Redis布隆过滤器
认识布隆过滤器
引子
网络爬虫,判断URL是否被爬过(每条URL平均64字节);APP用户注册,判断用户名是否可用?
正式介绍布隆过滤器之前,我们先用常规的手段去解决上面两个场景。
例子一:我们做爬虫程序,会爬取很多的URL地址,我们怎么知道某个URL地址是否爬取过呢?

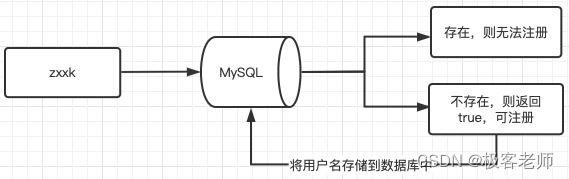
例子二:使用数据库判断某个用户名是否注册过?
上面两个案例的解决方案在数据量大或高并发的情况存在如下问题:
案例1,如果数据量大,有很多的URL需要存储,那么Set集合需要把所有的爬虫过的URL地址存下来,每个地址需要64个字节,那么如果有1亿条数据,64 * 8 * 1E个比特位(这个还不考虑数据结构本身还需要额外占用的内存),我们就需要大概5.96G的内存,内存占用几乎是不可忍受,那么就更不用说大型互联网公司,他们的数据量更大,这种方案肯定是不可行的。
案例2,我们采用MySQL这种带有持久化的数据库,虽然解决了内存问题,但是如果是亿级用户,在高并发的场景下,我们频繁查询数据库,仅仅是来确定用户是否注册过,务必影响系统的性能。
总结来说:传统方式在做大数据去重,会出现内存占用过大,或者操作耗时的问题;那么有没一种内存占用不那么大,同时性能还不错的方式呢?
答案,布隆过滤器是一个不错的选择。
基本原理
布隆过滤器 (Bloom Filter)是由 Burton Howard Bloom 于 1970 年提出,我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构;布隆过滤器可以用于检索一个元素是否在一个集合中;相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,缺点是有一定的误识别率和删除困难。
从上面的场景中看,我们的需求很简单,只是需要判断一下,某条数据是否存在,而不关心这条数据的具体内容,也就是返回一个bool值即可。而我们计算机中二进制天然的满足了这个特性,0代表false,1代表true;此时我们可以在内存中申请一个bit数组(又称Bigmap位图)。
![]()
我们就按最简单的来,我们判断的是int数值是否存在,如:2,5,6,7,12已经存在,则我们可以把对应位置的bit位置设为1,表示存在,如下图:
![]()
此时,如果我们判断3是否存在的时候,判断该位置的bit位是否为1即可,这样的比我们声明一个int类型的数组,挨个存储,然后判断,省去了极大空间,int值占用4个byte,也就是32个bit位,而采用这种bit数组来做,一下子省去了32倍的内存空间。
现在我们知道int的储存和判断方案,但实际引用场景很少会使int类型,比如案例一中判断某个URL是否爬虫,对于这种字符串,它不是一个int值,我们如何确定位置呢?此时,Hash函数就排上用场了,我们可以将字符串进行Hash运算,计算出一个int值,然后把值映射到位图上。

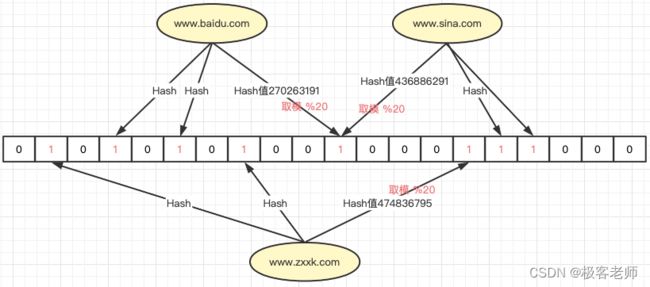
当然,上图给出的是理想情况,而实际上,我们很难找到一个足够好的hash函数,使得到的hash值在非常小的范围内,通常一个好的hash函数算出来的hash值足够随机且均匀,也就是说会随机的散列到0~Integer.maxValue的范围内,这是一个很大的值;如:www.zxxk.com在java自带的hash函数得出的值为474836795,www.baidu.com对应的hash值为270263191,www.sina.com对应的hash值为436886291。
如果我们只有1000万个字符串需要判断,但是随便一个字符串的hash值都有可能大于1000万这个数值,所以声明1000万个大小的bit位是不够用的,我们需要给出的int最大值的bit位,而这会浪费大量的空间,与布隆过滤器的目标相违背。这个时候,取模法就可以上场了,我们把得到出的hash值进行取余,得出位置。

