Apache doris架构及组件介绍
Apache Doris 代码仓库地址:apache/incubator-doris 欢迎大家关注加星
1.概述
Apache Doris是一个现代化的MPP分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris的分布式架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集。
Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。令您的数据分析工作更加简单高效!
什么是 MPP?
MPP ( Massively Parallel Processing ),即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。简单来说,MPP 是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果 ( 与 Hadoop 相似 )。
Doris 主要解决 PB 级别的数据量(如果高于 PB 级别,不推荐使用 Doris 解决,可以考虑用 Hive 等工具),解决结构化数据,查询时间一般在秒级或毫秒级。
Doris 由百度大数据部研发 ( 之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris ),在百度内部,有超过200个产品线在使用,部署机器超过1000台,单一业务最大可达到上百 TB。
百度将 Doris 贡献给 Apache 社区之后,许多外部用户也成为了 Doris 的使用者,例如新浪微博,美团,小米等著名企业。
2.doris 架构
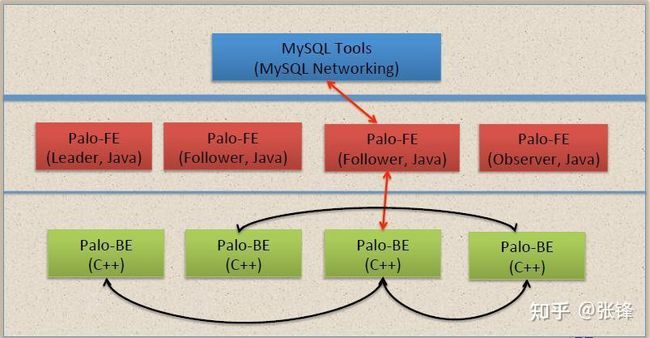
2.1 核心组件介绍
Doris 的架构很简洁,只设 FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维。
- 以数据存储的角度观之,FE 存储、维护集群元数据;BE 存储物理数据。
- 以查询处理的角度观之, FE 节点接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果;BE 节点依据 FE 生成的物理计划,分布式地执行查询。
FE,BE 都可线性扩展。
FE 主要有有三个角色,一个是 leader,一个是 follower,还有一个 observer。leader 跟 follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
Observer 只是用来扩展查询节点,就是说如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不参与任何的写入,只参与读取。
数据的可靠性由 BE 保证,BE 会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
2.2 元数据
Doris 采用 Paxos 协议以及 Memory + Checkpoint + Journal 的机制来确保元数据的高性能及高可靠。元数据的每次更新,都首先写入到磁盘的日志文件中,然后再写到内存中,最后定期 checkpoint 到本地磁盘上。我们相当于是一个纯内存的一个结构,也就是说所有的元数据都会缓存在内存之中,从而保证 FE 在宕机后能够快速恢复元数据,而且不丢失元数据。Leader、follower 和 observer 它们三个构成一个可靠的服务,这样如果发生节点宕机的情况,在百度内部的话,我们一般是部署一个 leader 两个 follower,外部公司目前来说基本上也是这么部署的。就是说三个节点去达到一个高可用服务。以我们的经验来说,单机的节点故障的时候其实基本上三个就够了,因为 FE 节点毕竟它只存了一份元数据,它的压力不大,所以如果 FE 太多的时候它会去消耗机器资源,所以多数情况下三个就足够了,可以达到一个很高可用的元数据服务
Doris FE高可用方案:
- 如果你是离线业务,对高可用要求不是那么高可以使用 1 FE(Follower leader) + 1 FE(Observer)
- 如果你是实时在线业务,对高可用要求很高,建议使用 3 FE(Follower),会自动选举出一个 leader
2.3 数据分布及可靠性
Doris 数据主要都是存储在 BE 里面,BE 节点上物理数据的可靠性通过多副本来实现,默认是 3 副本,副本数可配置且可随时动态调整,满足不同可用性级别的业务需求。FE 调度 BE 上副本的分布与补齐。
