数据湖架构Hudi(四)Hudi集成Spark案例详解
四、Hudi集成Spark案例详解
之前在hudi快速入门程序中,简单体验了一下spark集成hudi,现在详细讲解下。
数据湖架构Hudi(二)Hudi版本0.12源码编译、Hudi集成spark、使用IDEA与spark对hudi表增删改查
4.1 使用spark-shell方式
# 启动命令行
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
4.1.1 插入数据
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "hdfs://192.168.42.104:9000/datas/hudi_warehouse/hudi_trips_cow"
val dataGen = new DataGenerator
# 不需要单独的建表。如果表不存在,第一批写表将创建该表。(默认是COW表)
# 新增数据,使用官方提供的工具类生成一些Trips乘车数据,将其加载到DataFrame中,然后将DataFrame写入Hudi表。
# Mode(overwrite)将覆盖重新创建表(如果已存在)。
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
4.1.2 查询数据
# 注意:该表有三级分区(区域/国家/城市),在0.9.0版本以前的hudi,在load中的路径需要按照分区目录拼接"*",如:load(basePath + "/*/*/*/*"),当前版本不需要。
# 1、转换为df
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
# 2、进行查询
scala> spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
+------------------+-------------------+-------------------+-------------+
| fare| begin_lon| begin_lat| ts|
+------------------+-------------------+-------------------+-------------+
| 64.27696295884016| 0.4923479652912024| 0.5731835407930634|1677600005195|
| 27.79478688582596| 0.6273212202489661|0.11488393157088261|1677240470730|
| 93.56018115236618|0.14285051259466197|0.21624150367601136|1677696170708|
| 33.92216483948643| 0.9694586417848392| 0.1856488085068272|1677272458691|
| 43.4923811219014| 0.8779402295427752| 0.6100070562136587|1677360474147|
| 66.62084366450246|0.03844104444445928| 0.0750588760043035|1677583109653|
|34.158284716382845|0.46157858450465483| 0.4726905879569653|1677602421735|
| 41.06290929046368| 0.8192868687714224| 0.651058505660742|1677721939334|
+------------------+-------------------+-------------------+-------------+
# 3、查询hudi多出来的几个字段
scala> spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
+-------------------+--------------------+----------------------+---------+----------+------------------+
|_hoodie_commit_time| _hoodie_record_key|_hoodie_partition_path| rider| driver| fare|
+-------------------+--------------------+----------------------+---------+----------+------------------+
| 20230302191855836|16df8361-18cd-461...| americas/united_s...|rider-213|driver-213| 64.27696295884016|
| 20230302191855836|d2bb2448-1e1f-45f...| americas/united_s...|rider-213|driver-213| 27.79478688582596|
| 20230302191855836|8d1b3b83-e88c-45e...| americas/united_s...|rider-213|driver-213| 93.56018115236618|
| 20230302191855836|ce2b0518-1875-48b...| americas/united_s...|rider-213|driver-213| 33.92216483948643|
| 20230302191855836|a5b03e52-31c7-4f9...| americas/united_s...|rider-213|driver-213|19.179139106643607|
| 20230302191855836|30263e49-3c95-489...| americas/brazil/s...|rider-213|driver-213| 43.4923811219014|
| 20230302191855836|dd70365d-5345-4d3...| americas/brazil/s...|rider-213|driver-213| 66.62084366450246|
| 20230302191855836|ff01ba9d-92f0-410...| americas/brazil/s...|rider-213|driver-213|34.158284716382845|
| 20230302191855836|4d4e2563-bc21-4e6...| asia/india/chennai|rider-213|driver-213|17.851135255091155|
| 20230302191855836|3c495316-233e-418...| asia/india/chennai|rider-213|driver-213| 41.06290929046368|
+-------------------+--------------------+----------------------+---------+----------+------------------+
# 4、时间旅行查询
Hudi从0.9.0开始就支持时间旅行查询。目前支持三种查询时间格式,如下所示。
spark.read.
format("hudi").
option("as.of.instant", "20230302191855836").
load(basePath).show(10)
spark.read.
format("hudi").
option("as.of.instant", "2023-03-02 19:18:55.836").
load(basePath).show(10)
# 表示 "as.of.instant = 2023-03-02 00:00:00"
spark.read.
format("hudi").
option("as.of.instant", "2023-03-02").