上图我们可以看出,我们使用了取模法,达到了压缩空间的目的,但大家同时会发现,这里有一个冲突,有可能后,我们不同的数据落到同一个位置,甚至我们Hash函数都有可能发生冲突,也就是不同的字符串算出的Hash值是一样的,而且Hash冲突几乎是不可能解决的,也就导致我们的位图表示存在是有可能误报的,也就是布隆过滤器告诉你哪个位置上有数据了,但有可能是别人放进去的,实际上你自己并没有放;这是不可避免的,但我们可以通过增加Hash函数个数的方法降低冲突率:
布隆过滤器采用了位图数据结构,大大减少了内存占用,采用Hash方法将数据映射到位图上,但是Hash函数本身就有冲突,取模节省空间也会导致冲突率的上升,解决的办法主要就是增加Hash函数个数和位图大小上限,这些涉及到具体的算法和数学论证,在此我们就不展开了。
Guava工具类-布隆过滤器
理论上我们是完全可以自己实现一个布隆过滤器,当然,市面上有一些现成的工具包已经给我们封装好了布隆过滤器。比如:Google的Guava包就已经实现了布隆过滤器、Redis4.0通过插件方式提供了布隆过滤器的实现、Redisson布隆过滤器等等…
我们演示一下Guava工具包布隆过滤器:
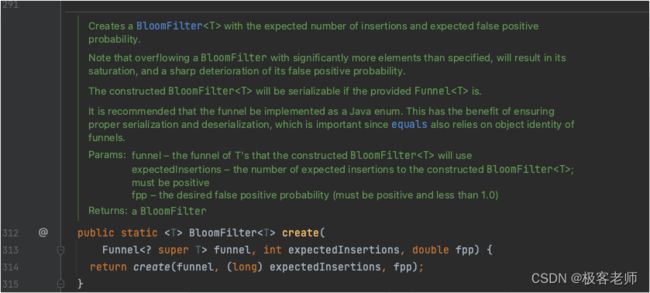
// 创建一个布隆过滤器,需要存放1000W的数据,误报率为0.0001
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 10000000, 0.0001);
// 存放100W的数据到布隆过滤器中
int totalCount = 10000000;
for (int i = 0; i < totalCount; i++) {
bloomFilter.put(i);
}
// 记录匹配到的次数
int matchCount = 0;
// 判断0~2000W区间数据是否在布隆过滤器中
for (int j = 0; j < totalCount * 2; j++) {
if (bloomFilter.mightContain(j)) {
matchCount++;
}
}
System.out.println("冲突的个数为:" + (matchCount - totalCount)); // 948,概率为0.0000948

上面使用Guava实现布隆过滤器是把数据放在本地内存中,无法实现布隆过滤器的共享。
**谨记:**布隆过滤器有可能会误报,但是不存在一定是不存在的。也就是说不存在一定不存在,存在不一定存在(false if always false, true maybe not true)。
Redis布隆过滤器
引子-缓存穿透
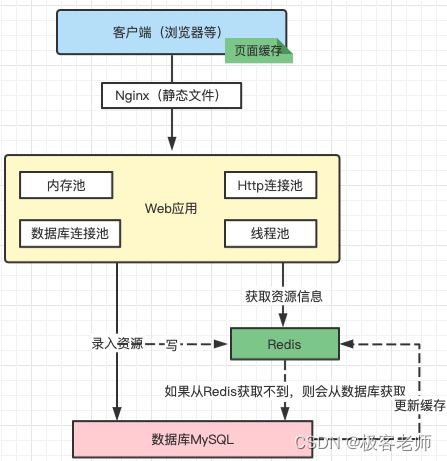
在高并发场景下,如果某一个 key 被高并发访问,没有被命中,出于对容错性考虑,会尝试去从后端数据库中获取,从而导致了大量请求到达数据库,而当该 key 对应的数据库本身就是空的情况下,这就导致数据库中并发的去执行了很多不必要的查询操作,从而导致巨大冲击和压力。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义。
造成缓存穿透的基本原因有两个:
1)自身业务代码或者数据出现问题;
2)一些恶意爬虫、网络攻击等造成大量空命中。
解决方案:缓存空对象
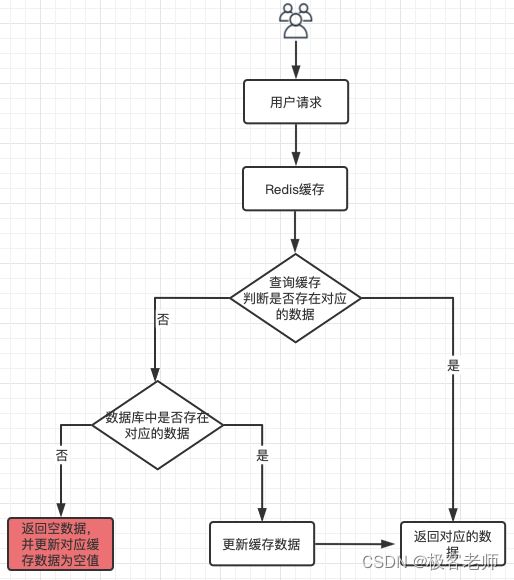
String getCacheValue(String key) {
// 先从缓存中获取数据
String cacheValue = cache.get(key);
// 如果缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 则从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(360秒)
