CrossCLR: Cross-modal Contrastive Learning for Multi-modal Video Representations, 2021 ICCV
**本文内容仅代表个人理解,如有错误,欢迎指正**
1. Points
这篇论文主要解决两个问题
1. 跨模态对比学习(Cross-modal Contrastive learning)更注重于不同模态下的数据,而非同一模态下的数据。
- 也就是说,将不同模态下的数据投影到Joint space时,希望paired samples(eg, Image1和Text1)之间的距离可以尽可能地小,unpaired samples(eg, Image1和Text2)之间的距离可以尽可能地大。而忽略了一个问题,即同一模态下语义相近的数据(eg, Image1和Image8, 其中, Image1和Image8在语义上是相近的)被投影到Joint space时,它们之间的距离也应该是相近。
* 因此,提出Inter-Modality and Intra-Modality Alignment,即模态间与模态内都要对齐。
2. 跨模态对比学习(Cross-modal Contrastive learning)中,负样本(Negative sample)的选取很重要,随机进行负样本选取容易产生语义冲突(Semantic Collision)。
- 之前对比学习方法在选取负样本时,或在mini-batch中随机抽取样本作为负样本,或将mini-batch中除paired sample外的样本均取为负样本。这样做的问题在于,如果此时负样本实质上与Anchor有着比较高的semantic similarity,那么将它们在Joint space中的距离拉大就有悖于我们对比学习的目的了。
* 因此,定义Influential samples,提出Negative set pruning以及Loss weighting.
## 综上所述,就是提出了CrossCLR loss来约束/缓解上述问题。
2. Background Introduction
对比学习(Contrastive Learning)的思想:给定Anchor以及与它相对应的Positive sample和Negative sample,当将它们投影到Joint space时,希望能够使得Anchor和Positive samples的距离相近,并使得Anchor和Negative sample相远离。
有一系列的Losses可以帮助model实现以上思路:Max-margin loss, Triplet loss, InfoNCE, etc.
以上Loss,相比于本文所提出的CrossCLR,忽略了一个问题,即False negative samples存在的可能性(即有些被认为是Negative samples的sample实质上与Anchor存在较高的语义上的相似性),盲目地将其与Anchor之间的距离拉大,会导致语义冲突。
从Figure 1 中可以观察到,
图a)和b)一方面只关注不同模态间数据的相似性;另一方面没有考虑False Negative sample的存在,一心只想拉近paired samples间的距离和拉远unpaired samples间的距离。
而图c)CrossCLR同时考虑了不同模态间以及同一模态内数据的相似性,亦充分考虑到False Negative sample的问题,没有刻意拉大Anchor和False Negative sample之间的距离,保证了语义上的一致性。

Figure 1
3. Main Components
3.1 Inter-Modality and Intra-Modality Alignment

Figure 2
- 定义Loss函数,使得模型能够同时注意模态间和模态内的对齐。
- 简单来说就是,给定模态A和模态B的数据,在做模态间以及模态内的对齐时,统共有4个部分(如Figure 2 所示):1. 模态A与模态B的对齐 2. 模态A与模态A的对齐 3. 模态B与模态A的对齐 4. 模态B与模态B的对齐。其中,1和2放在一个Loss函数里,3和4放在一个Loss函数里,如下图所示:


* 需要注意的是,不论在做模态间还是模态内的对齐时,要忽略Influential samples(会在下文介绍),以避免语义冲突。(其实这一部分还只是给出模态间和模态内对齐loss的一个形式,在后文中还会对其进行修改。)
3.2 Avoiding Semantic Collision
- 一般来说,大量的Negative samples可以帮助model学到更好的表示,但前提是,Negative samples真的是Negative samples,而不是False Negative samples (have strong semantic overlap with the anchor)。如果强行拉远语义上相似度高的samples(Anchor & False Negative Sample)之间的距离,就会产生语义冲突(Semantic Collision)。
* 因此,需要减少语义冲突所带来的影响并将False Negative samples从Negative set中移除掉。
从以下三个方面介绍本文在这一小节的工作:1. Influential samples 2. Negative set pruning 3. Loss weighting 其中,2和3是基于1的。
1. Influential samples
Influential sample的定义:与其他samples有着较强相关性的样本 (文章内关于Influential samples的表述有1. "We define an influential sample as a sample x that is strongly connected with many other samples." 2. "samples that are strongly connected with other samples are more likely to share semantics and, thus, more likely lead to semantic collision. ")
* 通过”L2 Normalization+点乘操作“来等价于计算余弦相似度,计算样本之间的相关性。相关性越强,意味着样本的影响力越大。如Figure 2右图所示,针对同一模态下的数据,计算每一个样本与其他样本之间的相关性并进行累加作为该样本的相关性/影响力,相关性/影响力超过一定阈值的就列为Influential samples,Influential samples将会从Negative set中被移除。

