深度学习实战21(进阶版)-AI实体百科搜索,任何名词都可搜索到的百科全书
大家好,我是微学AI,今天给大家带来一个AI实体百科搜索的有趣项目。
AI实体百科搜索功能可以让用户通过输入实体名称来搜索相关的信息,并将这些信息以可视化方式呈现出来。构建这个功能可以帮助用户快速地获取与特定实体相关的信息。在这个功能中,用户可以输入一个实体的名称,比如一个人、一个地方或一件事情等等,然后系统将会返回包括该实体的详细信息在内的相关结果,类似与本地部署一个百度百科了。

一、AI实体百科搜索功能
以下是该功能的具体介绍:
实体搜索:用户可以通过输入实体的名称来搜索相关的信息。例如,在搜索框中输入“人工智能”,系统就会返回与人工智能相关的信息。
属性值呈现:搜索结果会显示相关实体的基本属性和属性值,例如人工智能的名称、描述、简称、标签等。
可视化展示:除了基本属性和属性值外,AI实体百科搜索功能还可以以表格等形式进行可视化呈现,使用户更直观地了解实体的相关信息。
二、实体百科输入
1.例如输入:人工智能,结果如下:

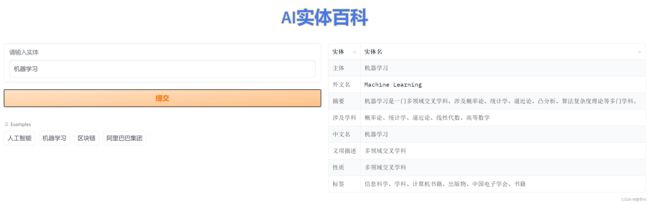
2.例如输入:机器学习,结果如下:
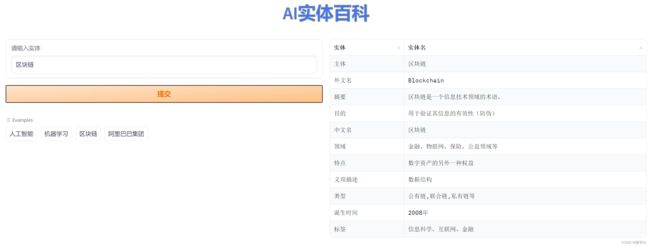
3.例如输入:区块链,结果如下:
三、代码实现
接下来就讲一下如何代码实现以上的功能点,首先是利用gradio框架搭建可视化的网页平台,这是主页的app_entity.pyd代码:
# -*- coding: utf-8 -*-
import gradio as gr
from el import EntityLinker
EL_MODEL = {
'embedding': 'damo/nlp_bert_entity-embedding_chinese-base',
'matching': 'damo/nlp_bert_entity-matching_chinese-base'
}
examples = [
'人工智能',
'机器学习',
'区块链',
'阿里巴巴集团',
]
class App:
def __init__(self, index_path, kb_path):
self.prepare_kb(index_path, kb_path)
self.linker = EntityLinker(
embedding_model_id=EL_MODEL['embedding'],
matching_model_id=EL_MODEL['matching'],
index_path=index_path,
kb_path=kb_path
)
def prepare_kb(self, index_path, kb_path):
def download_file(url, save_path):
import requests
r = requests.get(url)
with open(save_path, 'wb') as f:
f.write(r.content)
def run(self, text):
ner_result = {'text': text, 'entities': [{'word': text, 'entity': text, 'start': 2, 'end': 5}]}
#el_result = {}
for e in ner_result['entities']:
el_result = self.linker.link(
text, e['word'], e['start'], e['end']
)
return el_result
if __name__ == '__main__':
gr.close_all()
app = App(index_path='cand.index', kb_path='kb.json')
title = "AI实体百科"
with gr.Blocks(css='#ner-hint {padding: 5px 12px; color: #b3b3b3!important; font-size: .855rem} '
'#el-result .text-green-500 {color: #624aff}') as demo:
gr.HTML('
')
gr.HTML(
f'{title}
')
with gr.Row():
with gr.Column():
text_input = gr.Textbox(label='请输入实体')
submit_btn = gr.Button("提交", variant="primary")
gr_examples = gr.Examples(examples=examples, inputs=text_input)
with gr.Column():
el_output = gr.Dataframe(
headers=["实体", "实体名称"],
col_count=(2, "fixed")
)
submit_btn.click(fn=app.run, inputs=[text_input], outputs=[el_output])
demo.launch(show_error=True)接下来需要引入文件el.py ,代码如下:
import json
from typing import Any, Dict, List, Union
import faiss
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from tqdm import tqdm
import pandas as pd
class EntityLinker:
ENTITY_START_MARKER = '[ENT_S]'
ENTITY_END_MARKER = '[ENT_E]'
def __init__(self,
embedding_model_id: str,
matching_model_id: str,
index_path: str,
kb_path: str,
first_stage_topk: int = 50,
second_stage_topk: int = 1):
self.embedding_pipeline = pipeline(task=Tasks.sentence_embedding, model=embedding_model_id, model_revision='v1.0.0')
self.matching_pipeline = pipeline(task=Tasks.text_ranking, model=matching_model_id, model_revision='v1.0.0')
self.index = faiss.read_index(index_path)
self.kb = self.load_kb(kb_path)
