分享:数据库存储与索引技术(二) 分布式数据库基石——LSM树
欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/
本文来自OceanBase社区分享,仅限交流探讨。原作者马伟,长期从事互联网广告检索系统的研发,对数据库,编译器等领域也有浓厚兴趣。
文章目录
-
- 1. 概念介绍
- 1.1. BigTable
-
- 1.1.1. 数据模型
- 1.1.2. BigTable中LSM树实现
- 1.2. LSM树在分布式数据库中的应用
- 2. LSM树各类操作
- 2.1. 数据变更
- 2.2. 数据读取
-
- 2.2.1. 点查
- 2.2.2. 范围查询
- 2.3. 数据合并(Compaction)
-
- 2.3.1. Minor Compaction
- 2.3.2. Major Compaction
- 3.小结
- 参考文献
上文讲到,传统单机数据库受制于底层存储技术及扩展瓶颈,无法满足互联网席卷而来的海量存储和并发读写事务需求。由此衍生出各类数据库扩展技术,其中以NewSQL为代表的分布式数据库多采用LSM树用于构建底层的存储系统,对存储和读写请求的扩展都有非常好的支持。那么,LSM树到底有何独特之处?本文从应用及操作层面进行介绍。
1. 概念介绍
LSM-Tree 全称是 Log Structured Merge Tree,是一种分层、有序、面向磁盘的数据结构,其核心思想是充分利用磁盘的顺序写性能要远高于随机写性能这一特性,将批量的随机写转化为一次性的顺序写。其最早是在1996年的论文[《The Log-Structured Merge-Tree (LSM-Tree)》](https://open.oceanbase.com/blog/The Log-Structured Merge-Tree (LSM-Tree))中提出。
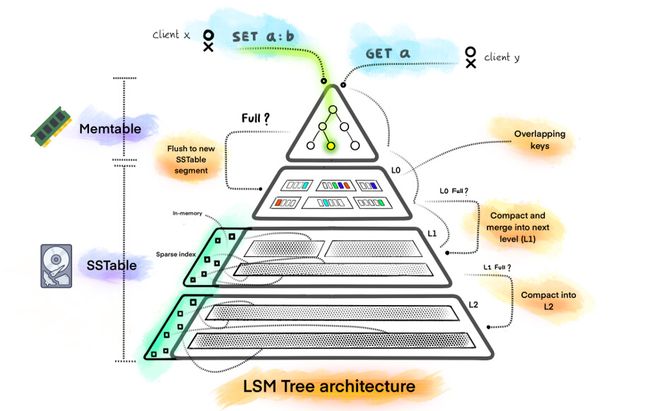
LSM树由两个或以上的存储结构组成,比如在论文中为了方便说明使用了最简单的两个存储结构。一个存储结构常驻内存中,称为C0 tree,具体可以是任何方便健值查找的数据结构,比如红黑树、map之类,甚至可以是跳表。另外一个存储结构常驻在硬盘中,称为C1 tree,具体结构类似B树。

在LSM树中,最低一级即最小的C0树位于内存,而更高级的C1、C2…树都位于磁盘里。数据会先写入内存中的C0树,当它的大小达到一定阈值之后,C0树中的全部或部分数据就会刷入磁盘中的C1树,如下图所示。在实际应用中,为防止内存因断电等原因丢失数据,写入内存的数据同时会顺序在磁盘上写日志,类似于预写日志(WAL),这就是LSM这个词中Log一词的来历。

