大数据篇--数仓概念总结
文章目录
-
-
- 一、数据仓库
-
- 1.什么是数据仓库:
- 2.技术发展历程:
- 3.数据仓库特点:
- 4.OLAP和OLTP的区别:
-
- OLAP分类:
- 二、数据分层
-
- 1.为什么要分层:
- 2.怎样分层:
-
- a.ODS层:
- b.DW/CDM层:
- c.DM/ADS/APP层:
- d.维表层/公共维度层(Dimension):
- 3.举个例子:
- 三、元数据
- 四、数据模型
-
- 1.什么是数据建模:
- 2.为什么需要数据建模:
- 3.数仓建模阶段划分:
- 五、数仓建模方法
-
- 1.关系建模:
-
- OLTP数据库三范式介绍:
- 2.维度建模:
-
- a.星型模型:
- b.雪花模型:
- c.星座模型:
- d.选择:
- 3.实体建模:
- 六、大数据基础设施架构的演进过程
-
- 1.第一阶段-以Hadoop为代表的离线数据处理基础设施:
- 2.第二阶段:lambda架构:
- 3.第三阶段:Kappa架构:
- 七、主题和主题域
-
- 1.主题:
- 2.主题域(数据域):
- 3.主题域、主题、实体间关系:
- 八、数据仓库的痛点
- 九、数据湖
-
- 1.概念:
- 2.数据湖与数据仓库区别:
-
一、数据仓库
1.什么是数据仓库:
数据仓库,英文名称为Data Warehouse,关于数据仓库概念的标准定义业内认可度比较高的,是由数据仓库之父比尔·恩门(Bill Inmon)在1991年出版的“Building the Data Warehouse”(《建立数据仓库》)一书中所提出:数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
2.技术发展历程:
| 阶段 | 时间 | 描述 |
|---|---|---|
| 开始阶段 | 20世纪70年代-80年代中期 | MIT的研究员提出将业务处理系统和分析系统分开的技术架构设计原则,DEC公司结合MIT的研究结论,建立了TA2(Technical Architecture2)规范,该规范定义了分析系统的四个组成部分:数据获取、数据访问、目录和用户服务 |
| 全企业集成 | 1988年 | 为解决全企业集成问题,IBM公司第一次提出了信息仓(InformationWarehouse)的概念 |
| 企业级数据仓库 | 1991 | Bill Inmon出版了他的第一本关于数据仓库的书《Building the Data Warehouse》,标志着数据仓库概念的确立 |
| 数据集市 | 1994-1996 | 由于企业级数据仓库设计、实施困难,建设者只考虑建设企业级数据仓库的一部分,Ralph Kimball的书《The Datawarehouse Toolkit》提出数据模型优化详细指导意见,掀起数据集市狂潮 |
| 争吵与混乱 | 1996-1997 | 企业级数据仓库与部门级数据集市争吵(Bill派和Kimball派),同时引出了新的应用如:ODS |
| 合并 | 1998-2001 | Bill Inmon推出新的BI架构:CIF(Corporation information factory),把Kimball数据集市也包容进来,Kimball也承认了Bill,CIF的核心思想把整个架构分成不同的层次,同时对ODS,DW,DM,进行了详细的描述 |
| 未来 | 2001~ | 1. 战略决策到战术决策的发展:对DW的实时性和可获得性要求更高,要求724365 2.需求更加多样化,要求有不同的架构和应用层次以适应不同的需求 3. 数据量膨胀,对数据建模、数据组织和层次划分提出更高要求 |
3.数据仓库特点:

