虚拟机(CentOS)下安装配置Hadoop(伪分布式)
一、hadoop相关介绍
- hadoop是由Apache开发的分布式系统基础架构,是利用集群对大量数据进行分布式处理和存储的软件框架。用户可以轻松地在Hadoop集群上开发和运行处理海量数据的应用程序。Hadoop有高可靠,高扩展,高效性,高容错等优点。
- Hadoop框架最核心的设计就是HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算。此外,Hadoop还包括了Hive,Hbase,ZooKeeper,Pig,Avro,Sqoop,Flume,Mahout等项目。Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,完全分布运行模式。
- hadoop的三种模式
(1)本地模式(local mode)
这种运行模式在一台单机上运行,没有HDFS分布式文件系统,而是直接读写本地操作系统中的文件系统。在本地运行模式(local mode)中不存在守护进程,所有进程都运行在一个JVM上。单机模式适用于开发阶段运行MapReduce程序,这也是最少使用的一个模式。
(2)伪分布模式
这种运行模式是在单台服务器上模拟Hadoop的完全分布模式,单机上的分布式并不是真正的分布式,而是使用线程模拟的分布式。在这个模式中,所有守护进程(NameNode,DataNode,ResourceManager,NodeManager,SecondaryNameNode)都在同一台机器上运行。因为伪分布运行模式的Hadoop集群只有一个节点,所以HDFS中的块复制将限制为单个副本,其
secondary-master和slave也都将运行于本地主机。此种模式除了并非真正意义的分布式之外,其程序执行逻辑完全类似于完全分布式,因此,常用于开发人员测试程序的执行。
(3)完全分布模式
这种模式通常被用于生产环境,使用N台主机组成一个Hadoop集群,Hadoop守护进程运行在每台主机之上。这里会存在Namenode运行的主机,Datanode运行的主机,以及
SecondaryNameNode运行的主机。在完全分布式环境下,主节点和从节点会分开。
二、伪分布模式安装步骤
- 创建一个新用户及用户组,后续操作基本都是在此用户下来操作的。也可以直接在自己的非root用户下操作。创建新用户qingqing,并为其创建home目录。
sudo useradd -d /home/qingqing -m qingqing
为新账户设置密码,输入及确认密码即可。
sudo passwd qingqing
将qingqing用户权限提升到sudo超级用户级别。
sudo usermod -G sudo qingqing
若出现“sudo”不存在或者xx不在sudoers文件中,此时将被报告。
说明sudoers文件由于某种原因写入失败了
解决方法:vi /etc/sudoers 把root ALL=(ALL) ALL 复制一下,把root改成你自己的用户名即可。
编写完保存后,查看用户是否是sudoer
sudo -l -U username
若出现下图所示结果,则用户可以使用sudo访问运行所有命令。


后续操作切换到qingqing用户下操作。
- 配置SSH免密登陆。SSH免密码登陆需要在服务器执行以下命令,生成公钥和私钥对。
ssh-keygen -t rsa
此时会有多处提醒输入在冒号后输入文本,这里主要是要求输入ssh密码以及密码的放置位置。在这里,只需要使用默认值,按回车即可。
