分享:FactorJoin,一种新的连接查询基数估计框架
欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/
本文来自OceanBase社区分享,仅限交流探讨。原作者巩李成,东北大学计算机科学与工程学院在读硕士生,课题方向为数据库查询优化,致力于应用 AI 技术改进传统基数估计器,令数据库选择最优查询计划。
原文:《FactorJoin: A New Cardinality Estimation Framework for Join Queries》,发表于SIGMOD 2023。
基数估计是查询优化中最为重要和最具挑战性的问题。传统方法和学习型方法在估计多表连接查询的基数时都没有令人满意的表现。它们或依赖于简单的假设导致无效的估计;或构建过大的模型来理解多表的联合分布,从而使得模型规划时间较长并缺乏泛化能力。
本文提出了一个新的多表连接基数估计方法——FactorJoin。FactorJoin将传统的连接直方图[1]与学习型方法相结合以捕获表间的关联性进而进行基数估计。具体地说,离线训练时,FactorJoin先建立单表估计模型以学习单表的分布。当处理连接查询时,FactorJoin首先依据已学习到的分布将查询建模为因子图[2](Factor Graph),而后使用变量消除[3](Variable Elimination,VE)算法进行推理。因只需单表的统计信息即可估计出多表连接的基数,FactorJoin在查询的端到端处理时间优于其它学习型方法[4,5,6]的情况下,模型大小、训练及更新时间比它们低了一至两个量级。
多表基数估计方法
给定A,B两表上的查询Q:
SELECT * FROM A, B WHERE Id1 = Id2 AND A1>0 AND B1>0
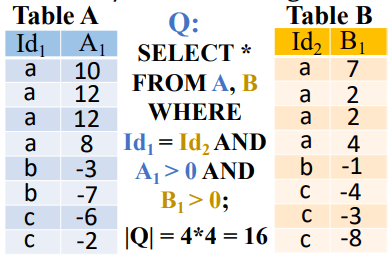
图1 两表连接示例
分别介绍下面四种估计方法。
Selinger 模型
Selinger 模型[7]在估计时作了两点假设:属性独立假设以及连接键均匀分布假设。首先依据属性独立假设计算两属性的联合概率密度PA(A1 > 0) * PB(B1 > 0);而后使用连接键均匀分布假设估计两表连接的大小:|A ⋈ B| = |A| * |B| / max{num uniques in A.Id1, num uniques in B.Id2}。

图2 Selinger模型估计示例
图2给出了Selinger模型以图1所示数据进行估计的过程:
PA(A1 > 0) * PB(B1 > 0) = 1/2 * 1/2,|A ⋈ B| = 8 * 8 / 3 = 21
|Q| = PA(A1 > 0) * PB(B1 > 0) * |A ⋈ B|
= 1/2 * 1/2 * 8 * 8 / 3
= 5
该查询的真实基数为4 * 4 = 16,可以看到Selinger模型因其所作的两点假设导致估计结果存在较大的误差。
连接直方图
连接直方图在估计时依旧采用了属性独立假设与连接键均匀分布假设。与Selinger 模型不同的是,在估计两表连接大小的时候对连接键进行了划分。如图3所示,对应连接键中的相同值被划分到具有相同下标的桶中(如值a被划分到桶1,值b和c被划分到桶2)。在计算两表连接大小时,直接将该连接键上所有桶中的对应元素的连接数目加和即可。
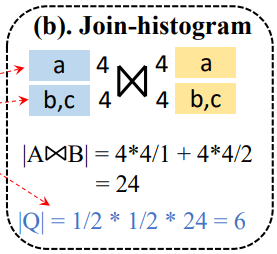
图3 连接直方图估计示例
如图2所示,|A⋈B| = 4 * 4 / 1 + 4 * 4 / 2 = 24,
|Q| = 1/2 * 1/2 * 24 = 6
