TIDB简介及TIDB部署、原理和使用介绍
TiDB简介及TiDB部署、原理和使用介绍
从MySQL架构到TiDB
数据库分类
介绍TiDB数据库之前,先引入使用场景。如今的数据库种类繁多,RDBMS(关系型数据库)、NoSQL(Not Only SQL)、NewSQL,在数据库领域均有一席之地,可谓百家争鸣之势。那么我们为什么要学习使用TiDB呢?接下来就从我们最熟悉的MySQL的使用说起。
MySQL痛点
假设现在有一个高速发展的互联网公司,核心业务库MySQL的数据量已经近亿行,且还在不断增长中,公司对于数据资产较为重视,所有数据要求多副本保存至少5年,且除了有对历史数据进行统计分析的离线报表业务外,还有一些针对用户数据实时查询的需求。
根据以往的MySQL使用经验,MySQL单表在 5000 万行以内时,性能较好,单表超过5000万行后,数据库性能、可维护性都会极剧下降。当然这时候可以做MySQL分库分表,如使用Mycat或Sharding-jdbc。
MySQL分库分表
MySQL分库分表的优点非常明显
-
将大表拆分成小表,单表数据量可以控制到 5000 万行以内,使MySQL 性能稳定可控。
-
将单张大表拆分成小表后,能水平扩展,通过部署到多台服务器,提升整个集群的 QPS、TPS、Latency 等数据库服务指标。
MySQL分库分表的缺点也非常明显
-
分表跨实例后,产生分布式事务管理难题,一旦数据库服务器宕机,有事务不一致风险。
-
分表后,对 SQL 语句有一定限制,对业务方功能需求大打折扣。尤其对于实时报表统计类需求,限制非常之大。
-
分表后,需要维护的对象呈指数增长(MySQL实例数、需要执行的 SQL 变更数量等)
MySQL痛点解决方案
基于以上核心痛点,我们需要探索新的数据库技术方案来应对业务爆发式增长所带来的挑战,为业务提供更好的数据库服务支撑。
调研市场上的各大数据库,我们可以考虑选用NewSQL技术来解决,因为NewSQL技术有如下显著特点:
- 无限水平扩展能力
- 分布式强一致性,确保数据 100% 安全
- 完整的分布式事务处理能力与 ACID 特性
而TiDB数据库 GitHub的活跃度及社区贡献者方面都可以算得上是国际化的开源项目,是NewSQL技术中的代表性产品,所以我们可以选择使用TiDB数据库!
四大核心应用场景
- 对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高的金融行业属性的场景
众所周知,金融行业对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高。传统的解决方案是同城两个机房提供服务、异地一个机房提供数据容灾能力但不提供服务,此解决方案存在以下缺点:资源利用率低、维护成本高、RTO (Recovery Time Objective) 及 RPO (Recovery Point Objective) 无法真实达到企业所期望的值。TiDB 采用多副本 + Multi-Raft 协议的方式将数据调度到不同的机房、机架、机器,当部分机器出现故障时系统可自动进行切换,确保系统的 RTO <= 30s 及 RPO = 0。
- 对存储容量、可扩展性、并发要求较高的海量数据及高并发的 OLTP 场景
随着业务的高速发展,数据呈现爆炸性的增长,传统的单机数据库无法满足因数据爆炸性的增长对数据库的容量要求,可行方案是采用分库分表的中间件产品或者 NewSQL 数据库替代、采用高端的存储设备等,其中性价比最大的是 NewSQL 数据库,例如:TiDB。TiDB 采用计算、存储分离的架构,可对计算、存储分别进行扩容和缩容,计算最大支持 512 节点,每个节点最大支持 1000 并发,集群容量最大支持 PB 级别。
- Real-time HTAP 场景
随着 5G、物联网、人工智能的高速发展,企业所生产的数据会越来越多,其规模可能达到数百 TB 甚至 PB 级别,传统的解决方案是通过 OLTP 型数据库处理在线联机交易业务,通过 ETL 工具将数据同步到 OLAP 型数据库进行数据分析,这种处理方案存在存储成本高、实时性差等多方面的问题。TiDB 在 4.0 版本中引入列存储引擎 TiFlash 结合行存储引擎 TiKV 构建真正的 HTAP 数据库,在增加少量存储成本的情况下,可以在同一个系统中做联机交易处理、实时数据分析,极大地节省企业的成本。
- 数据汇聚、二次加工处理的场景
当前绝大部分企业的业务数据都分散在不同的系统中,没有一个统一的汇总,随着业务的发展,企业的决策层需要了解整个公司的业务状况以便及时做出决策,故需要将分散在各个系统的数据汇聚在同一个系统并进行二次加工处理生成 T+0 或 T+1 的报表。传统常见的解决方案是采用 ETL + Hadoop 来完成,但 Hadoop 体系太复杂,运维、存储成本太高无法满足用户的需求。与 Hadoop 相比,TiDB 就简单得多,业务通过 ETL 工具或者 TiDB 的同步工具将数据同步到 TiDB,在 TiDB 中可通过 SQL 直接生成报表。
总结
传统关系型数据库历史比较久,目前RDBMS的代表为Oracle、MySQL、PostgreSQL,在数据库领域也是“辈份”比较高的,其广泛应用在各行各业,RDBMS大多为本地存储或共享存储。
但是此类数据库存在着一些问题,如自身容量的限制。随着业务量不断增加,容量渐渐成为瓶颈,此时DBA会通过多次的库表sharding,以此来缓解容量问题。大量的分库分表,不仅耗费了大量人力,还使得业务访问数据库的路由逻辑变得复杂。除此之外,RDBMS伸缩性比较差,通常集群扩容缩容成本较高,且不满足分布式的事务。
NoSQL类数据库的代表为Hbase、Redis、MongoDB、Cassandra等,这类数据库解决了 RDBMS伸缩性差的问题,集群容量扩容变得方便很多,但是由于存储方式为多个KV存储,所以对SQL的兼容性就大打折扣。对于NoSQL类数据库来说,只能满足部分分布式事务的特点。
NewSQL领域的代表是Google的spanner和F1,其号称可以实现全球数据中心容灾,且完全满足分布式事务的ACID,但是只能在Google云上使用。TiDB诞生在大背景下,也弥补了国内在NewSQL领域中的空缺。TiDB自2015年5月写下第一行代码以来,至今已发布大小版本几十次,版本迭代十分迅速
TiDB数据库简介
TiDB概述
TiDB数据库官方网址:https://pingcap.com/zh/
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景
数据库分类梳理
SQL、NoSQL、NewSQL
SQL
关系型数据库(RDBMS,即SQL数据库)
商业软件: Oracle,DB2
开源软件:MySQL,PostgreSQL
关系型数据库面临的单机版本已经很难满足海量数据的需求
NoSQL
NoSQL = Not Only SQL,意即“不仅仅是SQL,提倡运用非关系型的数据存储
普遍选择牺牲掉复杂 SQL 的支持及 ACID 事务换取弹性扩展能力
通常不保证强一致性的(支持最终一致)
主要分类
- 键值(Key-Value)数据库:如 MemcacheDB,Redis
- 文档存储:如 MongoDB
- 列存储:方便存储结构化和半结构化数据,并做数据压缩,对某几列的查询有非常大的IO优势: 如 HBase,Cassandra
- 图数据库:存储图关系(注意:不是图片)。如 Neo4J
NewSQL
针对OLTP的读写,提供与NOSQL相同的可扩展性和性能,同时能支持满足ACID特性的事务,即保持NoSQL的高可扩展和高性能,并且保持关系模型
为什么需要NewSQL
-
NoSQL 不能完全取代 RDBMS
-
单机RDBMS 无法满足性能需求
-
使用“单机RDBMS + 中间件”方式,在中间件层很难解决分布式事务、高可用问题
NewSQL设计架构
- 可以基于全新的数据库平台,也可以基于现有的SQL引擎优化。
- 无共享存储(MPP架构)是比较常见的架构
- 基于多副本实现高可用和容灾
- 分布式查询
- 数据Sharding机制
- 通过2PC,Paxos/Raft等协议实现数据一致
代表产品
- Google Spanner
- OceanBase
- TiDB
OLTP、OLAP
OLTP
-
强调支持短时间内大量并发的事务操作(增删改查)能力,每个操作涉及的数据量都很小(比如几十到几百字节)
-
强调事务的强一致性(如银行转账交易,差错零容忍)
举例:“双十一”期间,可能有几十万用户在同一秒内下订单。后台数据库要能够并发的、以近乎实时的速度处理这些订单请求
OLAP
- 偏向于复杂的只读查询,读取海量数据进行分析计算,查询时间往往很长
举例:“双十一”结束,淘宝的运营人员对订单进行分析挖掘,找出一些市场规律等等。这种分析可能需要读取所有的历史订单进行计算,耗时几十秒甚至几十分钟。
- OLAP代表产品:
- Greenplum
- TeraData
- 阿里AnalyticDB
TiDB诞生
著名的开源分布式缓存服务 Codis 的作者,PingCAP联合创始人& CTO ,资深 infrastructure工程师的黄东旭,擅长分布式存储系统的设计与实现,开源狂热分子的技术大神级别人物。即使在互联网如此繁荣的今天,在数据库这片边界模糊且不确定地带,他还在努力寻找确定性的实践方向。
2012 年底,他看到 Google 发布的两篇论文,如同棱镜般折射出他自己内心微烁的光彩。这两篇论文描述了 Google 内部使用的一个海量关系型数据F1/Spanner,解决了关系型数据库、弹性扩展以及全球分布的问题,并在生产中大规模使用。“如果这个能实现,对数据存储领域来说将是颠覆性的”,黄东旭为完美方案的出现而兴奋, PingCAP 的 TiDB 在此基础上诞生了。
TiDB架构特性
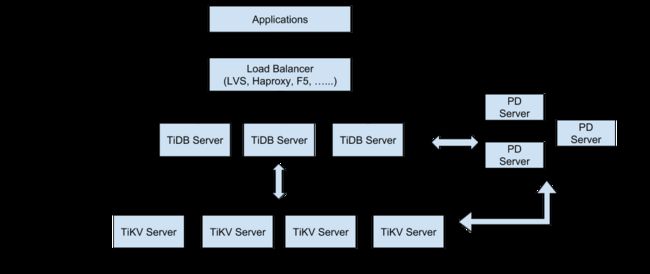
TiDB整体架构
TiDB集群主要包括三个核心组件:TiDB Server,PD Server 和TiKV Server。此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件和简化云上部署管理的 TiDB Operator组件
TiDB作为新一代的NewSQL数据库,在数据库领域已经逐渐站稳脚跟,结合了Etcd/MySQL/HDFS/HBase/Spark等技术的突出特点,随着TiDB的大面积推广,会逐渐弱化OLTP/OLAP的界限,并简化目前冗杂的ETL流程,引起新一轮的技术浪潮。一言以蔽之,TiDB,前景可待,未来可期。
TiDB架构图


TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑并通过 PD Server找到存储计算所需数据的TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:
-
一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);
-
二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);
-
三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度
TiSpark
TiSpark 作为TiDB中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB可以通过一套系统,同时支持OLTP与OLAP,免除用户数据同步的烦恼
TiDB Operator
TiDB Operator 提供在主流云基础设施(Kubernetes)上部署管理 TiDB 集群的能力。它结合云原生社区的容器编排最佳实践与 TiDB 的专业运维知识,集成一键部署、多集群混部、自动运维、故障自愈等能力,极大地降低了用户使用和管理 TiDB 的门槛与成本
TiDB核心特性
TiDB 具备如下众多特性,其中两大核心特性为:水平扩展与高可用
高度兼容 MySQL