if (storageValue == null) {
cache.expire(key, 60 * 6);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
除了使用上面这种办法(缓存空对象)解决缓存穿透的问题,也可以借助Redis的布隆过滤器解决该问题。
Redisson布隆过滤器
引入依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.0</version>
</dependency>
示例代码:
Config config = new Config();
config.useSingleServer().setAddress("redis://10.1.25.73:6379");
config.useSingleServer().setPassword("rzQP46/ThrECyHQ2tlEMSw==");
// 构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
// 初始化布隆过滤器:预计元素为100000000L,误差率为0.003,根据这两个参数会计算出底层的bit数组大小
bloomFilter.tryInit(100000L,0.003);
// 将zxxk插入到布隆过滤器中
bloomFilter.add("zxxk");
bloomFilter.add("baidu");
// 判断下面名称是否在布隆过滤器中
System.out.println(bloomFilter.contains("sina"));// false
System.out.println(bloomFilter.contains("google"));// false
System.out.println(bloomFilter.contains("zxxk"));// true
手写布隆过滤器
我们还可以把数据放在Redis中,用 Redis来实现布隆过滤器,我们要使用的数据结构是Bitmap,你可能会有疑问,Redis支持五种数据结构:String,List,Hash,Set,ZSet,没有Bitmap呀。没错,实际上Bitmap的本质还是String;要用Redis来实现布隆过滤器,我们需要自己设计映射函数,自己度量二进制向量的长度。
示例代码:
/**
* Redis布隆过滤器
*
* @author tony
* @date 2022/09/05
*/
public class RedisBloomFilter<T> {
private Jedis jedis;
public RedisBloomFilter(Jedis jedis) {
this.jedis = jedis;
}
/**
* 根据给定的布隆过滤器添加值
*/
public <T> void addByBloomFilter(BloomFilterStrategies<T> bloomFilterStrategies, String key, T value) {
int[] offset = bloomFilterStrategies.murmurHashOffset(value);
for (int i : offset) {
jedis.setbit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器判断值是否存在
*/
public <T> boolean includeByBloomFilter(BloomFilterStrategies<T> bloomFilterStrategies, String key, T value) {
int[] offset = bloomFilterStrategies.murmurHashOffset(value);
for (int i : offset) {
if (!jedis.getbit(key, i)) {
