序列模型与注意力机制
很久以前看吴恩达老师的视频和西瓜书时用jupyter写的,今天想起来就把它转到这里,真的挺方便
基础模型:Sequence to sequence(序列)模型在机器翻译和语音识别方面都有着广泛的应用。
机器翻译:使用“编码网络(encoder network)”+“解码网络(decoder network)”两个RNN模型组合的形式来解决。encoder network将输入语句编码为一个特征向量,传递给decoder network,完成翻译。
from IPython.display import Image
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "19.png", width=600, height=100)

encoder vector代表了输入语句的编码特征。encoder network和decoder network都是RNN模型,可使用GRU或LSTM单元。
这种模型也可以应用到图像捕捉领域。图像捕捉,即捕捉图像中主体动作和行为,描述图像内容。
首先,可以将图片输入到CNN,例如使用预训练好的AlexNet,删去最后的softmax层,保留至最后的全连接层。则该全连接层就构成了一个图片的特征向量(编码向量),表征了图片特征信息。然后,将encoder vector输入至RNN,即decoder network中,进行解码翻译。
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "20.png", width=600, height=100)

Sequence to sequence machine translation模型与我们第一节课介绍的language模型有一些相似,但也存在不同之处。二者模型结构如下所示:
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "21.png", width=600, height=100)
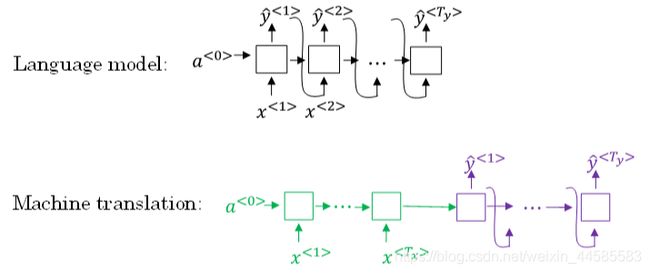
Language model是自动生成一条完整语句,语句是随机的。而machine translation model是根据输入语句,进行翻译,生成另外一条完整语句。decoder network与language model是相似的,encoder network可以看成是language model的 a < 0 > a^{<0>} a<0>.
也就是说,machine translation model是加了条件的Language model。
所以,machine translation的目标就是根据输入语句,作为条件,找到最佳翻译语句,使其概率最大:
m a x P ( y < 1 > , y < 2 > , ⋯ , y < T y > ∣ x < 1 > , x < 2 > , ⋯ , x < T x > ) max P(y^{<1>},y^{<2>},⋯,y^{
优化目标是让正确翻译对应的$ P(y{<1>},y{<2>},⋯,y{
优化方法:贪婪搜索:Greedy search根据条件,每次只寻找一个最佳单词作为翻译输出,力求把每个单词都翻译准确。缺点:每次只搜索一个单词,没有考虑该单词前后关系;运算成本较大。
Beam Search(定向搜索):优化了贪婪搜索,每次找出预测概率最大的B个单词。B为超参数。
B=1时,Beam Search就是贪婪搜索。
1.从词汇表中找出翻译的第一个单词概率最大的B个预测单词。
概率表示为: P ( y ^ < 1 > ∣ x ) P(\hat y^{<1>}|x) P(y^<1>∣x)
2.再以这B个单词为初始条件( a ( 0 ) a^{(0)} a(0))计算第二个单词的概率,选出B个预测值。
联合概率表示为: P ( y ^ < 2 > ∣ x , y ^ < 1 > ) P(\hat y^{<2>}|x,\hat y^{<1>}) P(y^<2>∣x,y^<1>)