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。对于用户使用的时候,可以透明地从MySQL切换到TiDB 中,只是“新MySQL”的后端是存储“无限的”,不再受制于Local的磁盘容量。在运维使用时也可以将TiDB当做一个从库挂到MySQL主从架构中。
分布式事务
TiDB 100% 支持标准的 ACID 事务。
一站式 HTAP 解决方案
HTAP: Hybrid Transactional/Analytical Processing
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
云原生 SQL 数据库
TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,配合 TiDB Operator 项目 可实现自动化运维,使部署、配置和维护变得十分简单。
水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
真正金融级高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入
∩核心特性-水平扩展∩
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力(TiDB)和存储能力(TiKV)。
-
TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐
-
TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。
-
PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。
所以在业务的早期,可以只部署少量的服务实例(推荐至少部署 3 个 TiKV, 3 个 PD,2 个 TiDB),随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
∩核心特性-高可用∩

高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
TiDB
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
PD
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
TiKV
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 节点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 30 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
TiDB存储能力和计算能力
存储能力-TiKV-LSM
TiKV Server通常是3+的,TiDB每份数据缺省为3副本,这一点与HDFS有些相似,但是通过Raft协议进行数据复制,TiKV Server上的数据的是以Region为单位进行,由PD Server集群进行统一调度,类似HBASE的Region调度。
TiKV集群存储的数据格式是KV的,在TiDB中,并不是将数据直接存储在 HDD/SSD中,而是通过RocksDB实现了TB级别的本地化存储方案,着重提的一点是:RocksDB和HBASE一样,都是通过 LSM树作为存储方案,避免了B+树叶子节点膨胀带来的大量随机读写。从而提升了整体的吞吐量
计算能力-TiDB Server
TiDB Server本身是无状态的,意味着当计算能力成为瓶颈的时候,可以直接扩容机器,对用户是透明的。理论上TiDB Server的数量并没有上限限制
TiDB实验环境安装部署
[注意]:这里先部署一个实验环境用于快速了解熟悉,生产级别的安装部署放后面介绍
单机上模拟部署生产环境集群
申请一台阿里云ECS云主机实例作为部署环境,抢占式资源,全部选便宜的选项即可,使用一天仅几块钱
可以预设好root密码,之后使用公网ip使用xshell连接,如果本地有服务器,使用自己现有服务器即可

机器环境信息:
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# free -g
total used free shared buff/cache available
Mem: 30 0 29 0 0 30
Swap: 0 0 0
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
安装MySQL-mariadb-server
安装MySQL-mariadb-server用于连接TiDB数据库,和后续测试使用
# yum安装
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# yum install mariadb* -y
# 启动服务和开机自启
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# systemctl start mariadb && systemctl enable mariadb
Created symlink from /etc/systemd/system/multi-user.target.wants/mariadb.service to /usr/lib/systemd/system/mariadb.service.
[root@iZ0jlfl8zktqzyt15o1o16Z ~]#
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# netstat -tnlpu|grep 3306
tcp6 0 0 :::3306 :::* LISTEN 11576/mysqld
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# mysql -uroot -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 2
Server version: 5.5.68-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root@123';
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'USER 'root'@'localhost' IDENTIFIED BY 'Root@123'' at line 1
MariaDB [(none)]> use mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MariaDB [mysql]> UPDATE user SET password=password('123456') WHERE user='root';
Query OK, 4 rows affected (0.00 sec)
Rows matched: 4 Changed: 4 Warnings: 0
MariaDB [mysql]> flush privileges;
Query OK, 0 rows affected (0.00 sec)
MariaDB [mysql]> exit;
Bye
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# mysql -uroot -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 3
Server version: 5.5.68-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> exit
Bye
[root@iZ0jlfl8zktqzyt15o1o16Z ~]#
安装单机版
在单机上模拟部署生产环境集群
适用场景:希望用单台 Linux 服务器,体验 TiDB 最小的完整拓扑的集群,并模拟生产环境下的部署步骤
# 在单机上模拟部署生产环境集群
# 下载并安装 TiUP
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
WARN: adding root certificate via internet: https://tiup-mirrors.pingcap.com/root.json
You can revoke this by remove /root/.tiup/bin/7b8e153f2e2d0928.root.json
Successfully set mirror to https://tiup-mirrors.pingcap.com
Detected shell: bash
Shell profile: /root/.bash_profile
/root/.bash_profile has been modified to add tiup to PATH
open a new terminal or source /root/.bash_profile to use it
Installed path: /root/.tiup/bin/tiup
===============================================
Have a try: tiup playground
===============================================
# 根据提示source引入环境变量
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# source /root/.bash_profile
# 安装 TiUP 的 cluster 组件
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# tiup cluster
tiup is checking updates for component cluster ...
A new version of cluster is available:
The latest version: v1.10.3
Local installed version:
Update current component: tiup update cluster
Update all components: tiup update --all
The component `cluster` version is not installed; downloading from repository.
download https://tiup-mirrors.pingcap.com/cluster-v1.10.3-linux-amd64.tar.gz 8.28 MiB / 8.28 MiB 100.00% 12.07 MiB/s
Starting component `cluster`: /root/.tiup/components/cluster/v1.10.3/tiup-cluster
Deploy a TiDB cluster for production
# 根据提示信息需要update
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# tiup update --self && tiup update cluster
download https://tiup-mirrors.pingcap.com/tiup-v1.10.3-linux-amd64.tar.gz 6.81 MiB / 6.81 MiB 100.00% 12.83 MiB/s
Updated successfully!
component cluster version v1.10.3 is already installed
Updated successfully!