load(basePath).show(10)
4.1.3 更新数据
# 更新前数据
scala> spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
+-------------------+--------------------+----------------------+---------+----------+------------------+
|_hoodie_commit_time| _hoodie_record_key|_hoodie_partition_path| rider| driver| fare|
+-------------------+--------------------+----------------------+---------+----------+------------------+
| 20230302191855836|16df8361-18cd-461...| americas/united_s...|rider-213|driver-213| 64.27696295884016|
| 20230302191855836|d2bb2448-1e1f-45f...| americas/united_s...|rider-213|driver-213| 27.79478688582596|
| 20230302191855836|8d1b3b83-e88c-45e...| americas/united_s...|rider-213|driver-213| 93.56018115236618|
| 20230302191855836|ce2b0518-1875-48b...| americas/united_s...|rider-213|driver-213| 33.92216483948643|
| 20230302191855836|a5b03e52-31c7-4f9...| americas/united_s...|rider-213|driver-213|19.179139106643607|
| 20230302191855836|30263e49-3c95-489...| americas/brazil/s...|rider-213|driver-213| 43.4923811219014|
| 20230302191855836|dd70365d-5345-4d3...| americas/brazil/s...|rider-213|driver-213| 66.62084366450246|
| 20230302191855836|ff01ba9d-92f0-410...| americas/brazil/s...|rider-213|driver-213|34.158284716382845|
| 20230302191855836|4d4e2563-bc21-4e6...| asia/india/chennai|rider-213|driver-213|17.851135255091155|
| 20230302191855836|3c495316-233e-418...| asia/india/chennai|rider-213|driver-213| 41.06290929046368|
+-------------------+--------------------+----------------------+---------+----------+------------------+
# 更新数据
# 类似于插入新数据,使用数据生成器生成(注意是同一个数据生成器对象)新数据对历史数据进行更新。将数据加载到DataFrame中并将DataFrame写入Hudi表中。
val updates = convertToStringList(dataGen.generateUpdates(5))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
# 注意:保存模式现在是Append。通常,除非是第一次创建表,否则请始终使用追加模式。
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
# 再次查询
# 1、转换为df
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
# 更新后数据
scala> spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
+-------------------+--------------------+----------------------+---------+----------+------------------+
|_hoodie_commit_time| _hoodie_record_key|_hoodie_partition_path| rider| driver| fare|
+-------------------+--------------------+----------------------+---------+----------+------------------+
| 20230302194751288|16df8361-18cd-461...| americas/united_s...|rider-243|driver-243|14.503019204958845|
| 20230302194751288|d2bb2448-1e1f-45f...| americas/united_s...|rider-243|driver-243| 51.42305232303094|
| 20230302194751288|8d1b3b83-e88c-45e...| americas/united_s...|rider-243|driver-243|26.636532270940915|
| 20230302194716880|ce2b0518-1875-48b...| americas/united_s...|rider-284|driver-284| 90.9053809533154|
| 20230302191855836|a5b03e52-31c7-4f9...| americas/united_s...|rider-213|driver-213|19.179139106643607|
| 20230302194751288|30263e49-3c95-489...| americas/brazil/s...|rider-243|driver-243| 89.45841313717807|
| 20230302194751288|dd70365d-5345-4d3...| americas/brazil/s...|rider-243|driver-243|2.4995362119815567|
| 20230302194716880|ff01ba9d-92f0-410...| americas/brazil/s...|rider-284|driver-284| 29.47661370147079|
| 20230302194751288|4d4e2563-bc21-4e6...| asia/india/chennai|rider-243|driver-243| 71.08018349571618|
| 20230302194716880|3c495316-233e-418...| asia/india/chennai|rider-284|driver-284| 9.384124531808036|
+-------------------+--------------------+----------------------+---------+----------+------------------+
4.1.4 增量查询
Hudi还提供了增量查询的方式,可以获取从给定提交时间戳以来更改的数据流。需要指定增量查询的beginTime,选择性指定endTime。如果我们希望在给定提交之后进行所有更改,则不需要指定endTime(这是常见的情况)。
# 1、加载数据
spark.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
# 2、获取指定beginTime
scala> val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
commits: Array[String] = Array(20230302210112648, 20230302210408496)
scala> val beginTime = commits(commits.length - 2)
beginTime: String = 20230302210112648
# 3、创建增量查询的表
val tripsIncrementalDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
# 4、查询增量表
scala> spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare < 20.0").show()
+-------------------+-----------------+-------------------+------------------+-------------+
|_hoodie_commit_time| fare| begin_lon| begin_lat| ts|
+-------------------+-----------------+-------------------+------------------+-------------+
| 20230302210408496|60.34474295461695|0.03363698727131392|0.9886806054385373|1677343847695|
| 20230302210408496| 57.4289850003576| 0.9692506010574379|0.9566270007622102|1677699656426|
+-------------------+-----------------+-------------------+------------------+-------------+
4.1.5 指定时间点查询
# 查询特定时间点的数据,可以将endTime指向特定时间,beginTime指向000(表示最早提交时间)
# 1)指定beginTime和endTime
val beginTime = "000"
val endTime = commits(commits.length - 2)
# 2)根据指定时间创建表
val tripsPointInTimeDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
option(END_INSTANTTIME_OPT_KEY, endTime).
load(basePath)
tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")
# 3)查询
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").show()
+-------------------+-----------------+------------------+-------------------+-------------+
|_hoodie_commit_time| fare| begin_lon| begin_lat| ts|
+-------------------+-----------------+------------------+-------------------+-------------+
| 20230302210112648|75.67233311397607|0.7433519787065044|0.23986563259065297|1677257554148|
| 20230302210112648|72.88363497900701|0.6482943149906912| 0.682825302671212|1677446496876|
| 20230302210112648|41.57780462795554|0.5609292266131617| 0.6718059599888331|1677230346940|
| 20230302210112648|69.36363684236434| 0.621688297381891|0.13625652434397972|1677277488735|
| 20230302210112648|43.51073292791451|0.3953934768927382|0.39178349695388426|1677567017799|
| 20230302210112648|62.79408654844148|0.8414360533180016| 0.9115819084017496|1677314954780|
| 20230302210112648|66.06966684558341|0.7598920002419857| 0.1591418101835923|1677428809403|
| 20230302210112648|63.30100459693087|0.4878809010360382| 0.6331319396951335|1677336164167|
+-------------------+-----------------+------------------+-------------------+-------------+
4.1.6 删除数据
根据传入的HoodieKeys来删除(uuid + partitionpath),只有append模式,才支持删除功能。
# 1)获取总行数
scala> spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
res50: Long = 10
# 2)取其中2条用来删除
val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2)
# 3)将待删除的2条数据构建DF
val deletes = dataGen.generateDeletes(ds.collectAsList())
val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2))
# 4)执行删除
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY,"delete").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
# 5)统计删除数据后的行数,验证删除是否成功
val roAfterDeleteViewDF = spark.
