自然语言处理|SkipGram训练中文词向量
课程作业,训练语料是维基百科的中文语料,训练词向量计算两个词之间的余弦相似度。关于预处理网络上有不少教程,后面如果有时间会补一下,程序结构图里给出了对应步骤用到的库,可以借鉴。
1. 程序结构概览
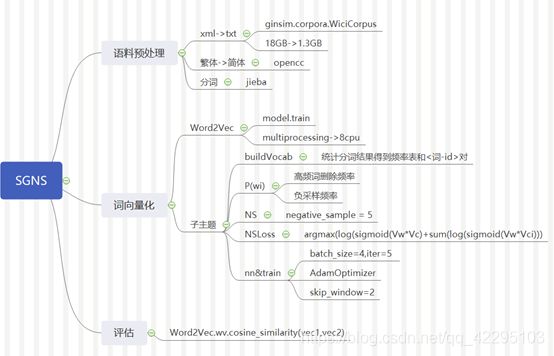
2. 基于Word2Vec的实现
基于Word2Vec的实现直接调用了gensim库,调整了几个参数,调整情况如下,详细代码备注见SGNS_ginsim.py. 训练数据有362826条左右,选择了其中的360000条,分10批进行训练。
(1)调整参数使之满足模型要求:
sg: 令其=1,指定方法为skip gram,默认值为0
size: 向量维度,100,默认即可
window:窗口大小,使其等于2,默认为5
hg: 默认即可,采用negative sampling
negative:取5,负采样个数
可以通过将workers设定为multiprocessing.cpu_coutn(),从而获得更高的计算效率
(2)语料分批训练:
Pc上运行所有数据时过段时间就会由守护进程将其关闭,所以可以通过分批训练避免这个问题,将数据分成10份,每份约36000条数据,训练结束后释放语料占用的空间,可以从一定程度上节省系统资源提高效率,使用
Model.train()可以在以训练模型上继续训练,并且更新原有词的模型。但这样做的弊端也很明显,由于在第一步设置了不计出现频次低于5的词,所有如果有些词分布式存在于语料中,则会有统计不到的情况,程序运行总时长约25分钟。
3. 基于神经网络的实现
自行实现的SGNS基于pytorch框架,根据ppt和两篇有关skip gram算法和实现的文章实现的(链接在文末给出),根据这个算法介绍的文章尝试了自行实现,但是因为数据规模和机器性能最后只跑了一小部分数据。
- 构建词表
词表构建基于统计,使用了collections.Counter()对分好词的语料计数并存入字典,构建word2id表,以备后期生成onehot编码和查询使用。
- Skip Gram
首先对Skip Gram按照算法图进行了搭建,即输入一个输入词,根据输入词的eonhot编码(假设有n维)将其映射到d维的向量,再对这个300维的向量进行一次计算获得n维概率分布,并使用softmax对齐进行一次标准化。损失函数选择了NLLLoss。
class SkipGram(nn.Module):
def __init__(self, n_vocab, n_vetor):
super().__init__()
self.hidden = nn.Embedding(n_vocab, n_vetor)
self.output = nn.Linear(n_vector,n_vocab)
self.log_softmax = nn.LogSoftmax(dim=1)
def forward(self,x):
x = self.hidden(x)
out = self.output(x)
log_p = self.log_softmax(out)
return log_p
- 高频词抽取
高频词抽取计算每个词从语料中删除的概率,从而在投入模型前根据概率随机的删除某个词,这样做可以减少训练样本数,可以这么做的原因是高频词往往一般是“的“、“是”、“和”等,而这些词和很多词的意义没有什么明确的贡献,所以可以删除部分高频词,其概率计算公式如下:
![]()
对每个input word对应窗口内的词根据概率随机选取数字,参考了网上的做法生成一个0-1的随机数,当随机数小于p时舍弃。按照这个公式,当一个词的出现频次大于0.26%时才有可能被删。
- 负采样
负采样的核心思想是将原来的n个词的分布分为正例和负例两部分,不进行多分类每次更新所有权重,而只从若干个负例中选择2-5个,只对这几个词的权重做更新。每个词被被选择的概率为:
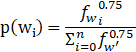
对一组样本:输入w,正例c 和负例ci,极大化
![]()
最终可以获得一个优化后的权重矩阵,上式即学习损失函数。定义类NSLoss:
class NSLoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, inputs_, positive_, negative_,theta, nNS=5):
input_vectors=inputs_.view(batch_size,embed_size, 1)
positive_vectors=positive_.view(batch_size,1,embed_size)
out_loss=(torch.bmm(positive_vectors,input_vectors)*theta1).sigmoid().log()
out_loss=out_loss.squeeze()
negative_loss=(torch.bmm(negative_.neg(),input_vectors)*theta2).sigmoid().log()
negative_loss=negative_loss.squeeze().sum(-1)
output_loss=out_loss+negative_loss
return output_loss
对应的,由于不在涉及输出概率分布,所以skip gram也做出相应的调整,将其输出层的d*n维权重矩阵替换为一个词作为上下文时的权重矩阵。
- 训练
训练函数以某个词w为输入的一组样本为一个batch(原本想固定一个较大的值,后来因为总是出现cuda memory error就选小了),迭代次数为5,优化器为Adam优化器。具体代码见文件SGNS.py. 具体没有运行大数据,所以性能什么的还不好说。
4. 结果分析
在分批训练的过程中,观察每次的结果可以发现随着模型规模增加词间相似度会产生一定的变化:
|
|
Epoch=0 |
Epoch=3 |
Epoch=6 |
Epoch=9 |
|||||
| Min_count |
5 |
1 |
5 |
1 |
5 |
1 |
5 |
1 |
|
| 包袱 段子 |
0.67 |
0.74 |
0.48 |
0.58 |
0.52 |
0.59 |
0.37 |
0.51 |
|
| 欧洲 南美洲 |
0.79 |
0.81 |
0.724 |
0.8 |
0.71 |
0.76 |
0.805 |
0.83 |
|
| 没戏 没辙 |
OOV |
0.89 |
OOV |
0.76 |
OOV |
0.68 |
OOV |
0.66 |
|
由于一开始并没有把word2vec的参数min_count调低,而又因为分批训练可能会导致如果一个词分散出现在不同批次的语料中,每批次的语料中的次数又达不到5的时候会被抛弃,所以后来进行了调整,将min_count调低后语料里出现的所有词都会出现在词库里,但是这样做的话词库规模从54万上升到了367万(包含英语,最低计数为5的时候中文词44万左右),相应的训练时间也增加了20分钟左右,虽然可以纳入一些出现次数很少的词但是根据上表相似度结果和原先的结果对比来看,相似的词和差异较大的词之间距离很近,而且基本分布在0.5-0.8的区间内,区别不是特别明显,并不能很好的体现相似的词对。
参考链接:
[1]一文详解Word2Vec之SkipGram模型(结构/训练/实现),https://www.leiphone.com/news/201706/PamWKpfRFEI42McI.html
[2]什么是Embedding,https://blog.csdn.net/weixin_44493841/article/details/95341407
[3]pytorch系列 ---5以 linear_regression为例讲解神经网络实现基本步骤以及解读nn.Linear函数,https://blog.csdn.net/dss_dssssd/article/details/83892824
[4]各种优化器的比较,https://www.cnblogs.com/qqw-1995/p/11095788.html