head;
rear = NULL;
temp = NULL;
while (newHead) {
temp = newHead->next;
newHead->next = rear;
rear = newHead;
newHead = temp;
}
return rear;
}
};
经典的三指针联动,一个指向下一个(temp),一个指向尾(rear),再加个中间操作变量(newHead),使用一个while循环直到链表完了就行。每次让指向下一个的(temp)先跳到下一个,然后再将newHead的next赋值为前一个rear地址,最后newHead跳向temp,rear跳向newHead一直循环就完成了。
剑指 Offer 25. 合并两个排序的链表

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
//方法一:
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if (!l1) {
return l2;
}
if (!l2) {
return l1;
}
if (l1->val > l2->val) {
l2->next = mergeTwoLists(l1, l2->next);
return l2;
} else {
l1->next = mergeTwoLists(l1->next, l2);
return l1;
}
}
};
//方法二:
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode *returnList = new ListNode();
ListNode *temp = returnList;
while (l2 || l1) {
if (!l1) {
temp->next = l2;
break;
}
if (!l2) {
temp->next = l1;
break;
}
if (l1->val > l2->val) {
temp->next = l2;
l2 = l2->next;
} else {
temp->next = l1;
l1 = l1->next;
}
temp = temp->next;
}
return returnList->next;
}
};
方法一:简单的递归,首先判断两个传过来的节点是不是空节点,如果是就直接返回另一个节点就行了。若都非空,就对其节点值进行判断,如果l1的值大于l2,因为要返回递增链表,那么肯定插入那个值较小节点的后边即l2,该节点已经被返回了,那么传入下一个该递归函数的节点就应该是l1和下一个节点了,反之,思路同上。
方法二:迭代,没啥好说的。
剑指 Offer 26. 树的子结构

/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isSubStructure(TreeNode* A, TreeNode* B) {
// 特判:树 A 为空 或 树 B 为空 时,直接返回 false
if (A == nullptr || B == nullptr) {
return false;
}
/*
1. 判断 B 是 A 的子树,recur(A, B);
2. 判断 B 是 A 的左子树,isSubisSubStructure(A->left, B);
3. 判断 B 是 A 的右子树,isSubisSubStructure(A->right, B);
*/
return recur(A, B) || isSubStructure(A->left, B) || isSubStructure(A->right, B);
}
/*
判断B是不是A的子树
当节点 B 为空:说明树 B 已完成匹配,返回 true
当节点 A 为空:说明树 A 全部遍历完也无法匹配树 B,返回 false
当节点 A 和 B 的值不等:匹配失败,返回 false
*/
bool recur(TreeNode* A, TreeNode* B) {
if (B == nullptr) {
return true;
}
if (A == nullptr || A->val != B->val) {
return false;
}
return recur(A->left, B->left) && recur(A->right, B->right);
}
};
这种递归题写起来还是很菜,不看人家题解虽然有思路但是根本写不出来。其实这个题就是两步,第一步找到A和B的相同节点,第二步就是通过相同节点对其左右子树进行判断,一直传递 A左B左 和 A右B右 进行递归判断就行了。当B完了就说明是子树,A完了,或者值不同了就说明不是子树了。
剑指 Offer 27. 二叉树的镜像

//方法一:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* mirrorTree(TreeNode* root) {
if (!root) {
return NULL;
}
TreeNode *temp = root->left;
root->left = root->right;
root->right = temp;
mirrorTree(root->left);
mirrorTree(root->right);
return root;
}
};
//方法二:
class Solution {
public:
TreeNode* mirrorTree(TreeNode* root) {
stack<TreeNode*> myStack;
TreeNode *temp;
myStack.push(root);
while (!myStack.empty()) {
temp = myStack.top();
myStack.pop();
if (!temp) {
continue;
}
swap(temp->left, temp->right);
if (temp->left) {
myStack.push(temp->left);
}
if (temp->right) {
myStack.push(temp->right);
}
}
return root;
}
};
//方法三:
class Solution {
public:
TreeNode* mirrorTree(TreeNode* root) {
queue<TreeNode*> myQueue;
TreeNode *temp;
myQueue.push(root);
while (!myQueue.empty()) {
temp = myQueue.front();
myQueue.pop();
if (!temp) {
continue;
}
swap(temp->left, temp->right);
if (temp->left) {
myQueue.push(temp->left);
}
if (temp->right) {
myQueue.push(temp->right);
}
}
return root;
}
};
方法一:递归,交换左右节点就行。
方法二:栈,先存入根节点,然后弹出栈顶元素,交换其左右节点,再存入弹出的该节点的左右子树,一直循环,知道栈空为止。
方法三:队列,与上述的栈思路相同。
剑指 Offer 28. 对称的二叉树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isSymmetric(TreeNode* root) {
if (!root) {
return 1;
}
return helpJudge(root->left, root->right);
}
bool helpJudge(TreeNode *leftNode, TreeNode *rightNode) {
if (!leftNode && !rightNode) {
return 1;
}
if (!leftNode || !rightNode) {
return 0;
}
return leftNode->val == rightNode->val && helpJudge(leftNode->left, rightNode->right) && helpJudge(leftNode->right, rightNode->left);
}
};
思路就看这个大哥的吧,我觉得他很牛皮。

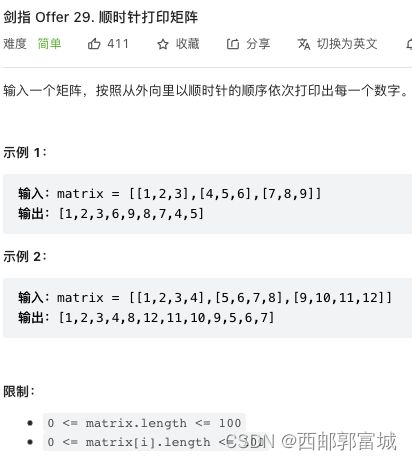
剑指 Offer 29. 顺时针打印矩阵
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
vector<int> myVector;
if (matrix.empty()) {
return myVector;
}
int col = matrix[0].size() - 1, row = matrix.size() - 1; //最大行数 列数
int tempCol = 0, tempRow = 0; //初始行数 列数
while (1) {
for (int i = tempCol; i <= col; i++) { //从左到右
myVector.push_back(matrix[tempRow][i]);
}
if (++tempRow > row) {
break;
}
for (int i = tempRow; i <= row; i++) { //从上到下
myVector.push_back(matrix[i][col]);
}
if (--col < tempCol) {
break;
}
for (int i = col; i >= tempCol; i--) { //从右到左
myVector.push_back(matrix[row][i]);
}
if (--row < tempRow) {
break;
}
for (int i = row; i >= tempRow; i--) { //从下到上
myVector.push_back(matrix[i][tempCol]);
}
if (++tempCol > col) {
break;
}
}
return myVector;
}
};
打印螺旋矩阵,感觉没啥说的。
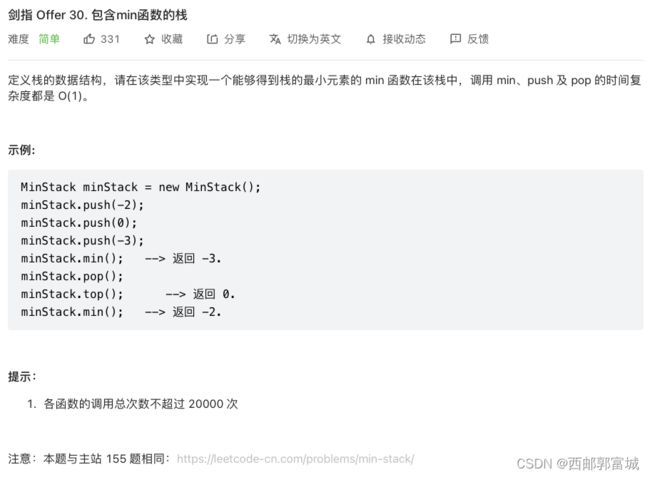
剑指 Offer 30. 包含min函数的栈
class MinStack {
public:
/** initialize your data structure here. */
stack <int> myStack;
stack <int> minStack;
MinStack() {
}
void push(int x) {
myStack.push(x);
if (minStack.empty()) {
minStack.push(x);
}
if (myStack.top() < minStack.top()) {
minStack.push(x);
} else if (myStack.size() != minStack.size()) {
minStack.push(minStack.top());
}
}
void pop() {
if (!myStack.empty()) {
myStack.pop();
minStack.pop();
}
}
int top() {
return myStack.top();
}
int min() {
return minStack.top();
}
};
/**
* Your MinStack object will be instantiated and called as such:
* MinStack* obj = new MinStack();
* obj->push(x);
* obj->pop();
* int param_3 = obj->top();
* int param_4 = obj->min();
*/
使用两个栈,一个作为普通栈(myStack)另一个作为存储最小数的栈(minStack),这两个栈的size相同,同时push、同时pop,每次向普通栈(myStack)中push数据的时候都与最小栈(minStack)的顶层元素进行比较,若比其小则向最小栈(minStack)中push该元素,否则最小栈(minStack)就将之前顶层数据再进行拷贝一遍push到自己的顶层,这样最小栈(minStack)的顶层元素一直都会是普通栈(myStack)的最小值了。
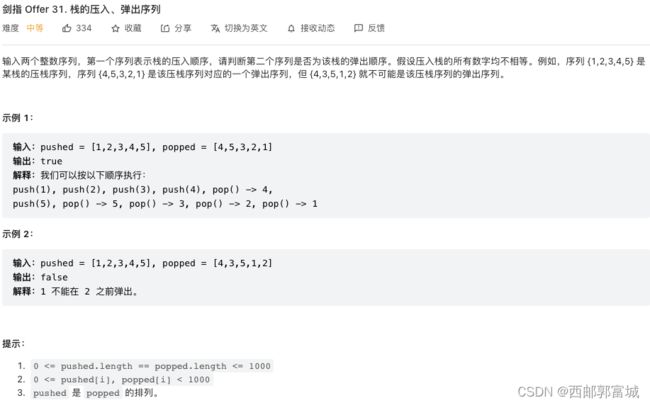
剑指 Offer 31. 栈的压入、弹出序列
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
if (pushed.empty()) {
return 1;
}
stack<int> myStack; //用于顺序的将pushed中的数据存储到栈中,便于比较
for (int i = 0; i < pushed.size(); i++) {
myStack.push(pushed[i]);
while (!myStack.empty() && !popped.empty() && myStack.top() == popped[0]) { //相等就将其删除
popped.erase(popped.begin()); //删除popped第一个元素
myStack.pop(); //弹出栈顶元素
}
if (popped.empty()) {
return 1;
}
}
return 0;
}
};
//或者 升级版 直接在原序列进行操作
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
if (pushed.empty()) {
return 1;
}
int i = 0;
while (i < pushed.size()) {
while (!popped.empty() && pushed[i] == popped[0]) { //相等就将其删除
popped.erase(popped.begin()); //删除popped第一个元素
pushed.erase(pushed.begin() + i); //删除该元素
if (i > 0) {
i--;
}
}
if (popped.empty()) {
return 1;
}
i++;
}
return 0;
}
};
定义一个栈myStack,用来模拟压入的顺序,压入之后再通过比较栈顶和输出序列的首元素是否相等,即这个元素是不是弹出元素,若是弹出元素,那么就弹出这个栈的栈顶元素,再删除输出序列的首元素,因为输出序列就是其出栈的顺序,所以只要和首元素不相等它就不是现在应该输出的数据,结束的条件就是将压入顺序数组遍历完,并且如果遍历完了输出序列还不为空就说明其不是该压入序列的弹出序列,反之就是。
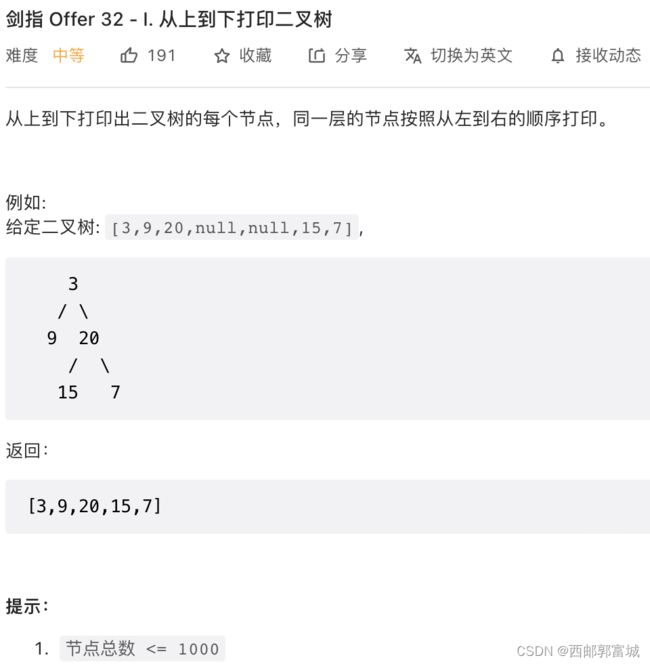
剑指 Offer 32 - I. 从上到下打印二叉树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
queue<TreeNode *> myQueue;
vector<int> valueVector;
vector<int> levelOrder(TreeNode* root) {
if (root == NULL) {
return valueVector;
}
myQueue.push(root);
while (myQueue.size()) {
TreeNode *temp = myQueue.front();
valueVector.push_back(temp->val);
if (temp->left) {
myQueue.push(temp->left);
}
if (temp->right) {
myQueue.push(temp->right);
}
myQueue.pop();
}
return valueVector;
}
};
就是一个简单的层序遍历,使用一个队列myQueue和一个返回的vector,先向队列myQueue存入根节点root,然后获取myQueue的首元素,将其值存入返回的vector,然后再向队列myQueue存入myQueue首元素的左右孩子在队尾,在pop队列myQueue的首元素,一直这样循环,直到队列为空就表示该二叉树层序遍历完毕。注意存入左右孩子之前要判断其是否存在。
剑指 Offer 32 - II. 从上到下打印二叉树 II