- 主题性:不同于传统数据库对应于某一个或多个项目,数据仓库根据使用者实际需求,将不同数据源的数据在一个较高的抽象层次上做整合,所有数据都围绕某一主题来组织。这里的主题怎么来理解呢?比如对于滴滴出行,“司机行为分析”就是一个主题,对于链家网,“成交分析”就是一个主题。
- 集成性:数据仓库中存储的数据是来源于多个数据源的集成,原始数据来自不同的数据源,存储方式各不相同。要整合成为最终的数据集合,需要从数据源经过一系列抽取、清洗、转换(ETL)的过程。
- 稳定性:数据仓库中保存的数据是一系列历史快照,不允许被修改。用户只能通过分析工具进行查询和分析。
- 变化的:数据仓库会定期接收新的集成数据,反应出最新的数据变化。这和稳定性特点并不矛盾。
4.OLAP和OLTP的区别:
面向业务的数据库常称作OLTP(联机事务处理,On-Line Transaction Processing),面向分析的数据仓库亦称为OLAP(联机分析处理OLAP,On-Line Analytical Processing)。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易;OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
OLAP分类:
参考:常见开源OLAP技术架构对比
OLAP 是一种让用户可以用从不同视角方便快捷的分析数据的计算方法。主流的 OLAP 可以分为3类:多维 MOLAP ( Multi-dimensional OLAP )、关系型 ROLAP ( Relational OLAP ) 和混合 HOLAP ( Hybrid OLAP ) 三大类。
MOLAP 的优点和缺点:
MOLAP的典型代表是:Druid,Kylin,Doris,MOLAP一般会根据用户定义的数据维度、度量(也可以叫指标)在数据写入时生成预聚合数据;Query查询到来时,实际上查询的是预聚合的数据而不是原始明细数据,在查询模式相对固定的场景中,这种优化提速很明显。
MOLAP 的优点和缺点都来自于其数据预处理 ( pre-processing ) 环节。数据预处理,将原始数据按照指定的计算规则预先做聚合计算,这样避免了查询过程中出现大量的即时计算,提升了查询性能。
但是这样的预聚合处理,需要预先定义维度,会限制后期数据查询的灵活性;如果查询工作涉及新的指标,需要重新增加预处理流程,损失了灵活度,存储成本也很高;同时,这种方式不支持明细数据的查询,仅适用于聚合型查询(如:sum,avg,count)。
因此,MOLAP 适用于查询场景相对固定并且对查询性能要求非常高的场景。如广告主经常使用的广告投放报表分析。
ROLAP 的优点和缺点:
ROLAP的典型代表是:Presto,Impala,GreenPlum,Clickhouse,Elasticsearch,Hive,Spark SQL,Flink SQL。
数据写入时,ROLAP并未使用像MOLAP那样的预聚合技术;ROLAP收到Query请求时,会先解析Query,生成执行计划,扫描数据,执行关系型算子,在原始数据上做过滤(Where)、聚合(Sum, Avg, Count)、关联(Join),分组(Group By)、排序(Order By)等,最后将结算结果返回给用户,整个过程都是即时计算,没有预先聚合好的数据可供优化查询速度,拼的都是资源和算力的大小。
ROLAP 不需要进行数据预处理 ( pre-processing ),因此查询灵活,可扩展性好。这类引擎使用 MPP 架构 ( 与Hadoop相似的大型并行处理架构,可以通过扩大并发来增加计算资源 ),可以高效处理大量数据。
但是当数据量较大或 query 较为复杂时,查询性能也无法像 MOLAP 那样稳定。所有计算都是即时触发 ( 没有预处理 ),因此会耗费更多的计算资源,带来潜在的重复计算。
因此,ROLAP 适用于对查询模式不固定、查询灵活性要求高的场景。如数据分析师常用的数据分析类产品,他们往往会对数据做各种预先不能确定的分析,所以需要更高的查询灵活性。
混合 OLAP ( HOLAP ):
混合 OLAP,是 MOLAP 和 ROLAP 的一种融合。当查询聚合性数据的时候,使用MOLAP 技术;当查询明细数据时,使用 ROLAP 技术。在给定使用场景的前提下,以达到查询性能的最优化。
顺便提一下,国内外有一些闭源的商业OLAP引擎,没有在这里归类和介绍,主要是因为使用的公司不多并且源码不可见、资料少,很难分析学习其中的源码和技术点。在一二线的互联网公司中,应用较为广泛的还是上面提到的各种OLAP引擎,如果你希望能够通过掌握一种OLAP技术,学习这些就够了。
二、数据分层
1.为什么要分层:
“为什么要设计数据分层?”,这应该是数据仓库同学在设计数据分层时首先要被挑战的问题,类似的问题可能会有很多,比如说“为什么要做数据仓库?”、“为什么要做元数据管理?”、“为什么要做数据质量管理?”。当然,这里我们只聊一下为什么要做设计数据分层。
作为一名数据的规划者,我们肯定希望自己的数据能够有秩序地流转,数据的整个生命周期能够清晰明确被设计者和使用者感知到。直观来讲就是如下的左图这般层次清晰、依赖关系直观。
但是,大多数情况下,我们完成的数据体系却是依赖复杂、层级混乱的。如下的右图,在不知不觉的情况下,我们可能会做出一套表依赖结构混乱,甚至出现循环依赖的数据体系。