可以看到,连接直方图的估计误差同样很大,但因其在估计两表连接大小时在连接键上划分了一些桶,因而不需要遍历所有元素,进而使得估计时间大大减少。
学习型数据驱动的方法
学习型基数估计方法依据使用的数据类型可分为两类:查询驱动的方法与数据驱动的方法。其中,查询驱动的方法在处理多表基数估计时仅将连接类型作为特征之一,并同其它特征一同送入网络中进行训练以构造出从查询到基数的映射函数。这种方法并未对多表基数估计进行特殊处理,因此不多赘述。
数据驱动的方法在处理多表基数估计时大多会学习多表的联合分布。如DeepDB、FLAT等会将关联性较强的两表通过全外连接的方式进行结合并学习全外连接表的分布情况。而后依据学习到的联合分布进行选择度的估计。

图4 数据驱动的方法示意图
图4给出了数据驱动的方法的示例,表A和表B通过连接键Id1与Id2连接后被送入模型以学习其分布。最后得到的结果与真值极为接近。
本文提出的方法
因数据驱动的方法须学习多表的联合分布,所以模型较大、训练及更新时间较长,所以作者想在仅知道单表统计信息的情况下估计出多表查询的基数。因此,作者采用了连接直方图的思想,即分别统计出参与连接的两表满足对应谓词的元组分布情况,并在连接键上进行分桶,而后将所有桶中对应值的连接数目加和即可。该方法的估计过程如图5所示。为了提高效率,作者将其与概率图模型相结合,具体情况如后文所述。

图5 本文方法的示意图
多表连接基数估计的新框架
两表连接基数估计示例
如图6所示,查询Q需要对表A和表B在连接键A.id与B.Aid上进行连接。连接直方图这类方法在估计两表的基数时会分别筛选出符合两表谓词的元组A|Q(A)与B|Q(B),而后在筛选出的元组上进行相应的连接操作。可算出最终的连接结果为:8 * 6 + 4 * 5 + 3 * 5 = 83。
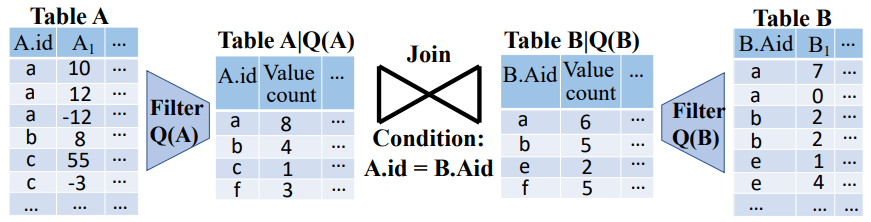
图6 两表估计示意图
这一步骤表示成公式则如公式(1)所示。其中,PA(A.id = v | Q(A))表示值v在表A中满足谓词Q(A)的元组中的分布情况。

多表估计示例
给定查询Q2:
SELECT * FROM A, B, C, D
WHERE A.id = B.Aid AND A.id2 = C.Aid2
AND C.id = B.Cid AND C.id = D.Cid
AND Q2(A) AND Q2(B) AND Q2(C) AND Q2(D)
如图7所示,在处理查询Q2时,首先将查询涉及到的表表示成图6(ii)的形式。其中,矩形阴影部分表示查询涉及到的表,椭圆代表涉及到的连接键,实线表示对应的连接关系。同种颜色实现连接起来的各连接键被称为等价键簇,后文在优化算法时会用到这个概念。

图7 四表基数估计示意图
同两表估计的思想一般,逐个对每个等价键簇中的值在各表中作等值连接。该计算过程表示成公式则如公式2所示。其时间复杂度为O(n3)。为了降低复杂度,作者将查询表示成图6(iii)所示的因子图。其中,变量节点V1表示等价键簇1;因子节点表示表,该节点中存有表中元素的分布信息PA(V1, V2 | Q2(A)) * |Q2(A)|;实线表示表中该查询涉及到该表在对应连接键上的连接操作。

因子图的推理是概率图模型中经过充分研究的问题,常用的推理方法有变量消除和信念传播[8](belief propagation)这两种方法。本文采用了变量消除这种方法,此时的时间复杂度为O(N * |D|max(|JK|))),其中,N表示等价键簇的数量,|D|表示所有连接键中最大的域的长度,max(|JK|)表示单表拥有的最大连接键的数量。在图7中,max(|JK|)的值为2。在现实世界的数据库中,这种复杂度还是不可接受的,因为|D|可能达到百万级别,而max(|JK|)可能比4还要大,因此是不可接受的。为了降低复杂度,作者对这两个点分别进行了优化,具体过程如下文所述。