read.
format("hudi").
load(basePath)
roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot")
// 返回的总行数应该比原来少2行
scala> spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
res53: Long = 8
4.1.7 覆盖数据
对于表或分区来说,如果大部分记录在每个周期都发生变化,那么做upsert或merge的效率就很低。我们希望类似hive的 "insert overwrite "操作,以忽略现有数据,只用提供的新数据创建一个提交。
也可以用于某些操作任务,如修复指定的问题分区。我们可以用源文件中的记录对该分区进行’插入覆盖’。对于某些数据源来说,这比还原和重放要快得多。
Insert overwrite操作可能比批量ETL作业的upsert更快,批量ETL作业是每一批次都要重新计算整个目标分区(包括索引、预组合和其他重分区步骤)。
# 1)查看当前表的key
scala> spark.
| read.format("hudi").
| load(basePath).
| select("uuid","partitionpath").
| sort("partitionpath","uuid").
| show(100, false)
+------------------------------------+------------------------------------+
|uuid |partitionpath |
+------------------------------------+------------------------------------+
|0a47c845-fb42-4187-af27-a85e6229a3c3|americas/brazil/sao_paulo |
|6f82914d-f7a0-4972-8691-d1404ed7cae3|americas/brazil/sao_paulo |
|e2d4fa5b-da34-4603-85c3-d2ad884ac090|americas/brazil/sao_paulo |
|26e8db50-755c-44e7-9200-988a78c1e5de|americas/united_states/san_francisco|
|5afb905d-7ed2-46f5-bba8-5e2fb8ac88da|americas/united_states/san_francisco|
|2947db75-fa72-43d5-993c-4530b9890c73|asia/india/chennai |
|74f3ec44-62fa-435f-b06c-4cb9e0f4defa|asia/india/chennai |
|f22b8c1c-7b57-4c5f-8bce-7ce6783047b0|asia/india/chennai |
+------------------------------------+------------------------------------+
# 2)生成一些新的行程数据
val inserts = convertToStringList(dataGen.generateInserts(2))
val df = spark.
read.json(spark.sparkContext.parallelize(inserts, 2)).
filter("partitionpath = 'americas/united_states/san_francisco'")
# 3)覆盖指定分区
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION.key(),"insert_overwrite").
option(PRECOMBINE_FIELD.key(), "ts").
option(RECORDKEY_FIELD.key(), "uuid").
option(PARTITIONPATH_FIELD.key(), "partitionpath").
option(TBL_NAME.key(), tableName).
mode(Append).
save(basePath)
# 4)查询覆盖后的key,发生了变化
spark.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)
+------------------------------------+------------------------------------+
|uuid |partitionpath |
+------------------------------------+------------------------------------+
|0a47c845-fb42-4187-af27-a85e6229a3c3|americas/brazil/sao_paulo |
|6f82914d-f7a0-4972-8691-d1404ed7cae3|americas/brazil/sao_paulo |
|e2d4fa5b-da34-4603-85c3-d2ad884ac090|americas/brazil/sao_paulo |
|ea2fe685-ad87-4bba-b688-4436f729e005|americas/united_states/san_francisco|
|2947db75-fa72-43d5-993c-4530b9890c73|asia/india/chennai |
|74f3ec44-62fa-435f-b06c-4cb9e0f4defa|asia/india/chennai |
|f22b8c1c-7b57-4c5f-8bce-7ce6783047b0|asia/india/chennai |
+------------------------------------+------------------------------------+
4.2 使用spark-sql方式
4.2.1 Hive3.1.2的安装
hive3.1.2的连接地址 http://archive.apache.org/dist/hive/hive-3.1.2/
1、下载后上传到/opt/apps下
2、解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz
3、重命名
mv apache-hive-3.1.2-bin hive-3.1.2
4、执行以下命令,修改hive-site.xml
cd /opt/apps/hive-3.1.2/conf
mv hive-default.xml.template hive-default.xml
5、执行以下命令,新建一个hive-site.xml配置文件
vim hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://centos04:3306/hive?useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>hive.metastore.event.db.notification.api.authname>
<value>falsevalue>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://centos04:9083value>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>centos04value>
property>
<property>
<name>hive.server2.thrift.portname>
<value>10000value>
property>
configuration>
6、配置hadoop
在hadoop 的core-site.xml添加如下内容,然后重启
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>rootvalue>
<description>Allow the superuser oozie to impersonate any members of the group group1 and group2description>
property>
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
<description>The superuser can connect only from host1 and host2 to impersonate a userdescription>
property>
7、hive内依赖的guava.jar和hadoop内版本不一致
# hadoop3.1.3的guava版本是27,而hive3.1.2版本是19
# 两者不一致,则删除低版本的,把高版本的复制过去。
rm -rf /opt/apps/hive-3.1.2/lib/guava-19.0.jar