如果说用户对可用性要求不高,而对资源的消耗比较敏感的话,我们可以在建表的时候选择建两副本或者一副本。比如在百度云上我们给用户建表的时候,有些用户对它的整个资源消耗比较敏感,因为他要付费,所以他可能会建两副本。但是我们一般不太建议用户建一副本,因为一副本的情况下可能一旦机器出问题了,数据直接就丢了,很难再恢复。我们在公司内部的话,一般是默认建三副本,这样基本可以保证一台机器单机节点宕机的情况下不会影响整个服务的正常运作
3.doris内部组件及周边生态组件介绍
3.1 Frontend(FE)
Java语言开发,Doris 系统的元数据管理和节点调度。在导入流程中主要负责导入 plan 生成和导入任务的调度工作,请求接入等
3.2 Backend(BE)
C++语言开发,Doris 系统的计算和存储节点,执行SQL计划等。在导入流程中主要负责数据的 ETL 和存储。
3.3 Broker
Broker 为一个独立的无状态进程。封装了文件系统接口,提供 Doris 读取远端存储系统中文件的能力,包括HDFS,S3,BOS等
3.4 Mysql Client
Doris 借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC以及MySQL 的客户端,都可以直接访问 Doris
3.5 Doris on ES
Doris-On-ES将Doris的分布式查询规划能力和ES(Elasticsearch)的全文检索能力相结合,提供更完善的OLAP分析场景解决方案:
- ES中的多index分布式Join查询
- Doris和ES中的表联合查询,更复杂的全文检索过滤
3.6 ODBC External Table Of Doris
ODBC External Table Of Doris 提供了Doris通过数据库访问的标准接口(ODBC)来访问外部表,外部表省去了繁琐的数据导入工作,让Doris可以具有了访问各式数据库的能力,并借助Doris本身的OLAP的能力来解决外部表的数据分析问题:
- 支持各种数据源接入Doris
- 支持Doris与各种数据源中的表联合查询,进行更加复杂的分析操作
- 通过insert into将Doris执行的查询结果写入外部的数据源
3.7 Spark Doris Connector
Spark Doris Connector 可以支持通过 Spark 读取 Doris 中存储的数据。
- 当前版本只支持从Doris中读取数据。
- 可以将Doris表映射为DataFrame或者RDD,推荐使用DataFrame。
- 支持在Doris端完成数据过滤,减少数据传输量。
3.8 Flink Doris Connector
Flink Doris Connector 可以支持通过 Flink 读取 Doris 中存储的数据。
- 可以将Doris表映射为DataStream或者Table
- 支持通过Flink table的方式使用doris数据
- 可以通过Flink table 方式方便的将数据通过insert into select方式将数据插入到doris表中
3.9 DataX doriswriter
DataX doriswriter 插件,用于通过 DataX 同步其他数据源的数据到 Doris 中。
这个插件是利用Doris的Stream Load 功能进行数据导入的。需要配合 DataX 服务一起使用。
这个扩展可以很方便的将业务数据库中的数据快速的抽取导入到doris数仓中
3.10 Doris output plugin
该插件用于logstash输出数据到Doris,使用 HTTP 协议与 Doris FE Http接口交互,并通过 Doris 的 stream load 的方式进行数据导入.
3.11 审计日志扩展
Doris 的审计日志插件是在 FE 的插件框架基础上开发的。是一个可选插件。用户可以在运行时安装或卸载这个插件。
该插件可以将 FE 的审计日志定期的导入到指定 Doris 集群中,以方便用户通过 SQL 对审计日志进行查看和分析。
4.Doris适用场景
4.1 数仓查询加速
应用Doris解决传统数仓查询效率低下的困境,PB级别数据低至毫秒/秒级查询耗时,海量数据无缝应用,极大幅度加速数据决策效率。
4.2 实时数仓构建
Doris支持流式数据高效导入、业务指标实时聚合,保证业务数据得以实时洞察,并可以减少数据处理链路、统一数据流向,简化大数据平台架构。
4.3 多源联邦查询
通过Doris构建跨多个数据源的统一查询入口,实现实时数据和离线数据的联邦分析,满足数据分析人员更多元化的查询需求。
4.4 交互式数据分析
基于Doris和BI可视化工具构建交互式数据分析应用,对海量数据进行自助探查和多维度分析,实现对业务的深层探索和快速决策
我的公众号关于关注
