ETL基础知识
目录
一、 背景
二、 简介
三、 工作过程
四、 ETL包含的主要内容
数据抽取:
数据清洗:
数据转换:
数据加载:
五、 ETL & ELT
六、ETL开发介绍
七、 常见的ETL流程模板
1) Koala:
2) Delta Merge:
3) Sync:
一、 背景
随着企业的发展,各业务线、产品线、部门都会承建各种信息化系统方便开展自己的业务,业务系统之间各自为政、相互独立造成的“数据孤岛”现象尤为普遍,业务不集成、流程不互通、数据不共享。这给企业进行数据的分析利用、报表开发、分析挖掘等带来了巨大困难。在此情况下,为了实现企业全局数据的系统化运作管理(信息孤岛、数据统计、数据分析、数据挖掘) ,为DSS(决策支持系统)、BI(商务智能)、经营分析系统等深度开发应用奠定基础,挖掘数据价值 ,企业会开始着手建立数据仓库,数据中台。将相互分离的业务系统的数据源整合在一起,建立一个统一的数据采集、处理、存储、分发、共享中心。

二、 简介
ETL即Extract(抽取)、Transform(转换)、Load(装载);
抽取是将数据从各种原始的业务系统中读取出来,这是所有工作的前提。(从数据源source_meta中抽取)
转换是按照预先设计好的规则将抽取的数据进行转换,使本来异构的数据格式可以统一起来。
装载是将转换完的数据按计划增量或全部导入到数据仓库中。(向目标库target_meta中导入)
数据仓库架构图及ETL应用范围

