图像分类算法:VGG论文解读
图像分类算法:VGG论文解读
前言
其实网上已经有很多很好的解读各种论文的文章了,但是我决定自己也写一写,当然,我的主要目的就是帮助自己梳理、深入理解论文,因为写文章,你必须把你所写的东西表达清楚而正确,我认为这是一种很好的锻炼,当然如果可以帮助到网友,也是很开心的事情。
说明
如果有笔误或者写错误的地方请指出(勿喷),如果你有更好的见解也可以提出,我也会认真学习。
原始论文地址
点击这里,或者复制链接
https://arxiv.org/pdf/1409.1556.pdf
目录结构
文章目录
-
- 图像分类算法:VGG论文解读
-
- 1. 背景简介:
- 2. 文章内容概述:
- 3. 模型架构:
- 4. 连续小卷积核的作用:
- 5. 1*1卷积核的作用:
- 6. 多尺度:
- 7. 卷积层代替全连接层:
- 8. 作者得出的结论:
- 9. 总结:
1. 背景简介:
在2012年AlexNet问世后,人们便开始热衷于研究新的网络结构。2013年的一个改进思路是:在第一个卷积层使用了较小的接受域窗口(卷积核)和较小的步长,因为这样可以对原始图片提取出更多的信息。2014年的一个改进方案是多尺度多次训练。
而基于这些背景以及作者对于网络深度这个因素的兴趣,出现了这篇文章。
解释:多尺度
多尺度,是信息的综合利用。举个例子,一张图片,整体处理为一个尺度,从中裁剪一部分处理就是另外一个尺度。再来个例子,将不同卷积层的输出的特征图利用也是一种多尺度。
2. 文章内容概述:
作者的主要目标是证明深度对准确率的影响,为此,作者固定了除深度外的所有参数,采用3*3小卷积核实现了卷积层,一共推出了六个模型架构,其中16层核19层架构取得了很好的结果,也被称之为VGG16和VGG19。
3. 模型架构:
在原论文中提供了模型架构表格:

对上面表格进行一点点的说明:
- conv3-128含义:
卷积核 3*3*64 - 总共六个模型,其中A和A-LRN是为了对比LRN是否会有作用,C和D是为了验证1*1卷积核的作用
当然,如果你觉得表格不够直观,也有一张VGG16的图片供你欣赏(图来自网络):
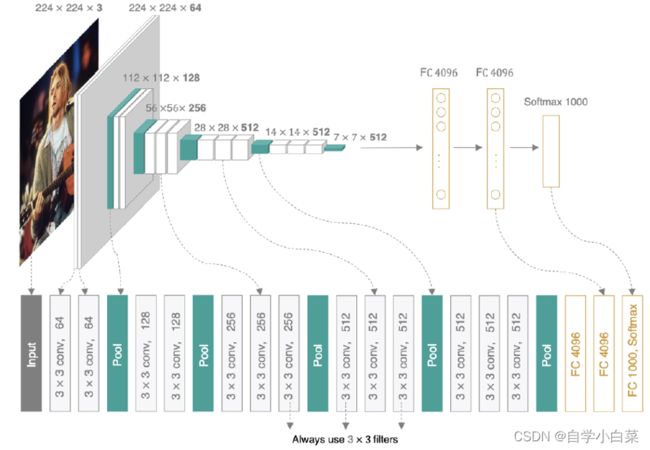
这么清晰的图,架构应该不需要详说,如果你问如何算尺寸,可以参考我关于AlexNet的论文,这篇文章详细推导了尺寸计算。
另外,我觉得一个很重要的点就是,模型参数量大家一定要熟悉,因为我实现AlexNet的时候,可以正常调用GPU,不过实现VGG16时却因为参数量增加而导致GPU内存满了而报错。

4. 连续小卷积核的作用:
观察上面的参数量图,不难发现:随着层数增加,模型参数量并没有增加多少,这是为什么?