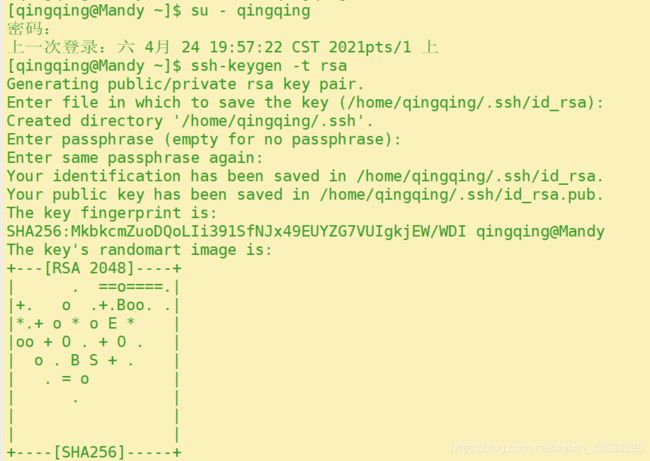
此时ssh公钥和私钥已经生成完毕,且放置在 ~ /.ssh目录下。
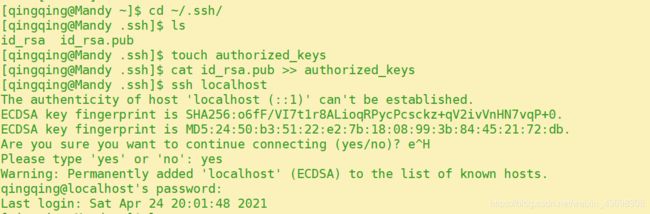
在~/.ssh目录下,创建一个空文本,名为authorized_keys
touch ~/ .ssh/ authorized_keys
将存储公钥文件的id_rsa.pub里的内容,追加到authorized_keys中
cat ~ / .ssh/id_rsa.pub >> ~/ .ssh/authorized_keys
执行ssh localhost测试ssh配置是否正确
ssh localhost
第一次使用ssh访问,会提醒是否继续连接,输入“yes"继续进行,执行完以后退出。后续再执行ssh localhost时,就不用输入密码了。
- 创建目录apps和data,/apps目录用来存放安装的框架,/data目录用来存放临时数据、HDFS数据、程序代码或脚本。
并为/apps和/data目录切换所属的用户为qingqing及用户组为qingqing,并查看。
sudo mkdir / apps
sudo mkdir /data
sudo chown -R qingqing : qingqing /apps
sudo chown -R qingqing : qingqing /data

- 配置HDFS。创建/data/hadoop1目录,用来存放相关安装工具。我安装的是hadoop-2.7.6.tar.gz jdk-8u171-linux-x64.tar.gz。(利用传输工具FIleZillaClient将本地压缩包传输至虚拟机,不了解的看文章的最后。)
mkdir /data/hadoop1
- 安装jdk和hadoop。将/data/hadoop1目录下hadoop和jdk的压缩包解压缩到/apps目录下,并重命名
tar -zxvf hadoop-2.7.6.tar.gz /apps/
tar -zxvf jdk-8u171-linux-x64.tar.gz /apps
mv /apps/jdk1.8.0_171 /apps/java
mv /apps/hadoop-2.7.6 /apps/hadoop
- 修改环境变量:系统变量或用户环境变量.此处修改用环境变量。
打开存储环境变量的文件。将java、hadoop的环境变量追加进用户环境变量,按i编辑,编辑完按ESC,:wq退出。追加完后使环境生效。
sudo vim ~/.bashrc
#java
export JAVA_HOME=/apps/java
export PATH=$JAVA_HOME/bin:$PATH
#hadoop
export HADOOP_HOME=/apps/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
source ~/.bashrc
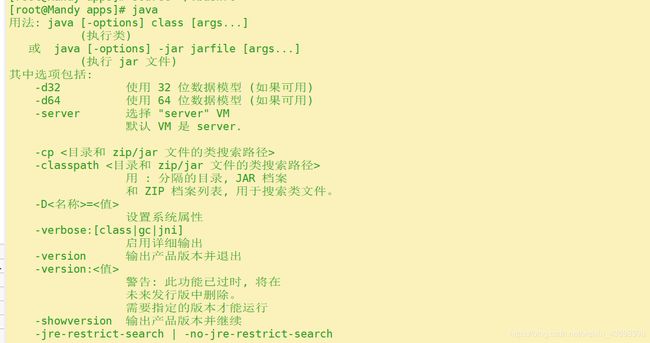
测试java环境是否成功:
java
若出现下图,说明配置成功 。
测试hadoop环境变量是否成功:
hadoop version
若出现hadoop的版本号及相关信息则说明配置成功。

7.修改hadoop本身相关配置。
切换到hadoop配置目录下
cd /apps/hadoop/etc/hadoop
7.1配置hadoop-env.sh:
将export JAVA_HOME=/apps/java 配置到hadoop-env.sh.