/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
queue<TreeNode *> myQueue;
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> valueVector;
vector<int> tempVector;
if (root == NULL) {
return valueVector;
}
TreeNode preventNode;
TreeNode *preTreeNode = &preventNode;
int i = 0;
myQueue.push(root);
myQueue.push(preTreeNode);
while (myQueue.size()) {
TreeNode *temp = myQueue.front();
if (temp == preTreeNode) {
i++;
myQueue.pop();
valueVector.push_back(tempVector);
tempVector.clear();
if (!myQueue.size()) {
break;
}
myQueue.push(preTreeNode);
continue;
}
tempVector.push_back(temp->val);
if (temp->left) {
myQueue.push(temp->left);
}
if (temp->right) {
myQueue.push(temp->right);
}
myQueue.pop();
}
return valueVector;
}
};
和上边说的层序遍历很相似,只是多加了一堵墙preTreeNode,用来隔开每一层的所有节点,如果到这堵墙了,先pop出去然后判断队列是否为空,为空就表示遍历完了,直接break结束循环就行,不为空就表示没完,再加入这堵墙作为屏障。vector的话每次遇到这堵墙之前都使用一个临时的一维vector,一直往其中添加数值,直到碰到这堵墙我们就将这个vector添加到最后返回的二维vector中,初始化该一维vector,继续使用就行了。
剑指 Offer 32 - III. 从上到下打印二叉树 III
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> valueVector;
vector<int> tempVector;
if (root == NULL) {
return valueVector;
}
queue<TreeNode *> myQueue; //用于层次遍历二叉树
stack<TreeNode *> myStack; //反向输出就先压入栈
TreeNode preventNode;
TreeNode *preTreeNode = &preventNode;
int i = 1;
myQueue.push(root);
myQueue.push(preTreeNode);
while (myQueue.size()) {
TreeNode *temp = myQueue.front();
if (temp == preTreeNode) {
i++;
//使用栈反转队列
valueVector.push_back(tempVector);
tempVector.clear();
myQueue = queue<TreeNode *> (); //清空队列
while (myStack.size()) {
myQueue.push(myStack.top());
myStack.pop();
}
if (!myQueue.size()) {
break;
}
myQueue.push(preTreeNode);
continue;
}
tempVector.push_back(temp->val);
if (i % 2) {
if (temp->left) {
myQueue.push(temp->left);
myStack.push(temp->left);
}
if (temp->right) {
myQueue.push(temp->right);
myStack.push(temp->right);
}
} else {
if (temp->right) {
myQueue.push(temp->right);
myStack.push(temp->right);
}
if (temp->left) {
myQueue.push(temp->left);
myStack.push(temp->left);
}
}
myQueue.pop();
}
return valueVector;
}
};
每次都对队列myQueue使用栈myStack进行反转,反转之后节点的存入顺序都要发生改变,如果从左到右进行遍历就得先存左孩子再存右孩子,如果从右到左进行遍历就得先存右孩子再存左孩子。
剑指 Offer 33. 二叉搜索树的后序遍历序列
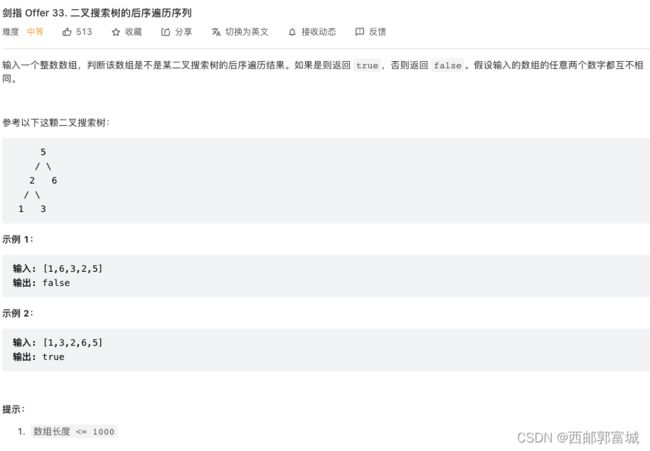
//方法一:
class Solution {
public:
bool verifyPostorder(vector<int>& postorder) {
stack<int> myStack; //单调栈使用,单调递增的单调栈
int nearRoot = INT_MAX; //存储最近节点的root节点
//逆向遍历,就是翻转的先序遍历
for (int i = postorder.size() - 1; i >= 0; i--) {
if (postorder[i] > nearRoot) {
return 0;
}
//单调栈非空,并且数组的该元素小于栈顶元素,即不满足单调栈的特性,就记录弹出栈顶的值(这个值就是其最近的根节点的值),然后弹出栈顶元素
while (!myStack.empty() && postorder[i] < myStack.top()) {
nearRoot = myStack.top();
myStack.pop();
}
//这个新元素入栈
myStack.push(postorder[i]);
}
return 1;
}
};
//方法二:
class Solution {
public:
bool verifyPostorder(vector<int>& postorder) {
return judgeVector(postorder, 0, postorder.size() - 1);
}
private:
bool judgeVector(vector<int> &postorder, int i, int j) {
//数组长度是1,那么肯定就是了
if (i >= j) {
return 1;
}
//找第一个大于root的位置,其左边肯定小于root,右边肯定大于root,根据这个道理对其进行判断
int m = i;
while (m < j && postorder[m] < postorder[j]) {
m++;
}
//判断其右边是否大于root
int p = m;
while (p < j && postorder[p] > postorder[j]) {
p++;
}
//如果右边都大于root那么p到最后一定等于j
return p == j && judgeVector(postorder, i, m - 1) && judgeVector(postorder, m, j - 1);
}
};
方法一:单调栈的使用,题目说要判断一个数组是不是后续遍历(left->righe->root)的结果,那我们不妨将其数组颠倒过来,那是不是就是(root->right->left)这不就成了从right开始的先序遍历,那我们只要掌握了先序遍历的规则,岂不是迎刃而解,这里使用到了单调栈,因为我们是从right开始的,根据二叉搜索树的概念,那么right>root,根据这个特性,我们使用单调递增的栈,如果栈非空并且访问的该元素大于栈顶元素那么就表示还是访问right,我们直接压入就行,不需要其他操作,但是若一个元素小于栈顶元素,那么就表示某一个root的right访问完了,现在该访问这个root的left了,那么现在的问题就转变成了怎么记录下这个root的值,以便做题,那我们能想到,二叉搜索树right都是大于root值的,并且我们刚才已经将right的值都已经存入单调栈了,那么我们只需要一只弹出刚才栈顶的元素,并记录下来,知道栈顶元素小于该值就说明上一个弹出的栈顶元素就是现在数组所指向位置索引的root了,这样问题就解决了,那么到底怎么他才不是一个二叉搜索的后序遍历呢,其实很简单,二叉搜索树的root>left,right>root我们刚才又知道了root的值,那么我们直接比较就行了,如果数组访问的元素大于之前记录的root值即left>root了,那么就不是了。