因此,我们需要一套行之有效的数据组织和管理方法来让我们的数据体系更有序,这就是谈到的数据分层。数据分层并不能解决所有的数据问题,但是,数据分层却可以给我们带来如下的好处:
- 在未分层的情况下,数据之间的耦合性与业务耦合性是不可避免的,当源业务系统的业务规则发生变化时,可能影响整个数据的清洗过程。
- 清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
- 数据血缘追踪:简单来讲可以这样理解,我们最终给业务呈现的是一能直接使用的张业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
- 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
- 把复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
- 屏蔽原始数据的异常。
- 屏蔽业务的影响,不必改一次业务就需要重新接入数据。
- 通过大量的预处理来提升应用系统查询速度,进而提升的用户体验,因此数据仓库会冗余大量的数据,是典型的空间换时间的策略。
可以从这几个角度来理解数据分层的划分:
- 从对应用的支持来讲,我们希望越靠上层次,越对应用友好。比如APP层,基本是完全为应用来设计的,很易懂,DWS层的话,相对来讲就会有一点点理解成本,然后DWM和DWD层就比较难理解了,因为它的维度可能会比较多,而且一个需求可能要多张表经过很复杂的计算才能完成。
- 从能力范围来讲,我们希望80%需求由20%的表来支持。直接点讲,就是大部分(80%以上)的需求,都用DWS的表来支持就行,DWS支持不了的,就用DWM和DWD的表来支持,这些都支持不了的极少一部分数据需要从原始日志中捞取。结合第一点来讲的话就是:80%的需求,我们都希望以对应用很友好的方式来支持,而不是直接暴露给应用方原始日志。
- 从数据聚合程度来讲,我们希望,越上层数据的聚合程度越高,看上面的例子即可,ODS和DWD的数据基本是原始日志的粒度,不做任何聚合操作,DWM做了轻度的聚合操作只保留了通用的维度,DWS做了更高的聚合操作,可能只保留一到两个能表征当前描述主体的维度。从这个角度来看,我们又可以理解为我们是按照数据的聚合程度来划分数据层次的。
2.怎样分层:
我们从理论上来做一个抽象,一般可以把数据仓库分为下面三个层,即:数据运营层、数据仓库层和数据产品层。




a.ODS层:
数据运营层/原始数据层,也叫ODS层(Operational Data Store),是最接近数据源中数据的一层,数据源中的数据,经过抽取、传输,也就是传说中的 ETL 之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的,数据保持原貌。
这一层做的工作是贴源,而这些数据和源系统的数据是同构,一般对这些数据分为全量更新和增量更新,通常在贴源的过程中会做一些简单的清洗(注:网上有的说这一层面的数据却不等同于原始数据。在源数据装入这一层时,要进行诸如去噪、去重等操作。一般来讲,为了考虑后续可能需要追溯数据问题,比如有的数据可能未来就是有用的而现阶段却被你认为是没用的数据清洗掉了,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程可以放在后面的DWD层来做。)。
- 保持数据原貌不做任何修改,起到备份数据的作用。
- 数据采用压缩,减少磁盘存储空间(例如:原始数据 100G,可以压缩到 10G 左 右)
- 创建分区表,防止后续的全表扫描
b.DW/CDM层:
数据仓库层/数据公共层,是数据仓库的主体。在这里,从 ODS 层中获得的数据按照主题建立各种数据模型。这一层和维度建模会有比较深的联系。dw层还可以更加细分为(看公司业务和需求,可就一层DW,也可以细分成两层或者三层,反正这层没有统一的规范,有的公司还分了DWA(数据汇总层 Data Warehouse Aggregation)、DWB(基础数据层 Data Warehouse Base)、DWM(数据中间层 Data WareHouse Middle)层等,比较常见的细分如下):
- DWD:Data Warehouse Detail,明细数据层。该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。对ODS层的数据进行清洗(去除空值,脏数据,和超范围数据),脱敏等操作,另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性,DWD层是真正发力的层。DWD 层需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型。