# 由于模拟多机部署,需要通过 root 用户调大 sshd 服务的连接数限制
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# cat /etc/ssh/sshd_config | grep MaxSessions
#MaxSessions 10
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# echo "MaxSessions 20" >> /etc/ssh/sshd_config
# 或者vim打开文件打开注释,把10改为20保存
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# cat /etc/ssh/sshd_config | grep MaxSessions|grep -vE "^#"
MaxSessions 20
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# service sshd restart
Redirecting to /bin/systemctl restart sshd.service
# 创建启动机器定义文件
#按下面的配置模板,编辑配置文件,命名为 topo.yaml,其中:
#user: "tidb":表示通过 tidb 系统用户(部署会自动创建)来做集群的内部管理,默认使用 22 端口通过 ssh 登录目标机器
#replication.enable-placement-rules:设置这个 PD 参数来确保 TiFlash 正常运行
#host:设置为本部署主机的 IP
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# vi topo.yaml
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/tidb-deploy"
data_dir: "/tidb-data"
# # Monitored variables are applied to all the machines.
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
server_configs:
tidb:
log.slow-threshold: 300
tikv:
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
pd:
replication.enable-placement-rules: true
replication.location-labels: ["host"]
tiflash:
logger.level: "info"
pd_servers:
- host: 172.28.54.199
tidb_servers:
- host: 172.28.54.199
tikv_servers:
- host: 172.28.54.199
port: 20160
status_port: 20180
config:
server.labels: { host: "logic-host-1" }
- host: 172.28.54.199
port: 20161
status_port: 20181
config:
server.labels: { host: "logic-host-2" }
- host: 172.28.54.199
port: 20162
status_port: 20182
config:
server.labels: { host: "logic-host-3" }
tiflash_servers:
- host: 172.28.54.199
monitoring_servers:
- host: 172.28.54.199
grafana_servers:
- host: 172.28.54.199
# 查看可以部署的版本信息
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# tiup list tidb
# tiup cluster deploy ./topo.yaml --user root -p
#参数 表示设置集群名称
#参数 表示设置集群版本,可以通过 tiup list tidb 命令来查看当前支持部署的 TiDB 版本
#参数 -p 表示在连接目标机器时使用密码登录
# 按照引导,输入”y”及 root 密码,来完成部署:
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# tiup cluster deploy wangtingtidb v5.2.4 ./topo.yaml --user root -p
tiup is checking updates for component cluster ...
Starting component `cluster`: /root/.tiup/components/cluster/v1.10.3/tiup-cluster deploy wangtingtidb v5.2.4 ./topo.yaml --user root -p
Input SSH password:
+ Detect CPU Arch Name
- Detecting node 172.28.54.199 Arch info ... Done
+ Detect CPU OS Name
- Detecting node 172.28.54.199 OS info ... Done
Please confirm your topology:
Cluster type: tidb
Cluster name: wangtingtidb
Cluster version: v5.2.4
Role Host Ports OS/Arch Directories
---- ---- ----- ------- -----------
pd 172.28.54.199 2379/2380 linux/x86_64 /tidb-deploy/pd-2379,/tidb-data/pd-2379
tikv 172.28.54.199 20160/20180 linux/x86_64 /tidb-deploy/tikv-20160,/tidb-data/tikv-20160
tikv 172.28.54.199 20161/20181 linux/x86_64 /tidb-deploy/tikv-20161,/tidb-data/tikv-20161
tikv 172.28.54.199 20162/20182 linux/x86_64 /tidb-deploy/tikv-20162,/tidb-data/tikv-20162
tidb 172.28.54.199 4000/10080 linux/x86_64 /tidb-deploy/tidb-4000
tiflash 172.28.54.199 9000/8123/3930/20170/20292/8234 linux/x86_64 /tidb-deploy/tiflash-9000,/tidb-data/tiflash-9000
prometheus 172.28.54.199 9090 linux/x86_64 /tidb-deploy/prometheus-9090,/tidb-data/prometheus-9090
grafana 172.28.54.199 3000 linux/x86_64 /tidb-deploy/grafana-3000
Attention:
1. If the topology is not what you expected, check your yaml file.
2. Please confirm there is no port/directory conflicts in same host.
Do you want to continue? [y/N]: (default=N) y
+ Generate SSH keys ... Done
+ Download TiDB components
- Download pd:v5.2.4 (linux/amd64) ... Done
- Download tikv:v5.2.4 (linux/amd64) ... Done
- Download tidb:v5.2.4 (linux/amd64) ... Done
- Download tiflash:v5.2.4 (linux/amd64) ... Done
- Download prometheus:v5.2.4 (linux/amd64) ... Done
- Download grafana:v5.2.4 (linux/amd64) ... Done
- Download node_exporter: (linux/amd64) ... Done
- Download blackbox_exporter: (linux/amd64) ... Done
+ Initialize target host environments
- Prepare 172.28.54.199:22 ... Done
+ Deploy TiDB instance
- Copy pd -> 172.28.54.199 ... Done
- Copy tikv -> 172.28.54.199 ... Done
- Copy tikv -> 172.28.54.199 ... Done
- Copy tikv -> 172.28.54.199 ... Done
- Copy tidb -> 172.28.54.199 ... Done
- Copy tiflash -> 172.28.54.199 ... Done
- Copy prometheus -> 172.28.54.199 ... Done
- Copy grafana -> 172.28.54.199 ... Done
- Deploy node_exporter -> 172.28.54.199 ... Done
- Deploy blackbox_exporter -> 172.28.54.199 ... Done
+ Copy certificate to remote host
+ Init instance configs
- Generate config pd -> 172.28.54.199:2379 ... Done
- Generate config tikv -> 172.28.54.199:20160 ... Done
- Generate config tikv -> 172.28.54.199:20161 ... Done
- Generate config tikv -> 172.28.54.199:20162 ... Done
- Generate config tidb -> 172.28.54.199:4000 ... Done
- Generate config tiflash -> 172.28.54.199:9000 ... Done
- Generate config prometheus -> 172.28.54.199:9090 ... Done
- Generate config grafana -> 172.28.54.199:3000 ... Done
+ Init monitor configs
- Generate config node_exporter -> 172.28.54.199 ... Done
- Generate config blackbox_exporter -> 172.28.54.199 ... Done
+ Check status
Enabling component pd
Enabling instance 172.28.54.199:2379
Enable instance 172.28.54.199:2379 success
Enabling component tikv
Enabling instance 172.28.54.199:20162
Enabling instance 172.28.54.199:20160
Enabling instance 172.28.54.199:20161
Enable instance 172.28.54.199:20160 success
Enable instance 172.28.54.199:20162 success
Enable instance 172.28.54.199:20161 success
Enabling component tidb
Enabling instance 172.28.54.199:4000
Enable instance 172.28.54.199:4000 success
Enabling component tiflash
Enabling instance 172.28.54.199:9000
Enable instance 172.28.54.199:9000 success
Enabling component prometheus
Enabling instance 172.28.54.199:9090
Enable instance 172.28.54.199:9090 success
Enabling component grafana
Enabling instance 172.28.54.199:3000
Enable instance 172.28.54.199:3000 success
Enabling component node_exporter
Enabling instance 172.28.54.199
Enable 172.28.54.199 success
Enabling component blackbox_exporter
Enabling instance 172.28.54.199
Enable 172.28.54.199 success
Cluster `wangtingtidb` deployed successfully, you can start it with command: `tiup cluster start wangtingtidb --init`
# 根据提示命令tiup cluster start wangtingtidb --init启动集群
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# tiup cluster start wangtingtidb --init
tiup is checking updates for component cluster ...
Starting component `cluster`: /root/.tiup/components/cluster/v1.10.3/tiup-cluster start wangtingtidb --init
Starting cluster wangtingtidb...
+ [ Serial ] - SSHKeySet: privateKey=/root/.tiup/storage/cluster/clusters/wangtingtidb/ssh/id_rsa, publicKey=/root/.tiup/storage/cluster/clusters/wangtingtidb/ssh/id_rsa.pub
+ [Parallel] - UserSSH: user=tidb, host=172.28.54.199
+ [Parallel] - UserSSH: user=tidb, host=172.28.54.199
+ [Parallel] - UserSSH: user=tidb, host=172.28.54.199
+ [Parallel] - UserSSH: user=tidb, host=172.28.54.199
+ [Parallel] - UserSSH: user=tidb, host=172.28.54.199
+ [Parallel] - UserSSH: user=tidb, host=172.28.54.199
+ [Parallel] - UserSSH: user=tidb, host=172.28.54.199
+ [Parallel] - UserSSH: user=tidb, host=172.28.54.199
+ [ Serial ] - StartCluster
Starting component pd
Starting instance 172.28.54.199:2379
Start instance 172.28.54.199:2379 success
Starting component tikv
Starting instance 172.28.54.199:20162
Starting instance 172.28.54.199:20160
Starting instance 172.28.54.199:20161
Start instance 172.28.54.199:20160 success
Start instance 172.28.54.199:20161 success
Start instance 172.28.54.199:20162 success
Starting component tidb
Starting instance 172.28.54.199:4000
Start instance 172.28.54.199:4000 success
Starting component tiflash
Starting instance 172.28.54.199:9000
Start instance 172.28.54.199:9000 success
Starting component prometheus
Starting instance 172.28.54.199:9090
Start instance 172.28.54.199:9090 success
Starting component grafana
Starting instance 172.28.54.199:3000
Start instance 172.28.54.199:3000 success
Starting component node_exporter
Starting instance 172.28.54.199
Start 172.28.54.199 success
Starting component blackbox_exporter
Starting instance 172.28.54.199
Start 172.28.54.199 success
+ [ Serial ] - UpdateTopology: cluster=wangtingtidb
Started cluster `wangtingtidb` successfully
The root password of TiDB database has been changed.
The new password is: 'rpi381$9*!cvX07D-w'.
Copy and record it to somewhere safe, it is only displayed once, and will not be stored.
The generated password can NOT be get and shown again.