方法二:
剑指 Offer 34. 二叉树中和为某一值的路径
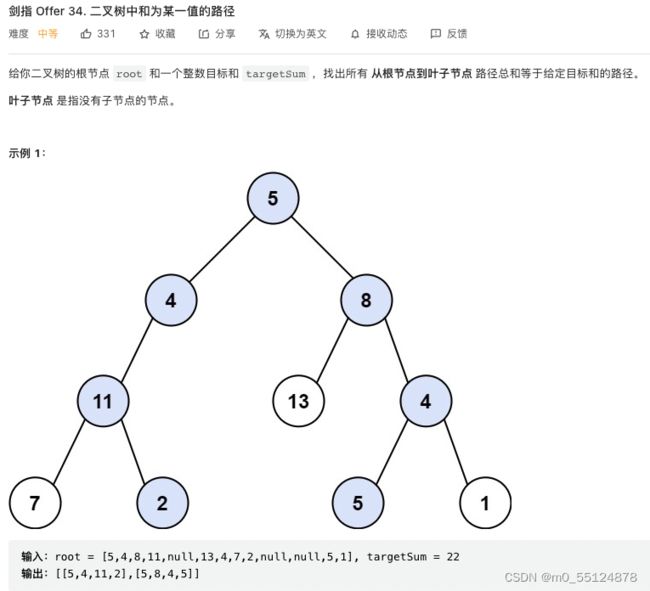
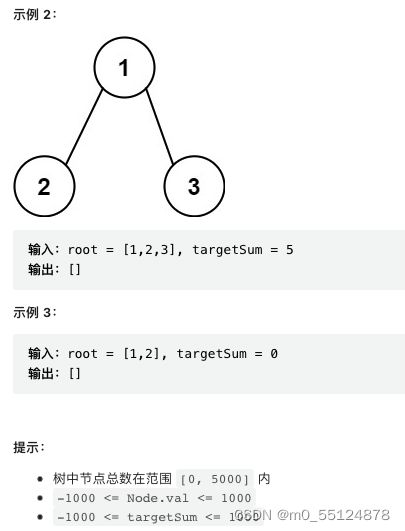
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> pathSum(TreeNode* root, int target) {
vector<int> tempVector;
vector<vector<int>> myVector;
dfs(root, target, myVector, tempVector);
return myVector;
}
void dfs(TreeNode *root, int target, vector<vector<int>>& myVector, vector<int>& tempVector) {
if (!root) {
return;
}
target -= root->val;
tempVector.push_back(root->val);
if (!target && !root->left && !root->right) {
myVector.push_back(tempVector);
} else {
dfs(root->left, target, myVector, tempVector);
dfs(root->right, target, myVector, tempVector);
}
tempVector.pop_back();
//target += root->val;这个可以不要,因为我们是值传递,而不是引用传递,所以不会修改掉原值
}
};
深度优先搜索,再加判断就行了,用vector存储它的值,并且vector和target是同步的,同时加减。
剑指 Offer 35. 复杂链表的复制
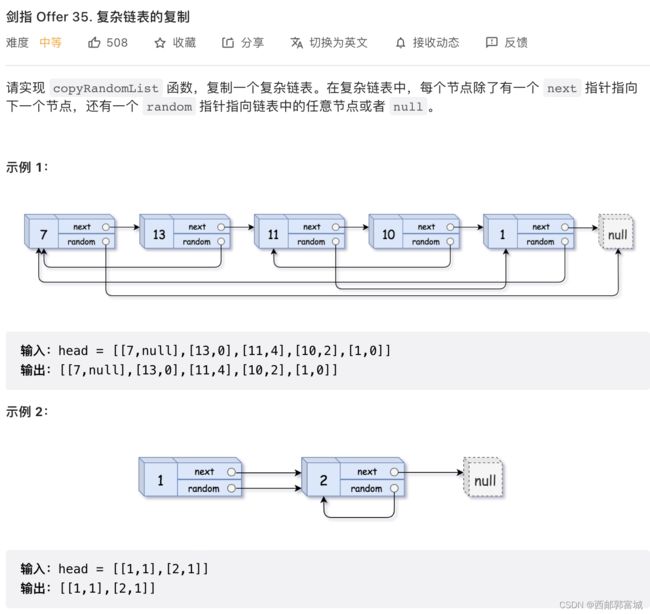
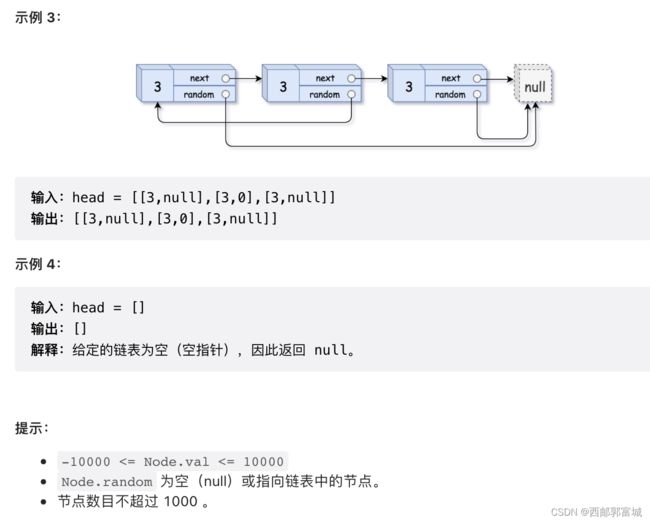
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
if (head == NULL) {
return head;
}
//复制节点
Node *temp = head;
while (temp) {
Node *copyNode = new Node(temp->val);
copyNode->next = temp->next;
temp->next = copyNode;
temp = temp->next->next;
}
//完成链表复制节点的随机指针复制
temp = head;
while (temp) {
if (temp->random != NULL) {
temp->next->random = temp->random->next;
}
temp = temp->next->next;
}
//将链表一分为二,删除原来的所有节点
Node *newHead = head->next;
temp = head->next;
Node *mid = head;
while (mid) {
mid->next = mid->next->next;
if (temp->next) {
temp->next = temp->next->next;
temp = temp->next;
} else {
temp->next = NULL;
}
mid = mid->next;
}
return newHead;
}
};
- 复制一个新的节点在原有节点之后,如 1 -> 2 -> 3 -> null 复制完就是 1 -> 1 -> 2 -> 2 -> 3 - > 3 -> null
- 从头开始遍历链表,通过 cur.next.random = cur.random.next 可以将复制节点的随机指针串起来,当然需要判断 cur.random 是否存在
- 将复制完的链表一分为二 根据以上信息,我们不难写出代码
剑指 Offer 36. 二叉搜索树与双向链表
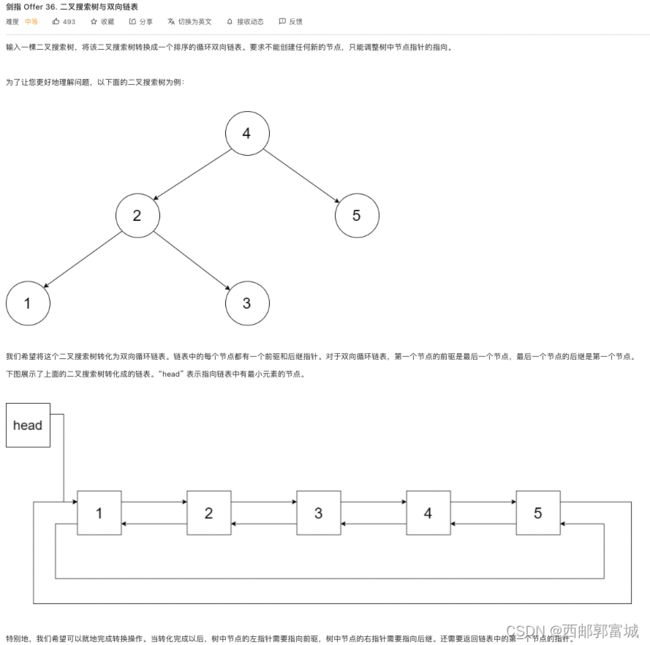
/*
// Definition for a Node.
class Node {
public:
int val;
Node* left;
Node* right;
Node() {}
Node(int _val) {
val = _val;
left = NULL;
right = NULL;
}
Node(int _val, Node* _left, Node* _right) {
val = _val;
left = _left;
right = _right;
}
};
*/
class Solution {
public:
Node *pre = NULL; //每次都指向root节点的前一个节点,它的第一次指向和fir相同
Node *fir = NULL; //一直都指向的是最小数的位置
Node* treeToDoublyList(Node* root) {
if (!root) {
return NULL;
}
dfs(root);
pre->right = fir; //让尾节点,即最大值节点的right指向首节点,即最小值节点
fir->left = pre; //让首节点,即最小值节点的left指向尾节点,即最大值节点
return fir;
}
private:
//中序遍历真的很好用,它会返回一个有序序列,我们只需要补充中序操作就行了
void dfs(Node *root) {
if (!root) {
return;
}
dfs(root->left);
if (!pre) { //及遍历到了最左下的位置,也就是值最小的位置
fir = root;
} else { //紧接着的三步操作就和双指针一样,pre一直指向的是root前一个节点,因为我们使用的是递归操作,不用再考虑之后的访问问题,所以我们就直接可以进行交换节点的指向
pre->right = root; //让前一个节点指向right指向当前节点root
root->left = pre; //让当前节点的left指向前一个节点
}
pre = root; //原本指向前一个节点的指针指向当前节点
dfs(root->right);
}
};
很玄幻,很妙,这个中序遍历,因为你之前已经递归到最小位置的节点了,所以你根本就不需要考虑后续怎么再返回上一个节点,你直接在中序的地方做你想要的操作就行了,这里root指向的是当前节点,而pre指向的是root的前一个节点,所以我们只需要将pre->right = root、root->left = pre这样就完成了这两个节点的双向链表的连接了,最后在记录下这个节点pre = root就好了,它就会一直递归上去,直到pre指向最后一个节点,即最大值节点,那么就剩一个问题了,怎么高效率的将头尾相连接起来,那么我们能想到,一开始的pre指向的是空,它直到访问到最小值节点,即头节点才会开始做中序的操作,那么这时候我们再定义一个指针fir一直指向这个头节点,最后直接对fir和pre进行连接操作岂不是快了很多,所以我们通过对pre的初值进行判空,若是空那么就表示才刚刚到达首节点,那么就赋值就行了,这样就记录下来这个节点了,最后通过pre->right = fir、fir->left = pre就完成了。
剑指 Offer 37. 序列化二叉树
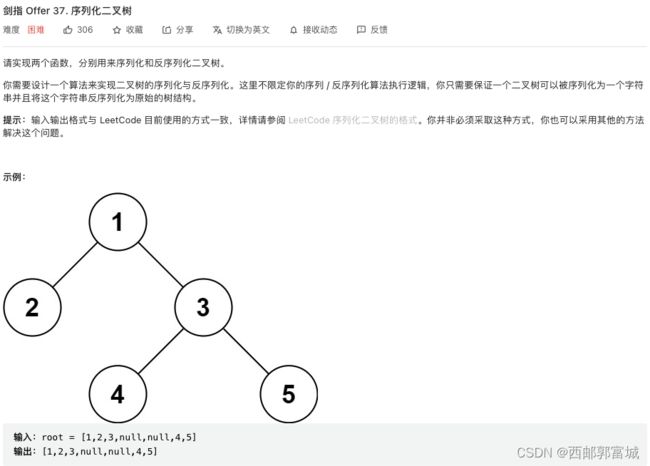
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Codec {
public:
// Encodes a tree to a single string.
string serialize(TreeNode* root) {
if (root == nullptr) {
return "";
}
queue<TreeNode*> q;
q.push(root);
string ans;
while (!q.empty()) {
TreeNode* t = q.front();
q.pop();
if (t == nullptr) {
ans += "#,";
} else {
ans += to_string(t->val) + ',';
q.push(t->left);
q.push(t->right);
}
}
return ans;
}
// Decodes your encoded data to tree.
TreeNode* deserialize(string data) {
if (data.length() == 0) {
return nullptr;
}
vector<TreeNode *> myVector;
int idx = 0;
//将节点都存入数组中
while (idx < data.length()) {
string tempString = "";
//存储两个 , 中间的字符
while (data[idx] != ',') {
tempString += data[idx];
++idx;
}
//若tempstring没有数据,则存入空,反之创建节点并存入
if (tempString == "#") {
myVector.push_back(nullptr);
} else {
int num = atoi(tempString.c_str());
TreeNode *tempNode = new TreeNode(num);
myVector.push_back(tempNode);
}
++idx;
}
//连接各个节点
int pos = 1;
for (int i = 0; i < myVector.size(); i++) {
if (myVector[i] == nullptr) {
continue;
}
myVector[i]->left = myVector[pos++];
myVector[i]->right = myVector[pos++];
}
return myVector[0];
}
};
// Your Codec object will be instantiated and called as such:
// Codec codec;
// codec.deserialize(codec.serialize(root));
这就是二叉树的创建和输出,哎嘘,要人命呢。
剑指 Offer 38. 字符串的排列