整体的工作流程
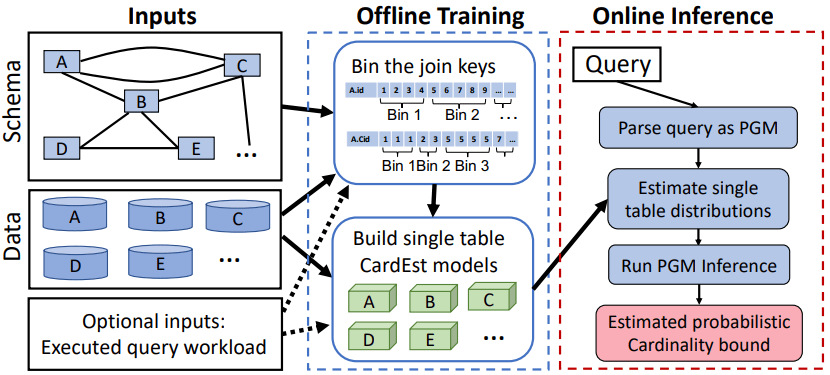
图8 FactorJoin的工作流
整体的工作流程如图8所示。在离线训练时,FactorJoin先分别在各表上建立单表估计模型并依据数据模型对所有连接键进行分桶并统计相应信息。在线推理时,FactorJoin先将查询表示成因子图,而后分别在单表上进行估计,最后使用变量消除算法对各表的连接结果进行估计。值得一提的是,FactorJoin估计的是查询的基数上限,而非具体的基数值。这是作者降本提效的一种手段,详情如下文所述。
提升效率的两种方法
上文提到,使用变量消除算法对因子图进行推理的复杂度为O(N * |D|max(|JK|))。其中影响较大的有最大的属性域的长度|D|以及单表拥有的最多的连接键的数量max(|JK|)。作者从这两个方面入手,分别进行了优化,使复杂度进一步降低。
概率上限算法
在以连接直方图估计多表连接的大小时,需要对连接键进行遍历以将两表连接键上对应的值进行连接。在现实的数据库中,连接键的域很大,能达到百万级别。为了提升效率,作者借鉴了基于概率上限方法的思想,即估计出基数的上限而非具体的值。
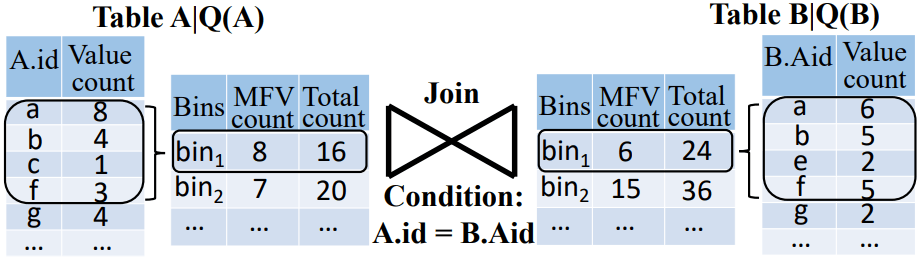
图9 使用分桶策略的量表估计示例
图9给出了两表估计的例子。如图,分别在表A、表B中筛选出符合相应谓词的元组后,统计连接键上的值分布情况并在连接键上划分桶,使得两表连接键上相同的值落在同一个下标的桶中。而后分别估计每个桶的连接上限,即先找出桶中的最频繁值(most frequent value, MFV)及桶包含的元组数目。如在表A的桶1中,值a出现的次数最多,为8次;桶2中MFV出现的次数为6次,则两桶中同一个值作等值连接最多产生48个连接结果。表A的桶1中总元组数目为16,则其桶1中最多包含两个MFV;对应地,表B的桶1中最多包含4个MFV。因此可以估计出两桶对应值作等值连接的数目上限为:min(2, 4) * 8 * 6 = 96。对比真值为8 * 6 + 4 * 5 + 3 * 5 = 83。表示成公式则如公式3所示。

在连接键上进行分桶时,需要考虑两个问题:划分多少个桶以及把哪些值放入同一个桶内。作者分别对这两个问题进行了处理。
基于工作流决定桶的数量k
桶的数量k对FactorJoin的性能有显著影响:较少的桶将连接键域中更多不同的值聚合到每一个桶,因此模型的准确性较低但效率更高。作者提出了一种基于工作流分桶的方法,在给定桶的数量上限K = ∑ki的情况下,依据等价键簇在工作流中出现的次数多少,对每个不同的等价键簇分配不同的桶数量;出现的次数越多,则分配的桶的数目越多。
分桶策略
传统的分桶策略有等宽划分和等高划分,但这两种方法在极端情况下会出现较大的误差,且等价键簇中所有的连接键共用一个分桶结果,所以为了降低每个连接键上桶的方差,作者提出了一种贪婪的分桶策略(greedy binning selection algorithm , GBSA)。

GBSA算法如算法2所述。GBSA首先在每个等价键簇中生成次优的分桶结果(line 1),而后对每个等价键簇执行算法2所示的过程(line 2-14)。以等价键簇中连接键域的长度递减的顺序进行排序(line 3)。用一半数量的桶降低第一个连接键的方差(line 4)。在单属性上获得具有最小方差的划分结果时,可将属性排序后以等深策略进行划分。而后,GBSA将在当前连接键上的分桶结果逐个应用到它后面的连接键中,计算各个桶的方差并以递减的方式排序(line 6-9),用剩余的可分配桶的数目的一半数量优化当前的桶方差,即将相应的桶一分为二(line 10-12)。