# 注意TiDB的初始密码会控制台输出,拷贝留存一份
[root@iZ0jlfl8zktqzyt15o1o16Z ~]#
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# mysql -h 172.28.54.199 -P 4000 -u root -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 15
Server version: 5.7.25-TiDB-v5.2.4 TiDB Server (Apache License 2.0) Community Edition, MySQL 5.7 compatible
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> use mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MySQL [mysql]> Set password for 'root'@'%'=password('123456');
Query OK, 0 rows affected (0.02 sec)
MySQL [mysql]> flush privileges;
Query OK, 0 rows affected (0.01 sec)
MySQL [mysql]> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
Query OK, 0 rows affected (0.02 sec)
MySQL [mysql]> exit;
Bye
验证集群
# 执行以下命令确认当前已经部署的集群列表:
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# tiup cluster list
tiup is checking updates for component cluster ...
Starting component `cluster`: /root/.tiup/components/cluster/v1.10.3/tiup-cluster list
Name User Version Path PrivateKey
---- ---- ------- ---- ----------
wangtingtidb tidb v5.2.4 /root/.tiup/storage/cluster/clusters/wangtingtidb /root/.tiup/storage/cluster/clusters/wangtingtidb/ssh/id_rsa
# 执行以下命令查看集群的拓扑结构和状态:
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# tiup cluster display wangtingtidb
tiup is checking updates for component cluster ...
Starting component `cluster`: /root/.tiup/components/cluster/v1.10.3/tiup-cluster display wangtingtidb
Cluster type: tidb
Cluster name: wangtingtidb
Cluster version: v5.2.4
Deploy user: tidb
SSH type: builtin
Dashboard URL: http://172.28.54.199:2379/dashboard
Grafana URL: http://172.28.54.199:3000
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
172.28.54.199:3000 grafana 172.28.54.199 3000 linux/x86_64 Up - /tidb-deploy/grafana-3000
172.28.54.199:2379 pd 172.28.54.199 2379/2380 linux/x86_64 Up|L|UI /tidb-data/pd-2379 /tidb-deploy/pd-2379
172.28.54.199:9090 prometheus 172.28.54.199 9090 linux/x86_64 Up /tidb-data/prometheus-9090 /tidb-deploy/prometheus-9090
172.28.54.199:4000 tidb 172.28.54.199 4000/10080 linux/x86_64 Up - /tidb-deploy/tidb-4000
172.28.54.199:9000 tiflash 172.28.54.199 9000/8123/3930/20170/20292/8234 linux/x86_64 Up /tidb-data/tiflash-9000 /tidb-deploy/tiflash-9000
172.28.54.199:20160 tikv 172.28.54.199 20160/20180 linux/x86_64 Up /tidb-data/tikv-20160 /tidb-deploy/tikv-20160
172.28.54.199:20161 tikv 172.28.54.199 20161/20181 linux/x86_64 Up /tidb-data/tikv-20161 /tidb-deploy/tikv-20161
172.28.54.199:20162 tikv 172.28.54.199 20162/20182 linux/x86_64 Up /tidb-data/tikv-20162 /tidb-deploy/tikv-20162
Total nodes: 8
访问 TiDB 的 Grafana 监控:
通过 http://39.101.65.150:3000 访问集群 Grafana 监控页面,默认用户名和密码均为 admin。
第一次访问需要修改初始密码,改为123456

访问 TiDB 的 Dashboard:
通过 http://39.101.65.150:2379/dashboard 访问集群 TiDB Dashboard 监控页面,默认用户名为 root,密码为刚才MySQL中新设置的123456

# 命令行在mariadb和TiDB分别建库
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# mysql -u root -P 3306 -h 39.101.65.150 -p"123456" -e "create database mariadb_666;"
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# mysql -u root -P 4000 -h 39.101.65.150 -p"123456" -e "create database tidb_666;"
可以看到在两个数据库中均已经看到
TiDB使用介绍
SQL操作
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# mysql -u root -P 4000 -h 39.101.65.150 -p"123456"
Welcome to the MariaDB monitor. Commands end with ; or \g.
# 创建一个名为 samp_db 的数据库
MySQL [(none)]> CREATE DATABASE IF NOT EXISTS samp_db;
Query OK, 0 rows affected (0.08 sec)
# 查看数据库
MySQL [(none)]> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
| METRICS_SCHEMA |
| PERFORMANCE_SCHEMA |
| mysql |
| samp_db |
| test |
| tidb_666 |
+--------------------+
7 rows in set (0.01 sec)
# 删除数据库
MySQL [(none)]> DROP DATABASE samp_db;
Query OK, 0 rows affected (0.19 sec)
MySQL [(none)]> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
| METRICS_SCHEMA |
| PERFORMANCE_SCHEMA |
| mysql |
| test |
| tidb_666 |
+--------------------+
6 rows in set (0.01 sec)
MySQL [(none)]> CREATE DATABASE IF NOT EXISTS samp_db;
Query OK, 0 rows affected (0.08 sec)
# 切换数据库
MySQL [(none)]> USE samp_db;
Database changed
# 创建表
MySQL [samp_db]> CREATE TABLE IF NOT EXISTS person (
-> number INT(11),
-> name VARCHAR(255),
-> birthday DATE
-> );
Query OK, 0 rows affected (0.08 sec)
# 查看建表语句
MySQL [samp_db]> SHOW CREATE table person;
+--------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+--------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| person | CREATE TABLE `person` (
`number` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`birthday` date DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin |
+--------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
# 查看表的列
MySQL [samp_db]> SHOW FULL COLUMNS FROM person;
+----------+--------------+-------------+------+------+---------+-------+---------------------------------+---------+
| Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment |
+----------+--------------+-------------+------+------+---------+-------+---------------------------------+---------+
| number | int(11) | NULL | YES | | NULL | | select,insert,update,references | |
| name | varchar(255) | utf8mb4_bin | YES | | NULL | | select,insert,update,references | |
| birthday | date | NULL | YES | | NULL | | select,insert,update,references | |
+----------+--------------+-------------+------+------+---------+-------+---------------------------------+---------+
3 rows in set (0.00 sec)
MySQL [samp_db]> DROP TABLE IF EXISTS person;
Query OK, 0 rows affected (0.20 sec)
MySQL [samp_db]> CREATE TABLE IF NOT EXISTS person (
-> number INT(11),
-> name VARCHAR(255),
-> birthday DATE
-> );
Query OK, 0 rows affected (0.08 sec)
# 创建索引,对于值不唯一的列,可使用 CREATE INDEX 或 ALTER TABLE 语句
MySQL [samp_db]> CREATE INDEX person_num ON person (number);
Query OK, 0 rows affected (2.76 sec)
# 查看表内所有索引
MySQL [samp_db]> SHOW INDEX from person;
+--------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+-----------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | Clustered |
+--------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+-----------+
| person | 1 | person_num | 1 | number | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL | NO |
