大数据应用——Hadoop运行模式(伪分布式运行)
4.2 伪分布式运行模式
4.2.1 启动HDFS并运行MapReduce程序
1. 分析
(1)配置集群
(2)启动、测试集群增、删、查没有改(多台机子麻烦)
(3)执行WordCount案例
2. 执行步骤
(1)配置集群
(a)配置:hadoop-env.sh
【路径:/opt/module/hadoop-2.7.1/etc/hadoop】
Linux系统中获取JDK的安装路径:sudo vi ~/.bashrc
[hadoop@hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_162
修改JAVA_HOME 路径:
在export JAVA_HOME={}添加以下路径
export JAVA_HOME=/opt/module/jdk1.8.0_162

(b)配置:core-site.xml
|

(c)配置:hdfs-site.xml
|

(2)启动集群
(a)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
执行命令会产生临时文件cd /opt/module/hadoop-2.7.1/data下删除tmp临时文件即可
[hadoop@hadoop101 hadoop-2.7.1]$ bin/hdfs namenode -format

(b)启动NameNode
[hadoop@hadoop101 hadoop-2.7.1]$sbin/hadoop-daemon.sh start namenode
(c)启动DataNode
[hadoop@hadoop101 hadoop-2.7.1]$sbin/hadoop-daemon.sh start datanode
(3)查看集群
(a)查看是否启动成功
[hadoop@hadoop101 hadoop-2.7.2]$ jps
13586 NameNode
13668 DataNode
13786 Jps
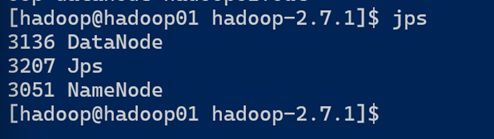
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
查看web端之前先查看防火墙的状态并关闭
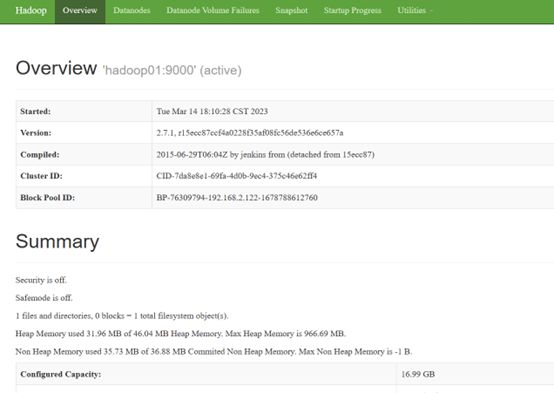
(b)web端查看HDFS文件系统
http://192.168.2.122:50070/
(d)思考:为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
注意:格式化时产生data文件夹
[hadoop@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/name/current/
[hadoop@hadoop101 current]$ cat VERSION
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
[hadoop@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/data/current/
[hadoop@hadoop101 current]$ cat VERSION
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。(先关闭namenode和datanode进程)
(4)操作集群
(a)在HDFS文件系统上创建一个input文件夹
[hadoop@hadoop101 hadoop-2.7.1]$
bin/hdfs dfs -mkdir -p /user/hadoop/input
(b)将测试文件内容上传到文件系统上
[hadoop@hadoop101 hadoop-2.7.1]$bin/hdfs dfs -put wcinput/wc.txt /user/hadoop/input/
(c)查看上传的文件是否正确
[hadoop@hadoop101 hadoop-2.7.1]$ bin/hdfs dfs -ls /user/hadoop/input/
[hadoop@hadoop101 hadoop-2.7.1]$ bin/hdfs dfs -cat /user/hadoop/ input/wc.txt

(d)运行MapReduce程序
[hadoop@hadoop101 hadoop-2.7.1]$
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /user/hadoop/input/ /user/hadoop/output
(e)查看输出结果
命令行查看:
[hadoop@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/hadoop/output/*

浏览器查看
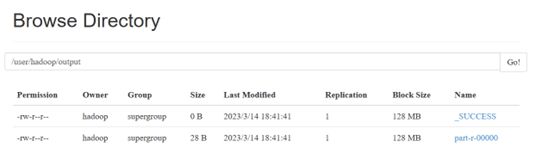
查看output文件
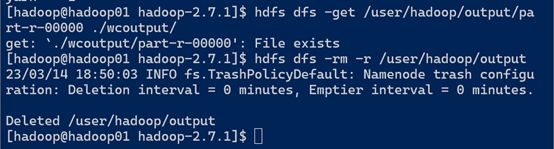
(f)将测试文件内容下载到本地
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -get /user/hadoop/output/part-r-00000./wcoutput/
(g)删除输出结果
[hadoop@hadoop101 hadoop-2.7.2]$ hdfs dfs -rm -r /user/hadoop/output
4.2.2 启动YARN并运行MapReduce程序
1. 分析
(1)配置集群在YARN上运行MR
(2)启动、测试集群增、删、查
(3)在YARN上执行WordCount案例
2. 执行步骤
(1)配置集群opt/module/hadoop-2.7.1/etc/hadoop
(a)配置yarn-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_162

(b)配置yarn-site.xml

(c)配置:mapred-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_162

(d)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
[hadoop@hadoop101 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[hadoop@hadoop101 hadoop]$ sudo vi mapred-site.xml