1.1. BigTable
LSM树在前互联网时代并未得到很好的重视,传统的关系型数据库的存储和索引结构依然以基于页面(Page)的B+树和HashTable为主。随着互联网规模的扩大和普及,在面对十亿级的用户接入,以及PB规模数据的写入,传统的关系型数据库已经难以支撑。Google 2006年发表的论文《Bigtable: A Distributed Storage System for Structured Data》提出了利用LSM树在GFS上构建可线性扩展的KV系统的方案,即大名鼎鼎的BigTable系统。
1.1.1. 数据模型
BigTable的数据模型,每一个键值对的 Key 都为 Row key + Column key + Timestamp 的结构,Value 则是任意二进制字符串:
(row:string, column:string,time:int64) -> string
举一个具体的例子:比如,一个存储了大量网页及其相关信息的表 Webtable,Webtable 使用 URL 作为行名,使用网页的某些属性作为列名,网页的内容存入 contents 列中,并使用获取该网页的时间戳标识同一个网页的不同版本。在 Bigtable 中,Webtable 的存储范例如下图所示:
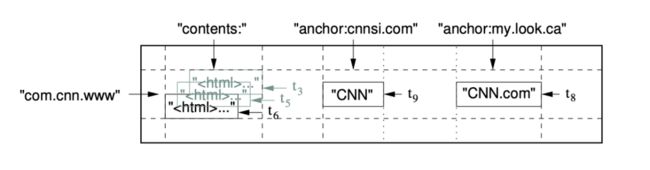
BigTable引入了RowKey, ColumnFamily, ColumnKey, TimeStamp等概念来方便用户抽象和管理自己的数据。其各自作用如下:
- Row Key
BigTable的RowKey概念与关系数据库的PrimaryKey类似,是一行数据的唯一标识。RowKey可以是任意二进制字符串,最大容量为 64KB。但是在大多数场景下,字节数只有 10~100 Bytes 左右。Bigtable 的表按照 RowKey的字典序组织数据。即BigTable表中的数据是全局有序的。 - Column Key 与 ColumnFamily
ColumnKey类似关系数据库中的列,一般表示一种数据类型,也可以是一个复杂Object序列化后的一串二进制字符串。若干个有业务含义的ColumnKey聚合在一起被称为ColumnFamily(列族)。ColumnFamily 是 access control(访问控制)、disk and memory accounting(磁盘和内存计算)的基本单元。 - TimeStamp
Bigtable 中的表项可以包含同一数据的不同版本,采用时间戳进行索引。时间戳是 64 位整型,既可以由系统赋值也可由用户指定。时间戳通常以 us(微秒)为单位。时间戳既可以由 Bigtable 进行分配,也可以由客户端进行分配,如果应用程序希望避免冲突,应当生产唯一的时间戳。
表项的不同版本按照时间戳倒序排列(大的在前,时间戳越大表明数据加入的时间越晚),即最新的数据排在最前面,因而每次查询会先读到最新版本。为了简化多版本数据的管理,每个列族都有两个设置参数用于版本的自动回收,用户可以指定保存最近 N 个版本,或保留足够新的版本(如最近 7 天的内容)。
1.1.2. BigTable中LSM树实现
BigTable的数据模型,在概念上抽象出了完整的Table, Row, Column等概念,方便应用进行业务抽象。但是在实现上,BigTable是如何何LSM树进行结合的呢?我们前面提到,LSM是一个K-V结构的数据结构,在BigTable中,每个Table即对应一棵LSM树。BigTable通过分隔符(这里假定为",将Rwo, ColumnFamily, ColumnKey, TimeStamp组合成一个Key,由此来索引对应的Value值,即
RowKey:ColumnFamily:ColumnKey:TimeStamp->Value
BigTable中即以这种格式的K-V数据对LSM树进行读写:

如上图的BigTable的LSM树实现中,提出了MemoryTable和SSTable的概念。在原始的BigTable论文中,只提到了这两种数据结构的作用,并未详细介绍其实现。2011年Google开源了基于LSM树的单机K-V引擎LevelDB,其中包含了MemoryTable和SSTable的具体实现:
- MemoryTable,即对应LSM树论文中的C0 Tree,在LevelDB中被分为了可以随时修改(插入/删除)的MemTable,以及不可变的**Immutable MemTable。**当MemTable数据写满之后(通常是看占用内存超过一定Quota之后),将MemTable固化成SSTable格式并常驻内存中。
- SSTable,即对应LSM论文中的C1, C2, …, Ck Tree。LevelDB中每个SSTable大小基本固定(2M),SSTable中的数据按照Key进行排序,每一层的SSTable都是按照Key全局有序的。当内存中的Immutable MemTable太多系统需要释放内存时,此时会将Immutable MemTable的数据写入到第一层的SSTable磁盘并与第一层的已有SSTable进行合并,从而保证C1层的所有SSTable是全局有序的。磁盘上的每一层的SSTable达到一定Size之后都会与下一层的SSTable进行合并。
1.2. LSM树在分布式数据库中的应用
之所以称LSM树是各类分布式数据库的基石,是因为自从2011年Google开源LevelDB之后,各类分布式NewSQL数据库,基本都是基于LSM树来构建其存储系统的,有些甚至直接基于LevelDB的改进开源版版RocksDB来构建的。
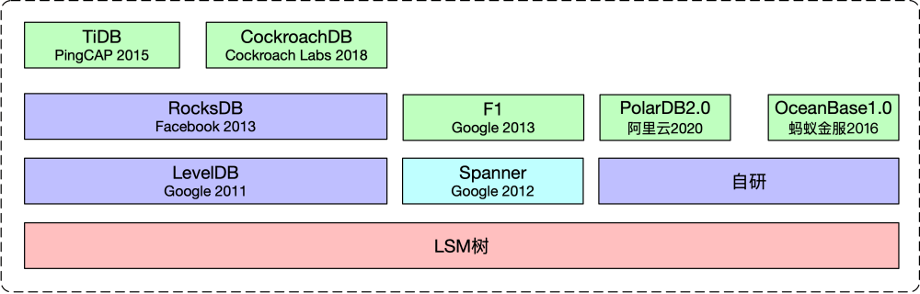
以开源的TiDB为例(TiDB开源且文档齐全,所以以它为例),其是在开源的RocksDB基础上,加上自己开发实现的Multi-Raft协议,将TiDB的存储层统一封装成了独立的KV存储服务TiKV。TiDB的SQL/事务层(TiDB Server)是无状态的,可以和TiKV分别独立扩容。

对比蚂蚁的OceanBase,则是将LSM树结构和数据库其他核心功能实现在了一个单一的应用OBServer中。这样的好处是存储层和上层功能可以更好的进行整合和优化,对本地数据的访问可以减少一次RPC请求。与TiDB相比,则牺牲了一部分灵活性(TiDB可以单独就计算或者存储扩容,OB只能整体扩容)。

2. LSM树各类操作
LSM树将任何的对数据操作都转化为对内存中的Memtable的一次插入。Memtable可以使用任意内存数据结构,如HashTable,B+Tree,SkipList等。对于有事务控制需要的存储系统,需要在将数据写入Memtable之前,先将数据写入持久化存储的WAL(Write Ahead Log)日志。由于WAL日志是顺序Append到持久化存储的,因此无论对磁盘还是SSD都是非常友好的。
2.1. 数据变更
LSM树支持常见的变更操作,插入,删除,更新。常见的实现里,为了统一变更的数据结构标识,往MemTable里写入的除了
通常MemTable的大小有限,当MemTable占用的内存超过一定大小或者内存比例之后,LSM需要将当前的MemTable先冻结为Immutable MemTable,然后通过后台线程将其持久化为SSTable到外部存储。持久化的过程中,会创建一个新的MemTable用于接收新的数据变更,Immutable Memtable则变成只读的。持久化过程在不同实现中不一样,有的实现会简单的将其写入磁盘,有的则会与磁盘上已有的SSTable进行合并。当持久化完成之后,Immutable MemTable的内存将会被释放。
2.2. 数据读取
2.2.1. 点查
数据读取分为点查或者范围查询。点查即针对单行数据进行查询,如常见的SQL语句:
select id, name, grade, score from student where id = '3042111009';
我们假定这里id字段即是要查询的LSM树的Key,那么点查询将会是如下过程:

在不考虑SSTable缓存的情况下,一次点读查询的代价是若干次内存查询 + n次磁盘IO,其中n是磁盘上的SSTable层数。可以看到,LSM树一次数据变更只需要一次内存插入即可,而一次点查询却需要若干次磁盘IO。
2.2.2. 范围查询
范围查询则是针对某一个范围的数据进行查询,如针对某个用户的10月份历史消费账单的数据查询:
select * from user_bill where id = '3042111009' and date >= '2021-10-01' and date <= '2021-10-31';
范围查询根据表的查询Key的范围区间[StartKey, EndKey],通常会先对StartKey在LSM树上逐层做LowerBound查询,即每一层上找到大于或等于StartKey的数据的起始位置。由于LSM树每一层都是有序的(内存中的MemTable如果是无序的Hash表则需要全部遍历),只需要从这个起始位置开始读取数据,直到读取到EndKey为止。
2.3. 数据合并(Compaction)
随着LSM树中写入数据的增多,不断的有MemTable被写入到磁盘上的作为SSTable存储。随着数据写入不断增多,转储的SSTable也会越来越多。但是太多SSTable会导致数据查询IO次数增多,因此后台尝试着不断对这些SSTable进行合并,这个合并过程称为Compaction。Compaction是LSM树实现中最复杂的部分,因为其持续对IO以及CPU资源的使用,会对系统的负载造成很大影响,影响上层业务的稳定性。业内也有很多不同的Compaction策略尝试缓解这一问题,这将在下篇文章《LSM树实现案例》中详细介绍。
目前主流的LSM树实现,其Compaction分为两类:Minor Compaction和Major Compaction。

2.3.1. Minor Compaction
Minor Compaction顾名思义,即代价较小的Compaction,很多实现里,这步操作主要就是将内存中的Immutable MemTable作为SSTable写入到磁盘。实际并不做磁盘上的SSTable之间的合并。因此在这种实现下,磁盘上的第一层SSTable,即C1层的SSTable之间,互相是可能会有数据重叠的。读取查询的时候需要将C1层的所有SSTable都读取才能进行正确查询。
2.3.2. Major Compaction
Major Compaction的触发策略可能有多种,如某一层的数据达到一定的阈值,也可能是用户手动触发等。因为Major Compaction代价比较大,不同的实现里都有不同的触发策略。其主要的作用即是在和层之间进行Merge Sort,将两层的数据归并到,去除删除或者旧版本的数据,保证同一层的数据之间是完全有序的。
3.小结
本文讲述了LSM树的历史、基本概念和各种重要操作,以及Google在此基础上的一系列开创性的贡献,如LevelDB、BigTable、Spanner等。下一篇文章我们将以OceanBase v3.x为例,重点介绍LSM树OceanBase中的实现和应用。
参考文献
1. LSM树及BigTable
- LSM论文1996:https://www.cs.umb.edu/~poneil/lsmtree.pdf
- LSM树综述:https://zhuanlan.zhihu.com/p/351241814
- 深入浅出LevelDB:https://mrcroxx.github.io/categories/%E6%B7%B1%E5%85%A5%E6%B5%85%E5%87%BAleveldb/
- RCFile格式参考:https://cloud.tencent.com/developer/article/1328762
- BigTable论文2006:https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf
- LSM树综述:https://zhuanlan.zhihu.com/p/351241814
- 深入浅出LevelDB:https://mrcroxx.github.io/categories/%E6%B7%B1%E5%85%A5%E6%B5%85%E5%87%BAleveldb/
2. 分布式数据库
- Spanner论文(2012): https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/spanner-osdi2012.pdf
- Spanner论文(2017):https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/46103.pdf
- Google Spanner论文解读:https://cloud.tencent.com/developer/article/1131036
- TiDB整体架构:https://docs.pingcap.com/zh/tidb/stable/tidb-architecture
- TiDB存储架构:https://docs.pingcap.com/zh/tidb/stable/tidb-storage
- TiDB博客全系列:https://pingcap.com/zh/blog/
- OB数据库存储架构:https://www.oceanbase.com/docs/oceanbase-database/oceanbase-database/V3.2.1/overview-4
- OB数据存储管理:https://www.oceanbase.com/docs/oceanbase-database/oceanbase-database/V3.2.1/consolidation-management-overview
- OB数据库压缩特性:https://zhuanlan.zhihu.com/p/49161275
- OB存储引擎详解:https://www.modb.pro/db/137286
- OB博客文章全系列:https://open.oceanbase.com/articles