cp /opt/apps/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar /opt/apps/hive-3.1.2/lib
8、配置hive元数据库在mysql
1.首先下载mysql jdbc包
2.把它复制到hive/lib目录下。
3.启动并登陆mysql
4.将hive数据库下的所有表的所有权限赋给root用户,并配置123456为hive-site.xml中的连接密码,然后``刷新系统权限关系表
mysql> create database hive;
mysql> CREATE USER 'root'@'%' IDENTIFIED BY '123456';
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
mysql> flush privileges;
-- 初始化Hive元数据库
[root@centos04 conf]# schematool -initSchema -dbType mysql -verbose
9、启动Hive的Metastore
# 配置环境变量
export HIVE_HOME=/opt/apps/hive-3.1.2
# 启动Hive
[root@centos04 conf]# nohup hive --service metastore &
[root@centos04 conf]# netstat -nltp | grep 9083
tcp6 0 0 :::9083 :::* LISTEN 10282/java
10 、启动Hive
# 先启动hadoop集群
start-dfs.sh
# 启动hadoop集群后,要等hdfs退出安全模式之后再启动hive。
[root@centos04 conf]# hive
# 启动远程连接
[root@centos04 ~]# hiveserver2 &
[root@centos04 ~]# netstat -nltp | grep 10000
tcp6 0 0 :::10000 :::* LISTEN 10589/java
[root@centos04 ~]# netstat -nltp | grep 10002
tcp6 0 0 :::10002 :::* LISTEN 10589/java
beeline
!connect jdbc:hive2://centos04:10000
输入用户名 root
输入密码 回车
4.2.2 使用spark-sql创建hudi表
# 启动命令行窗口
spark-sql \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
注意:如果没有配置hive环境变量,手动拷贝hive-site.xml到spark的conf下
| 参数名 | 默认值 | 说明 |
|---|---|---|
| primaryKey | uuid | 表的主键名,多个字段用逗号分隔。同 hoodie.datasource.write.recordkey.field |
| preCombineField | 表的预合并字段。同 hoodie.datasource.write.precombine.field |
|
| type | cow | 创建的表类型: type = ‘cow’ type = ‘mor’ 同hoodie.datasource.write.table.type |
4.2.2.1 创建非分区表
use hudi_spark;
-- 创建一个cow表,默认primaryKey 'uuid',不提供preCombineField
create table hudi_cow_nonpcf_tbl (
uuid int,
name string,
price double
) using hudi;
-- 默认创建的路径为本地,/root/spark-warehouse/hudi_spark.db/hudi_cow_nonpcf_tbl
-- 创建一个mor非分区表
create table hudi_mor_tbl (
id int,
name string,
price double,
ts bigint
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'ts'
);
4.2.2.2 创建分区表
-- 创建一个cow分区外部表,指定primaryKey和preCombineField
create table hudi_cow_pt_tbl (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location 'hdfs://192.168.42.104:9000/datas/hudi_warehouse/spark_sql/hudi_cow_pt_tbl';
4.2.2.3 在已有的hudi表上创建新表
-- 不需要指定模式和非分区列(如果存在)之外的任何属性,Hudi可以自动识别模式和配置。
-- 非分区表(依据本地存在的路径进行创建)
create table hudi_existing_tbl0 using hudi
location 'file:///root/spark-warehouse/hudi_spark.db/hudi_cow_nonpcf_tbl';
-- 分区表(依据hdfs上存在的路径进行创建,如果没有数据会报错)
-- It is not allowed to specify partition columns when the table schema is not defined
create table hudi_existing_tbl1 using hudi
partitioned by (dt, hh)
location 'hdfs://192.168.42.104:9000/datas/hudi_warehouse/spark_sql/hudi_cow_pt_tbl';
4.2.2.4 通过CTAS (Create Table As Select)建表
-- 为了提高向hudi表加载数据的性能,CTAS使用批量插入作为写操作。
--(1)通过CTAS创建cow非分区表,不指定preCombineField
create table hudi_ctas_cow_nonpcf_tbl
using hudi
tblproperties (primaryKey = 'id')
as
select 1 as id, 'a1' as name, 10 as price;
-- (2)通过CTAS创建cow分区表,指定preCombineField
create table hudi_ctas_cow_pt_tbl
using hudi
tblproperties (type = 'cow', primaryKey = 'id', preCombineField = 'ts')
partitioned by (dt)
as
select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-12-01' as dt;
-- (3)通过CTAS从其他表加载数据
# 创建内部表
create table parquet_mngd using parquet location 'file:///tmp/parquet_dataset/*.parquet';
# 通过CTAS加载数据
create table hudi_ctas_cow_pt_tbl2 using hudi location 'file:/tmp/hudi/hudi_tbl/' options (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (datestr) as select * from parquet_mngd;
4.2.3 插入数据
默认情况下,如果提供了preCombineKey,则insert into的写操作类型为upsert,否则使用insert。
-- 1)向非分区表插入数据
insert into hudi_cow_nonpcf_tbl select 1, 'a1', 20;
insert into hudi_mor_tbl select 1, 'a1', 20, 1000;
-- 2)向分区表动态分区插入数据
insert into hudi_cow_pt_tbl partition (dt, hh)
select 1 as id, 'a1' as name, 1000 as ts, '2021-12-09' as dt, '10' as hh;
-- 3)向分区表静态分区插入数据
insert into hudi_cow_pt_tbl partition(dt = '2021-12-09', hh='11') select 2, 'a2', 1000;
-- 4)使用bulk_insert插入数据
-- hudi支持使用bulk_insert作为写操作的类型,只需要设置两个配置:
-- hoodie.sql.bulk.insert.enable和hoodie.sql.insert.mode。
-- 向指定preCombineKey的表插入数据,则写操作为upsert
insert into hudi_mor_tbl select 1, 'a1_1', 20, 1001;