捕获属性间的依赖关系
在使用因子图计算多表的基数时,时间复杂度为O(N * |D|max(|JK|)),|D|为所有连接键中最长的域的长度,已通过概率上限算法进行优化;指数项max(|JK|)表示单表拥有的最多连接键的数量,在IMDB数据集中,该值能大到4,所以作者对这一项进行优化。
由于因子图需要知道单表中连接键的联合分布,单表的连接键数量就决定着该部分推理的复杂度。如对拥有六个属性的表A{id1, id2, id3, id4, attr1, attr2}(idi表示各个连接键),因子图需要估计PA(id1, id2, id3, id4 | Q(A))。即使已经采用概率上限算法,该部分时空复杂度也达到了k2。然而,可用贝叶斯网络构建各连接键的依赖关系并使用变量消除算法进行推理。此时,仅需进行如下形式的计算:
PA(id1 | Q(A)) * PA(id2 | Q(A)) * PA(id3 | id1) * PA(id4 | id3)
这种形式效率更高因为它最多只涉及二维分布上的乘积。时空复杂度降低为了O(N * k2)。
子计划估计结果的重用
由于优化器在选择查询计划时,可能会估计多达上千个计划的代价。但这些计划可能存在一些相同的子计划,所以为了进一步提升效率,作者将各子计划的结果保留用作其余部分的估计。
实验
数据集
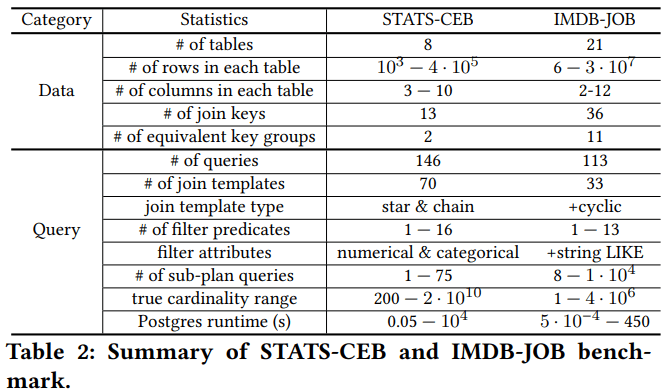
Baselines
PostgresSQL[10]:使用基于直方图的方法
JoinHist[1]:传统的基于连接直方图的方法
WJSample[11]:在多表中使用基于随机游走的wander join方法生成样本
MSCN[4]、BayesCard[9]、DeepDB[5]、FLAT[6]:最具代表性的学习型方法
PessEst[12]:SOTA的基于上限的方法,利用随机哈希和数据画像来使上限尽量接近真值
U-Block[13]:使用 top-k 统计数据来估计基数界限
总体表现
表3表4分别给出了众模型在STATS-CEB与IMDB-JOB上的端到端时间的实验结果。在STATS数据集上,多数方法的端到端时间优于Postgres,FactorJoin达到最优的效果;值得注意的是,DeepDB、FLAT的端到端时间虽然略长于FactorJoin,但二者的计划时间比FactorJoin高了一个量级,应是在处理CEB包含的查询时会产生多种执行计划,DeepDB与FLAT需要把每种计划都推理一遍,因此比较耗时。
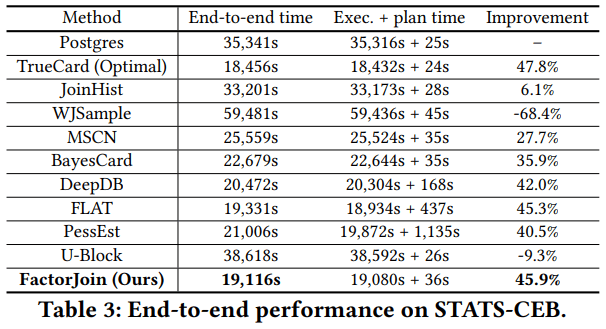
表4给出了在IMDB数据集上的端到端时间的实验结果。可以看到,除了MSCN和FactorJoin外其它方法的效果均没有Postgres的好。因为相较于STATS数据集,IMDB的体量更大,IMDB拥有更多的表、更大的属性域以及更复杂的连接关系。且IMDB含有较多的复杂字符类数据,而BayesCard、DeepDB以及FLAT仅支持可枚举的字符型数据,所以并未进行相应的实验。值得一提的是,FactorJoin的端到端时间在STATS数据集上与TrueCard相近,但在IMDB数据集上则与之相差较远。这是因为IMDB拥有更复杂的连接,而FactorJoin在连接键上进行上限估计,当连接键增多时错误也会累积。MSCN相较于Postgres也有提升,因为查询驱动的方法对数据集的大小不敏感而更依赖于训练所使用的查询的质量。
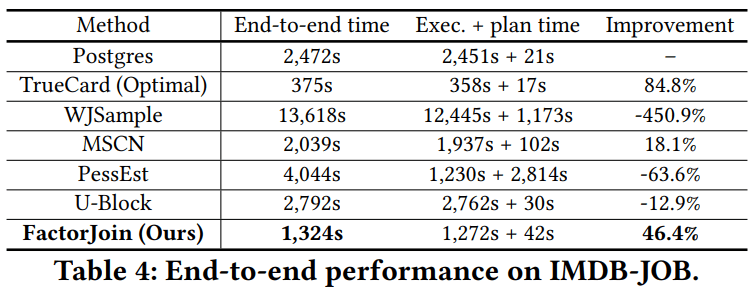