//方法一:
class Solution {
public:
vector<string> permutation(string s) {
vector<string> myVector;
sort(s.begin(), s.end());
do {
myVector.push_back(s);
} while (next_permutation(s.begin() , s.end()));
return myVector;
}
};
//next_permutation是求当前排列的下一个排列,(按字典升序的下一个序列),如1234的next_permutation是1243,常用于全排列题目
//返回值:如果有下一个序列就返回1,否则返回0
//方法二:
class Solution {
public:
vector<string> permutation(string s) {
vector<string> myVector;
dfs(myVector, s, 0);
return myVector;
}
void dfs(vector<string>& myVector, string &s, int pos) {
if (pos == s.size()) {
myVector.push_back(s);
}
for (int i = pos; i < s.size(); i++) {
int flag = 1;
for (int j = pos; j < i; j++) { //字母相同时,等效,就不用再次交换加入vector了,去重,剪枝
if (s[j] == s[i]) {
flag = 0;
}
}
if (flag) {
swap(s[pos], s[i]);
dfs(myVector, s, pos + 1);
swap(s[pos], s[i]); //再交换回来
}
}
}
};
方法一:使用c++中的next_permutation函数,直接存储所有序列。
方法二:标准的深度优先搜索,做一下剪枝就好。
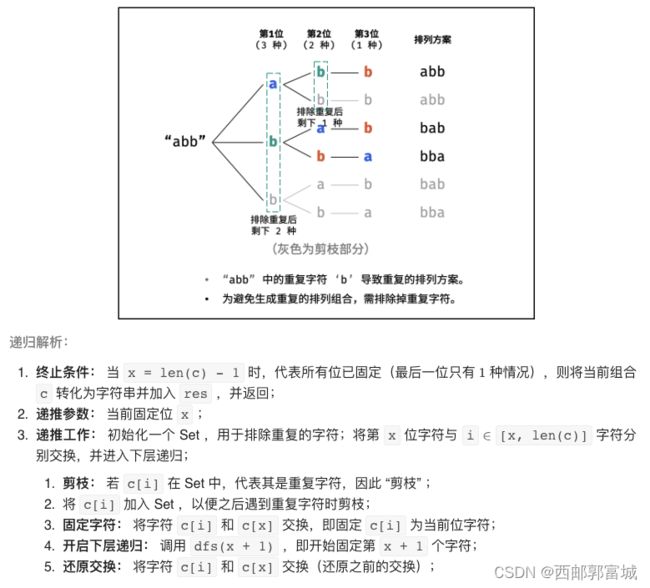
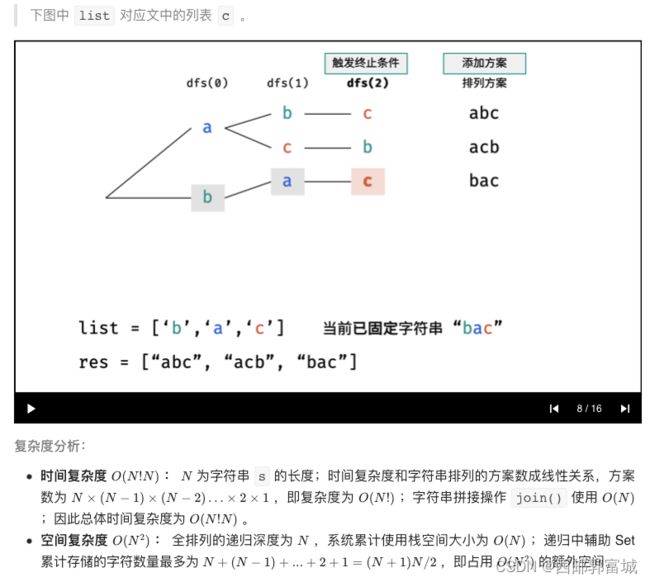
剑指 Offer 39. 数组中出现次数超过一半的数字

//方法一:
class Solution {
public:
int majorityElement(vector<int>& nums) {
map<int, int> myMap;
for (int i = 0; i < nums.size(); i++) {
myMap[nums[i]]++;
if (myMap[nums[i]] > nums.size() / 2) {
return nums[i];
}
}
return 0;
}
};
//方法二:
class Solution {
public:
int majorityElement(vector<int>& nums) {
sort(nums.begin(), nums.end());
return nums[nums.size() / 2];
}
};
//方法三:
class Solution {
public:
int majorityElement(vector<int>& nums) {
int num = nums[0];//记录最有可能的众数
int count = 0; //记录抵消后num的数量
for (auto i: nums) {
if (!count) { //如果抵消后num数量为0,那就表示该数可能不是众数,换下一个数
num = i;
count++;
continue;
}
if (i == num) {
count++;
} else {
count--;
}
}
return num;
}
};
方法一:哈希表,没啥说的,不用等遍历完了再判断,直接可以进行判断。
方法二:排序,因为它的数量大于长度的一半,所以数组中间一定是该数。
方法三:Boyer-Moore 投票算法。

剑指 Offer 40. 最小的k个数
//方法一:
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& arr, int k) {
sort(arr.begin(), arr.end());
vector<int> myVector;
while (k) {
myVector.push_back(arr[k - 1]);
k--;
}
return myVector;
}
};
//方法二:
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& arr, int k) {
vector<int> myVector;
if (!k || !arr.size()) {
return myVector;
}
//c++优先队列就是大根堆,即堆顶是最大的元素
priority_queue<int> myQueue;
//先压入四个元素
for (int i = 0; i < k; i++ ) {
myQueue.push(arr[i]);
}
//然后一直比较,打了就剔除,压入新的
for (int i = k; i < arr.size(); i++) {
if (myQueue.top() > arr[i]) {
myQueue.pop();
myQueue.push(arr[i]);
}
}
//把最终剩下来的k个数存入数组
while (k--) {
myVector.push_back(myQueue.top());
myQueue.pop();
}
return myVector;
}
};
//方法三:
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& arr, int k) {
vector<int> myVector;
quickSort(arr, 0, arr.size() - 1);
while (k--) {
myVector.push_back(arr[k]);
}
return myVector;
}
private:
void quickSort(vector<int>& arr, int left, int right) {
if (left >= right) {
return;
}
int tempLeft = left;
int tempRight = right;
int base = arr[tempLeft]; //最左边元素作为基准元素
while (tempLeft < tempRight) {
//从右往左扫描,找到第一个比基准元素小的元素
while (tempRight > tempLeft && arr[tempRight] >= base) {
tempRight--;
}
//从左往右扫描,找到第一个比基准元素大的元素
while (tempLeft < tempRight && arr[tempLeft] <= base) {
tempLeft++;
}
//找到这种元素arr[tempLeft]后,与arr[tempRight]交换
if (tempLeft < tempRight) {
swap(arr[tempLeft], arr[tempRight]);
}
}
//基准元素归位
arr[left] = arr[tempLeft];
arr[tempLeft] = base;
quickSort(arr, left, tempLeft - 1); //对基准元素左边的元素进行递归排序
quickSort(arr, tempLeft + 1, right); //对基准元素右边的进行递归排序
}
};
方法一:offer转移法,直接排序,返回前k个。
方法二:使用大根堆即根为最大数,队列中先存入k个元素,然后再使用数组剩下的元素与队头进行比较,因为要最小的k个,所以队头比数组元素大了才进行操作,出队,入队新元素,最终再将这个队列中的元素存入返回数组,就完成了。
方法三:快排。
剑指 Offer 41. 数据流中的中位数
class MedianFinder {
public:
/** initialize your data structure here. */
priority_queue<int, vector<int>, less<int>> smallQueue; //从大到小排序
priority_queue<int, vector<int>, greater<int>> bigQueue; //从小到大排序
int n;
MedianFinder() {
n = 0;
}
void addNum(int num) {
if (smallQueue.empty()) {
smallQueue.push(num);
n++;
return;
}
if (smallQueue.top() > num) {
smallQueue.push(num);
} else {
bigQueue.push(num);
}
n++;
if (smallQueue.size() - bigQueue.size() == 2) {
bigQueue.push(smallQueue.top());
smallQueue.pop();
}
if (bigQueue.size() - smallQueue.size() == 2) {
smallQueue.push(bigQueue.top());
bigQueue.pop();
}
}
double findMedian() {
if (n % 2) {
if (smallQueue.size() > bigQueue.size()) {
return (double)smallQueue.top();
} else {
return (double)bigQueue.top();
}
} else {
return (double)(smallQueue.top() + bigQueue.top()) / 2;
}
}
};
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder* obj = new MedianFinder();
* obj->addNum(num);
* double param_2 = obj->findMedian();
*/
看不懂看不懂,直接就是一个双顶对冲,一个大根堆一个小根堆(大根堆就是堆顶是最大的数,小根堆就是堆顶是最小的数),等于说是把存入的数据从中间砍成两半,小根堆里存储都是大于大根堆顶的数,大根堆存储都是小于小根堆堆顶的数,那么这两个数中间就是整体数据的中间,那么我们只需要再判断是偶数个数据还是奇数个数据就好,奇数个就返回两个根堆size大的那个堆顶,偶数个就返回两个顶之和除以2,那么我们就只需要再使用一个数据存储总数据的个数就行了。输入的同时保证两堆的大小之差不超过一,如果超过,则将数量多的堆弹出堆顶元素放到另一个堆中,确保他们两个堆顶就是数据中间的数。
剑指 Offer 42. 连续子数组的最大和

class Solution {
public:
int maxSubArray(vector<int>& nums) {
int all = INT_MIN, temp = 0;
for (int i = 0; i < nums.size(); i++) {
temp += nums[i];
all = max(all, temp);
if (temp < 0) {
temp = 0;
}
}
return all;
}
};
这个类似于我之前写的包含min函数的栈,不过这里是使用一个变量一直存储最大值,另一个变量一直在顺着数组往后加,如果小于0了就将其归零继续加,直至数组末尾。

剑指 Offer 43. 1~n 整数中 1 出现的次数

class Solution {
public:
int countDigitOne(int n) {
int high = n / 10; //高位
int cur = n % 10; //当前位
int low = 0; //低位
long int digit = 1; //位因子
long int num = 0; //1个总个数
while (high != 0 || cur != 0) {
if (cur == 0) {
num += high * digit;
} else if (cur == 1) {
num += high * digit + low + 1;
} else {
num += (high + 1) * digit;
}
//到一下位
digit *= 10;
cur = high % 10;
high /= 10;
low = n % digit;
}
return num;
}
};



case 1: cur=0
2 3 0 4
千位和百位可以选00 01 02…22 十位可以取到1( 形如[00|01…|22]1[0-9] 都是<2304 ) 个位可以选0-9 共有 23 * 10 中排列
当千位和百位取23,如果十位取1 那就是形如 231[0-9] > 2304,所以当千位和百位取23,十位只能能取0,个位取0-4即 2300 2301 2302 2303 2304
但是2301不应该算进来,这个1是 单独 出现在个位的(而11,121,111这种可以被算多次)
即 23*10
case 2: cur=1
2 3 1 4
千位和百位可以选00 01 02…22 十位可以取到1 个位可以选0-9 共有 23 * 10 中排列
当千位和百位取23,十位取1,个位可以去0-4 即 2310-2314共5个
即 23 *10 + 4 +1
case 3: cur>1 即2-9
2 3 2 4
千位和百位可以选00 01 02…22 十位可以取到1(形如 [00|01…|22]1[0-9] 都是<2324) 个位可以选0-9 共有 23 * 10 中排列
当千位和百位取23,十位取1,个位可以去0-9 即 2310-2319共10个 (其中2311,被计算了两次,分别是从个位和十位分析得到的1次)
即 23 *10 + 10
只能说困难题还是不是我能指染的。
剑指 Offer 44. 数字序列中某一位的数字
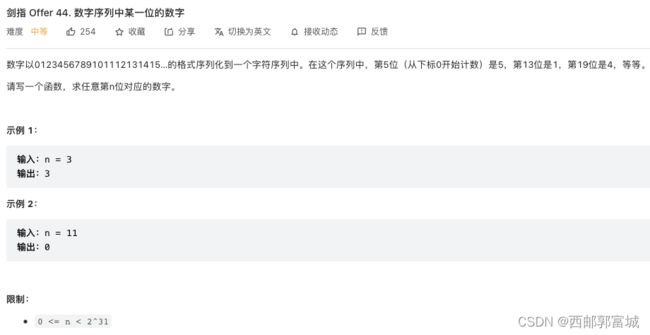
class Solution {
public:
int findNthDigit(int n) {
long int start = 1; //每digit位数的起始数字
int digit = 1; //位数
long int count = 9; //数位数量
//找到该数的位数
while (n > count) {
n -= count;
digit++;
start *= 10;
count = 9 * start * digit;
}
//找到具体数字
long int num = start + (n - 1) / digit;
//找到具体位
return to_string(num)[(n - 1) % digit] - '0';
}
};