select id, name, price, ts from hudi_mor_tbl;
1 a1_1 20.0 1001
-- 向指定preCombineKey的表插入数据,指定写操作为bulk_insert(此时不会更新数据)
set hoodie.sql.bulk.insert.enable=true;
set hoodie.sql.insert.mode=non-strict;
insert into hudi_mor_tbl select 1, 'a1_2', 20, 1002;
select id, name, price, ts from hudi_mor_tbl;
1 a1_1 20.0 1001
1 a1_2 20.0 1002
4.2.4 查询数据
-- 1)查询
select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0
-- 2)时间旅行查询
Hudi从0.9.0开始就支持时间旅行查询。Spark SQL方式要求Spark版本 3.2及以上。
create table hudi_cow_pt_tbl1 (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/tmp/hudi/hudi_cow_pt_tbl1';
-- 插入一条id为1的数据
insert into hudi_cow_pt_tbl1 select 1, 'a0', 1000, '2021-12-09', '10';
select * from hudi_cow_pt_tbl1;
-- 修改id为1的数据
insert into hudi_cow_pt_tbl1 select 1, 'a1', 1001, '2021-12-09', '10';
select * from hudi_cow_pt_tbl1;
-- 基于第一次提交时间进行时间旅行
select * from hudi_cow_pt_tbl1 timestamp as of '20230303013452312' where id = 1;
-- 其他时间格式的时间旅行写法
select * from hudi_cow_pt_tbl1 timestamp as of '2023-03-03 01:34:52.312' where id = 1;
select * from hudi_cow_pt_tbl1 timestamp as of '2023-03-03' where id = 1;
4.2.5 更新数据
-- 1)update
更新操作需要指定preCombineField。
(1)语法
UPDATE tableIdentifier SET column = EXPRESSION(,column = EXPRESSION) [ WHERE boolExpression]
(2)执行更新
update hudi_mor_tbl set price = price * 2, ts = 1111 where id = 1;
update hudi_cow_pt_tbl1 set name = 'a1_1', ts = 1001 where id = 1;
-- update using non-PK field
update hudi_cow_pt_tbl1 set ts = 1111 where name = 'a1_1';
-- 2)MergeInto
(1)语法
MERGE INTO tableIdentifier AS target_alias
USING (sub_query | tableIdentifier) AS source_alias
ON <merge_condition>
[ WHEN MATCHED [ AND <condition> ] THEN <matched_action> ]
[ WHEN MATCHED [ AND <condition> ] THEN <matched_action> ]
[ WHEN NOT MATCHED [ AND <condition> ] THEN <not_matched_action> ]
<merge_condition> =A equal bool condition
<matched_action> =
DELETE |
UPDATE SET * |
UPDATE SET column1 = expression1 [, column2 = expression2 ...]
<not_matched_action> =
INSERT * |
INSERT (column1 [, column2 ...]) VALUES (value1 [, value2 ...])
(2)执行案例
-- 1、准备source表:非分区的hudi表,插入数据
create table merge_source (id int, name string, price double, ts bigint) using hudi
tblproperties (primaryKey = 'id', preCombineField = 'ts');
insert into merge_source values (1, "old_a1", 22.22, 2900), (2, "new_a2", 33.33, 2000), (3, "new_a3", 44.44, 2000);
merge into hudi_mor_tbl as target
using merge_source as source
on target.id = source.id
when matched then update set *
when not matched then insert *
;
-- 2、准备source表:分区的parquet表,插入数据
create table merge_source2 (id int, name string, flag string, dt string, hh string) using parquet;
insert into merge_source2 values (1, "new_a1", 'update', '2021-12-09', '10'), (2, "new_a2", 'delete', '2021-12-09', '11'), (3, "new_a3", 'insert', '2021-12-09', '12');
merge into hudi_cow_pt_tbl1 as target
using (
select id, name, '2000' as ts, flag, dt, hh from merge_source2
) source
on target.id = source.id
when matched and flag != 'delete' then
update set id = source.id, name = source.name, ts = source.ts, dt = source.dt, hh = source.hh
when matched and flag = 'delete' then delete
when not matched then
insert (id, name, ts, dt, hh) values(source.id, source.name, source.ts, source.dt, source.hh)
;
4.2.6 删除数据
-- 删除数据
1)语法
DELETE FROM tableIdentifier [ WHERE BOOL_EXPRESSION]
2)案例
delete from hudi_cow_nonpcf_tbl where uuid = 1;
delete from hudi_mor_tbl where id % 2 = 0;
-- 使用非主键字段删除
delete from hudi_cow_pt_tbl1 where name = 'a1_1';
4.2.7 覆盖数据
使用INSERT_OVERWRITE类型的写操作覆盖分区表
使用INSERT_OVERWRITE_TABLE类型的写操作插入覆盖非分区表或分区表(动态分区)
-- 1)insert overwrite 非分区表
insert overwrite hudi_mor_tbl select 99, 'a99', 20.0, 900;
insert overwrite hudi_cow_nonpcf_tbl select 99, 'a99', 20.0;
-- 2)通过动态分区insert overwrite table到分区表
insert overwrite table hudi_cow_pt_tbl1 select 10, 'a10', 1100, '2021-12-09', '11';
-- 3)通过静态分区insert overwrite 分区表
insert overwrite hudi_cow_pt_tbl1 partition(dt = '2021-12-09', hh='12') select 13, 'a13', 1100;
4.2.8 修改表结构和修改分区
-- 修改表结构(Alter Table)
1)语法
-- Alter table name
ALTER TABLE oldTableName RENAME TO newTableName