+--------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+-----------+
1 row in set (0.01 sec)
# 删除索引
MySQL [samp_db]> DROP INDEX person_num ON person;
Query OK, 0 rows affected (0.26 sec)
# 创建唯一索引
MySQL [samp_db]> CREATE UNIQUE INDEX person_num ON person (number);
Query OK, 0 rows affected (2.76 sec)
# 插入数据
MySQL [samp_db]> INSERT INTO person VALUES("1","tom","20170912");
Query OK, 1 row affected (0.01 sec)
# 查数据
MySQL [samp_db]> SELECT * FROM person;
+--------+------+------------+
| number | name | birthday |
+--------+------+------------+
| 1 | tom | 2017-09-12 |
+--------+------+------------+
1 row in set (0.01 sec)
# 修改表内数据
MySQL [samp_db]> UPDATE person SET birthday='20200202' WHERE name='tom';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL [samp_db]> SELECT * FROM person;
+--------+------+------------+
| number | name | birthday |
+--------+------+------------+
| 1 | tom | 2020-02-02 |
+--------+------+------------+
1 row in set (0.00 sec)
# 删除表内数据
MySQL [samp_db]> DELETE FROM person WHERE number=1;
Query OK, 1 row affected (0.01 sec)
MySQL [samp_db]> SELECT * FROM person;
Empty set (0.01 sec)
# 创建一个用户 tiuser,登录为本地localhost访问
MySQL [samp_db]> CREATE USER 'tiuser'@'localhost' IDENTIFIED BY '123456';
Query OK, 0 rows affected (0.02 sec)
# 本地验证
[root@iZ0jlfl8zktqzyt15o1o16Z ~]# mysql -u tiuser -P 4000 -h 127.0.0.1 -p"123456"
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 99
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
+--------------------+
1 row in set (0.00 sec)
MySQL [(none)]>

远程不能访问
授权普通用户远程访问:
MySQL [mysql]> update user set host='%' where user='tiuser';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL [mysql]> flush privileges;
Query OK, 0 rows affected (0.00 sec)
授权普通用户访问库权限:
MySQL [mysql]> GRANT SELECT ON samp_db.* TO 'tiuser'@'%';
Query OK, 0 rows affected (0.01 sec)
MySQL [mysql]> SHOW GRANTS for 'tiuser'@'%';
+-------------------------------------------+
| Grants for tiuser@% |
+-------------------------------------------+
| GRANT USAGE ON *.* TO 'tiuser'@'%' |
| GRANT SELECT ON samp_db.* TO 'tiuser'@'%' |
+-------------------------------------------+
2 rows in set (0.00 sec)

删除用户
# 删除用户 tiuser
MySQL [samp_db]> DROP USER 'tiuser'@'localhost';
Query OK, 0 rows affected (0.03 sec)
# 查看所有权限
MySQL [samp_db]> SHOW GRANTS;
+-------------------------------------------------------------+
| Grants for User |
+-------------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION |
+-------------------------------------------------------------+
1 row in set (0.00 sec)
MySQL [samp_db]>
读取历史数据
功能说明
TiDB 实现了通过标准 SQL 接口读取历史数据功能,无需特殊的 client 或者 driver。当数据被更新、删除后,依然可以通过 SQL 接口将更新/删除前的数据读取出来。
另外即使在更新数据之后,表结构发生了变化,TiDB 依旧能用旧的表结构将数据读取出来
操作流程
为支持读取历史版本数据, 引入了一个新的 system variable: tidb_snapshot ,这个变量是 Session 范围有效,可以通过标准的 Set 语句修改其值。其值为文本,能够存储 TSO 和日期时间。TSO 即是全局授时的时间戳,是从 PD 端获取的; 日期时间的格式可以为: “2020-10-08 16:45:26.999”,一般来说可以只写到秒,比如”2020-10-08 16:45:26”。 当这个变量被设置时,TiDB 会用这个时间戳建立 Snapshot(没有开销,只是创建数据结构),随后所有的 Select 操作都会在这个 Snapshot 上读取数据。
注意:
TiDB 的事务是通过 PD 进行全局授时,所以存储的数据版本也是以 PD 所授时间戳作为版本号。在生成 Snapshot 时,是以 tidb_snapshot 变量的值作为版本号,如果 TiDB Server 所在机器和 PD Server 所在机器的本地时间相差较大,需要以 PD 的时间为准。
当读取历史版本操作结束后,可以结束当前 Session 或者是通过 Set 语句将 tidb_snapshot 变量的值设为 “",即可读取最新版本的数据
历史数据保留策略
TiDB 使用 MVCC 管理版本,当更新/删除数据时,不会做真正的数据删除,只会添加一个新版本数据,所以可以保留历史数据。历史数据不会全部保留,超过一定时间的历史数据会被彻底删除,以减小空间占用以及避免历史版本过多引入的性能开销。
TiDB 使用周期性运行的 GC(Garbage Collection,垃圾回收)来进行清理,关于 GC 的详细介绍参见 TiDB 垃圾回收 (GC)。
这里需要重点关注的是 tikv_gc_life_time 和 tikv_gc_safe_point 这条。tikv_gc_life_time 用于配置历史版本保留时间,可以手动修改;tikv_gc_safe_point 记录了当前的 safePoint,用户可以安全地使用大于 safePoint 的时间戳创建 snapshot 读取历史版本。safePoint 在每次 GC 开始运行时自动更新
读取历史数据操作示例
# 创建一个表,并插入几行测试数据
MySQL [mysql]> create table t (c int);
Query OK, 0 rows affected (0.08 sec)
MySQL [mysql]> insert into t values (1), (2), (3);
Query OK, 3 rows affected (0.04 sec)
Records: 3 Duplicates: 0 Warnings: 0
# 查看表中的数据
MySQL [mysql]> select * from t;
+------+
| c |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.00 sec)
# 查看当前时间,一般这个时间可以理解成数据的版本和时间挂钩,在某个时间点前和后有变动,查询时可以以时间为参照点
MySQL [mysql]> select now();
+---------------------+
| now() |
+---------------------+
| 2022-08-22 10:17:26 |
+---------------------+
1 row in set (0.01 sec)
# 更新某一行数据
MySQL [mysql]> update t set c=222222 where c=2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL [mysql]> select * from t;
+--------+
| c |
+--------+
| 1 |
| 222222 |
| 3 |
+--------+
3 rows in set (0.00 sec)
# 设置一个特殊的环境变量,这个是一个 session scope 的变量,其意义为读取这个时间之前的最新的一个版本,也就时查询数据时不再是实时数据,而是截至到2022-08-22 10:17:26时间的数据,这个时间之后的数据修改不体现,从而实现查询历史数据
MySQL [mysql]> set @@tidb_snapshot="2022-08-22 10:17:26";
Query OK, 0 rows affected (0.00 sec)
#注意:
#这里的时间设置的是 update 语句之前的那个时间。
#在 tidb_snapshot 前须使用 @@ 而非 @,因为 @@ 表示系统变量,@ 表示用户变量
MySQL [mysql]> select * from t;
+------+
| c |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.00 sec)
# 清空这个变量后,即可读取最新版本数据
MySQL [mysql]> set @@tidb_snapshot="";
Query OK, 0 rows affected (0.00 sec)
MySQL [mysql]> select * from t;
+--------+
| c |
+--------+
| 1 |
| 222222 |
| 3 |
+--------+
3 rows in set (0.00 sec)
TiDB技术原理
数据库、操作系统和编译器并称为三大系统,可以说是整个计算机软件的基石。其中数据库更靠近应用层,是很多业务的支撑。这一领域经过了几十年的发展,不断的有新的进展。
很多人用过数据库,但是很少有人实现过一个数据库,特别是实现一个分布式数据库。了解数据库的实现原理和细节,一方面可以提高个人技术,对构建其他系统有帮助,另一方面也有利于用好数据库。
研究一门技术最好的方法是研究其中一个开源项目,数据库也不例外。单机数据库领域有很多很好的开源项目,其中 MySQL 和 PostgreSQL 是其中知名度最高的两个,不少同学都看过这两个项目的代码。但是分布式数据库方面,好的开源项目并不多。 TiDB 目前获得了广泛的关注,特别是一些技术爱好者,希望能够参与这个项目。由于分布式数据库自身的复杂性,很多人并不能很好的理解整个项目,所以我希望能写一些文章,自顶向下,由浅入深,讲述 TiDB 的一些技术原理,包括用户可见的技术以及大量隐藏在 SQL 界面后用户不可见的技术点
数据存储
数据库最根本的功能是能把数据存下来,所以我们从这里开始。
保存数据的方法很多,最简单的方法是直接在内存中建一个数据结构,保存用户发来的数据。比如用一个数组,每当收到一条数据就向数组中追加一条记录。这个方案十分简单,能满足最基本,并且性能肯定会很好,但是除此之外却是漏洞百出,其中最大的问题是数据完全在内存中,一旦停机或者是服务重启,数据就会永久丢失。
为了解决数据丢失问题,我们可以把数据放在非易失存储介质(比如硬盘)中。改进的方案是在磁盘上创建一个文件,收到一条数据,就在文件中 Append 一行。OK,我们现在有了一个能持久化存储数据的方案。但是还不够好,假设这块磁盘出现了坏道呢?我们可以做 RAID (Redundant Array of Independent Disks),提供单机冗余存储。如果整台机器都挂了呢?比如出现了火灾,RAID 也保不住这些数据。我们还可以将存储改用网络存储,或者是通过硬件或者软件进行存储复制。到这里似乎我们已经解决了数据安全问题,可以松一口气了。But,做复制过程中是否能保证副本之间的一致性?也就是在保证数据不丢的前提下,还要保证数据不错。保证数据不丢不错只是一项最基本的要求,还有更多令人头疼的问题等待解决:
• 能否支持跨数据中心的容灾?
• 写入速度是否够快?
• 数据保存下来后,是否方便读取?
• 保存的数据如何修改?如何支持并发的修改?
• 如何原子地修改多条记录?