return false;
}
}
return true;
}
}
/**
* 布隆过滤器策略
*
* @author tony
* @date 2022/09/05
*/
public class BloomFilterStrategies<T> {
private int numHashFunctions;
private int bitSize;
private Funnel<T> funnel;
public BloomFilterStrategies(Funnel<T> funnel, int expectedInsertions, double fpp) {
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
bitSize = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
}
Rebloom插件方式实现布隆过滤器
Redis 官方提供的布隆过滤器到了 Redis 4.0 提供了插件功能之后才正式登场。布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。相关文档参考:https://github.com/RedisBloom/RedisBloom
$ git clone git://github.com/RedisLabsModules/rebloom
$ cd rebloom
$ make
cd /usr/redis
#加载module 并设置容量与容错率
# 容量100万, 容错率万分之一
./src/redis-server redis.conf --loadmodule /usr/rebloom/rebloom.so INITIAL_SIZE 1000000 ERROR_RATE 0.0001
Redis命令:
BF.ADD bloom redis
BF.EXISTS bloom redis
BF.EXISTS bloom nonxist

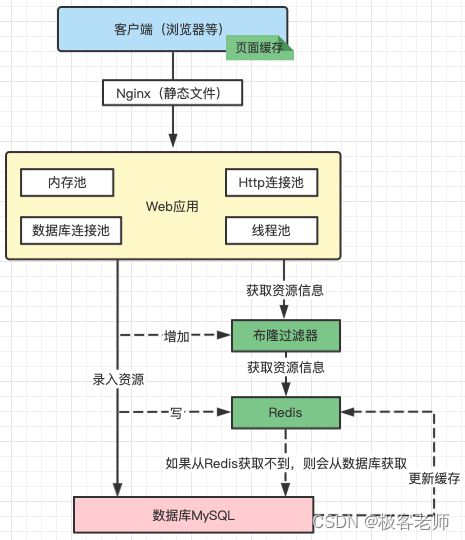
基于布隆过滤器解决缓存穿透
使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放。
// 初始化布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("sourceList");
// 初始化布隆过滤器:预计元素为100000000L,误差率为0.003
bloomFilter.tryInit(100000000L,0.003);
// 把所有数据存入布隆过滤器
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
从Redis缓存中获取数据前,先通过布隆过滤器判断缓存是否存在;然后再走前文描述的逻辑。
String getCacheValue(String key) {
// 先从布隆过滤器这一级缓存判断下key是否存在
Boolean exist = bloomFilter.contains(key);
if(!exist){
return "";
}
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 如果缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 则从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
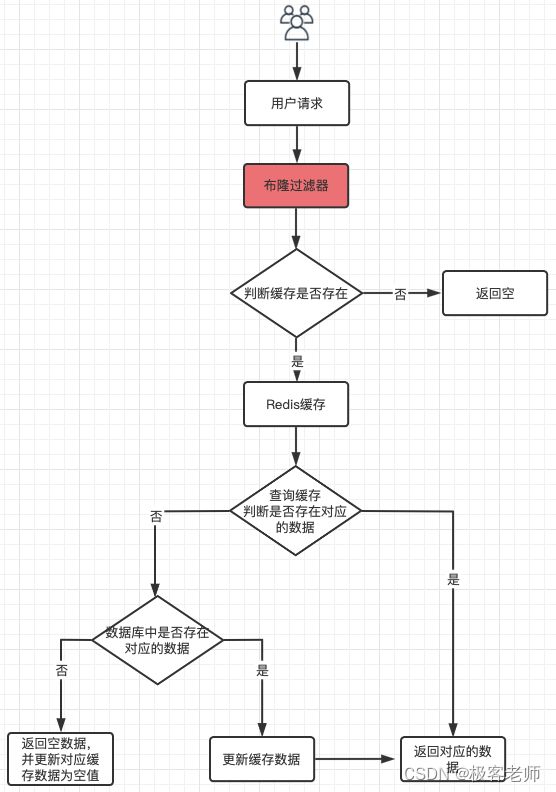
总结
布隆过滤器判断存在的不一定存在,但是判断不存在的一定不存在。Falase is always false. True is maybe true. 在高并发情况下,是避免缓存穿透的一把利器。