维度建模一般按照以下四个步骤:

- DWS/DWM/DWB:Data Warehouse Summary/Data WareHouse Middle/Data Warehouse Base,数据汇总层/数据中间层/基础数据层。该层会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。如统计各个主题对象的当天行为,服务于 DWT 层的主题宽表,以及一些业务明细数据, 应对特殊需求(例如,购买行为,统计商品复购率)。直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。主题:比如用户主题,商品主题,订单主题;主题对象:不同主题有不同的主题对象,以用户主题为例,一个主题对象就是一个用户。

- DWT/DWS:Data Warehouse Topic/Data Warehouse Service,数据主题层/数据服务层。以分析的主题对象为建模驱动,基于上层的应用和产品的指标需求,构建主题对象的全量宽表。(按照维度来决定分析者的角度,如用户->什么时间->下了什么单,支付了什么,加入购物车了什么)。一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。

在实际计算中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在DWS/DWM层先计算出多个小的中间表,然后再拼接成一张DWT/DWS的宽表。由于宽和窄的界限不易界定,也可以去掉DWS/DWM这一层,只留DWS层,将所有的数据在放在DWT/DWS亦可。
c.DM/ADS/APP层:
数据集市(Data Mart)/数据应用层(Application Data Service)/数据产品层,这一层是提供为数据产品使用的结果数据。
在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、PostgreSql、Mysql 等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。比如我们经常说的统计报表数据,一般就放在这里。
d.维表层/公共维度层(Dimension):
最后补充一个维表层,可包含在DW层中,维表层主要包含两部分数据:
- 高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
- 低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。

3.举个例子:
如一个电商网站的数据体系设计。我们暂且只关注用户访问日志这一部分数据。
- 在ODS层中,由于各端的开发团队不同或者各种其它问题,用户的访问日志被分成了好几张表上报到了我们的ODS层。
- 为了方便大家的使用,我们在DWD层做了一张用户访问行为天表,在这里,我们将PC网页、H5、小程序和原生APP访问日志汇聚到一张表里面,统一字段名,提升数据质量,这样就有了一张可供大家方便使用的明细表了。
- 在DWM层,我们会从DWD层中选取业务关注的核心维度来做聚合操作,比如只保留人、商品、设备和页面区域维度。类似的,我们这样做了很多个DWM的中间表。
- 然后在DWS层,我们将一个人在整个网站中的行为数据放到一张表中,这就是我们的宽表了,有了这张表,就可以快速满足大部分的通用型业务需求了。
- 最后,在APP应用层,根据需求从DWS层的一张或者多张表取出数据拼接成一张应用表即可。
三、元数据
元数据(Metadata)是关于数据的数据。在数据仓库系统中,元数据是描述数据仓库内数据的结构和建立方法的数据,可将其按用途的不同分为两类:技术元数据(Technical Metadata);业务元数据(Business Metadata)
技术元数据:
技术元数据是存储关于数据仓库系统技术细节的数据,是用于开发和管理数据仓库使用的数据,它主要包括以下信息:数据仓库结构的描述,包括仓库模式、视图、维、层次结构和导出数据的定义,以及数据集市的位置和内容;业务系统、数据仓库和数据集市的体系结构和模式,汇总用的算法,包括度量和维定义算法,数据粒度、主题领域、聚集、汇总、预定义的查询与报告;由操作环境到数据仓库环境的映射,包括源数据和它们的内容、数据分割、数据提取、清理、转换规则和数据刷新规则、安全(用户授权和存取控制)。
业务元数据:
业务元数据从业务角度描述了数据仓库中的数据,它提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员也能够“读懂”数据仓库中的数据。业务元数据主要包括以下信息:使用者的业务术语所表达的数据模型、对象名和属性名;访问数据的原则和数据的来源;系统所提供的分析方法以及公式和报表的信息;具体包括以下信息:
- 企业概念模型:这是业务元数据所应提供的重要的信息,它表示企业数据模型的高层信息、整个企业的业务概念和相互关系。以这个企业模型为基础,不懂数据库技术和SQL语句的业务人员对数据仓库中的数据也能做到心中有数。
- 多维数据模型:这是企业概念模型的重要组成部分,它告诉业务分析人员在数据集市当中有哪些维、维的类别、数据立方体以及数据集市中的聚合规则。这里的数据立方体表示某主题领域业务事实表和维表的多维组织形式。业务概念模型和物理数据之间的依赖:以上提到的业务元数据只是表示出了数据的业务视图,这些业务视图与实际的数据仓库或数据库、多维数据库中的表、字段、维、层次等之间的对应关系也应该在元数据知识库中有所体现。
四、数据模型
1.什么是数据建模:
数据模型是抽象描述现实世界的一种工具和方法,是通过抽象的实体及实体之间联系的形式,来表示现实世界中事务的相互关系的一种映射。在这里,数据模型表现的抽象的是实体和实体之间的关系,通过对实体和实体之间关系的定义和描述,来表达实际的业务中具体的业务关系。
2.为什么需要数据建模:
进行全面的业务梳理,改进业务流程:
在业务模型建设的阶段,能够帮助我们的企业或者是管理机关对本单位的业务进行全面的梳理。通过业务模型的建设,我们应该能够全面了解该单位的业务架构图和整个业务的运行情况,能够将业务按照特定的规律进行分门别类和程序化,同时,帮助我们进一步的改进业务的流程,提高业务效率,指导我们的业务部门的生产。
建立全方位的数据视角,消灭信息孤岛和数据差异:
通过数据仓库的模型建设,能够为企业提供一个整体的数据视角,不再是各个部门只是关注自己的数据,而且通过模型的建设,勾勒出了部门之间内在的联系,帮助消灭各个部门之间的信息孤岛的问题,更为重要的是,通过数据模型的建设,能够保证整个企业的数据的一致性,各个部门之间数据的差异将会得到有效解决。
解决业务的变动和数据仓库的灵活性:
通过数据模型的建设,能够很好的分离出底层技术的实现和上层业务的展现。当上层业务发生变化时,通过数据模型,底层的技术实现可以非常轻松的完成业务的变动,从而达到整个数据仓库系统的灵活性。
帮助数据仓库系统本身的建设:
通过数据仓库的模型建设,开发人员和业务人员能够很容易的达成系统建设范围的界定,以及长期目标的规划,从而能够使整个项目组明确当前的任务,加快整个系统建设的速度。
3.数仓建模阶段划分:

业务建模: 生成业务模型,主要解决业务层面的分解和程序化。这部分建模工作,主要包含以下几个部分:
- 划分整个单位的业务,一般按照业务部门的划分,进行各个部分之间业务工作的界定,理清各业务部门之间的关系。
- 深入了解各个业务部门的内具体业务流程并将其程序化。
- 提出修改和改进业务部门工作流程的方法并程序化。
- 数据建模的范围界定,整个数据仓库项目的目标和阶段划分。
领域建模: 生成领域模型,主要是对业务模型进行抽象处理,生成领域概念模型。这部分得建模工作,主要包含以下几个部分:
- 抽取关键业务概念,并将之抽象化。
- 将业务概念分组,按照业务主线聚合类似的分组概念。
- 细化分组概念,理清分组概念内的业务流程并抽象化。
- 理清分组概念之间的关联,形成完整的领域概念模型。
逻辑建模: 生成逻辑模型,主要是将领域模型的概念实体以及实体之间的关系进行数据库层次的逻辑化。这部分得建模工作,主要包含以下几个部分:
- 业务概念实体化,并考虑其具体的属性。
- 事件实体化,并考虑其属性内容。
- 说明实体化,并考虑其属性内容。
物理建模: 生成物理模型,主要解决,逻辑模型针对不同关系型数据库的物理化以及性能等一些具体的技术问题。这部分得建模工作,主要包含以下几个部分:
- 针对特定物理化平台,做出相应的技术调整。
- 针对模型的性能考虑,对特定平台作出相应的调整。
- 针对管理的需要,结合特定的平台,做出相应的调整。
- 生成最后的执行脚本,并完善之。
从我们上面对数据仓库的数据建模阶段的各个阶段的划分,我们能够了解到整个数据仓库建模的主要工作和工作量,希望能够对我们在实际的项目建设能够有所帮助。
五、数仓建模方法
1.关系建模:
关系模型如图所示,严格遵循第三范式(3NF),从图中可以看出,较为松散、零碎,物理表数量多,而数据冗余程度低。由于数据分布于众多的表中,这些数据可以更为灵活地被应用,功能性较强。关系模型主要应用与OLTP系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。