这些问题每一项都非常难,但是要做一个优秀的数据存储系统,必须要解决上述的每一个难题。 为了解决数据存储问题,我们开发了 TiKV 这个项目。接下来我向大家介绍一下 TiKV 的一些设计思想和基本概念
Key-Value
作为保存数据的系统,首先要决定的是数据的存储模型,也就是数据以什么样的形式保存下来。TiKV 的选择是 Key-Value 模型,并且提供有序遍历方法。简单来讲,可以将 TiKV 看做一个巨大的 Map,其中 Key 和 Value 都是原始的 Byte 数组,在这个 Map 中,Key 按照 Byte 数组总的原始二进制比特位比较顺序排列。
-
这是一个巨大的 Map,也就是存储的是 Key-Value pair
-
这个 Map 中的 Key-Value pair 按照 Key 的二进制顺序有序,也就是我们可以 Seek 到某一个 Key 的位置,然后不断的调用 Next 方法以递增的顺序获取比这个 Key 大的 Key-Value
现在让我们忘记 SQL 中的任何概念,专注于讨论如何实现 TiKV 这样一个高性能高可靠性的巨大的(分布式的) Map
RocksDB
任何持久化的存储引擎,数据终归要保存在磁盘上,TiKV 也不例外。但是 TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。这个选择的原因是开发一个单机存储引擎工作量很大,特别是要做一个高性能的单机引擎,需要做各种细致的优化,而 RocksDB 是一个非常优秀的开源的单机存储引擎,可以满足我们对单机引擎的各种要求,而且还有 Facebook 的团队在做持续的优化,这样我们只投入很少的精力,就能享受到一个十分强大且在不断进步的单机引擎。当然,我们也为 RocksDB 贡献了一些代码,希望这个项目能越做越好。这里可以简单的认为 RocksDB 是一个单机的 Key-Value Map。
底层LSM树将对数据的修改增量保存在内存中,达到指定大小限制之后批量把数据flush到磁盘中,磁盘中树定期可以做merge操作,合并成一棵大树,以优化性能。
Raft
如何保证单机失效的情况下,数据不丢失,不出错?简单来说,我们需要想办法把数据复制到多台机器上,这样一台机器挂了,我们还有其他的机器上的副本;复杂来说,我们还需要这个复制方案是可靠、高效并且能处理副本失效的情况。听上去比较难,但是好在我们有 Raft 协议。Raft 是一个一致性算法,它和 Paxos 等价,但是更加易于理解。Raft 的论文,感兴趣的可以看一下。本文只会对 Raft 做一个简要的介绍,细节问题可以参考论文。另外提一点,Raft 论文只是一个基本方案,严格按照论文实现,性能会很差,我们对 Raft 协议的实现做了大量的优化,具体的优化细节可参考tangliu 同学的《TiKV 源码解析系列 - Raft 的优化》这篇文章。
Raft 是一个一致性协议,提供几个重要的功能:
1.Leader 选举
2.成员变更
3.日志复制
TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到 Group 的多数节点中

通过单机的 RocksDB,我们可以将数据快速地存储在磁盘上;通过 Raft,我们可以将数据复制到多台机器上,以防单机失效。数据的写入是通过 Raft 这一层的接口写入,而不是直接写 RocksDB。通过实现 Raft,我们拥有了一个分布式的 KV,现在再也不用担心某台机器挂掉了
Region
讲到这里,我们可以提到一个 非常重要的概念:Region。这个概念是理解后续一系列机制的基础,请仔细阅读这一节。
前面提到,我们将 TiKV 看做一个巨大的有序的 KV Map,那么为了实现存储的水平扩展,我们需要将数据分散在多台机器上。这里提到的数据分散在多台机器上和 Raft 的数据复制不是一个概念,在这一节我们先忘记 Raft,假设所有的数据都只有一个副本,这样更容易理解。
对于一个 KV 系统,将数据分散在多台机器上有两种比较典型的方案:一种是按照 Key 做 Hash,根据 Hash 值选择对应的存储节点;另一种是分 Range,某一段连续的 Key 都保存在一个存储节点上。TiKV 选择了第二种方式,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,我们将每一段叫做一个 Region,并且我们会尽量保持每个 Region 中保存的数据不超过一定的大小(这个大小可以配置,目前默认是 64mb)。每一个 Region 都可以用 StartKey 到 EndKey 这样一个左闭右开区间来描述。

注意,这里的 Region 还是和 SQL 中的表没什么关系! 请各位继续忘记 SQL,只谈 KV。 将数据划分成 Region 后,我们将会做 两件重要的事情:
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多
- 以 Region 为单位做 Raft 的复制和成员管理
先看第一点,数据按照 Key 切分成很多 Region,每个 Region 的数据只会保存在一个节点上面。我们的系统会有一个组件来负责将 Region 尽可能均匀的散布在集群中所有的节点上,这样一方面实现了存储容量的水平扩展(增加新的结点后,会自动将其他节点上的 Region 调度过来),另一方面也实现了负载均衡(不会出现某个节点有很多数据,其他节点上没什么数据的情况)。同时为了保证上层客户端能够访问所需要的数据,我们的系统中也会有一个组件记录 Region 在节点上面的分布情况,也就是通过任意一个 Key 就能查询到这个 Key 在哪个 Region 中,以及这个 Region 目前在哪个节点上。
对于第二点,TiKV 是以 Region 为单位做数据的复制,也就是一个 Region 的数据会保存多个副本,我们将每一个副本叫做一个 Replica。Replica 之间是通过 Raft 来保持数据的一致,一个 Region 的多个 Replica 会保存在不同的节点上,构成一个 Raft Group。其中一个 Replica 会作为这个 Group 的 Leader,其他的 Replica 作为 Follower。所有的读和写都是通过 Leader 进行,再由 Leader 复制给 Follower。

我们以 Region 为单位做数据的分散和复制,就有了一个分布式的具备一定容灾能力的 KeyValue 系统,不用再担心数据存不下,或者是磁盘故障丢失数据的问题。这已经很 Cool,但是还不够完美,我们需要更多的功能。
MVCC
很多数据库都会实现多版本控制(MVCC),TiKV 也不例外。设想这样的场景,两个 Client 同时去修改一个 Key 的 Value,如果没有 MVCC,就需要对数据上锁,在分布式场景下,可能会带来性能以及死锁问题。 TiKV 的 MVCC 实现是通过在 Key 后面添加 Version 来实现,简单来说,没有 MVCC 之前,可以把 TiKV 看做这样的:
Key1 -> Value
Key2 -> Value
……
KeyN -> Value
有了 MVCC 之后,TiKV 的 Key 排列是这样的:
Key1-Version3 -> Value
Key1-Version2 -> Value
Key1-Version1 -> Value
……
Key2-Version4 -> Value
Key2-Version3 -> Value
Key2-Version2 -> Value
Key2-Version1 -> Value
……
KeyN-Version2 -> Value
KeyN-Version1 -> Value
……
注意,对于同一个 Key 的多个版本,我们把版本号较大的放在前面,版本号小的放在后面(回忆一下 Key-Value 一节我们介绍过的 Key 是有序的排列),这样当用户通过一个 Key + Version 来获取 Value 的时候,可以将 Key 和 Version 构造出 MVCC 的 Key,也就是 Key-Version。然后可以直接 Seek(Key-Version),定位到第一个大于等于这个 Key-Version 的位置
事务
TiKV 的事务采用的是 Percolator 模型,并且做了大量的优化。TiKV 的事务采用乐观锁,事务的执行过程中,不会检测写写冲突,只有在提交过程中,才会做冲突检测,冲突的双方中比较早完成提交的会写入成功,另一方会尝试重新执行整个事务。当业务的写入冲突不严重的情况下,这种模型性能会很好,比如随机更新表中某一行的数据,并且表很大。但是如果业务的写入冲突严重,性能就会很差,举一个极端的例子,就是计数器,多个客户端同时修改少量行,导致冲突严重的,造成大量的无效重试。
数据计算
关系模型到 Key-Value 模型的映射
在这我们将关系模型简单理解为 Table 和 SQL 语句,那么问题变为如何在 KV 结构上保存 Table 以及如何在 KV 结构上运行 SQL 语句。 假设我们有这样一个表的定义:
CREATE TABLE User {
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
Key idxAge (age)
};
SQL 和 KV 结构之间存在巨大的区别,那么如何能够方便高效地进行映射,就成为一个很重要的问题。一个好的映射方案必须有利于对数据操作的需求。那么我们先看一下对数据的操作有哪些需求,分别有哪些特点。
对于一个 Table 来说,需要存储的数据包括三部分:
1.表的元信息
2.Table 中的 Row
3.索引数据
表的元信息我们暂时不讨论,后面介绍。
对于 Row,可以选择行存或者列存,这两种各有优缺点。TiDB 面向的首要目标是 OLTP 业务,这类业务需要支持快速地读取、保存、修改、删除一行数据,所以采用行存是比较合适的。
对于 Index,TiDB 不止需要支持 Primary Index,还需要支持 Secondary Index。Index 的作用的辅助查询,提升查询性能,以及保证某些 Constraint。
查询的时候有两种模式,一种是点查,比如通过 Primary Key 或者 Unique Key 的等值条件进行查询,如 select name from user where id=1; ,这种需要通过索引快速定位到某一行数据;另一种是 Range 查询,如 select name from user where age > 30 and age < 35;,这个时候需要通过idxAge索引查询 age 在 30 和 35 之间的那些数据。Index 还分为 Unique Index 和 非 Unique Index,这两种都需要支持。
分析完需要存储的数据的特点,我们再看看对这些数据的操作需求,主要考虑 Insert/Update/Delete/Select 这四种语句。
对于 Insert 语句,需要将 Row 写入 KV,并且建立好索引数据。
对于 Update 语句,需要将 Row 更新的同时,更新索引数据(如果有必要)。
