【你不知道的事】Javascript 中一种更安全的 URL 读写方式
在日常开发中,你可能在不知不觉中以一种不安全的方式编写url,例如,你能发现下面这段代码中有什么错误吗?
const url = `https://blog.xxx
?model=${model}&locale=${locale}?query.text=${text}`
const res = await fetch(url)
至少有三个错误:
1. 不正确的分隔符
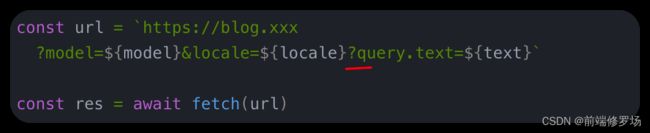
这像是一个新手会犯的错误,但也是一个很容易忽略的错误,即使在开发了10年的JS之后,我也在自己的代码中也发现了这个错误。
在我的经验中,一个常见的造成这个错误的原因是在编辑或移动代码之后引发了这个问题。例如,你有一个结构正确的URL,然后从一个部分复制到另一个部分,然后忽略了参数分隔符的顺序错误。
除此之外,在连接字符串时也会发生这种情况。例如:
url = url + '?foo=bar'
2. 忘记进行 encode

嗨。model和locale可能不需要编码,因为它们是 url 安全的值,但文本可以是各种类型的文本,包括空白和特殊字符,如果不进行 encode,将给我们带来问题。
所以也许我们会矫枉过正,写成了这样:
const url = `https://blog.xxx
?model=${
encodeURIComponent(model)
}&locale=${
encodeURIComponent(locale)
}&query.text=${
encodeURIComponent(text)
}`
但这样感觉有点更糟糕了。
3. 出现意外的空白字符
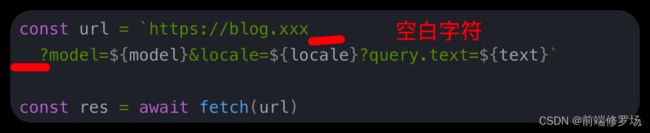
为了将这个长 URL 分解成多行,我们可能意外地在 URL 中包含了换行符和额外的空格,这将使获取不再像预期的那样工作。
虽然这个问题可以通过正确地拆分字符串来处理,但这也会使得变得更加混乱和难以阅读,例如:
const url = `https://blog.xxx`
+ `?model=${
encodeURIComponent(model)
}&locale=${
encodeURIComponent(locale)
}&query.text=${
encodeURIComponent(text)
}`
仅仅为了正确地构造一个URL,就做了很多。我们下次还会记住这些吗,特别是当最后期限即将到来,我们需要尽快发布新功能或修复时?
是不是有更好的方法。URL构造函数可以拯救你!
URL构造函数
一个更干净、更安全的解决方案是使用 URL 构造函数,所有的现代浏览器中均支持它。
下面有一代这样的代码:
const url = new URL('https://blog.xxx')
url.searchParams.set('model', model)
url.searchParams.set('locale', locale)
url.searchParams.set('text', text)
const res = await fetch(url.toString())
它为我们解决了几个问题:
- 分隔符总是正确的(?对于第一个参数,以及之后)。
- 所有参数都是自动编码的。
- 对于长 url,在跨多行中断时没有额外的空白字符的风险。
修改url
对于我们正在修改URL但不知道当前状态的情况,这也是非常有用的。
url += (url.includes('?') ? '&' : '?') + 'foo=bar'
对于上述代码,可以用下列代码替换:
url.searchParams.set('foo', 'bar')
const structuredUrl = new URL(url)
structuredUrl.searchParams.set('foo', 'bar')
url = structuredUrl.toString()
类似地,你也可以写URL的其他部分:
const url = new URL('https://builder.io')
url.pathname = '/blog' // Update the path
url.hash = '#featured' // Update the hash
url.host = 'www.blog.xxx' // Update the host
url.toString() // https://www.blog.xxx/blog#featured
读取 URL 的值
使用 URL 构造函数,在没有库的情况下从当前URL读取查询参数的老问题得到了解决。
const pageParam = new URL(location.href).searchParams.get('page')
或者例如更新当前URL:
const url = new URL(location.href)
const currentPage = Number(url.searchParams.get('page'))
url.searchParams.set('page', String(currentPage + 1))
location.href = url.toString()
但这不仅仅局限于浏览器。它也可以在Node.js中使用:
const http = require('node:http');
const server = http.createServer((req, res) => {
const url = new URL(req.url, `https://${req.headers.host}`)
});
URL 属性
URL实例支持在浏览器中已经使用过的所有属性,例如 window.location 或锚定元素,所有这些元素都可以读和写:
const url = new URL('https://blog.xxx/blog?page=1');
url.protocol // https:
url.host // blog.xxx
url.pathname // /blog
url.search // ?page=1
url.href // https://blog.xxx/blog?page=1
url.origin // https://blog.xxx
url.searchParams.get('page') // 1
URLSearchParams方法
URLSearchParams 对象,在 URL 实例中作为 URL 访问。searchParams支持许多方便的方法:
searchParams.has(name)
检查搜索参数是否包含给定的名称:
url.searchParams.has('page') // true
searchParams.get(name)
获取给定参数的值:
url.searchParams.get('page') // '1'
searchParams.getAll(name)
获取为参数提供的所有值。这很方便,如果你允许多个值在同一个名称,如&page=1&page=2:
url.searchParams.getAll('page') // ['1']
searchParams.set(name, value)
设置一个参数的值:
url.searchParams.set('page', '1')
searchParams.append(name, value)
追加一个参数值。如果你可能支持多个相同的参数,就很有用,比如&page=1&page=2 :
url.searchParams.append('page', '2')
searchParams.delete(name)
从URL中完全删除一个参数:
url.searchParams.delete('page')
注意点
要知道的一个大陷阱是传递给 URL 构造函数的所有 URL 都必须是绝对路径。
例如,这将抛出一个错误:
new URL('/blog') // ERROR!
你可以通过提供一个 origin (源)作为第二个参数来解决这个问题,如下所示:
new URL('/blog', 'https://blog.xxx')
或者,如果你真的只需要使用 URL 部分,你也可以直接使用 URLSearchParams。例如你只需要使用相对URL的查询参数:
const params = new URLSearchParams('page=1')
params.set('page=2')
params.toString()
URLSearchParams 还有另一个优点,那就是它可以把一个键值对的对象作为它的输入:
const params = new URLSearchParams({
page: 1,
text: 'foobar',
})
params.set('page=2')
params.toString()