-- Alter table add columns
ALTER TABLE tableIdentifier ADD COLUMNS(colAndType (,colAndType)*)
-- Alter table column type
ALTER TABLE tableIdentifier CHANGE COLUMN colName colName colType
-- Alter table properties
ALTER TABLE tableIdentifier SET TBLPROPERTIES (key = 'value')
2)案例
--rename to:
ALTER TABLE hudi_cow_nonpcf_tbl RENAME TO hudi_cow_nonpcf_tbl2;
--add column:
ALTER TABLE hudi_cow_nonpcf_tbl2 add columns(remark string);
--change column:
ALTER TABLE hudi_cow_nonpcf_tbl2 change column uuid uuid int;
--set properties;
alter table hudi_cow_nonpcf_tbl2 set tblproperties (hoodie.keep.max.commits = '10');
-- 修改分区
1)语法
-- Drop Partition
ALTER TABLE tableIdentifier DROP PARTITION ( partition_col_name = partition_col_val [ , ... ] )
-- Show Partitions
SHOW PARTITIONS tableIdentifier
2)案例
--show partition:
show partitions hudi_cow_pt_tbl1;
--drop partition:
alter table hudi_cow_pt_tbl1 drop partition (dt='2021-12-09', hh='10');
注意:show partition结果是基于文件系统表路径的。删除整个分区数据或直接删除某个分区目录并不精确。
4.3 使用IDEA方式
可以参考: https://blog.csdn.net/qq_44665283/article/details/129271737?spm=1001.2014.3001.5501
4.4 使用DeltaStreamer导入工具(从Apache kafka到hudi表案例)
HoodieDeltaStreamer工具 (hudi-utilities-bundle中的一部分) 提供了从DFS或Kafka等不同来源进行摄取的方式,并具有以下功能:
Ø 精准一次从Kafka采集新数据,从Sqoop、HiveIncrementalPuller的输出或DFS文件夹下的文件增量导入。
Ø 导入的数据支持json、avro或自定义数据类型。
Ø 管理检查点,回滚和恢复。
Ø 利用 DFS 或 Confluent schema registry的 Avro Schema。
Ø 支持自定义转换操作。
官网如下:https://hudi.apache.org/cn/docs/0.12.2/hoodie_deltastreamer/
官网上给的案例是基于Confluent Kafka,此案例基于Apache Kafka。
1、启动zk和kafka
2、创建测试topic
/opt/apps/kafka_2.12-2.6.2/bin/kafka-topics.sh --bootstrap-server centos01:9092 --create --topic hudi_test
3、准备kafka生产者程序
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>hudi-startartifactId>
<groupId>com.yydsgroupId>
<version>1.0-SNAPSHOTversion>
parent>
<modelVersion>4.0.0modelVersion>
<artifactId>hudi-kafkaartifactId>
<dependencies>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.4.1version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.83version>
dependency>
dependencies>
project>
package com.yyds;
import com.alibaba.fastjson.JSONObject;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.Random;
public class HudiKafkaProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "centos01:9092,centos02:9092,centos03:9092");
props.put("acks", "-1");
props.put("batch.size", "1048576");
props.put("linger.ms", "5");
props.put("compression.type", "snappy");
props.put("buffer.memory", "33554432");
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
Random random = new Random();
for (int i = 0; i < 1000; i++) {
JSONObject model = new JSONObject();
model.put("userid", i);
model.put("username", "name" + i);
model.put("age", 18);
model.put("partition", random.nextInt(100));
producer.send(new ProducerRecord<String, String>("hudi_test", model.toJSONString()));
}
producer.flush();
producer.close();
}
}
4、准备DeltaStreamer工具的配置文件
(1) 定义arvo所需schema文件(包括source和target)
mkdir /opt/apps/hudi-props/
vim /opt/apps/hudi-props/source-schema-json.avsc
# kafka字段配置如下
{
"type": "record",
"name": "Profiles",
"fields": [
{
"name": "userid",
"type": [ "null", "string" ],
"default": null
},
{
"name": "username",
"type": [ "null", "string" ],
"default": null
},
{
"name": "age",
"type": [ "null", "string" ],
"default": null
},
{
"name": "partition",
"type": [ "null", "string" ],
"default": null
}
]
}
# hudi表的配置
cp source-schema-json.avsc target-schema-json.avsc
(2) hudi配置base.properties
cp /opt/apps/hudi-0.12.0/hudi-utilities/src/test/resources/delta-streamer-config/base.properties /opt/apps/hudi-props/
(3) 编写kafka source的配置文件
cp /opt/apps/hudi-0.12.0/hudi-utilities/src/test/resources/delta-streamer-config/kafka-source.properties /opt/apps/hudi-props/
vim /opt/apps/hudi-props/kafka-source.properties
include=hdfs://centos04:9000/hudi-props/base.properties
# Key fields, for kafka example
hoodie.datasource.write.recordkey.field=userid
hoodie.datasource.write.partitionpath.field=partition
# schema provider configs
hoodie.deltastreamer.schemaprovider.source.schema.file=hdfs://centos04:9000/hudi-props/source-schema-json.avsc