对于 Delete 语句,需要在删除 Row 的同时,将索引也删除。
上面三个语句处理起来都很简单。对于 Select 语句,情况会复杂一些。首先我们需要能够简单快速地读取一行数据,所以每个 Row 需要有一个 ID (显示或隐式的 ID)。其次可能会读取连续多行数据,比如 Select * from user;。最后还有通过索引读取数据的需求,对索引的使用可能是点查或者是范围查询。
大致的需求已经分析完了,现在让我们看看手里有什么可以用的:一个全局有序的分布式 Key-Value 引擎。全局有序这一点重要,可以帮助我们解决不少问题。比如对于快速获取一行数据,假设我们能够构造出某一个或者某几个 Key,定位到这一行,我们就能利用 TiKV 提供的 Seek 方法快速定位到这一行数据所在位置。再比如对于扫描全表的需求,如果能够映射为一个 Key 的 Range,从 StartKey 扫描到 EndKey,那么就可以简单的通过这种方式获得全表数据。操作 Index 数据也是类似的思路。接下来让我们看看 TiDB 是如何做的。
TiDB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID),其中 TableID 在整个集群内唯一,IndexID/RowID 在表内唯一,这些 ID 都是 int64 类型。
每行数据按照如下规则进行编码成 Key-Value pair:
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4]
其中 Key 的 tablePrefix/recordPrefixSep 都是特定的字符串常量,用于在 KV 空间内区分其他数据。
对于 Index 数据,会按照如下规则编码成 Key-Value pair:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: rowID
Index 数据还需要考虑 Unique Index 和非 Unique Index 两种情况,对于 Unique Index,可以按照上述编码规则。但是对于非 Unique Index,通过这种编码并不能构造出唯一的 Key,因为同一个 Index 的 tablePrefix{tableID}_indexPrefixSep{indexID} 都一样,可能有多行数据的 ColumnsValue 是一样的,所以对于非 Unique Index 的编码做了一点调整:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID
Value: null
这样能够对索引中的每行数据构造出唯一的 Key。
注意上述编码规则中的 Key 里面的各种 xxPrefix 都是字符串常量,作用都是区分命名空间,以免不同类型的数据之间相互冲突,定义如下:
var(
tablePrefix = []byte{‘t’}
recordPrefixSep = []byte(“_r”)
indexPrefixSep = []byte(“_i”)
)
另外请大家注意,上述方案中,无论是 Row 还是 Index 的 Key 编码方案,一个 Table 内部所有的 Row 都有相同的前缀,一个 Index 的数据也都有相同的前缀。这样具体相同的前缀的数据,在 TiKV 的 Key 空间内,是排列在一起。
同时只要我们小心地设计后缀部分的编码方案,保证编码前和编码后的比较关系不变,那么就可以将 Row 或者 Index 数据有序地保存在 TiKV 中。这种保证编码前和编码后的比较关系不变 的方案我们称为 Memcomparable,对于任何类型的值,两个对象编码前的原始类型比较结果,和编码成 byte 数组后(注意,TiKV 中的 Key 和 Value 都是原始的 byte 数组)的比较结果保持一致。采用这种编码后,一个表的所有 Row 数据就会按照 RowID 的顺序排列在 TiKV 的 Key 空间中,某一个 Index 的数据也会按照 Index 的 ColumnValue 顺序排列在 Key 空间内。
现在我们结合开始提到的需求以及 TiDB 的映射方案来看一下,这个方案是否能满足需求。
首先我们通过这个映射方案,将 Row 和 Index 数据都转换为 Key-Value 数据,且每一行、每一条索引数据都是有唯一的 Key。
其次,这种映射方案对于点查、范围查询都很友好,我们可以很容易地构造出某行、某条索引所对应的 Key,或者是某一块相邻的行、相邻的索引值所对应的 Key 范围。
最后,在保证表中的一些 Constraint 的时候,可以通过构造并检查某个 Key 是否存在来判断是否能够满足相应的 Constraint。
至此我们已经聊完了如何将 Table 映射到 KV 上面,这里再举个简单的例子,便于大家理解,还是以上面的表结构为例。假设表中有 3 行数据:
1, “TiDB”, “SQL Layer”, 10
2, “TiKV”, “KV Engine”, 20
3, “PD”, “Manager”, 30
那么首先每行数据都会映射为一个 Key-Value pair,注意这个表有一个 Int 类型的 Primary Key,所以 RowID 的值即为这个 Primary Key 的值。假设这个表的 Table ID 为 10,其 Row 的数据为:
t10_r1 --> [“TiDB”, “SQL Layer”, 10]
t10_r2 --> [“TiKV”, “KV Engine”, 20]
t10_r3 --> [“PD”, “Manager”, 30]
除了 Primary Key 之外,这个表还有一个 Index,假设这个 Index 的 ID 为 1,则其数据为:
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
元信息管理
上节介绍了表中的数据和索引是如何映射为 KV,本节介绍一下元信息的存储。Database/Table 都有元信息,也就是其定义以及各项属性,这些信息也需要持久化,我们也将这些信息存储在 TiKV 中。每个 Database/Table 都被分配了一个唯一的 ID,这个 ID 作为唯一标识,并且在编码为 Key-Value 时,这个 ID 都会编码到 Key 中,再加上 m_ 前缀。这样可以构造出一个 Key,Value 中存储的是序列化后的元信息。
除此之外,还有一个专门的 Key-Value 存储当前 Schema 信息的版本。TiDB 使用 Google F1 的 Online Schema 变更算法,有一个后台线程在不断的检查 TiKV 上面存储的 Schema 版本是否发生变化,并且保证在一定时间内一定能够获取版本的变化(如果确实发生了变化)
SQL on KV 架构
TiKV Cluster 主要作用是作为 KV 引擎存储数据,前面已经介绍过了细节,这里不再敷述。这里主要介绍 SQL 层,也就是 TiDB Servers 这一层,这一层的节点都是无状态的节点,本身并不存储数据,节点之间完全对等。TiDB Server 这一层最重要的工作是处理用户请求,执行 SQL 运算逻辑,接下来我们做一些简单的介绍
SQL运算
理解了 SQL 到 KV 的映射方案之后,我们可以理解关系数据是如何保存的,接下来我们要理解如何使用这些数据来满足用户的查询需求,也就是一个查询语句是如何操作底层存储的数据。
能想到的最简单的方案就是通过上一节所述的映射方案,将 SQL 查询映射为对 KV 的查询,再通过 KV 接口获取对应的数据,最后执行各种计算。
比如 Select count(*) from user where name=“TiDB”; 这样一个语句,我们需要读取表中所有的数据,然后检查 Name 字段是否是 TiDB,如果是的话,则返回这一行。这样一个操作流程转换为 KV 操作流程:
- 构造出 Key Range:一个表中所有的 RowID 都在 [0, MaxInt64) 这个范围内,那么我们用 0 和 MaxInt64 根据 Row 的 Key 编码规则,就能构造出一个 [StartKey, EndKey) 的左闭右开区间
- 扫描 Key Range:根据上面构造出的 Key Range,读取 TiKV 中的数据
- 过滤数据:对于读到的每一行数据,计算 name=“TiDB” 这个表达式,如果为真,则向上返回这一行,否则丢弃这一行数据
- 计算 Count:对符合要求的每一行,累计到 Count 值上面 这个方案肯定是可以 Work 的,但是并不能 Work 的很好,原因是显而易见的:
- 在扫描数据的时候,每一行都要通过 KV 操作同 TiKV 中读取出来,至少有一次 RPC 开销,如果需要扫描的数据很多,那么这个开销会非常大
- 并不是所有的行都有用,如果不满足条件,其实可以不读取出来
- 符合要求的行的值并没有什么意义,实际上这里只需要有几行数据这个信息就行
分布式SQL运算
如何避免上述缺陷也是显而易见的,
首先我们需要将计算尽量靠近存储节点,以避免大量的 RPC 调用。
其次,我们需要将 Filter 也下推到存储节点进行计算,这样只需要返回有效的行,避免无意义的网络传输。
最后,我们可以将聚合函数、GroupBy 也下推到存储节点,进行预聚合,每个节点只需要返回一个 Count 值即可,再由 tidb-server 将 Count 值 Sum 起来。
这里有一个数据逐层返回的示意图:

SQL层架构
上面几节简要介绍了 SQL 层的一些功能,希望大家对 SQL 语句的处理有一个基本的了解。实际上 TiDB 的 SQL 层要复杂的多,模块以及层次非常多,下面这个图列出了重要的模块以及调用关系:

用户的 SQL 请求会直接或者通过 Load Balancer 发送到 tidb-server,tidb-server 会解析 MySQL Protocol Packet,获取请求内容,然后做语法解析、查询计划制定和优化、执行查询计划获取和处理数据。
数据全部存储在 TiKV 集群中,所以在这个过程中 tidb-server 需要和 tikv-server 交互,获取数据。
最后 tidb-server 需要将查询结果返回给用户
任务调度
为什么要进行调度
先回忆一下TiDB 技术内幕 - 存储提到的一些信息,TiKV 集群是 TiDB 数据库的分布式 KV 存储引擎,数据以 Region 为单位进行复制和管理,每个 Region 会有多个 Replica(副本),这些 Replica 会分布在不同的 TiKV 节点上,其中 Leader 负责读/写,Follower 负责同步 Leader 发来的 raft log。了解了这些信息后,请思考下面这些问题:
- 如何保证同一个 Region 的多个 Replica 分布在不同的节点上?更进一步,如果在一台机器上启动多个 TiKV 实例,会有什么问题?
- TiKV 集群进行跨机房部署用于容灾的时候,如何保证一个机房掉线,不会丢失 Raft Group 的多个 Replica?
- 添加一个节点进入 TiKV 集群之后,如何将集群中其他节点上的数据搬过来?
