GTP科普——简单入门资料
本文主要描述GPT模型的基本组成,如前所述,从GPT-1到GPT-3.5,它们模型的主要组成基本相同。我们提炼了这些通用组成模块于本文,方便大家可以更好的入门与了解GPT,包括GPT模型的训练目标函数、模型的基本结构,以及模型基本结构中的文本输入层、多头注意力层、前馈层等。
1 GPT目标函数
目标函数可以说是一个神经网络的灵魂,我们知道了目标函数就可以大体知道神经网络的工作机理。我们在第1章对GPT基本思想有了初步的了解,下面就介绍下GPT训练的目标函数,公式相对简单,方便我们更加直接的了解其原理。公式如下所示:


以第二步示例,其示意图如下。“晴空万里”是完整输入到GPT模型里的,只是GPT模型内部有一个控制,控制预测“万”的时候,只能看到“晴空”,看不到“里”字,这样从前到后依次预测训练。

上面的学习过程就是非监督学习,因为它没有依靠人工标注的数据,只是将完整的文本输入到GTP中,让GTP自己学习文字间的关系。当有大量的文本训练数据时,GPT就会自然而然的发现各种文字间的关系,就有了理解语言的能力。
2 GPT模型结构
GPT模型的整体结构如下图所示,包含输入层、多头注意力层、前馈层。其中输入层负责文本的加工,主要是将文本转换成向量(数组),方便机器进行学习;多头注意力层学习文本之间的关系,就像人类那样理解语言;前馈层(英文feedforward)输出要预测文本的概率,目标函数的最后输出就是依靠该层。下面的章节,我们将分别介绍下各层的具体构造。

3 文本输入层
我们知道计算机的世界只能处理0和1,那么文本又是如何处理的呢?尤其是在GPT中文本是如何处理的?本节就会讲下文本如何输入到GPT中,同时文本之间的顺序,也要输入到GPT中,这个顺序被称为位置编码。
3.1 文本编码
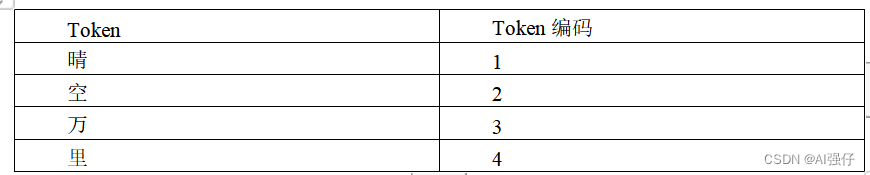
文本输入到GPT要经过两个步骤,其中第一步是将文字转换为Token。Token可以理解为最小单元的词或者字,比如“晴空万里”我们可以拆成4个Token,分别为“晴”、“空”、“万”、“里”。除此之外,我们还需要构建一个词汇表,其中包括所有的Token,我们要给每个Token编一个数字码,比如用“1”表示“晴”,“2”表示“空”等等,如下表所示:
第二步是将Token转换为词向量(embedding),或者理解成数组。词向量的流行主要是从2013年google团队推出的word2vec,其将单词映射到高维向量空间,这样更有益于丰富词的含义,同时方便学习词与词之间的复杂的关系。
在词向量流行前,有一种简单的向量(或数组)表示方式,叫one-hot,该表示方式更容易让读者理解向量。One-hot表示是将词语所在下标位置置为1,其他位置置为0。比如用长度为4的one-hot表示,具体表示如下表:
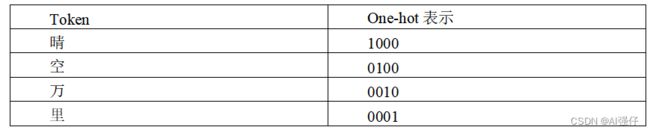
可以看到one-hot表示的向量(或数组),比较稀疏,即有很多的0;而且one-hot表示也缺乏语义信息的理解。所以就提出了非稀疏的表现方式,即embedding,用稠密的数组进行表示。比如GPT-1的词向量维度为768维。如下是一个30维的embedding示例:
[ 0.00501078 -0.02695217 0.00602702 0.00266289 0.03473682 0.0097171
0.01049457 0.04075214 -0.01465576 -0.03764923 0.02566164 -0.03778331
0.00713614 0.04891029 -0.04066588 0.04367645 0.02802004 0.03197568
-0.03032377 -0.04005457 0.04845554 0.04599163 0.03079205 0.00011758
0.0425863 0.01251983 -0.00086614 0.01517198 0.03247393 -0.0487391]
第一步的Token是不需要模型训练的,直接从词汇表中获得即可;而第二步的embedding是GPT在训练目标函数时学到的,也就是说每个单词的embedding是模型参数的一部分,可以理解为,每个单词的embedding就像我们人类大脑中存储单词的样子,需要学习得到。
3.2 位置编码
用位置编码(positional encoding)表示单词之间的顺序,比如“晴空万里”中每个字的位置分别为1、2、3、4。将位置编码输入到GPT模型中,有助于其更好的理解语言,就像“我爱你”和“你爱我”表达的意思是不一样的。
但实际上,我们不会直接将“1、2、3、4”这种绝对的位置编码输入到模型,而是采用更加复杂的形式,其中一种就是将位置编码也变成embedding形式,由GPT在模型训练中学习,如下图所示,输入的文本转换为文本编码加位置编码,然后再输入到GPT:

位置编码加入的另一个原因是下节讲到的注意力机制也没有考虑词语的顺序。实验结果也表明位置编码加入提升了模型的效果。
4 多头注意力层
从2017年Google提供自注意力(self-attention)模型Transformer开始,自然语言处理能力发生了非常大的变化,开启了一个新时代。GPT就采用了Transformer的编码器部分。本节我们会介绍下什么是注意力、多头注意力,以及GPT的Transformer编码器。
4.1 注意力机制
理解一个词语的含义,需要考虑上下文,比如“我画了一幅画”,“画”字在不同的地方表示不同的含义,一个是动词,一个是名词。注意力机制就是用来捕捉词与词之间关系的,它会考虑一句话中各个单词之间的互相关注程度、关系密切程度,有的关系密切会强些,有的关系密切会弱些。
还是以“晴空万里”为例,在已知“晴空”,又输入“万”字时,我们就会考虑“万”字和前面“晴”字和“空”字的关系,但“万”与“晴”、“空”关系密切程度不一样。如下面公式,认为“晴”与“万”字关系密切较小,只有0.3的比重;而“空”与“万”字关系密切较大,就0.7的比重。
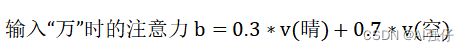
这个0.3、0.7就是注意力分数(attention score),表示“万”字与“晴”字、“空”字的注意力关注度、关系密切程度。分数越大,“万”字与它们的关系密切程度越大,内在联系越密切。


4.2 多头注意力
多头注意力增加了多个注意力,比如一个注意力的query可以关注文本自然科学方面的知识,另一个注意力的query关注文本社会科学方面的知识。
5 前馈层
我们知道GPT训练的是已知一句话的前面几个文字(),后面出现某个文字()的概率。所以前馈层主要是输出这个概率。最主要的就是softmax函数了。softmax函数将输出的每一个元素的范围都压缩在(0,1)之间,并且所有输出元素的和为1,即所有可能出现的文字概率和为1。最终我们会取概率最大那个输出元素。