hoodie.deltastreamer.schemaprovider.target.schema.file=hdfs://centos04:9000/hudi-props/target-schema-json.avsc
# Kafka Source
hoodie.deltastreamer.source.kafka.topic=hudi_test
#Kafka props
bootstrap.servers=centos01:9092,centos02:9092,centos03:9092
auto.offset.reset=earliest
group.id=test-group
# 将配置文件上传到Hdfs
hadoop fs -put /opt/apps/hudi-props/ /
5、拷贝所需jar包到Spark
cp /opt/apps/hudi-0.12.0/packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.12.0.jar /opt/apps/spark-3.2.2/jars/
需要把hudi-utilities-bundle_2.12-0.12.0.jar放入spark的jars路径下,否则报错找不到一些类和方法。
6、运行导入命令
spark-submit \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
/opt/apps/spark-3.2.2/jars/hudi-utilities-bundle_2.12-0.12.0.jar \
--props hdfs://centos04:9000/hudi-props/kafka-source.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
--source-ordering-field userid \
--target-base-path hdfs://centos04:9000/tmp/hudi/hudi_test \
--target-table hudi_test \
--op BULK_INSERT \
--table-type MERGE_ON_READ
7、查看导入结果
(1)启动spark-sql(记得启动Hive)
spark-sql \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
(2)指定location创建hudi表
use spark_hudi;
create table hudi_test using hudi
location 'hdfs://centos04:9000/tmp/hudi/hudi_test';
(3)查询hudi表
spark-sql> select * from hudi_test limit 10;
20230306182511817 20230306182511817_0_0 222 45 b7b4efa6-af0a-49b9-a9ac-fdff4139dcf3-85_0-15-13_20230306182511817.parquet 222 name222 18 45
20230306182511817 20230306182511817_0_1 767 45 b7b4efa6-af0a-49b9-a9ac-fdff4139dcf3-85_0-15-13_20230306182511817.parquet 767 name767 18 45
20230306182511817 20230306182511817_1_0 128 45 19eb5a0a-aa85-492d-bfb7-c3ccd620d0ca-76_1-15-14_20230306182511817.parquet 128 name128 18 45
20230306182511817 20230306182511817_1_1 150 45 19eb5a0a-aa85-492d-bfb7-c3ccd620d0ca-76_1-15-14_20230306182511817.parquet 150 name150 18 45
20230306182511817 20230306182511817_1_2 154 45 19eb5a0a-aa85-492d-bfb7-c3ccd620d0ca-76_1-15-14_20230306182511817.parquet 154 name154 18 45
20230306182511817 20230306182511817_1_3 163 45 19eb5a0a-aa85-492d-bfb7-c3ccd620d0ca-76_1-15-14_20230306182511817.parquet 163 name163 18 45
20230306182511817 20230306182511817_1_4 598 45 19eb5a0a-aa85-492d-bfb7-c3ccd620d0ca-76_1-15-14_20230306182511817.parquet 598 name598 18 45
20230306182511817 20230306182511817_1_5 853 45 19eb5a0a-aa85-492d-bfb7-c3ccd620d0ca-76_1-15-14_20230306182511817.parquet 853 name853 18 45
20230306182511817 20230306182511817_1_6 982 45 19eb5a0a-aa85-492d-bfb7-c3ccd620d0ca-76_1-15-14_20230306182511817.parquet 982 name982 18 45
20230306182511817 20230306182511817_1_0 140 98 19eb5a0a-aa85-492d-bfb7-c3ccd620d0ca-78_1-15-14_20230306182511817.parquet 140 name140 18 98
Time taken: 5.119 seconds, Fetched 10 row(s)
4.5 并发控制
4.5.1 Hudi支持的并发控制
1)MVCC
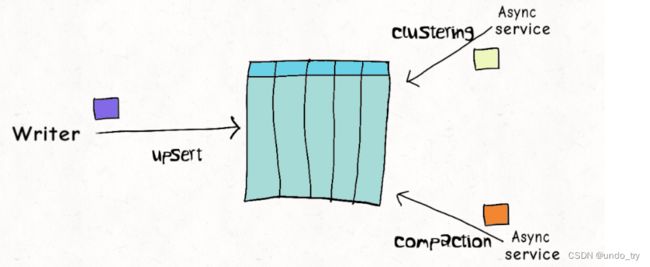
Hudi的表操作,如压缩、清理、提交,hudi会利用多版本并发控制来提供多个表操作写入和查询之间的快照隔离。使用MVCC这种模型,Hudi支持并发任意数量的操作作业,并保证不会发生任何冲突。Hudi默认这种模型。MVCC方式所有的table service都使用同一个writer来保证没有冲突,避免竟态条件。
2)OPTIMISTIC CONCURRENCY
针对写入操作(upsert、insert等)利用乐观并发控制来启用多个writer将数据写到同一个表中,Hudi支持文件级的乐观一致性,即对于发生在同一个表中的任何2个提交(写入),如果它们没有写入正在更改的重叠文件,则允许两个写入都成功。此功能处于实验阶段,需要用到Zookeeper或HiveMetastore来获取锁。

4.5.2 使用并发写方式
(1)如果需要开启乐观并发写入,需要设置以下属性
hoodie.write.concurrency.mode=optimistic_concurrency_control
hoodie.cleaner.policy.failed.writes=LAZY
hoodie.write.lock.provider=<lock-provider-classname>
Hudi获取锁的服务提供两种模式使用zookeeper、HiveMetaStore或Amazon DynamoDB(选一种即可)
(2)相关zookeeper参数
hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider
hoodie.write.lock.zookeeper.url
hoodie.write.lock.zookeeper.port
hoodie.write.lock.zookeeper.lock_key
hoodie.write.lock.zookeeper.base_path
(3)相关HiveMetastore参数,HiveMetastore URI是从运行时加载的hadoop配置文件中提取的
hoodie.write.lock.provider=org.apache.hudi.hive.HiveMetastoreBasedLockProvider
hoodie.write.lock.hivemetastore.database
hoodie.write.lock.hivemetastore.table
4.5.3 使用Spark DataFrame并发写入
(1)启动spark-shell
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
(2)编写代码
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option("hoodie.write.concurrency.mode", "optimistic_concurrency_control").