三、 工作过程
提取来自一个或多个源的数据,然后将其复制到数据仓库。处理大量数据和多个源系统时,会合并数据。ETL用于将数据从一个数据库迁移到另一个数据库,并且通常是将数据加载到数据集市和数据仓库以及从数据集市(data marts)和数据仓库(data warehouses)加载数据所需的特定过程,并且这个过程也用于大量地将数据库从一种格式(类型)转换或改变成另一种。
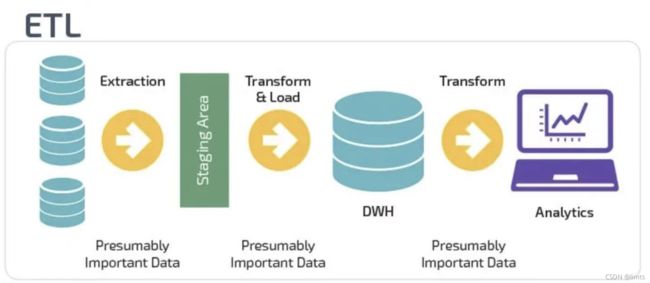
四、 ETL包含的主要内容
ETL处理分为几个主要模块,分别是:数据抽取、数据清洗、数据转换、数据加载。各模块可灵活进行组合,形成ETL处理流程。
数据抽取:
1) 对于与存放DW的数据库系统相同的数据源处理方法:这一类数据源在设计上比较容易。一般情况下,DBMS(SQLServer、Oracle)都会提供数据库链接功能,在DW数据库服务器和原业务系统之间建立直接的链接关系就可以写Select 语句直接访问。
2) 对于与DW数据库系统不同的数据源的处理方法:对于这一类数据源,一般情况下也可以通过ODBC的方式建立数据库链接——如SQL Server和Oracle之间。如果不能建立数据库链接,可以有两种方式完成,一种是通过工具将源数据导出成.txt或者是.xls文件,然后再将这些源系统文件导入到ODS中。另外一种方法是通过程序接口来完成。
3) 对于文件类型数据源(.txt,.xls):可以培训业务人员利用数据库工具将这些数据导入到指定的数据库,然后从指定的数据库中抽取。或者还可以借助工具实现。
4) 增量更新的问题:对于数据量大的系统,必须考虑增量抽取。一般情况下,业务系统会记录业务发生的时间,我们可以用来做增量的标志,每次抽取之前首先判断ODS中记录最大的时间,然后根据这个时间去业务系统取大于这个时间所有的记录。
数据清洗:
数据清洗的任务是过滤那些不符合要求的数据,具体分为不完整的数据、错误的数据、重复的数据三大类。
1) 不完整的数据:这一类数据主要是一些应该有的信息缺失。对于这一类数据过滤出来,要求在规定的时间内补全,补全后才写入数据仓库。
2) 错误的数据:这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
3)重复的数据:对于这一类数据需要将重复数据记录的所有字段导出来进行修改。
数据转换:
1) 不一致数据转换:这个过程是一个整合的过程,将不同业务系统的相同类型的数据统一,比如同一个供应商在结算系统的编码是XX0001,而在CRM中编码是YY0001,这样在抽取过来之后统一转换成一个编码。
2) 数据粒度的转换:业务系统一般存储非常明细的数据,而数据仓库中数据是用来分析的,不需要非常明细的数据。一般情况下,会将业务系统数据按照数据仓库粒度进行聚合。
3) 商务规则的计算:不同的企业有不同的业务规则、不同的数据指标,这些指标有的时候不是简单的加加减减就能完成,这个时候需要在ETL中将这些数据指标计算好了之后存储在数据仓库中,以供分析使用。
数据加载:
将数据缓冲区的数据直接加载到数据库对应表中,如果是全量方式则采用LOAD方式,如果是增量则根据业务规则MERGE进数据库
五、 ETL & ELT
ETL架构按其字面含义理解就是按照E-T-L这个顺序流程进行处理的架构:先抽取、然后转换、完成后加载到目标数据库中。在ETL架构中,数据的流向是从源数据流到ETL工具,ETL工具是一个单独的数据处理引擎,一般会在单独的硬件服务器上,实现所有数据转化的工作,然后将数据加载到目标数据仓库中。如果要增加整个ETL过程的效率,则需增强ETL工具服务器的配置,优化系统处理流程。
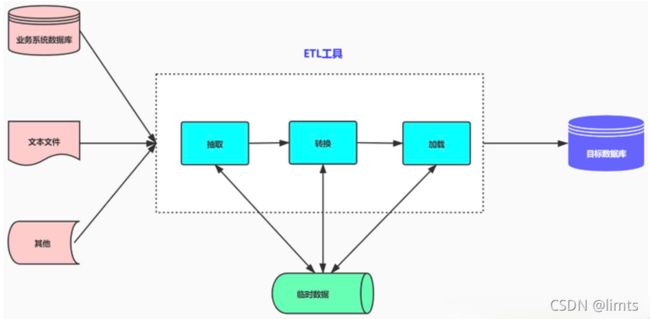
ELT只负责提供图形化的界面来设计业务规则,数据的整个加工过程都在目标和源数据库之间流动,ELT协调相关的数据库系统来执行相关的应用,数据加工过程既可以在源数据库端执行,也可以在目标数据仓库端执行(主要取决于系统的架构设计和数据属性)。当ETL过程需要提高效率,则可以通过对相关数据库进行调优,或者改变执行加工的服务器就可以达到。ELT 通常发生在 NoSQL 数据库中,具有处理非结构化数据的能力。

两种架构优势对比
ETL
ELT
可以分担数据库系统的负载(采用单独的硬件服务器)
充分利用数据库引擎来实现的可扩展性
相对于ELT架构可以实现更为复杂的数据转换逻辑
可以保持所有的数据始终在数据库当中,避免数据的加载和导出,从而保证效率,提高系统的可监控性
采用单独的硬件服务器
可以根据数据的分布情况进行并行处理优化,并可以利用数据库的固有功能优化磁盘I/O
与底层的数据库存储无关
通过对相关数据库进行性能调优,ELT过程获得3到4倍的效率提升比较容易
六、ETL开发介绍

七、 常见的ETL流程模板
1) Koala:
最常用的模板;支持所有的ETL流程类型
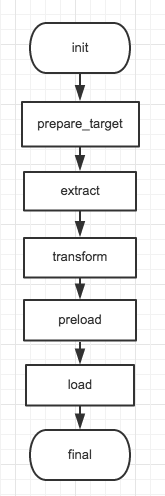
2) Delta Merge:
可以提供增量计算的方式,提高流程的运行效率;DeltaMerge模板支持的ETL流程目标表必须是hive表, 数据流基本可以分为两种mysql->hive, hive->hive。

3) Sync:
简化流程的编写,提高ETL开发效率;实现mysql-hive,mysql-mysql,hive-mysql的数据同步,源数据表和目标数据表的表包含的字段及属性基本一致(mysql和hive的字段属性不能完全一致,但不影响数据正确性)。