按i编辑,编辑完按ESC,:wq退出。
vim /apps/hadoop/etc/hadoop/hadoop-env.sh
7.2配置core-site.xml:
提前创建临时文件的存储位置
mkdir -p /data/tmp/hadoop/tmp
将
<property>
<name>hadoop.tmp.dir</name>
<value>/data/tmp/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000
</property>
配置到core-site.xml的与标签之间。编辑操作同上
vim /apps/hadoop/etc/hadoop/core-site.xml
7.3配置hdfs-site.xml:
提前创建/data/tmp/hadoop/hdfs路径
mkdir -p /data/tmp/hadoop/hdfs
将
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/tmp/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/tmp/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
配置解释:
dfs.namenode.name.dir,配置元数据信息存储位置;dfs.datanode.data.dir,配置具体数据存储位置;
dfs.replication,配置每个数据库备份数,由于目前使用1台节点,所以,设置为1
dfs.permissions.enabled,配置hdfs是否启用权限认证
配置到hdfs-site.xml的与标签之间。编辑操作同上
vim /apps/hadoop/etc/hadoop/hdfs-site.xml
7.4配置slaves
将集群中slave角色的节点的主机名,添加进slaves文件中。目前只有一台节点,所以slaves文件内容为:localhost 编辑操作同上
vim /apps/hadoop/etc/hadoop/slaves
格式化HDFS
hadoop namenode -format
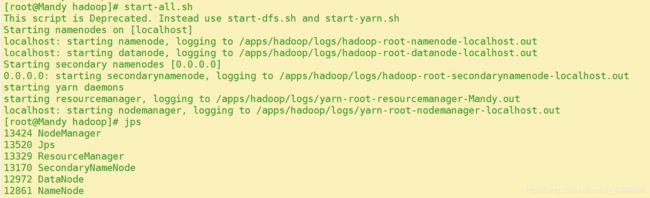
切换目录,启动hadoop的hdfs相关进程
cd /apps/hadoop/sbin/
./start-dfs.sh
查看hdfs相关进程是否已经启动
jps
结果如下图:NameNode、DataNode和SecondaryNameNode均已启动。
进一步验证HDFS运行状态,创建一个目录,并查看。
hadoop fs -mkdir /first
hadoop fs -ls /
结果如下:

至此hadoop伪分布式安装成功!
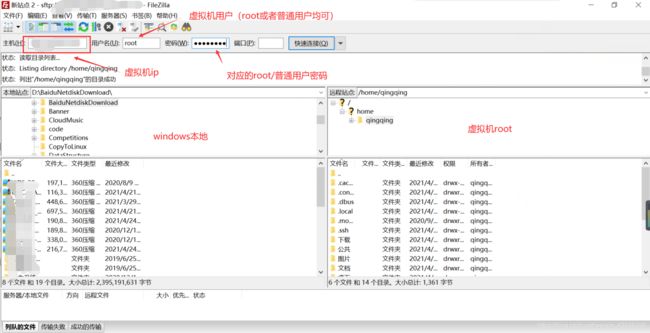
利用传输工具FIleZillaClient将本地压缩包传输至虚拟机
FileZilla是一个免费开源的FTP软件,分为客户端版本和服务器版本,具备所有的FTP软件功能。
使用FileZilla客户端,将本地windows系统上的文件,传到虚拟机上。
下载地址:https://filezilla-project.org/
安装完打开,输入虚拟机ip(可通过ifconfig查看ip)、用户名、用户密码连接虚拟机。先选好存放的虚拟机路径,再双击要传输的文件,即可传输至虚拟机。
希望能对你有所帮助,感谢观看!