【自写信息搜集工具】ThunderSearch开发原理解析
前段时间结合zoomeye的开发文档做了个简易的信息搜集工具ThunderSearch【项目地址 / 博客地址】,这次来讲讲具体的实现原理和开发思路
首先要能看懂开发文档,https://www.zoomeye.org/doc#user,上面介绍了一些api的使用。我们只需要调用我们想要的api就可以获取到想要的数据。
1. 登陆
根据文档,登陆方式分为两种,api-key和账号/密码,我这里使用了账号密码登陆的方式,主要是获取api-key需要登陆到网页比较麻烦。登陆的目的是为了拿到access-token,在后期的api调用过程中需要将其作为请求头发送。我们先来看access-token的获取。
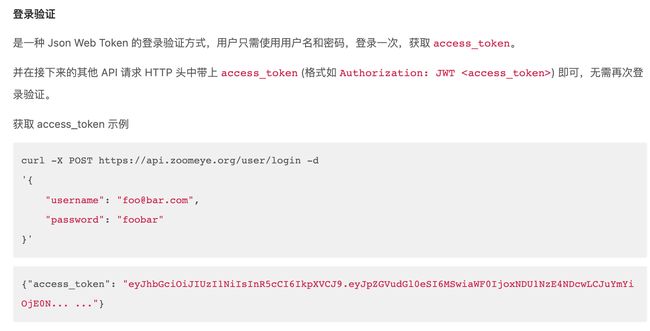
文档中使用curl制造http请求,在python中可以使用requests
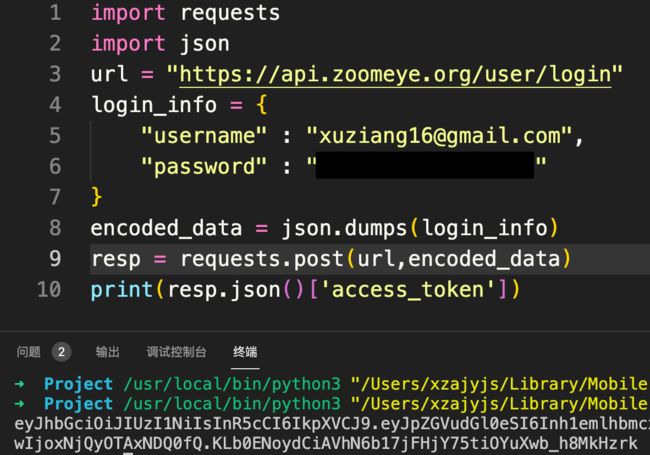
import requests
import json
url = "https://api.zoomeye.org/user/login"
login_info = {
"username" : "xxxxx",
"password" : "xxxxx"
}
encoded_data = json.dumps(login_info)
resp = requests.post(url,encoded_data)
access_token = resp.json()['access_token']
print(access_token)
这里需要注意的是发送的data数据必须是json格式,因此需要把字典格式的info进行一个转化
再通过
resp.jgon()['access_token']就能拿到token数据了。在这个token前加上
JWT(空格)作为Authorization提交
headers = {
'Authorization':'JWT ' + access_token
}
2.调用api
以主机设备搜索为例

请求的url为https://api.zoomeye.org/host/search,请求方式为GET,四个参数中query(查询语句)为必填项
那么就可以创造如下函数
def host_search(query, page): # 主机设备搜索
url = f'https://api.zoomeye.org/host/search?query={query}&page={page}&sub_type=v4&facets=app,os'
matches = requests.get(url, headers=headers).json()
文档中提供的返回json数据样例如下:(在上面的例子中就是matches)
{ "matches": [ {
"geoinfo": {
"asn": 45261,
"city": {
"names": {
"en": "Brisbane",
"zh-CN": "\u5e03\u91cc\u65af\u73ed"
}
},
"continent": {
"code": "OC",
"names": {
"en": "Oceania",
"zh-CN": "\u5927\u6d0b\u6d32"
}
},
"country": {
"code": "AU",
"names": {
"en": "Australia",
"zh-CN": "\u6fb3\u5927\u5229\u4e9a"
}
},
"location": {
"lat": -27.471,
"lon": 153.0243
}
},
"ip": "192.168.1.1",
"portinfo": {
"app": "",
"banner": "+OK Hello there.\r\n-ERR Invalid command.\r\n\n",
"device": "",
"extrainfo": "",
"hostname": "",
"os": "",
"port": 110,
"service": "",
"version": ""
},
"timestamp": "2016-03-09T16:14:04"
}, ... ...],
"facets": {
},
"total": 28731397
}
按照如下方式就可以拿到数据了
for each in matches['matches']:
ip = each['ip']
port = each['portinfo']['port']
country = each['geoinfo']['country']['names']['en']
os = each['portinfo']['os']
hostname = each['portinfo']['hostname']
3. 图形化
这里主要使用到了tkinter。按照如下通过面向对象的方式就能建立一个基础的GUI界面
from tkinter import *
class Application(Frame):
def __init__(self,master):
super().__init__(master)
self.master=master
self.createWidget()
self.pack()
def createWidget(self):
pass
if __name__=="__main__":
root = Tk()
root.title("TEST")
root.geometry('400x300+200+100')
Application(root)
root.mainloop()
4. 整合
结合多线程并发技术,最终能够实现ThunderSearch这样一个小公举
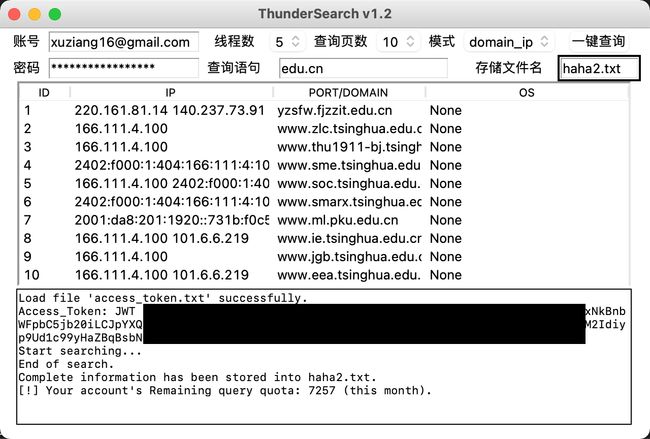
5. 总结
整体难度并不大,主要是GUI库tkinter的使用和读懂api开发文档、结合多线程并发的综合练习。
另外在tkinter的开发中遇到了一个问题,
mainloop事件中的任何一个循环都要等待其结束之后主组件才会进行刷新,刷新前会一直卡住呈现假死状态。查遍S.O.,基本方法有每执行一次循环刷新界面,或者使用master等,但不能很好的解决问题,尤其是在复杂的多线程的多个循环同时执行的情况下就不好用了。我这里是开了一个守护子线程去跑每个模块,这样和组件的
mainloop事件就不冲突了,也能很好的上线程池。但总觉得有些不太好,希望有哪位懂的师傅能指点一下。