self.null_id = len(self.kb)
self.first_stage_topk = first_stage_topk
self.second_stage_topk = second_stage_topk
@staticmethod
def load_kb(kb_path: str) -> List[Dict[str, Any]]:
kb = []
with open(kb_path, 'r',encoding='utf-8') as f:
#data = f.readline()
for line in tqdm(f):
kb.append(json.loads(line))
print(len(kb))
return kb
def get_kb_by_id(self, kb_id: int, fmt: str) -> Union[str, Dict[str, str]]:
if fmt == 'str':
if kb_id == self.null_id:
return 'no link; NULL'
data = self.kb[kb_id]
ret = '; '.join([
data['subject'],
'类型:'+data['type'],
'别名: '+', '.join(data['alias']),
'三元组: '+' $ '.join([' # '.join([data['subject'], x['predicate'], x['object']]) for x in data['data']])
])
elif fmt == 'dict':
if kb_id == self.null_id:
return {}
data = self.kb[kb_id]
ret = {
'主体': data['subject'],
**dict([(x['predicate'], x['object']) for x in data['data']])
}
else:
raise ValueError(f'Not supported format: {fmt}')
return ret
def link(self, text: str, mention: str, start: int, end: int) -> List[Dict[str, Any]]:
marked_text = text[:start] + self.ENTITY_START_MARKER + mention + self.ENTITY_END_MARKER + text[end:]
mention_emb = self.embedding_pipeline({'source_sentence': [marked_text], 'sentences_to_compare': []})['text_embedding']
recalled_kb_ids = list(self.index.search(mention_emb, self.first_stage_topk)[1][0])
if self.null_id not in recalled_kb_ids:
recalled_kb_ids.append(self.null_id)
kb_candidates = [self.get_kb_by_id(kb_id, 'str') for kb_id in recalled_kb_ids]
rank_scores = self.matching_pipeline({'source_sentence': [marked_text], 'sentences_to_compare': kb_candidates})['scores']
rank_scores[recalled_kb_ids.index(self.null_id)] /= 10 # manully modify threshold
ranked_idx = sorted(range(len(rank_scores)), key=lambda i: rank_scores[i], reverse=True)
final_result = [self.get_kb_by_id(recalled_kb_ids[idx], 'dict') for idx in ranked_idx[:self.second_stage_topk]]
datafram =[]
for key in final_result[0].keys():
datafr = [key, final_result[0][key]]
datafram.append(datafr)
datas = pd.DataFrame(datafram, columns=["实体", "实体名"])
#print(datafram)
return datas
if __name__ == '__main__':
pass同时程序需要两个文件,一个是索引文件cand.index,一个是kb.json文件,这两个文件可以私信发给你们,或者链接获取:链接:https://pan.baidu.com/s/1gIPVhVl1tH5gf1-d93wgXQ?pwd=y5su
提取码:y5su。
需要代码辅导,接单,合作的可私信。
往期作品:
深度学习实战项目
1.深度学习实战1-(keras框架)企业数据分析与预测
2.深度学习实战2-(keras框架)企业信用评级与预测
3.深度学习实战3-文本卷积神经网络(TextCNN)新闻文本分类
4.深度学习实战4-卷积神经网络(DenseNet)数学图形识别+题目模式识别
5.深度学习实战5-卷积神经网络(CNN)中文OCR识别项目
6.深度学习实战6-卷积神经网络(Pytorch)+聚类分析实现空气质量与天气预测
7.深度学习实战7-电商产品评论的情感分析
8.深度学习实战8-生活照片转化漫画照片应用
9.深度学习实战9-文本生成图像-本地电脑实现text2img
10.深度学习实战10-数学公式识别-将图片转换为Latex(img2Latex)
11.深度学习实战11(进阶版)-BERT模型的微调应用-文本分类案例
12.深度学习实战12(进阶版)-利用Dewarp实现文本扭曲矫正
13.深度学习实战13(进阶版)-文本纠错功能,经常写错别字的小伙伴的福星
14.深度学习实战14(进阶版)-手写文字OCR识别,手写笔记也可以识别了
15.深度学习实战15(进阶版)-让机器进行阅读理解+你可以变成出题者提问
16.深度学习实战16(进阶版)-虚拟截图识别文字-可以做纸质合同和表格识别
17.深度学习实战17(进阶版)-智能辅助编辑平台系统的搭建与开发案例
18.深度学习实战18(进阶版)-NLP的15项任务大融合系统,可实现市面上你能想到的NLP任务
19.深度学习实战19(进阶版)-ChatGPT的本地实现部署测试,自己的平台就可以实现ChatGPT
...(待更新)