OLTP数据库三范式介绍:
该方法主要由Inmon 所提倡,主要解决关系型数据库得数据存储,利用的一种技术层面上的方法。目前,我们在关系型数据库中的建模方法,大部分采用的是三范式(ThirdNormal Form,3NF)建模法。




2.维度建模:
维度建模法,Ralph Kimball 最先提出这一概念。其最简单的描述就是,按照事实表,维表来构建数据仓库。这种方法的最被人广泛知晓的名字就是星型模式(Star-schema)。
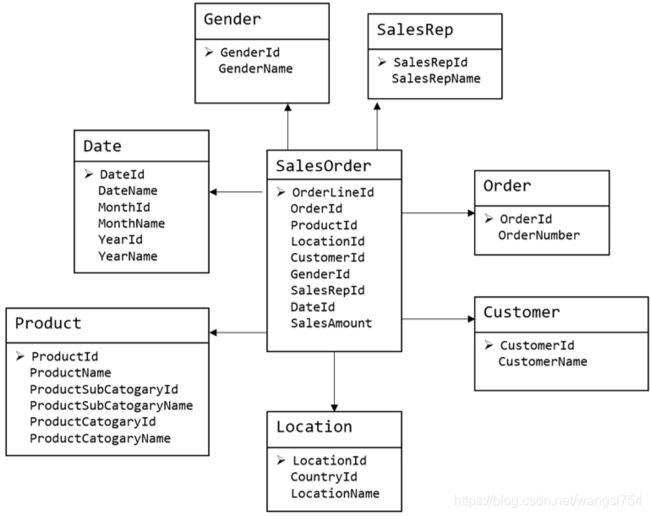
维度模型如图所示,主要应用于OLAP系统中,通常以某一个事实表为中心进行表的组织,主要面向业务,特征是可能存在数据的冗余,但是能方便的得到数据。
关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。所以通常我们采用维度模型建模,把相关各种表整理成两种:事实表和维度表两种。
在维度建模的基础上还可以分为三种模型:星型模型、雪花模型、星座模型。
当设计好概念模型时,就要根据概念模型设计逻辑模型,而在设计逻辑模型时,通常根据事实表和维度表的关系,将常见的模型架构分为星型模型和雪花型模型。
星型模型架构是一种非正规化的结构,特点是有一张事实表,多张维度表,是不存在渐变维度的,事实表和维度表通过主外键相关联,维度表之间是没有关联,因为维度表的数据冗余,所以统计查询时不需要做过多外部连接。
雪花模型架构就是将星型模型中的某些维度表抽取成更细粒度的维度表,然后让维度表之间也进行关联,通过最大限度的减少数据存储量以及联合较小的维度表来改善查询性能。

a.星型模型:

标准的星型模型周围只有一层,即一个事实表周围只有一层维度表与之对应。
b.雪花模型:

雪花模型的维度层级比星型模型多,雪花模型比较靠近3NF,但无法完全遵守,因为遵守3NF的性能成本太高。
c.星座模型:

星座模型与前两个模型的区别在于事实表的数量,星座模型中的事实表要多。而且事实表之间也有可能会共享维度表。
d.选择:
首先星座与否与数据和需求有关系,与设计无关,不用抉择。星型还是雪花,取决于性能优先,还是灵活优先。实际开发中,不会只选择一种,根据情况灵活组合,甚至并存。但是整体来看,更倾向于维度更少的星型模型。尤其是Hadoop体系,减少join就是减少shuffle,性能差别很大。
3.实体建模:
实体建模法并不是数据仓库建模中常见的一个方法,它来源于哲学的一个流派。从哲学的意义上说,客观世界应该是可以细分的,客观世界应该可以分成由一个个实体,以及实体与实体之间的关系组成。那么我们在数据仓库的建模过程中完全可以引入这个抽象的方法,将整个业务也可以划分成一个个的实体,而每个实体之间的关系,以及针对这些关系的说明就是我们数据建模需要做的工作。