图10给出了多个模型在两个数据集上的端到端时间、模型大小以及训练时间的实验结果。可以看到,FactorJoin在各个实验内容上都达到了最优的效果,且其模型大小与训练时间比DeepDB与FLAT低了两个量级。

图10 在两个数据集上的总体表现
详细分析
图11给出了几个模型在CEB的146个查询上估计的相对误差。可以看到,PessEst 生成精确的上限并且从不低估。 FLAT 使用更大的模型来理解连接模式的分布并产生最准确的估计。FactorJoin 可以为超过 90% 的子计划查询输出基数上限。大多数边际低估都非常接近真实基数。
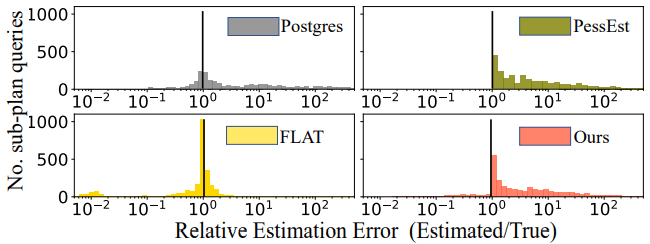
图11 在STATS上的相对误差
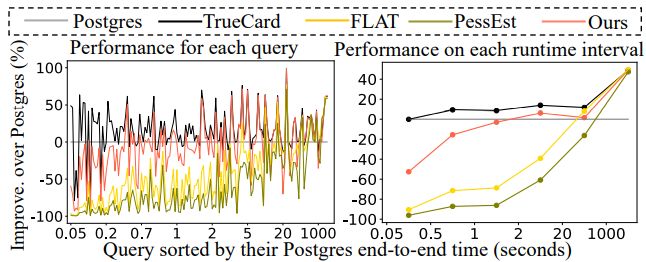
图12 在STATS上单个查询的表现
图12给出了各模型在STATS-CEB上单个查询的表现。可以看到,在时间较短的查询里,多数模型的表现不如Postgres。随着查询的端到端的时间的提升,几种方法的效果开始优于Postgres,因为随着查询的端到端时间的增加,用于计划的时间占比降低,执行时间占比增大,而其余方法相较于Postgres有更高的准确度进而会产生代价更低的计划。
消融实验
图13给出了FactorJoin在不同的k值下的表现。可以看到,随着桶数量的增加,模型估计的端到端时间以及相对误差在逐步降低并逐渐趋于稳定。而单查询的推理时延、训练时间以及模型大小在快速增加。
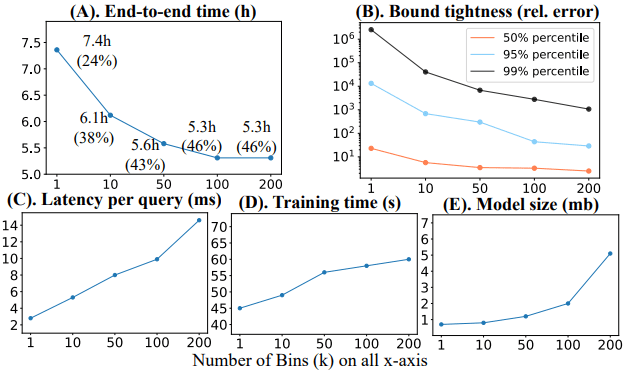
图13 不同桶的数量(k)对模型的影响

表6给出了在使用不同分桶算法的情况下模型的端到端时间。可以看到,等宽划分和等高划分的效果相近,而本文提出的GBSA优于这两种方法。
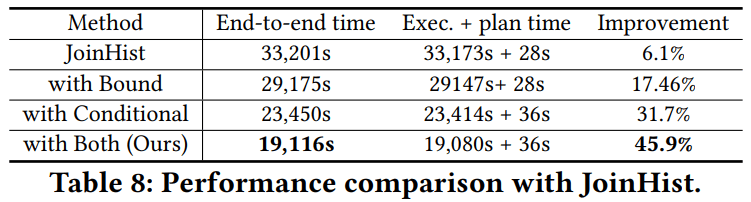
表8给出了使用本文提出的两种方法相较于传统的连接直方图的端到端时间对比。可以看到,本文提出的两种方法都能提升模型的估计效果以使优化器选择更优的执行计划。
总结
本文提出了一种用于连接查询的基数估计框架FactorJoin,该框架将经典的连接直方图与学习型单表基数估计结合成一个因子图。该框架将传统的基数估计问题转化成因子图的推理问题,且只需要知道单表的分布。作者还提出了两种优化算法以提升模型的效率。最终,FactorJoin在查询的端到端时间优于其它SOTA算法的情况下,模型大小、训练及更新时间比DeepDB及FLAT低了两个量级。
参考文献
[1] Alberto Dell’Era. 2007. Join Over Histograms. Available on www. adellera.it/investigations/join_over_histograms (2007).
[2] H-A Loeliger. 2004. An introduction to factor graphs. IEEE Signal Processing Magazine 21, 1 (2004), 28–41.
[3] Daphne Koller and Nir Friedman. 2009. Probabilistic graphical models: principles and techniques. MIT press.
[4] Andreas Kipf, Thomas Kipf, Bernhard Radke, Viktor Leis, Peter Boncz, and Alfons Kemper. 2019. Learned cardinalities: Estimating correlated joins with deep learning. In CIDR.