剑指 Offer 45. 把数组排成最小的数
class Solution {
public:
string minNumber(vector<int>& nums) {
vector<string> stringVector;
for (auto num : nums) {
stringVector.push_back(to_string(num));
}
//compareString位用于规定排序的方法,可不填,默认升序。
sort(stringVector.begin(), stringVector.end(), compareString);
string myString;
for (auto temp : stringVector) {
myString += temp;
}
return myString;
}
private:
static bool compareString(const string &a, const string &b) {
return a + b < b + a;
}
};
这道题就是一个排序题,其实你想明白当a+b>b+a时进行交换,这道题就游刃而解了。但是这里的a+b和b+a并不是简单的相加,而是字符串进行相加,即拼接。
剑指 Offer 46. 把数字翻译成字符串
class Solution {
public:
int translateNum(int num) {
if (num == 0) {
return 1;
}
//将数字转换成数组
vector<int> myNum;
while (num) {
myNum.push_back(num % 10);
num /= 10;
}
reverse(myNum.begin(), myNum.end());
vector<int> transNumber;
int i = 0;
for (i = 0; i < myNum.size(); i++) {
if (i == 0) { //一个数字它肯定就只有一种翻译方法
transNumber.push_back(1);
} else if (i == 1) {
if (myNum[i - 1] * 10 + myNum[i] < 26) {
transNumber.push_back(2);
} else {
transNumber.push_back(1);
}
} else {
if (myNum[i - 1] * 10 + myNum[i] < 26 && myNum[i - 1] * 10 + myNum[i] > 9) {
transNumber.push_back(transNumber[i - 1] + transNumber[i - 2]);
} else {
transNumber.push_back(transNumber[i - 1]);
}
}
}
return transNumber[i - 1];
}
};
思路就是找规律,这个其实和之前的青蛙跳台阶差不多,不过每次都加一个判断条件,看其是否可以组合(即该位和上一位组合是不是大于10小于26,因为存在0这个数,所以要考虑其特殊的结合情况),如果可以组合,那么该位的dp[i]就是dp[i] = dp[i - 1] + dp[i - 2];,不可以结合的话就是dp[i] = dp[i - 1];因为之前已经考虑过各自翻译的情况了,所以现在就算新加一个数也没有啥影响,它的dp数不会增加。
剑指 Offer 47. 礼物的最大价值
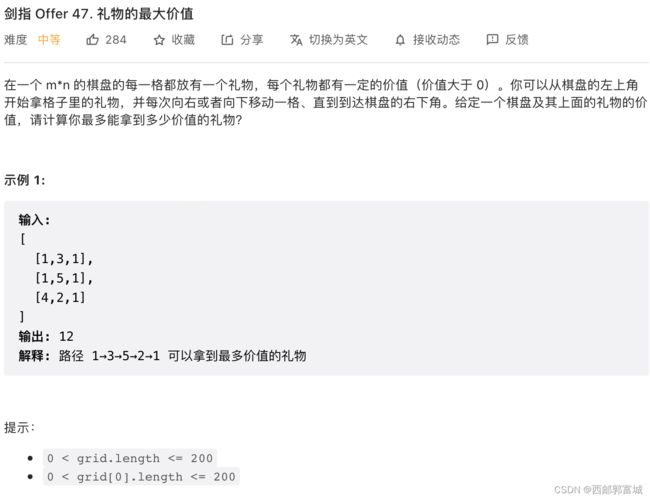
class Solution {
public:
int maxValue(vector<vector<int>>& grid) {
int i = 0, j = 0;
int section = grid.size(), row = grid[0].size();
for (int i = 0; i < section; i++) {
for (int j = 0; j < row; j++) {
if (i == 0 && j > 0) {
grid[i][j] += grid[i][j - 1];
} else if (i > 0 && j == 0) {
grid[i][j] += grid[i - 1][j];
} else if (i > 0 && j > 0) {
grid[i][j] += max(grid[i - 1][j], grid[i][j - 1]);
}
}
}
return grid[section - 1][row - 1];
}
};
第一时间想到二维dp数组,其中dp[i][j]为到第i行第j列时可获得的最大价值。
第i行第j列的最大价值(dp[i][j])可以为:
- 左边一格的最大价值(dp[i][j - 1])加目前格子(grid[i][j])
- 上面一格的最大价值(dp[i - 1][j])加目前格子(grid[i][j])
那么转移方程为:dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]) + grid[i][j]
考虑边界情况:
- i == 0, j == 0, 最左上角直接为格子本身(grid[i][j])
- i == 0, j != 0, 第一行没有上面格子只能是左边一格的最大价值(dp[i][j - 1])加目前格子(grid[i][j])
- i != 0, j == 0, 第一列没有左边格子只能是上面一格的最大价值(dp[i - 1][j])加目前格子(grid[i][j])
他这个很妙,用我的话来解释如下:每个位置的最大价值其实就是看他的上边和左边的两个最大价值谁大,这个位置就加上那两个中较大的数值。第一行因为没有上边,所以不用比较,就直接加每个位置左边就行,就是这个位置的最大价值。第一列因为没有左边,所以也不用比较,就直接加每个位置上边就行了,就是这个位置的最大价值。还不懂就画图,一画就懂了。
剑指 Offer 48. 最长不含重复字符的子字符串
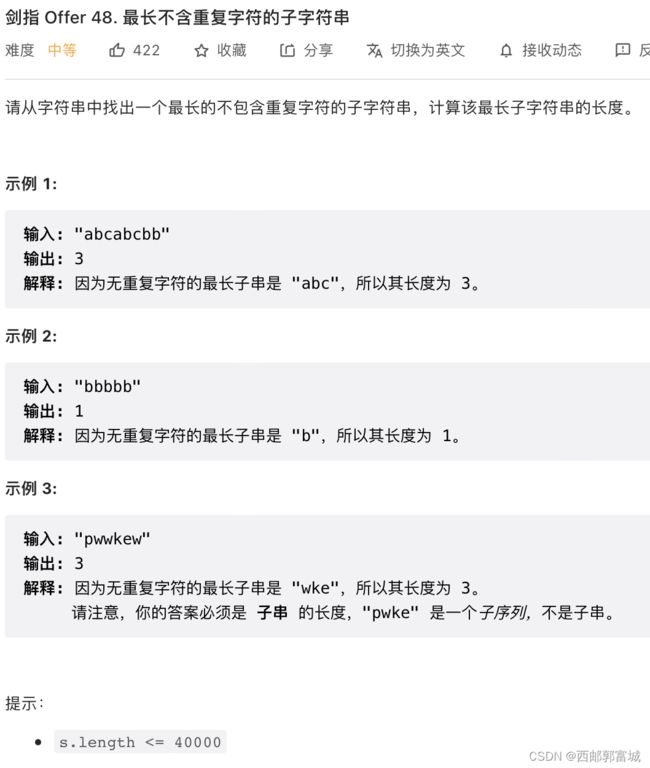
class Solution {
public:
int lengthOfLongestSubstring(string s) {
//特殊情况
if (s.length() == 1 || s.length() == 0) {
return s.length();
}
int value = 1, temp = 1; //value用于存储最大的返回值,temp用于存储每次falg改变之前的值,在其值改变的时候要与value进行比较,保证实时记录其返回的最大值
int flag = 0; //指向之前判断的相等字符位置的后一个位置,指向这的时候就表示由此之后到i就没有与之相等的字符了
int judge = 0; //判断其是否遇到相等的字符
for (int i = 1; i < s.length(); i++) {
judge = 0;
for (int j = i - 1; j >= flag; j--) {
//遇到相等的字符先获取其之前不相等的长度,并且与value进行比较,记录其最大值,然后初始化temp并且让falg指向相等字符的下一个位置
if (s[j] == s[i]) {
judge = 1;
if (temp < i - flag) {
temp = i - flag;
}
if (temp > value) {
value = temp;
}
temp = 1;
flag = j + 1;
break;
}
}
if (judge == 0 && i == s.length() - 1) { //字符串到最后并且在flag之前没有重复的
if (temp < i - flag + 1) {
temp = i - flag + 1;
}
} else if (judge == 0) { //在flag之前没有重复的
temp++;
}
if (temp > value) { //实时记录数据
value = temp;
}
}
return value;
}
};
定义一个flag指针,一直指向的是相等字符位置的下一个位置,在使用循环一直跑,从第i位跑到,flag的位置,因为flag之前一定有重复的字符,所以再往前跑也没用,就跑到flag就行了,一直循环,直到字符串结束,同时因为考虑到结束时的特殊情况,在结束的时候还没有找到的话就说明到flag之前一直没有重复字符,所以你还得做一次处理,存储其最大值。value是用来存储最终返回值的最大值的,每次记录临时长度的temp改变都需要和value进行比较,并且保证数据的实时性。judge就是一个判断是否找到重复值的操作,通过判断它来保证后续的特殊操作。
### 剑指 Offer 49. 丑数