3.以开始的B个单词结合了B个预测值之后 为初始条件,继续进行
联合概率表示为: P ( y ^ < 3 > ∣ x , y ^ < 1 > , y ^ < 2 > ) P(\hat y^{<3>}|x,\hat y^{<1>},\hat y^{<2>}) P(y^<3>∣x,y^<1>,y^<2>)
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "22.png", width=600, height=100)
#beam search就是对以下概率对最大化
#符号是乘积运算
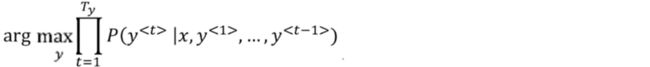
beam search的改进:
长度归一化:以上式子中每一项p都是小于1的,假设要预测的序列很长,那么就会有很多P相乘,会得到很小很小的数字,导致电脑的浮点不能精确得储存。所以将上述式子变成log形式求和的模式。
a r g m a x ∑ t = 1 T y P ( y ^ < t > ∣ x , y ^ < 1 > , ⋯ , y ^ < t − 1 > ) arg max∑_{t=1}^{T_y}P(\hat y^{
当序列很长的时候,每一项的概率值很小,那么log之后就为负,所有log项相加就会越来越负,使得模型更倾向于输出较短的句子。
解决方法:上面那个句子除以句子长度,实现长度归一化。
a r g m a x 1 T y ∑ t = 1 T y P ( y ^ < t > ∣ x , y ^ < 1 > , ⋯ , y ^ < t − 1 > ) arg max \frac 1{T_y}∑_{t=1}^{T_y}P(\hat y^{
实际应用中,会引入归一化因子α(超参数):
a r g m a x 1 T y α ∑ t = 1 T y P ( y ^ < t > ∣ x , y ^ < 1 > , ⋯ , y ^ < t − 1 > ) arg max \frac 1{T_y^α}∑_{t=1}^{T_y}P(\hat y^{
若α=1,则完全进行长度归一化;若α=0,则不进行长度归一化。一般令α=0.7.
Error analysis in beam search:首先,为待翻译语句建立人工翻译,记为 y ∗ y^∗ y∗。在RNN模型上使用beam search算法,得到机器翻译,记为 y ^ \hat y y^。
对于一个输入语句,分别计算输出是 y ∗ y^∗ y∗的概率P( y ∗ y^∗ y∗|x)和 y ^ \hat y y^的概率P( y ^ \hat y y^|x)。
然后比较大小:
P( y ∗ y^∗ y∗|x)>P( y ^ \hat y y^|x):Beam search算法有误,可以调试参数B。
P( y ∗ y^∗ y∗|x)
对机器翻译进行打分。以人工翻译为标准,观察机器翻译与人工翻译的符合度进行打分。
1.机器翻译的单词出现在人工翻译中的总次数除以机器翻译单词数目。
2.bleu score:1中是对一个单词进行操作,现在同时对两个连续单词进行打分。机器翻译中连续的2个单词出现在机器翻译中的次数之和除以机器翻译中连续的2个单词出现在人工翻译中的总次数。
对于机器翻译语句过短而造成的得分“虚高”的情况,引入参数因子brevity penalty,记为BP。
注意力模型:因为单纯的encoder-decoder RNN对较长语句的把握较差,因为encoder阶段要记住整句输入再传递给decoder进行翻译,于是提出“注意力机制”。
对待长语句,正确的翻译方法是将长语句分段,每次只对长语句的一部分进行翻译。即局部聚焦.
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "23.png", width=600, height=100)
#注意力模型
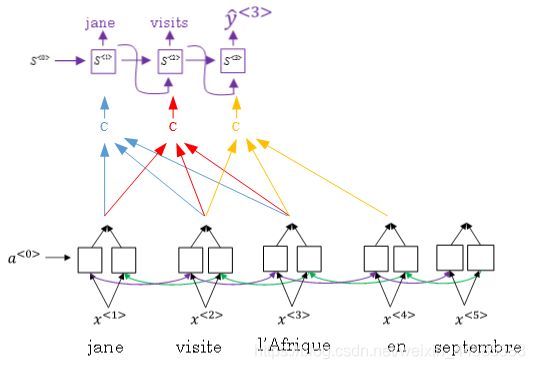