option("hoodie.cleaner.policy.failed.writes", "LAZY").
option("hoodie.write.lock.provider", "org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider").
option("hoodie.write.lock.zookeeper.url", "centos01,centos02,centos03").
option("hoodie.write.lock.zookeeper.port", "2181").
option("hoodie.write.lock.zookeeper.lock_key", "test_table").
option("hoodie.write.lock.zookeeper.base_path", "/multiwriter_test").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
(3)使用zk客户端,验证是否使用了zk。
/opt/apps/apache-zookeeper-3.5.7/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
(4)zk下产生了对应的目录,/multiwriter_test下的目录,为代码里指定的lock_key
[zk: localhost:2181(CONNECTED) 1] ls /multiwriter_test
4.5.4 使用Delta Streamer并发写入
基于前面DeltaStreamer的例子,使用Delta Streamer消费kafka的数据写入到hudi中,这次加上并发写的参数。
1)进入配置文件目录,修改配置文件添加对应参数,提交到Hdfs上
cd /opt/apps/hudi-props/
cp kafka-source.properties kafka-multiwriter-source.propertis
vim kafka-multiwriter-source.propertis
# 添加并发控制的参数
hoodie.write.concurrency.mode=optimistic_concurrency_control
hoodie.cleaner.policy.failed.writes=LAZY
hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider
hoodie.write.lock.zookeeper.url=centos01,centos02,centos03
hoodie.write.lock.zookeeper.port=2181
hoodie.write.lock.zookeeper.lock_key=test_table2
hoodie.write.lock.zookeeper.base_path=/multiwriter_test2
hadoop fs -put /opt/apps/hudi-props/kafka-multiwriter-source.propertis /hudi-props
2)运行Delta Streamer
spark-submit \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
/opt/apps/spark-3.2.2/jars/hudi-utilities-bundle_2.12-0.12.0.jar \
--props hdfs://centos04:9000/hudi-props/kafka-multiwriter-source.propertis \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
--source-ordering-field userid \
--target-base-path hdfs://centos04:9000/tmp/hudi/hudi_test_multi \
--target-table hudi_test_multi \
--op INSERT \
--table-type MERGE_ON_READ
3)查看zk是否产生新的目录
/opt/apps/apache-zookeeper-3.5.7-bin/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zk: localhost:2181(CONNECTED) 1] ls /multiwriter_test2
4.6 hudi调优
4.6.1 常规调优
# 并行度
Hudi对输入进行分区默认并发度为1500,以确保每个Spark分区都在2GB的限制内(在Spark2.4.0版本之后去除了该限制),如果有更大的输入,则相应地进行调整。建议设置shuffle的并发度,配置项为 hoodie.[insert|upsert|bulkinsert].shuffle.parallelism,以使其至少达到inputdatasize/500MB。
# Off-heap(堆外)内存
Hudi写入parquet文件,需要使用一定的堆外内存,如果遇到此类故障,请考虑设置类似 spark.yarn.executor.memoryOverhead或 spark.yarn.driver.memoryOverhead的值。
# Spark 内存
通常Hudi需要能够将单个文件读入内存以执行合并或压缩操作,因此执行程序的内存应足以容纳此文件。另外,Hudi会缓存输入数据以便能够智能地放置数据,因此预留一些 spark.memory.storageFraction通常有助于提高性能。
# 调整文件大小
设置 limitFileSize以平衡接收/写入延迟与文件数量,并平衡与文件数据相关的元数据开销。
# 时间序列/日志数据
对于单条记录较大的数据库/ nosql变更日志,可调整默认配置。另一类非常流行的数据是时间序列/事件/日志数据,它往往更加庞大,每个分区的记录更多。在这种情况下,请考虑通过 .bloomFilterFPP()/bloomFilterNumEntries()来调整Bloom过滤器的精度,以加速目标索引查找时间,另外可考虑一个以事件时间为前缀的键,这将使用范围修剪并显着加快索引查找的速度。
# GC调优
请确保遵循Spark调优指南中的垃圾收集调优技巧,以避免OutOfMemory错误。[必须]使用G1 / CMS收集器,其中添加到spark.executor.extraJavaOptions的示例如下:
-XX:NewSize=1g -XX:SurvivorRatio=2 -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintTenuringDistribution -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof
# OutOfMemory错误
如果出现OOM错误,则可尝试通过如下配置处理:spark.memory.fraction=0.2,spark.memory.storageFraction=0.2允许其溢出而不是OOM(速度变慢与间歇性崩溃相比)。
4.6.2 配置示例
spark.driver.extraClassPath /etc/hive/conf
spark.driver.extraJavaOptions -XX:+PrintTenuringDistribution -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof
spark.driver.maxResultSize 2g
spark.driver.memory 4g
spark.executor.cores 1
spark.executor.extraJavaOptions -XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof
spark.executor.id driver
spark.executor.instances 300
spark.executor.memory 6g
spark.rdd.compress true
spark.kryoserializer.buffer.max 512m
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.shuffle.service.enabled true
spark.sql.hive.convertMetastoreParquet false
spark.submit.deployMode cluster
spark.task.cpus 1
spark.task.maxFailures 4
spark.yarn.driver.memoryOverhead 1024
spark.yarn.executor.memoryOverhead 3072
spark.yarn.max.executor.failures 100