- 当一个节点掉线时,会出现什么问题?整个集群需要做什么事情?如果节点只是短暂掉线(重启服务),那么如何处理?如果节点是长时间掉线(磁盘故障,数据全部丢失),需要如何处理?
- 假设集群需要每个 Raft Group 有 N 个副本,那么对于单个 Raft Group 来说,Replica 数量可能会不够多(例如节点掉线,失去副本),也可能会过于多(例如掉线的节点又回复正常,自动加入集群)。那么如何调节 Replica 个数?
- 读/写都是通过 Leader 进行,如果 Leader 只集中在少量节点上,会对集群有什么影响?
- 并不是所有的 Region 都被频繁的访问,可能访问热点只在少数几个 Region,这个时候我们需要做什么?
- 集群在做负载均衡的时候,往往需要搬迁数据,这种数据的迁移会不会占用大量的网络带宽、磁盘 IO 以及 CPU?进而影响在线服务?
这些问题单独拿出可能都能找到简单的解决方案,但是混杂在一起,就不太好解决。有的问题貌似只需要考虑单个 Raft Group 内部的情况,比如根据副本数量是否足够多来决定是否需要添加副本。但是实际上这个副本添加在哪里,是需要考虑全局的信息。整个系统也是在动态变化,Region 分裂、节点加入、节点失效、访问热点变化等情况会不断发生,整个调度系统也需要在动态中不断向最优状态前进,如果没有一个掌握全局信息,可以对全局进行调度,并且可以配置的组件,就很难满足这些需求。因此我们需要一个中心节点,来对系统的整体状况进行把控和调整,所以有了 PD 这个模块。
调度的需求
上面罗列了一大堆问题,我们先进行分类和整理。总体来看,问题有两大类:
1.作为一个分布式高可用存储系统,必须满足的需求,包括四种:
-
副本数量不能多也不能少
-
副本需要分布在不同的机器上
-
新加节点后,可以将其他节点上的副本迁移过来
-
节点下线后,需要将该节点的数据迁移走
2.作为一个良好的分布式系统,需要优化的地方,包括: -
维持整个集群的 Leader 分布均匀
-
维持每个节点的储存容量均匀
-
维持访问热点分布均匀
-
控制 Balance 的速度,避免影响在线服务
-
管理节点状态,包括手动上线/下线节点,以及自动下线失效节点
满足第一类需求后,整个系统将具备多副本容错、动态扩容/缩容、容忍节点掉线以及自动错误恢复的功能。
满足第二类需求后,可以使得整体系统的负载更加均匀、且可以方便的管理。
为了满足这些需求,首先我们需要收集足够的信息,比如每个节点的状态、每个 Raft Group 的信息、业务访问操作的统计等;
其次需要设置一些策略,PD 根据这些信息以及调度的策略,制定出尽量满足前面所述需求的调度计划;最后需要一些基本的操作,来完成调度计划。
调度的基本操作
我们先来介绍最简单的一点,也就是调度的基本操作,也就是为了满足调度的策略,我们有哪些功能可以用。这是整个调度的基础,了解了手里有什么样的锤子,才知道用什么样的姿势去砸钉子。
上述调度需求看似复杂,但是整理下来最终落地的无非是下面三件事:
-
增加一个 Replica
-
删除一个 Replica
-
将 Leader 角色在一个 Raft Group 的不同 Replica 之间 transfer
刚好 Raft 协议能够满足这三种需求,通过 AddReplica、RemoveReplica、TransferLeader 这三个命令,可以支撑上述三种基本操作。
信息收集
调度依赖于整个集群信息的收集,简单来说,我们需要知道每个 TiKV 节点的状态以及每个 Region 的状态。TiKV 集群会向 PD 汇报两类消息:
每个 TiKV 节点会定期向 PD 汇报节点的整体信息
TiKV 节点(Store)与 PD 之间存在心跳包,一方面 PD 通过心跳包检测每个 Store 是否存活,以及是否有新加入的 Store;另一方面,心跳包中也会携带这个 Store 的状态信息,主要包括:
- 总磁盘容量
- 可用磁盘容量
- 承载的 Region 数量
- 数据写入速度
- 发送/接受的 Snapshot 数量(Replica 之间可能会通过 Snapshot 同步数据)
- 是否过载
- 标签信息(标签是具备层级关系的一系列 Tag)
每个 Raft Group 的 Leader 会定期向 PD 汇报信息
每个 Raft Group 的 Leader 和 PD 之间存在心跳包,用于汇报这个 Region 的状态,主要包括下面几点信息:
- Leader 的位置
- Followers 的位置
- 掉线 Replica 的个数
- 数据写入/读取的速度
PD 不断的通过这两类心跳消息收集整个集群的信息,再以这些信息作为决策的依据。除此之外,PD 还可以通过管理接口接受额外的信息,用来做更准确的决策。比如当某个 Store 的心跳包中断的时候,PD 并不能判断这个节点是临时失效还是永久失效,只能经过一段时间的等待(默认是 30 分钟),如果一直没有心跳包,就认为是 Store 已经下线,再决定需要将这个 Store 上面的 Region 都调度走。但是有的时候,是运维人员主动将某台机器下线,这个时候,可以通过 PD 的管理接口通知 PD 该 Store 不可用,PD 就可以马上判断需要将这个 Store 上面的 Region 都调度走。
调度的策略
PD 收集了这些信息后,还需要一些策略来制定具体的调度计划。
- 一个 Region 的 Replica 数量正确
当 PD 通过某个 Region Leader 的心跳包发现这个 Region 的 Replica 数量不满足要求时,需要通过 Add/Remove Replica 操作调整 Replica 数量。出现这种情况的可能原因是:-
某个节点掉线,上面的数据全部丢失,导致一些 Region 的 Replica 数量不足
-
某个掉线节点又恢复服务,自动接入集群,这样之前已经补足了 Replica 的 Region 的 Replica 数量多过,需要删除某个 Replic
-
- 管理员调整了副本策略,修改了 max-replicas 的配置
2.一个 Raft Group 中的多个 Replica 不在同一个位置
注意第二点,『一个 Raft Group 中的多个 Replica 不在同一个位置』,这里用的是『同一个位置』而不是『同一个节点』。在一般情况下,PD 只会保证多个 Replica 不落在一个节点上,以避免单个节点失效导致多个 Replica 丢失。在实际部署中,还可能出现下面这些需求:
-
多个节点部署在同一台物理机器上
-
TiKV 节点分布在多个机架上,希望单个机架掉电时,也能保证系统可用性
-
TiKV 节点分布在多个 IDC 中,希望单个机房掉电时,也能保证系统可用
这些需求本质上都是某一个节点具备共同的位置属性,构成一个最小的容错单元,我们希望这个单元内部不会存在一个 Region 的多个 Replica。这个时候,可以给节点配置 lables 并且通过在 PD 上配置 location-labels 来指明哪些 lable 是位置标识,需要在 Replica 分配的时候尽量保证不会有一个 Region 的多个 Replica 所在结点有相同的位置标识。
3.副本在 Store 之间的分布均匀分配
前面说过,每个副本中存储的数据容量上限是固定的,所以我们维持每个节点上面,副本数量的均衡,会使得总体的负载更均衡。
4.Leader 数量在 Store 之间均匀分配
Raft 协议要读取和写入都通过 Leader 进行,所以计算的负载主要在 Leader 上面,PD 会尽可能将 Leader 在节点间分散开。
5.访问热点数量在 Store 之间均匀分配
每个 Store 以及 Region Leader 在上报信息时携带了当前访问负载的信息,比如 Key 的读取/写入速度。PD 会检测出访问热点,且将其在节点之间分散开。
6.各个 Store 的存储空间占用大致相等
每个 Store 启动的时候都会指定一个 Capacity 参数,表明这个 Store 的存储空间上限,PD 在做调度的时候,会考虑节点的存储空间剩余量。
7.控制调度速度,避免影响在线服务
调度操作需要耗费 CPU、内存、磁盘 IO 以及网络带宽,我们需要避免对线上服务造成太大影响。PD 会对当前正在进行的操作数量进行控制,默认的速度控制是比较保守的,如果希望加快调度(比如已经停服务升级,增加新节点,希望尽快调度),那么可以通过 pd-ctl 手动加快调度速度。
8.支持手动下线节点
当通过 pd-ctl 手动下线节点后,PD 会在一定的速率控制下,将节点上的数据调度走。当调度完成后,就会将这个节点置为下线状态。
调度的实现
了解了上面这些信息后,接下来我们看一下整个调度的流程。
PD 不断的通过 Store 或者 Leader 的心跳包收集信息,获得整个集群的详细数据,并且根据这些信息以及调度策略生成调度操作序列,每次收到 Region Leader 发来的心跳包时,PD 都会检查是否有对这个 Region 待进行的操作,通过心跳包的回复消息,将需要进行的操作返回给 Region Leader,并在后面的心跳包中监测执行结果。注意这里的操作只是给 Region Leader 的建议,并不保证一定能得到执行,具体是否会执行以及什么时候执行,由 Region Leader 自己根据当前自身状态来定