2. Negative set pruning
- 简单来说,就是把Influential samples从Negative set中移除。
3. Loss weighting
- 将每个Sample的Connectivity(相关性)作为依据来给该样本赋以权重(指的是作为Negative sample的权重)。相关性与权重成正比,即相关性越高,权重越高。
* 1. "Samples with very low connectivity can be regarded as outliers to the dataset. They are too sparse to positively influence the shape of the embedding" 其实是指,如果这个样本跟其他样本的差距比较大,那么作为负样本进行对比学习的时候,相对而言比较容易,但学出来的特征就会相对而言比较粗糙(coarse)。
* 2. 在论文中"At the same time, we increase the weight of influential samples, since the cross-modal information of these samples should have a large impact on the shape of the embedding." 个人认为可能存在一定的歧义?其中所说的"influential samples"应该指的是connectivity相对而言比较高,但还低于阈值的samples(类似于Hard negative samples?),而不是第一点中所定义的influential samples。
Q: 其实本文所定义的Influential samples和Hard negative samples之间的关系还是值得去深究的,相对而言它们之间的界限还是比较模糊。

最后,CrossCLR loss 为(Lx+Ly)/2。值得注意的是,下图的Loss和3.1中的Loss有些许不同,一方面是给每个sample添加了weight,另一方面是将influential sample从negative set中移除了。

最后,将CrossCLR Loss应用在Two-stream hierarchical architecture of COOT上验证其有效性,这个model包括两个Transformer(local transformer和global transformer)。其中,local transformer for clip/sentence-level embeddings, global transformer for video/paragraph-level embeddings.即给定Video和Text,通过pre-trained的models去提取frame/word-level的特征,并将frame/word-level的特征输入local transformers得到clip/sentence-level的特征,再将clip/sentence-level的特征输入global transformer得到video/paragraph-level的特征。

Figure 3
4. Experimental Results
Comparison among contrastive learning losses
- outperforms other contrastive losses :)

Comparison to the state-of-the-art text-to-video retrieval on Youcook2

Comparison to the state-of-the-art text-to-video retrieval on LSMDC dataset

Ablation study
- CrossCLR主要有三个组成部分
1. Intra-modality alignment:定义loss,保证同一模态下数据的对齐
2. negative pruning:将Influential samples从Negative set中移除
3. proximity weighting:依据Connectivity的值来给sample权重
从表中可以看出,相较于2和3,Intra-modality alignment所带来的提升最大,所以模态内数据的对齐还是很值得再去摸索摸索的。

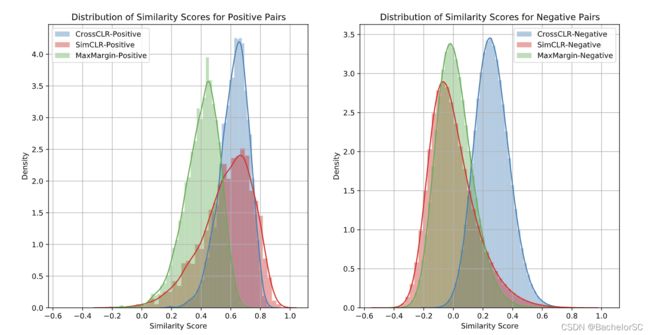
Distribution of similarity scores for positive and negative pairs
- 这张图主要可以看出Cross-CLR loss下,负样本的整体分布是更趋近于正样本的。
- "CrossCLR yields a higher certainty (lower variance) for positive samples than the MaxMargin loss or SimCLR loss."
- "CrossCLR allows for semantic similarity among negative samples, which shifts the distribution towards positive scores."
Qualitative results for LSMDC dataset
- t-SNE visualization:非线性降维技术,用于对高维数据可视化。
- 下图左边的区域是分别是CrossCLR和NT-Xent下基于text embeddings的t-SNE visualization,可以看到的是,CrossCLR下的数据分布是较为可分的,"brings more consistency over intra-modality samples in comparison to NT-Xent."
(*我的实验分析果然还有待加强)