此时就不得不提小卷积核的好处了。作者发现,两个3*3卷积核相当于一个5*5卷积核,三个3*3卷积核相当于一个7*7卷积核。这意味着参数量的减小和非线性变换次数的增加,看下图:
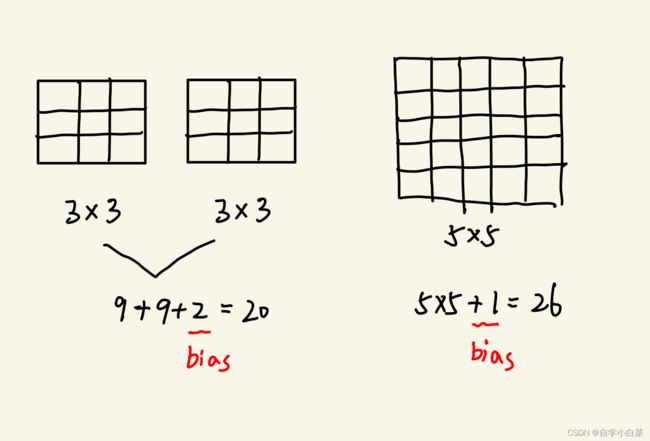
- 参数量减小
假设一个卷积核对应一个bias,那么:
两个3*3卷积核,参数量: 3*3*2+2 = 20
一个5*5卷积核,参数量: 5*5 + 1 = 26
可见,参数量确实减少了
- 非线性变换次数增加:可以防止过拟合并且提取更多的信息
两个3*3卷积核:
对于同样的输入,经历了两次卷积操作
一个5*5卷积核:
对于同样的输入,只经历了一次卷积操作
解释: 两个3*3卷积核相当于一个5*5卷积核
假设输入为m*m,步长为1,padding为0。
那么,两个3*3卷积后:
第一个卷积: (m-3)/1 + 1 = m-2
第二个卷积: (m-2-3)/1 + 1 = m-4
而,经过5*5卷积核后:
(m-5) + 1 = m-4
所以,两者在输出尺寸是相同的,只是最后的输出肯定是不同的,只是大小相同而已。
5. 1*1卷积核的作用:
作者在C模型中引入了1*1卷积核,其发挥的作用为:
- 为决策增加非线性因素
1*1卷积核其实是线性映射(你想,卷积操作用1*1来用,不就是线性操作嘛),但是不要忘记,这个1*1卷积层后会接上ReLU函数,这就增加了非线性因素。
从另外一个角度想,其实也是一种增加深度的手段
- 改变通道数
这个作用是核心作用,可以用于升维或降维,比如我可以写为1*1*64或1*1*256来改变通道数。这个作用后面也被经常使用。
6. 多尺度:
作者实现多尺度的方法是图片裁剪。在原论文中,作者用S表示各向同性缩放的训练图像的最小边(即先将图像同比例缩放至S*H,再从其中裁剪出224*224大小图像),那么:
- 单尺度训练:固定S,作者取了S=256和384两个值进行测试
- 多尺度训练:S为[Smin,Smax]之间的一个随机数
不难猜测,多尺度训练的方式好一些,因为图像中的物体大小是不固定的,那么裁剪的时候肯定是波动了S值比固定的S值好。
7. 卷积层代替全连接层:
作者在测试时,采用了FCN(Full Convolutional Network,全卷积网络),即用卷积层来代替全连接层。
谈及这里,必须得问:为什么AlexNet、VGG都要限制输入图像的大小,前者为227*227,后者为224*224?
这是因为,全连接层的神经元个数是固定的,因此要求最后一个卷积层的输出必须是固定大小的,从而要求输入图像大小必须固定。
那么FCN就可以解除这个限制了,即卷积代替全连接的好处之一就是不限制输入图像大小。
那么,作者如何实现这个想法的呢?首先,我们知道VGG16最后一个卷积层的输出为7*7*512(从上面的VGG16图中得知或者自己计算),而第一个FC层输入为7*7*512,输出为4096,那么我们可以用一个7*7*4096(保证最后输出为4096)的卷积层代替,而后两个FC层用1*1*4096和1*1*1000代替。
见下图,我稍微解释了一下第一个FC层为什么用7*7*4096代替(核心是让输出保持一致,即为1*1*4096):
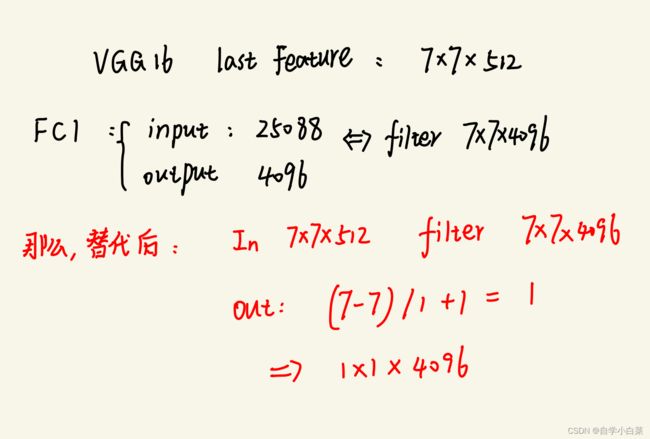
8. 作者得出的结论:
作者尝试了六个模型和不同的训练细节,得出了一些有用的结论:
- LRN没有发挥理想中的作用
- 错误率随深度增加而减小
- 连续小卷积核和1*1卷积核作用很大
- 多尺度训练比单尺度好
- 多模型融合取得的效果更好(就是有点像集成算法)
9. 总结:
站在我这个后辈的角度,我觉得VGG这样的文章是必然会出现的,因为在AlexNet中早已提及了深度的重要性。不过,同样也告诉我,即使有方向,想要实现也是困难的,因为如果不是采取连续小卷积核等手段,想要探索深度重要性也是很困难的。
而,VGG很重要的贡献就是:
- 证明深度的重要性
- 连续小卷积核和1*1卷积核可以发挥更大的作用
- 多尺度的重要性
最后,如果你对实现VGG16感兴趣,可以阅读我的两篇文章,一篇是单纯实现架构VGG16,另外一篇是侧重于使用VGG16:
https://blog.csdn.net/weixin_46676835/article/details/128730174
https://blog.csdn.net/weixin_46676835/article/details/129582927