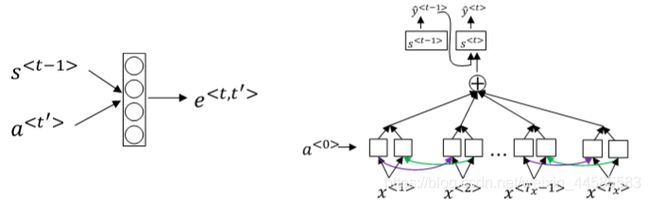
attention model仍由类似的编码网络(下)和解码网络(上)构成。其中,S由原语句附近单元共同决定,原则上说,离得越近,注意力权重(attention weights)越大,相当于在你当前的注意力区域有个滑动窗。
注意力模型:采用双向RNN,每个a
a < t ′ > = ( a → < t ′ > , a ← < t ′ > ) a^{
RNN编码生成特征,注意力权重用α表示,C是各个RNN神经元经过注意力权重得到的参数值。
例如, α < 1 , t ′ > α^{<1,t′>} α<1,t′>表示机器翻译的第一个单词“jane”对应的第t’个RNN神经元对应的注意力权重, C < 1 > C^{<1>} C<1>表示机器翻译第一个单词“jane”对应的解码网络输入参数。满足:
∑ t ′ α < 1 , t ′ > = 1 ∑_{t′}α^{<1,t′>}=1 ∑t′α<1,t′>=1
C < 1 > = ∑ t ′ α < 1 , t ′ > ⋅ a < t ′ > C^{<1>}=∑_{t′}α^{<1,t′>}⋅a^{
也就是说, α < t , t ′ > α^{
为了让 α < t , t ′ > α^{
α < t , t ′ > = e < t , t ′ > ∑ t ′ T x e < t , t ′ > α^{
求 e < t , t ′ > e^{
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "24.png", width=600, height=100)
Attention model的一个缺点是其计算量较大,若输入句子长度为Tx,输出句子长度为Ty,则计算时间约为Tx∗Ty。但是,其性能提升很多,计算量大一些也是可以接受的。
Attention model还能有效处理很多机器翻译问题。
Speech recognition:语音识别的输入是声音,量化成时间序列。更一般地,可以把信号转化为频域信号,即声谱图(spectrogram),再进入RNN模型进行语音识别。
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "25.png", width=500, height=100)

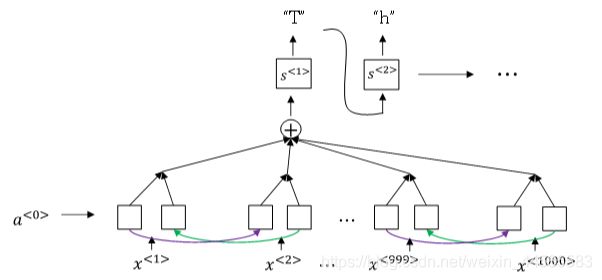
CTC模型(Connectionist temporal classification)
语音识别的注意力模型(attention model):语音识别的输入时间序列都比较长,而翻译的语句通常很短,Tx与Ty差别很大。为了让Tx=Ty,可以把输出相应字符重复并加入空白(下划线”_“)。
没有被空白符”_“分割的重复字符将被折叠到一起,即表示一个字符。通过这样,使得Tx=Ty。
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "26.png", width=500, height=100)
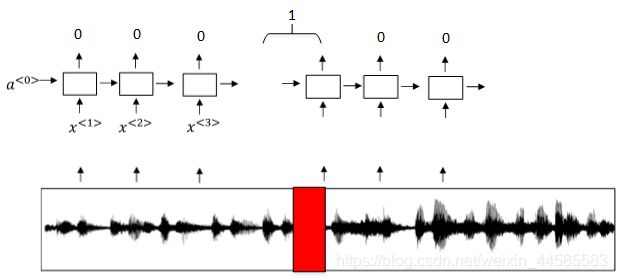
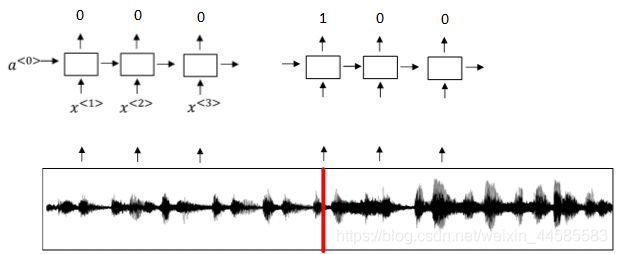
触发字检测:使用RNN模型来建立,RNN检测到触发字后输出1,非触发字输出0。
模型缺点:触发字较非触发字数目少得多,即正负样本分布不均。一种解决办法是在出现一个触发字时,将其附近的RNN都输出1。
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "27.png", width=500, height=100)
libo="C:/Users/libo/Desktop/machine learning/序列模型/图片/"
Image(filename = libo + "28.png", width=500, height=100)