[5] Benjamin Hilprecht, Andreas Schmidt, Moritz Kulessa, Alejandro Molina, Kristian Kersting, and Carsten Binnig. 2019. DeepDB: learn from data, not from queries! In PVLDB.
[6] Rong Zhu, Ziniu Wu, Yuxing Han, Kai Zeng, Andreas Pfadler, Zhengping Qian, Jingren Zhou, and Bin Cui. 2021. FLAT: Fast, Lightweight and Accurate Method for Cardinality Estimation. VLDB 14, 9 (2021), 1489–1502.
[7] P Griffiths Selinger, Morton M Astrahan, Donald D Chamberlin, Raymond A Lorie, and Thomas G Price. 1979. Access path selection in a relational database management system. In SIGMOD. 23–34.
[8] Frank R Kschischang, Brendan J Frey, and H-A Loeliger. 2001. Factor graphs and the sum-product algorithm. IEEE Transactions on information theory 47, 2 (2001), 498–519.
[9] Ziniu Wu, Amir Shaikhha, Rong Zhu, Kai Zeng, Yuxing Han, and Jingren Zhou. 2020. BayesCard: Revitilizing Bayesian Frameworks for Cardinality Estimation. arXiv e-prints (2020), arXiv–2012.
[10] Postgresql Documentation 12. 2020. Chapter 70.1. Row Estimation Examples. https://www.postgresql.org/docs/current/row-estimation-examples.html (2020).
[11] Feifei Li, Bin Wu, Ke Yi, and Zhuoyue Zhao. 2016. Wander join: Online aggregation via random walks. In SIGMOD. 615–629.
[12] Walter Cai, Magdalena Balazinska, and Dan Suciu. 2019. Pessimistic cardinality estimation: Tighter upper bounds for intermediate join cardinalities. In SIGMOD. 18–35.
[13] Axel Hertzschuch, Claudio Hartmann, Dirk Habich, and Wolfgang Lehner. 2021. Simplicity Done Right for Join Ordering. CIDR (2021).
欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/