六、大数据基础设施架构的演进过程
1.第一阶段-以Hadoop为代表的离线数据处理基础设施:
如下图所示,Hadoop是以HDFS为核心存储,以MapReduce(简称MR)为基本计算模型的批量数据处理基础设施。

围绕HDFS和MR,产生了一系列的组件,不断完善整个大数据平台的数据处理能力,例如面向在线KV操作的HBase、面向SQL的HIVE、面向工作流的PIG等。同时,随着大家对于批处理的性能要求越来越高,新的计算模型不断被提出,产生了Tez、Spark、Presto、Flink等计算引擎,MR模型也逐渐进化成DAG模型。
DAG模型一方面增加计算模型的抽象并发能力:对每一个计算过程进行分解,根据计算过程中的聚合操作点对任务进行逻辑切分,任务被切分成一个个的stage,每个stage都可以有一个或者多个Task组成,Task是可以并发执行的,从而提升整个计算过程的并行能力;
另一方面,为减少数据处理过程中的中间结果写文件操作,Spark、Presto等计算引擎尽量使用计算节点的内存对数据进行缓存,从而提高整个数据过程的效率和系统吞吐能力。
2.第二阶段:lambda架构:
随着数据处理能力和处理需求的不断变化,越来越多的用户发现,批处理模式无论如何提升性能,也无法满足一些实时性要求高的处理场景,流式计算引擎应运而生,例如Storm、Spark Streaming、Flink等。
然而,随着越来越多的应用上线,大家发现,其实批处理和流计算配合使用,才能满足大部分应用需求;而对于用户而言,其实他们并不关心底层的计算模型是什么,用户希望无论是批处理还是流计算,都能基于统一的数据模型来返回处理结果,于是Lambda架构被提出,如下图所示。

Lambda架构的核心理念是“流批一体”,如上图所示,整个数据流向自左向右流入平台。进入平台后一分为二,一部分走批处理模式,一部分走流式计算模式。无论哪种计算模式,最终的处理结果都通过统一服务层对应用提供,确保访问的一致性,底层到底是批或流对用户透明。
3.第三阶段:Kappa架构:
Lambda架构虽然解决了应用读取数据的统一性问题,但是“流批分离”的处理链路增大了研发的复杂性。因此,有人就提出能不能用一套系统来解决所有问题。目前比较流行的做法就是基于流计算来做。流计算天然的分布式特征,注定了他的扩展性更好。通过加大流计算的并发性,加大流式数据的“时间窗口”,来统一批处理与流式处理两种计算模式。

七、主题和主题域
1.主题:
主题是与传统数据库的面向应用相对应的,是一个抽象概念,是在较高层次上将企业信息系统中的数据综合、归类并进行分析利用的抽象。
每一个主题对应一个宏观的分析领域。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。面向主题的数据组织方式, 就是在较高层次上对分析对象数据的一个完整并且一致的描 述,能刻画各个分析对象所涉及的企业各项数据,以及数据之间的联系。所谓较高层次是相对面向应用的数据组织方式而言的, 是指按照主题进行数据组织的方式具有更高的数据抽象级别。 与传统数据库面向应用进行数据组织的特点相对应, 数据仓库中的数据是面向主题进行组织的。主题是根据分析的要求来确定的。这与按照数据处理或应用的要求来组织数据是不同的。
2.主题域(数据域):
主题域通常是联系较为紧密的数据主题的集合。可以根据业务的关注点,将这些数据主题划分到不同的主题域。主题域的确定必须由最终用户和数据仓库的设计人员共同完成。
3.主题域、主题、实体间关系:
主题设计是对主题域进一步分解,细化的过程。主题域下面可以有多个主题,主题还可以划分成更多的子主题,而实体则是不可划分的最小单位。主题域、主题、实体的关系如下图所示:

八、数据仓库的痛点
参考:
数据仓库架构
数仓基础概念
什么是数据仓库?
数据仓库与数仓建模
企业级数据仓库PPT分享
一种通用的数据仓库分层方法
九、数据湖
参考:数据库, 数据仓库, 数据集市,数据湖,数据中台
1.概念:
伴随着数据湖概念热度的增加,已有超过数据仓库之势。Pentaho首席技术官James Dixon创造了“数据湖”一词。它把数据集市描述成一瓶水(清洗过的,包装过的和结构化易于使用的)。
而数据湖更像是在自然状态下的水,数据流从源系统流向这个湖。用户可以在数据湖里校验,取样或完全的使用数据。
这个也是一个不精确的定义。数据湖还有以下特点:
- 从源系统导入所有的数据,没有数据流失。
- 数据存储时没有经过转换或只是简单的处理。
- 数据转换和定义schema 用于满足分析需求。

数据湖为什么叫数据湖而不叫数据河或者数据海?一个有意思的回答是: - “河”强调的是流动性,“海纳百川”,河终究是要流入大海的,而企业级数据是需要长期沉淀的,因此叫“湖”比叫“河”要贴切;
同时,湖水天然是分层的,满足不同的生态系统要求,这与企业建设统一数据中心,存放管理数据的需求是一致的,“热”数据在上层,方便应用随时使用;温数据、冷数据位于数据中心不同的存储介质中,达到数据存储容量与成本的平衡。 - 不叫“海”的原因在于,海是无边无界的,而“湖”是有边界的,这个边界就是企业/组织的业务边界;因此数据湖需要更多的数据管理和权限管理能力。
- 叫“湖”的另一个重要原因是数据湖是需要精细治理的,一个缺乏管控、缺乏治理的数据湖最终会退化为“数据沼泽”,从而使应用无法有效访问数据,使存于其中的数据失去价值。
2.数据湖与数据仓库区别:
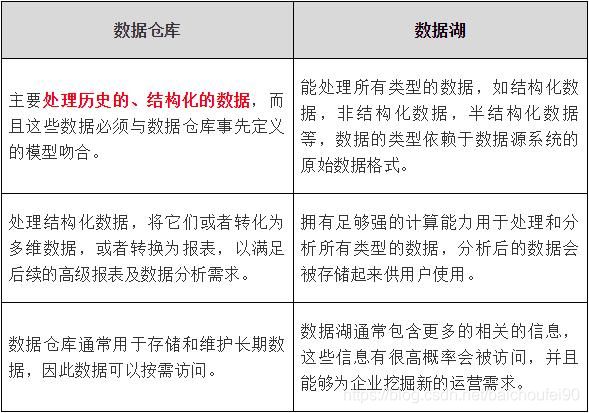
数据仓库和数据湖面向应用场景不同,不存在谁比谁更“厉害”,数据仓库注重数据的规范性,牺牲了灵活性,提供最直接的服务给业务人员。而数据湖由于缺乏数据标准规范的约束,对数据管理能力不会高,但数据湖保留了数据最原始的状态,面向技术人员(有一定技术基础的业务人员)提供灵活的可定制的数据服务。
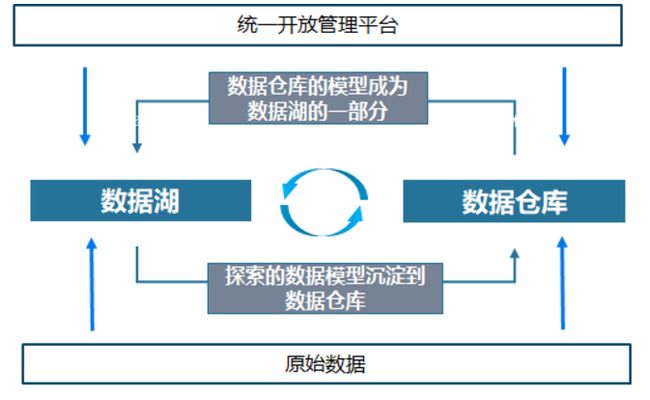
数仓和数据湖可以结合使用,实现优势互补(出自阿里提出的湖仓一体的概念,可参考:贾扬清发布阿里云「湖仓一体」解决方案,下一代大数据计算平台来了! ),湖和仓的数据/元数据无缝打通,互相补充,数据仓库的模型反哺到数据湖(成为原始数据一部分),湖的结构化应用知识沉淀到数据仓库,数据湖与数据仓库的数据,系统可以根据自动的规则决定哪些数据放在数仓,哪些保留在数据湖,进而形成一体化。