class Solution {
public:
int nthUglyNumber(int n) {
vector<int> dp;
dp.push_back(1);
int n2 = 0, n3 = 0, n5 = 0;
for (int i = 1; i < n; i++) {
dp.push_back(min(dp[n2] * 2, min(dp[n3] * 3, dp[n5] * 5)));
if (dp[i] == dp[n2] * 2) {
n2++;
}
if (dp[i] == dp[n3] * 3) {
n3++;
}
if (dp[i] == dp[n5] * 5) {
n5++;
}
}
return dp[n - 1];
}
};
使用三指针法,这个找丑数你只要认真看,就能发现其实是每个数乘以2,3,5之后再按照从小到大的顺序排下来的,所以我们使用三指针分别指向2,3,5相乘的位置,每次压入其这三个数中最小的数,然后进行判断,到底是哪个相乘的出来的结果,这里要注意,因为可能出现数重复的现象,所以我们不能使用if else而是使用三个if将其都判断一次。
剑指 Offer 50. 第一个只出现一次的字符
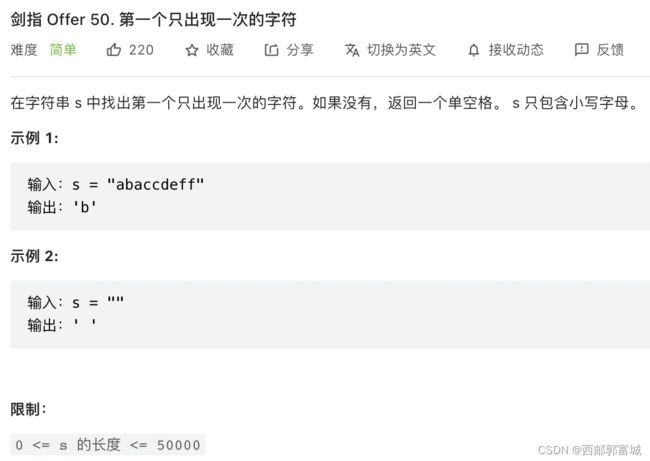
class Solution {
public:
char firstUniqChar(string s) {
unordered_map<char, int> myMap;
for (int i = 0; i < s.length(); i++) {
myMap[s[i]]++;
}
for (int i = 0; i < s.length(); i++) {
if (myMap[s[i]] == 1) {
return s[i];
}
}
return ' ';
}
};
使用c++中自带的map,第一次将所有字符对应出现的次数按出现顺序存入map中,第二次再进行遍历,找到第一个出现一次的字符,也就是数值等于1的字符,返回就行,空就返回’ '。
剑指 Offer 51. 数组中的逆序对
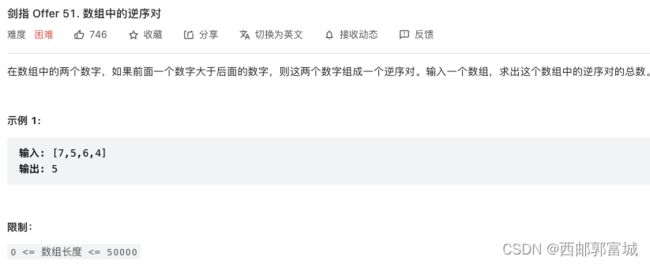
class Solution {
//一个全局的计数器,其个数就是结果
int count = 0;
public:
int reversePairs(vector<int>& nums) {
count = 0;
mergeSort(nums, 0, nums.size() - 1);
return count;
}
private:
void mergeSort(vector<int>& nums, int left, int right) {
//当只有一个节点的时候,直接返回,退出递归
if (left >= right) {
return;
}
int mid = (right - left) / 2 + left;
//左拆分
mergeSort(nums, left, mid);
//右拆分
mergeSort(nums, mid + 1, right);
//合并
merge(nums, left, mid, right);
}
void merge(vector<int>& nums, int left, int mid, int right) {
//定义一个临时数组
vector<int> myVector(right - left + 1);
//定义一个指针,指向第一个数组的第一个元素
int i = left;
//定义一个指针,指向第二个数组的第一个元素
int j = mid + 1;
//定义一个指针,指向临时数组要操作的位置
int t = 0;
//将两个数组进行合并
while (i <= mid && j <= right) {
//比较两个数组元素,取较小的元素加入到临时数组中
//并将两个指针指向下一个要操作的元素
if (nums[i] <= nums[j]) {
myVector[t++] = nums[i++];
} else {
//当左边数组的大与右边数组的元素时,就对当前元素以及后面的元素的个数进行统计,
//此时这个数就是,逆序数
//定义一个计数器,记下每次合并中存在的逆序数。
count += mid - i + 1; //因为i位的数都大于这个数了,并且第一个数组i之后的数比i还大,那么后面的数和j位的数组合都是一个逆序数了
myVector[t++] = nums[j++];
}
}
//遍历没有遍历完的元素
//如果第一个数组没有遍历完,那么就直接将其剩余元素全部赋值到临时数组的后边
//因为前面是用的mid+1-i,这就使得i后面直到mid和j构成的逆序数都已经计算过了,再最后把多的复制过去的时候就不用再管了
while (i <= mid) {
myVector[t++] = nums[i++];
}
//如果第二个数组没有遍历完,那么就直接将其剩余元素全部赋值到临时数组的后边
while (j <= right) {
myVector[t++] = nums[j++];
}
//使用临时数组中的数据覆盖nums旧数组的数据
//此时数组的元素已经是有序的
for (int k = 0; k < myVector.size(); k++) {
nums[left + k] = myVector[k];
}
}
};
//使用分治算法,当左边数组的大与右边数组的元素时,就对当前元素以及后面的元素的个数进行统计,最终这个统计的数就是其结果
使用分治算法,当左边数组的大与右边数组的元素时,就对当前元素以及后面的元素的个数进行统计,最终这个统计的数就是其结果。
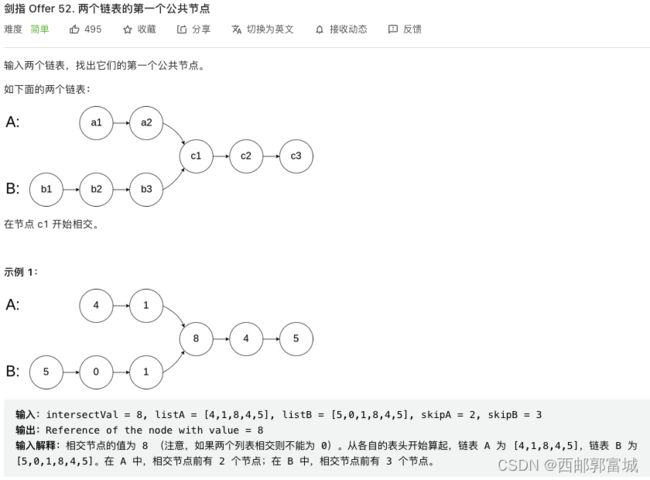
剑指 Offer 52. 两个链表的第一个公共节点

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode *you = headA;
ListNode *me = headB;
while (you != me) {
if (you) {
you = you->next;
} else {
you = headB;
}
if (me) {
me = me->next;
} else {
me = headA;
}
}
return you;
}
};
这可能是我做过最骚的题了,❤两个结点不断的去对方的轨迹中寻找对方的身影,只要二人有交集,就终会相遇❤,若有缘,彼此一起走,走到了各自人生的尽头,在体验对方的人生,我们终会在第一次相见时处再次相遇。若无缘,我们再体验对方人生,注定会同时走向尽头,结束循环。
剑指 Offer 53 - I. 在排序数组中查找数字 I

//方法一:
class Solution {
public:
int search(vector<int>& nums, int target) {
int t = 0;
for (int i = 0; i < nums.size(); i++) {
if (target < nums[i]) {
return t;
}
if (nums[i] == target) {
t++;
}
}
return t;
}
};
//方法二:
class Solution {
public:
int binarySearch (vector<int>& nums, int target, bool lower) {
int left = 0, right = (int)nums.size() - 1, ans = (int)nums.size();
while (left <= right) {
int mid = (left + right) / 2;
if (nums[mid] > target || (lower && nums[mid] >= target)) {
right = mid - 1;
ans = mid;
} else {
left = mid + 1;
}
}
return ans;
}
int search (vector<int>& nums, int target) {
int leftIdx = binarySearch(nums, target, true);
int rightIdx = binarySearch(nums, target, false) - 1;
if (leftIdx <= rightIdx && rightIdx < nums.size() && nums[leftIdx] == target && nums[rightIdx] == target) {
return rightIdx - leftIdx + 1;
}
return 0;
}
};
方法一:暴力求解,找次数,比查找数的值大就直接停止查找。
方法二:二分查找要找数的两端,两端相减加一就是出现次数。
方法三:哈希表,懒得写了。
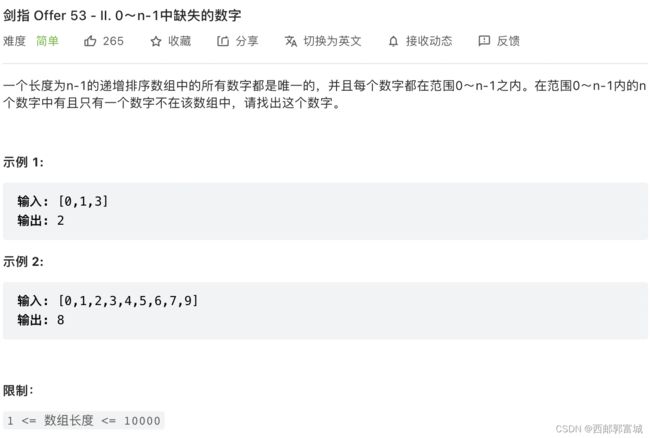
剑指 Offer 53 - II. 0~n-1中缺失的数字
//方法一:
class Solution {
public:
int missingNumber(vector<int>& nums) {
int left = 0;
int right = nums.size() - 1;
while(left <= right) {
int mid = (left + right) / 2;
/* 如果相等说明 left 到 mid 中间肯定不少元素 所以往右边二分查找 */
//如果nums[mid] == mid,表示左侧区域没有数字缺失,向右缩短边界
//如果nums[mid] > mid,表示左侧区域数字缺失,向左缩短边界
if (nums[mid] == mid) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return left;
}
};
方法一:二分法查找,若该数没问题的话,那么其索引一定为其值,以此为突破口,查找第一个索引与其值不同的位置,就是缺失数。
方法二:利用等差数列的求和公式(n*(n+1)/2),算出和,然后减去该数组总和,就是缺失数。
剑指 Offer 54. 二叉搜索树的第k大节点

/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
//方法一:
class Solution {
public:
vector<int> myVector;
int kthLargest(TreeNode* root, int k) {
transTree(root);
return myVector[myVector.size() - k];
}
private:
void transTree(TreeNode *root) {
if (!root) {
return;
}
if (root->left) {
transTree(root->left);
}
myVector.push_back(root->val);
if (root->right) {
transTree(root->right);
}
}
};
//方法二:
class Solution {
public:
int ans = 0, count = 0;
int kthLargest(TreeNode* root, int k) {
transTree(root, k);
return ans;
}
private:
void transTree(TreeNode *root, int k) {
if (root->right) {
transTree(root->right, k);
}
if (++count == k) {
ans = root->val;
return;
}
if (root->left) {
transTree(root->left, k);
}
}
};
二叉树的遍历,中序遍历的话它返回的就是一个有序序列,左中右是升序,右中左是降序,所以我们只要将其存储起来,最后直接返回就行了。或者我们可以直接将要返回的数用全局变量存储起来,最后直接返回就行,如方法二,但是它没有第一种快,因为它其实到最后还是会将这个遍历走完的,return也没用。
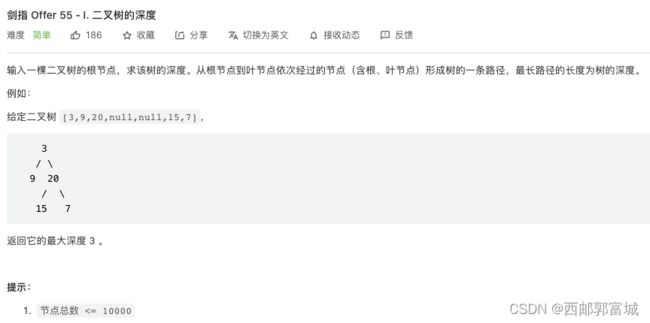
剑指 Offer 55 - I. 二叉树的深度
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
//方法一:
class Solution {
public:
int maxDepth(TreeNode* root) {
if (!root) {
return 0;
}
return max(maxDepth(root->left), maxDepth(root->right)) + 1;
}
};
//方法二:
class Solution {
public:
int depth = 0;
int maxDepth(TreeNode* root) {
dfs(root, 0);
return depth;
}
private:
void dfs(TreeNode* root, int now) {
if (!root) {
return;
}
now++;
if (now >= depth) {
depth = now;
}
dfs(root->left, now);
dfs(root->right, now);
}
};
没啥说的,递归。但是可能是因为不含有返回值的原因吧,第二种能比第一种快一点。
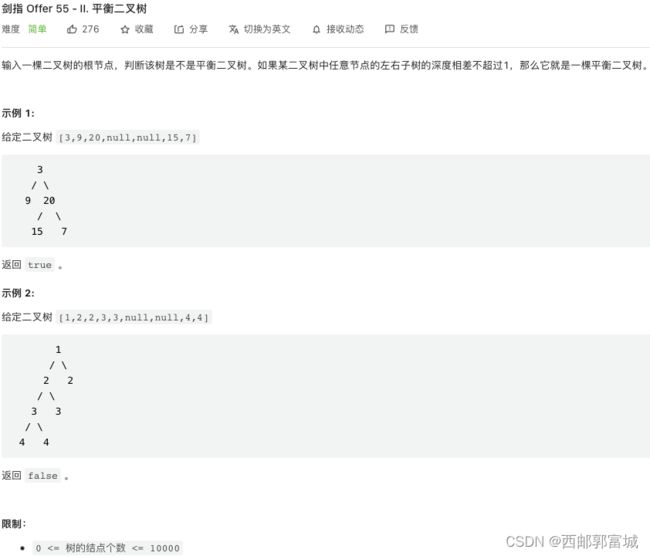
剑指 Offer 55 - II. 平衡二叉树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isBalanced(TreeNode* root) {
if (!root) {
return 1;
}
return isBalanced(root->left) && isBalanced(root->right) && abs(dfs(root->left) - dfs(root->right)) < 2;
}
private:
//计算深度
int dfs(TreeNode *root) {
if (!root) {
return 0;
}
return max(dfs(root->left), dfs(root->right)) + 1;
}
};
平衡二叉树的要求是,每个节点的左右子树深度差不超过1,那么我们就可以将其分为两步,一步是计算一个节点的高度差,另一步就是以平衡二叉树的条件遍历每一个节点,保证其每个节点都是平衡二叉树,这个数整体才是平衡二叉树。
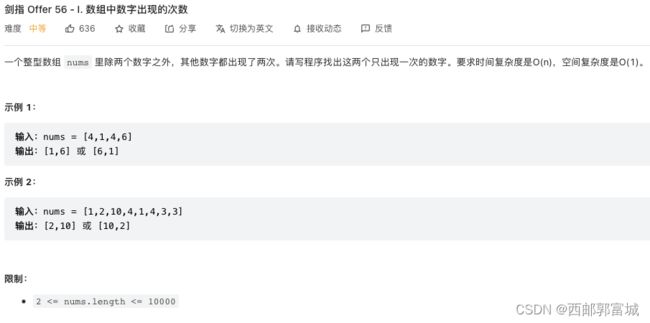
剑指 Offer 56 - I. 数组中数字出现的次数
class Solution {
public:
vector<int> singleNumbers(vector<int>& nums) {
//获取两个只出现一次的数字的 ^ 操作的值
int x = 0;
for (auto i : nums) {
x ^= i;
}
// x & (-x)本身的作用是得到最低位的1,因为x是两个不同的数^操作的结果,所以其不可能在相同的二进制位上都是1,所以我们可以通过此特性将其分开,得到其中一个数,使用flag对数组进行&运算,获取最低位也是1的数,并给另一个变量result一直^该最低位也是1的数,因为相同的会抵消,所以最终result一定会是两个只出现一次的数的其中一个,我们有了这个数,又有了其与另一个只出现一次的数的^结果,那么它两个在进行^操作就是另一个数了。
int flag = x & (-x), result = 0;
for (auto i : nums) {
//如果其&运算不为0,那么就一直给result进行^运算,并且相同的数^操作的值是相同的,第二次进行^操作那么就会抵消掉第一次的^操作
if (flag & i) {
result ^= i;
}
}
return {result, x ^ result};
}
};
这里利用了抑或运算的特性,相同的数进行疑惑运算结果为0,那么我们对整个数组进行抑或运算就得到了两个只出现一次的数的抑或结果x。此时的问题就成了怎么获取其中一个数,只要我们有了其中一个只出现一次的数result,那么另一个数就可以使用之前的抑或结果x和其再进行一次抑或运算就能得出另一个数了。此时我们可以想到,因为x是所有数抑或操作后的结果,再根据抑或的特性,相同二进制位相同时为0,也就是说明这两个只出现一次的数在这个位上不可能都是1,即第一个数在这个位上是1,那么另一个数在这个位上必不是1。那么就可以通过这个特性来获取其中之一的数了,我们这里使用flag存储x & (-x)操作的结果,x & (-x)本身的作用是得到最低位的1,所以我们对数组整体再进行遍历操作,判断条件就是如果和flag与运算之后不为0,即这个数在刚求出来的最低位上也是1,那么就将其和result(result初始化为0)进行抑或运算,一直到数组结束,还是因为上边所说的,相同的数进行抑或运算之后结果为0,所以遍历完一遍之后这个result就是两个数其中的一个数了,剩下的操作上边也都说过了,这样就得到了这两个只出现一次的数了。
剑指 Offer 56 - II. 数组中数字出现的次数 II