(2)启动集群
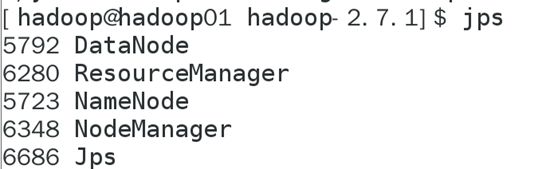
(a)启动前必须保证NameNode和DataNode已经启动
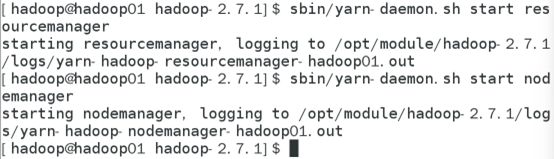
(b)启动ResourceManager
[hadoop@hadoop101 hadoop-2.7.1]$sbin/yarn-daemon.sh start resourcemanager
(c)启动NodeManager
[hadoop@hadoop101 hadoop-2.7.1]$sbin/yarn-daemon.sh start nodemanager
(3)集群操作
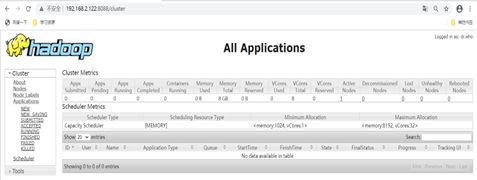
(a)YARN的浏览器页面查看
http://192.168.2.122:8088/cluster
hadoop101的yarn的浏览器页面
(b)删除文件系统上的output文件
[hadoop@hadoop101 hadoop-2.7.1]$ bin/hdfsdfs -rm -R /user/hadoop/output
(c)执行MapReduce程序
[hadoop@hadoop101 hadoop-2.7.1]$
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jarwordcount /user/hadoop/input /user/hadoop/output
(d)查看运行结果,如图2-36所示
[hadoop@hadoop101 hadoop-2.7.1]$ bin/hdfsdfs -cat /user/hadoop/output/*

查看运行结果
4.2.3 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
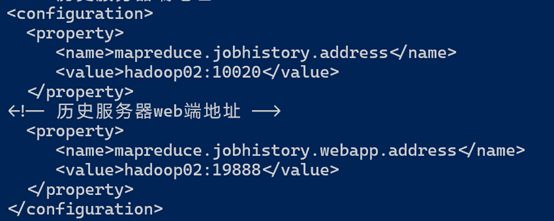
1. 配置mapred-site.xml
[hadoop@hadoop101hadoop]$ vi mapred-site.xml
在该文件里面增加如下配置。
2. 启动历史服务器
[hadoop@hadoop101 hadoop-2.7.1]$sbin/mr-jobhistory-daemon.sh start historyserver
3. 查看历史服务器是否启动
[hadoop@hadoop101 hadoop-2.7.1]$ jps
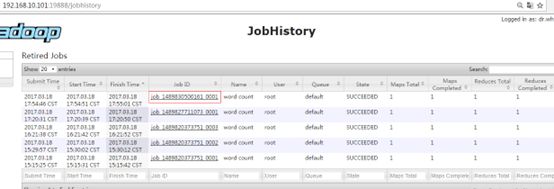
4. 查看JobHistory
http://192.168.2.122:19888/jobhistory
4.2.4 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
配置yarn-site.xml
[hadoop@hadoop101 hadoop]$ sudo vi yarn-site.xml
在该文件里面增加如下配置。
关闭NodeManager 、ResourceManager和HistoryManager
[hadoop@hadoop101 hadoop-2.7.1]$sbin/yarn-daemon.sh stop resourcemanager
[hadoop@hadoop101 hadoop-2.7.1]$sbin/yarn-daemon.sh stop nodemanager
[hadoop@hadoop101 hadoop-2.7.1]$sbin/mr-jobhistory-daemon.sh stop historyserver
启动NodeManager 、ResourceManager和HistoryManager
[hadoop@hadoop01 hadoop-2.7.1]$sbin/yarn-daemon.sh start resourcemanager
[hadoop@hadoop01 hadoop-2.7.1]$sbin/yarn-daemon.sh start nodemanager
[hadoop@hadoop01 hadoop-2.7.1]$ sbin/mr-jobhistory-daemon.shstart historyserver
删除HDFS上已经存在的输出文件
[hadoop@hadoop101 hadoop-2.7.1]$ bin/hdfs dfs -rm -R /user/hadoop/output
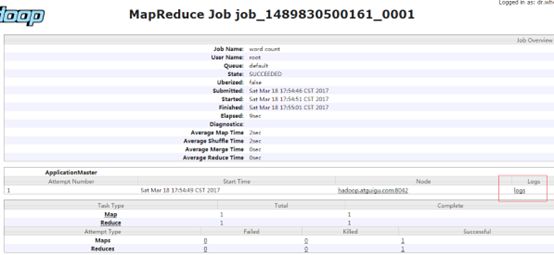
执行WordCount程序
[hadoop@hadoop101 hadoop-2.7.1]$
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /user/hadoop/input /user/hadoop/output
查看日志
http://192.168.2.122:19888/jobhistory
4.2.5 配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
要获取的默认文件 |
文件存放在Hadoop的jar包中的位置 |
[core-default.xml] |
hadoop-common-2.7.2.jar/ core-default.xml |
[hdfs-default.xml] |
hadoop-hdfs-2.7.2.jar/ hdfs-default.xml |
[yarn-default.xml] |
hadoop-yarn-common-2.7.2.jar/ yarn-default.xml |
[mapred-default.xml] |
hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。