方法一:
class Solution {
public:
int singleNumber(vector<int>& nums) {
int ones = 0, twos = 0;
for (int num : nums) {
ones = ones ^ num & ~twos;
twos = twos ^ num & ~ones;
}
return ones;
}
};
方法一:自己创建一个三进制方法,看不太懂。
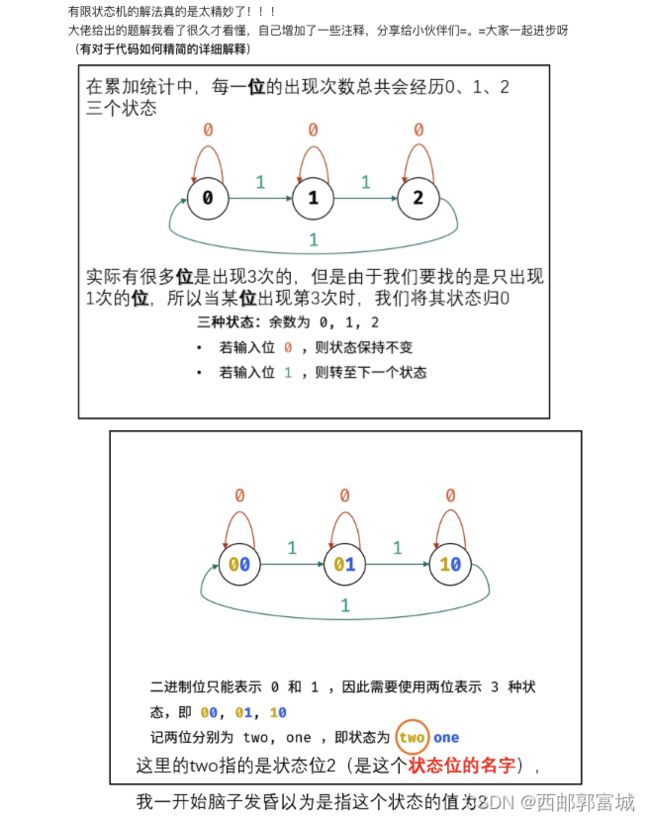



方法二:如果一个数字出现3次,它的二进制每一位也出现的3次。如果把所有的出现三次的数字的二进制表示的每一位都分别加起来,那么每一位都能被3整除。 我们把数组中所有的数字的二进制表示的每一位都加起来。如果某一位能被3整除,那么这一位对只出现一次的那个数的这一肯定为0。如果某一位不能被3整除,那么只出现一次的那个数字的该位置一定为1。
方法三:哈希表,没啥意思。
剑指 Offer 57. 和为s的两个数字
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
while (left < right) {
if (nums[left] + nums[right] == target) {
return {nums[left], nums[right]};
} else if (nums[left] + nums[right] > target) {
right--;
} else {
left++;
}
}
return {};
}
};
没啥好说的,双指针,大了右–,小了左++。
剑指 Offer 57 - II. 和为s的连续正数序列
class Solution {
public:
vector<vector<int>> findContinuousSequence(int target) {
vector<vector<int>> myVector;
if (target <= 2) { //小于等于2就没有连续的序列,直接返回
return myVector;
}
vector<int> tempVector;
int num = 1; //存储tempVector中数据的和
tempVector.push_back(num); //先存入1
while (tempVector.back() <= target / 2 + 2) {
if (num == target) { //等于就存,先加再减
myVector.push_back(tempVector); //将该vector加入返回的vector
num -= tempVector.front(); //减去要删除元素的值
tempVector.erase(tempVector.begin()); //删除临时vector的第一个元素
} else if (num > target) { //大于就删
num -= tempVector.front(); //减去要删除元素的值
tempVector.erase(tempVector.begin()); //删除临时vector的第一个元素
} else { //小于就加
tempVector.push_back(tempVector.back() + 1); //加入比原最后值大一的数
num += tempVector.back(); //同时总值也的加
}
}
return myVector;
}
};
使用滑动窗口解决,同时定义一个变量,存储这个窗口的总和,如果相等就存储起来同时删除窗口的第一个元素,如果大于就删除第一个元素,如果小于就再添加比原窗口大一的元素。注意,删除和增加的同时,总和也的删除和增加。
剑指 Offer 58 - I. 翻转单词顺序

class Solution {
public:
string reverseWords(string s) {
string myString;
stack<string> myStack;
//使用循环压入栈
for (int i = 0; i < s.length(); i++) {
if (s[i] == ' ' && myString.length()) {
myStack.push(myString);
myString.erase(myString.begin(), myString.end());
}
if (s[i] != ' ') {
myString += s[i];
}
}
//将最后一次的数据压入栈
if (myString.length()) {
myStack.push(myString);
myString.erase(myString.begin(), myString.end());
}
//拼接字符串
while (!myStack.empty()) {
myString.append(myStack.top());
myStack.pop();
if (!myStack.empty()) {
myString += ' ';
}
}
return myString;
}
};
将每个单词压入栈中,最后弹出,再拼接就完了。
剑指 Offer 58 - II. 左旋转字符串
//方法一:
class Solution {
public:
string reverseLeftWords(string s, int n) {
string oneString = s.substr(0, n);
string twoString = s.substr(n, s.size() - n);
return twoString + oneString;
}
};
//方法二:
class Solution {
public:
string reverseLeftWords(string s, int n) {
s = s.insert(s.size(), s.substr(0, n)); //向最后添加转的字符
s = s.erase(0, n); //删除开始到第n位字符
return s;
}
};
方法一:截取两段然后拼接。
方法二:先向string最后添加转的字符,然后删除开始到第n位字符。
剑指 Offer 59 - I. 滑动窗口的最大值
//方法一:
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
vector<int> myVector;
priority_queue<pair<int, int>> bigQueue;
for (int i = 0; i < nums.size(); i++) {
bigQueue.emplace(nums[i], i);
if (i + 1 >= k) {
while (bigQueue.top().second <= i - k) {
bigQueue.pop();
}
myVector.push_back(bigQueue.top().first);
}
}
return myVector;
}
};
//方法二:
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
vector<int> myVector;
deque<int> indexQueue;
for (int i = 0; i < nums.size(); i++) {
while (!indexQueue.empty() && nums[i] > nums[indexQueue.back()]) {
indexQueue.pop_back();
}
indexQueue.push_back(i);
if (i + 1 >= k) {
while (indexQueue.front() <= i - k) {
indexQueue.pop_front();
}
myVector.push_back(nums[indexQueue.front()]);
}
}
return myVector;
}
};
方法一:
方法二:这是一个双端队列。

剑指 Offer 59 - II. 队列的最大值
class MaxQueue {
private:
queue<int> myQueue;
deque<int> maxDeque;
public:
MaxQueue() {
}
int max_value() {
if (myQueue.empty()) {
return -1;
}
return maxDeque.front();
}
void push_back(int value) {
myQueue.push(value);
while (!maxDeque.empty() && value > maxDeque.back()) {
maxDeque.pop_back();
}
maxDeque.push_back(value);
}
int pop_front() {
if (myQueue.empty()) {
return -1;
}
int temp = myQueue.front();
myQueue.pop();
if (maxDeque.front() == temp) {
maxDeque.pop_front();
}
return temp;
}
};
/**
* Your MaxQueue object will be instantiated and called as such:
* MaxQueue* obj = new MaxQueue();
* int param_1 = obj->max_value();
* obj->push_back(value);
* int param_3 = obj->pop_front();
*/
这个题实际上和上边的滑动窗口是同一个类型的题,我们用一个双端队列maxDeque存储它的最大值,在push的时候,遇到value比其最后一个值大,就把最后一个数pop掉(因为这个滑动窗口中原来的最后一个值没有新的value大,而且如果pop的话一定是原来的值先pop出去,就说明原来的值现在在存储最大值的双端队列中存在的意义不大了),存入新的value。
剑指 Offer 60. n个骰子的点数
class Solution {
public:
vector<double> dicesProbability(int n) {
vector<double> dp(6, 1.0 / 6.0);
for (int i = 2; i <= n; i++) {
vector<double> tempDp(5 * i + 1, 0); //这里的 5 * i + 1 是因为n个骰子,值范围为[n, 6n],总数量就为 5 * n + 1
for (int j = 0; j < dp.size(); j++) {
for (int k = 0; k < 6; k++) {
tempDp[j + k] += dp[j] / 6.0;
}
}
dp = tempDp;
}
return dp;
}
};
第n个骰子的结果有5n+1种,其递推公式为:

将其代码化就行。
剑指 Offer 61. 扑克牌中的顺子
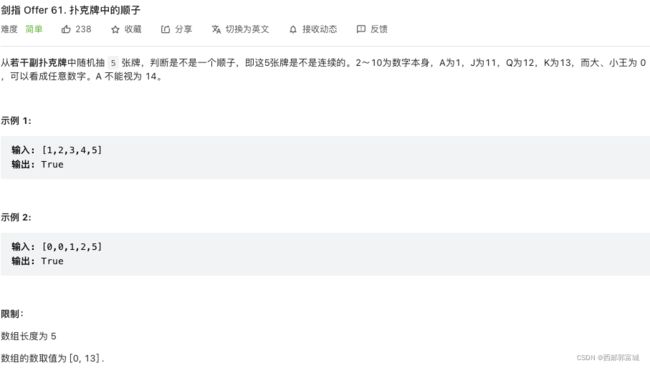
class Solution {
public:
bool isStraight(vector<int>& nums) {
int zeroNum = 0;
sort(nums.begin(), nums.end());
for (int i = 0; i < nums.size() - 1; i++) {
if (!nums[i]) { //计算癞子
zeroNum++;
continue;
}
if (nums[i] == nums[i + 1]) { //除0外相邻它就不可能是顺子
return 0;
} else { //计算相邻两数之间应该补几个癞子(即0)
zeroNum -= nums[i + 1] - nums[i] - 1;
}
}
return zeroNum >= 0 ? 1 : 0; //剩余癞子数大于等于零,他就是顺子
}
};
看上边说的就行。
剑指 Offer 62. 圆圈中最后剩下的数字
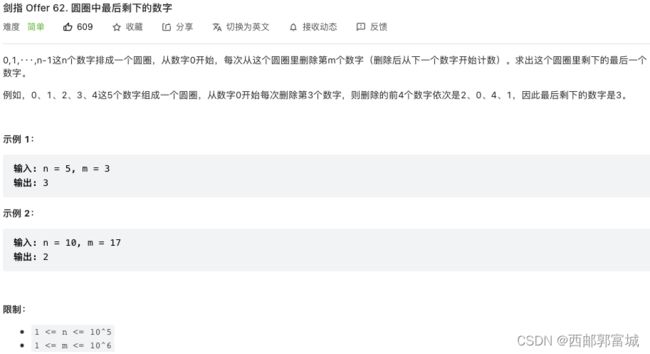
class Solution {
private:
int fun(int n, int m) {
if (n == 1) {
return 0;
}
int x = fun(n - 1, m);
return (m + x) % n;
}
public:
int lastRemaining(int n, int m) {
return fun(n, m);
}
};
我就只能想到模拟法了,还得看k神的,动态规划,吊太,每一次要删除的就是上次删除的位置加上m,避免大于n,最后还会%n,f(n) = (f(n - 1) + t) % n。


剑指 Offer 63. 股票的最大利润

class Solution {
public:
int maxProfit(vector<int>& prices) {
if (prices.size() == 0 || prices.size() == 1) {
return 0;
}
int money = 0, min = 0;
for (int i = 1; i < prices.size(); i++) {
if (prices[i] < prices[min]) {
min = i;
continue;
}
if (prices[i] - prices[min] > money) {
money = prices[i] - prices[min];
}
}
return money;
}
};
定义一个变量money用来存储最大的利益,再定义一个标识min,用来指向之前的最小数,每次都进行相减运算,比money大就表示利润高,就记录下来,如果遇到比指点min还小的,也记录下来,重复上述操作,直到数组遍历完。
剑指 Offer 64. 求1+2+…+n

//方法一:
class Solution {
public:
int sumNums(int n) {
int sum = n;
n && (sum += sumNums(n - 1));
return sum;
}
};
//方法二:
class Solution {
public:
int sumNums(int n) {
bool a[n][n + 1];
return sizeof(a) >> 1;
}
};
//方法三:
class Solution {
public:
int sumNums(int n) {
int ans = 0, A = n, B = n + 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
return ans >> 1;
}
};
方法一:使用&&运算作为if的替代品,递归作为for的替代品。
方法二:这是我看一个老哥的评论看到的,秀的我头皮发麻,你定义的数组大小就相当于实现了n * (n + 1),接下来我们使用>>位的右移运算完成/ 2的效果,这就是n (n + 1) / 2了。
方法三:快速乘,
剑指 Offer 65. 不用加减乘除做加法

class Solution {
public:
int add(int a, int b) {
while (b) { //应进位的每位上都为0时结束
int carry = a & b; // 计算 每位是否有进位,若该位有那么该位就是1
a = a ^ b; // 计算 本位,即剔除要进位之后的位
b = (unsigned)carry << 1; // 存储 相应位上的进位 后序的数直接加上进位就可
}
return a;
}
};
//记住口诀: 异或保留,与进位, 与为空时就返回
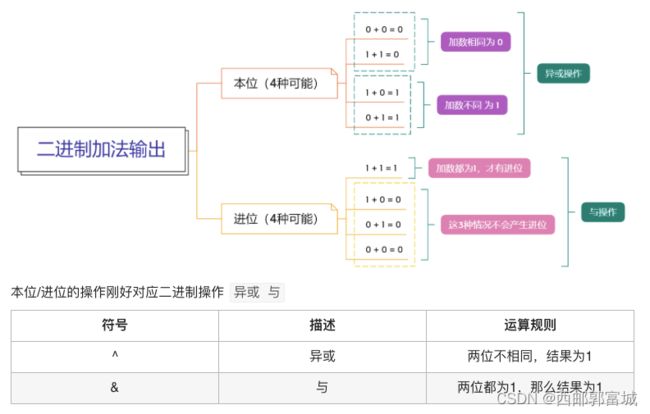
c:判断a和b进行&运算后每一位是否有进位,若该位有进位,那么该位就为1。
a:计算本位,即a和b进行^运算后剔除掉二进制数中相同的位置为0,方便后序与进位再做运算。
b:其实b才是真正的进位,c只是判断是否存在进位,知道哪一位存在进位之后将其进行<<运算,即二进制数中每位左移一位,计算本位a再加上这个b不就是最终的数了,但是要考虑进位之后还有进位的问题,所以使用了while循环,其结束的条件就是没有真正的进位b就结束了,因为没有进位那么就直接操作就行了。
剑指 Offer 66. 构建乘积数组
//方法一:
class Solution {
public:
vector<int> constructArr(vector<int>& a) {
vector<int> myVector(a.size(), 1);
int cur = 1;
for (int i = 0; i < a.size(); i++) { //从左往右累乘(不包括自己)
//新数组的第i位记录的是i位置前所有数的乘积
myVector[i] = cur;
//这里的cur记录的是从0位置一直到i位置之前的所有数的乘积
cur *= a[i];
}
cur = 1;
for (int i = a.size() - 1; i >= 0; i--) { //从右往左累乘(不包括自己)
//因为之前已经记录过i位置前所有数的乘积,这里再乘i位置之后的所有数的乘积,就成了最终的结果
myVector[i] *= cur;
//这里的cur记录的是从数组结尾位置一直到i位置之后的所有数的乘积
cur *= a[i];
}
return myVector;
}
};
//关键就在于要使用一个临时变量存储之前和之后的所有数的乘积
方法一:题解如注释所示。
剑指 Offer 67. 把字符串转换成整数
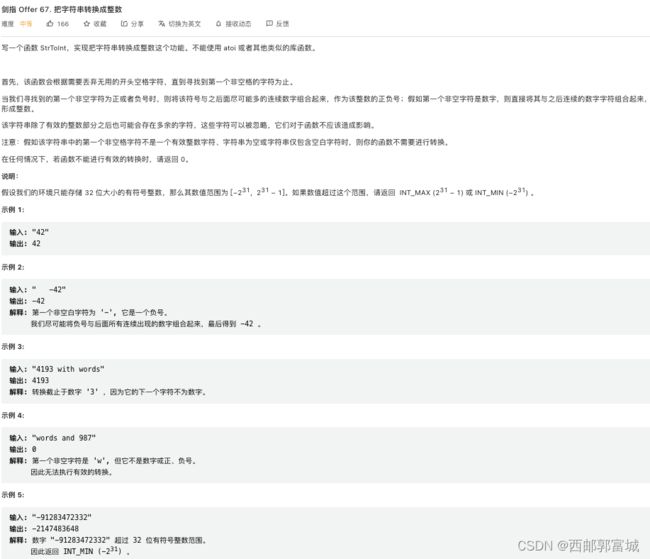
class Solution {
public:
int strToInt(string str) {
string tmp;
unsigned int digit = 0;
int flag = 0; //是否遇到一次符号或者数字
int sig = 1; //符号
for (auto x : str) { //先提取字符串
if (x == ' ') {
if (flag) break; //在数字后面有空格则跳出
continue;
}
if ((x < '0' || x > '9') && (x != '-' && x != '+')) {
break;
}
if (x == '-' || x == '+') {
if (flag) break; //已经遇到过数字或符号,再次遇到符号就跳出
if (x == '-') {
sig = -1;
}
flag = 1;
continue; //符号不写进tmp
}
flag = 1;
tmp += x;
}
int i = 0;
for (i = 0; i < tmp.size(); ++i) {
if (tmp[i] != '0') break;
}
tmp = tmp.substr(i, tmp.size() - i);
if (tmp.size() == 0) return 0;
if (tmp.size() > 10) {
if (sig == 1) return INT_MAX;
if (sig == -1) return INT_MIN;
}
if (tmp.size() == 10) {
if (sig == 1 && tmp >= "2147483647") {
return INT_MAX;
}
if (sig == -1 && tmp >= "2147483648") {
return INT_MIN;
}
}
for (int i = 0; i < tmp.size(); ++i) {
digit = digit * 10 + tmp[i] - '0';
}
return sig * digit;
}
};
哎,真无聊,这种题。

剑指 Offer 68 - I. 二叉搜索树的最近公共祖先

/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
//仔细看的话,不难看出这个数是一个经典的二叉树,左<根,根>右
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
TreeNode *min = p->val > q->val ? q : p; //存储两个节点值大的节点
TreeNode *max = p->val > q->val ? p : q; //存储两个节点值小的节点
if (root->val > max->val) { //说明该root节点的值较大,要向值小的方向遍历
return lowestCommonAncestor(root->left, p, q);
} else if (root->val < min->val) { //说明该root节点的值较小,要向值大的方向遍历
return lowestCommonAncestor(root->right, p, q);
} else {
return root;
}
}
};
这是一个经典的二叉树,左<根,根>右,所以我们没有必要访问每一个节点,我们根据其root节点值进行判断,如果root大于其中节点的最大值,那么就递归左子树,因为左子树小,如果root小于其中节点的最小值,那么就递归右子树,因为右子树大,如果root节点的值夹在两个值的中间或者等于其中之一,那么就说明这个节点就是其最近的公共祖先,返回就行了。
剑指 Offer 68 - II. 二叉树的最近公共祖先

/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (!root || root == p || root == q) { //遍历完或者找到相同的就返回
return root;
}
TreeNode *left = lowestCommonAncestor(root->left, p, q); //寻找左边,返回第一个找到的节点
TreeNode *right = lowestCommonAncestor(root->right, p, q); //寻找右边,返回第一个站到的节点
if (!left) { //左边为空,说明左边没有相等的节点,右边第一个找到的节点就是其祖先
return right;
}
if (!right) { //右边为空,说明右边没有相等的节点,左边第一个找到的节点就是其祖先
return left;
}
return root; //每一边都有相同的节点,就说明该root节点就是其祖先
}
};
我的评价是,没咋做过这种题,思路太少了,没有经验。
从根节点开始,在其左右子树中分别找相等的节点,找到就返回,如果找到的left为空,就说明左边没有相等的节点,那么返回右边的第一个相等的节点就是其最近公共祖先,同理,如果找到的right为空,就说明右边没有相等的节点,那么返回左边的第一个相等的节点就是其最近公共祖先,如果两种情况都存在的话,就说明该节点的左右子树中都有相等节点,那么该root节点肯定就是其最近公共祖先。