端边云协作推理相关论文总结
Papers About End-Edge-Cloud Collaborative Inference
文章目录
- Papers About End-Edge-Cloud Collaborative Inference
-
- Part 1: Edge Computing
- Part 2: Model Compressing
- Part 3: Reinforcement Learning
- References
Part 1: Edge Computing
- Neurosurgeon1是一个轻量级的调度程序,可以在神经网络层的细粒度上自动划分移动设备和数据中心的DNN计算。基于DNN层的类型和配置,我们开发了一系列模型来预测其延迟和功耗,并创造了Neurosurgeon,来作为一个智能化地划分在移动设备和云之间的DNN计算的系统。Neurosurgeon配置移动设备和服务器,为DNN层类型的频谱生成性能预测模型。在部署阶段,它为每种层类型生成预测模型,对任意神经网络结构的每层延迟和能耗来进行建模;在运行时阶段,它基于每个层的类型和配置来预测每层的延迟和能耗代价,然后基于不同因素选择最好的划分点。

- Edgent2是一个移动设备和边缘协同作用的DNN协同推理框架。它主要包含两个关键点:(1)自适应地将DNN计算划分在设备和边缘之间的DNN分区,利用不同的计算资源来进行实时的DNN推理;(2)利用BranchyNet的思想,通过在适当的中间DNN层添加分支提前退出来加速DNN推理,从而进一步降低计算延迟。Edgent由三个阶段组成:离线训练阶段、在线优化阶段和协作推理阶段。在离线训练阶段,Edgent主要执行两个初始化:(1)分析移动设备和边缘服务器来生成对不同类型DNN层的基于回归的性能预测模型;(2)训练带有不同退出点的DNN模型,使部分样本可以提前退出来加速DNN推理。在在线优化优化阶段,DNN优化器选择DNNs的最佳划分点和早期退出点,从而使精度最大化,同时保证端到端的延迟性能。在协作推理阶段,根据划分和早期退出计划,移动设备和边缘服务器执行网络层推理任务。

- AdaComp3是一种用于压缩worker对服务器模型更新的最新算法,它结合了有效的梯度选择和学习率调整,适用于随机梯度下降的方法。它是在参数服务器模型(PS)中将随机梯度下降(SGD)分布到大量workers上的一种方法,即灵活地通过自适应压缩在边缘设备上进行分布式深度学习。其中,PS与其他每个节点通信来维护一个中心模型,其他节点都是workers,它们使用本地数据来计算中心模型的更新,并且在发送前更新都被压缩过。另外,边缘节点也扮演了监督者的角色,它包含了一个测试数据集用来计算中心模型的准确性。

- 本文4提出了一种基于深度的CNN模型输入分区方案,克服了目前行列和网格分区方案的困难之处,同时强调了当前卷积层的输入和输出深度在分布式执行实现过程中的加速作用。在该项工作中,我们分割了一个图像和一个过滤器,它们沿着深度维度分布在Fog资源中,我们还将所有的过滤器分配到资源中,使其分区是无损失的。
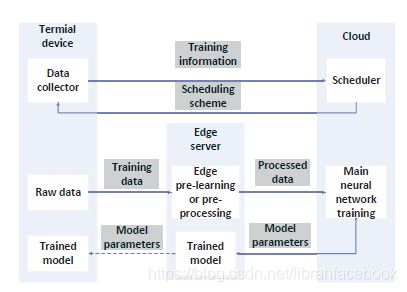
- Task Scheduling5来优化加权数据传输时间,同时保证可承受的精度损失。我们基于端边云架构来描述一个边缘学习框架,对于每个终端设备,这里有一个或几个边缘服务器可以被访问。在数据被上传到云用来主神经网络训练前,需要被卸载到一个可访问边缘服务器来做预学习或预处理。另外,该边云学习系统将提供一个合适的调度方案来安排终端设备到一个边缘服务器,使在边缘服务器的资源可以被有效利用。其workflow由两个阶段组成,分别是调度处理阶段和边云系统的深度学习处理阶段。对于加权数据传输时间优化的任务调度算法,有两种算法:基于极值点线性规划解决方案的舍入算法和模拟退火重排算法。
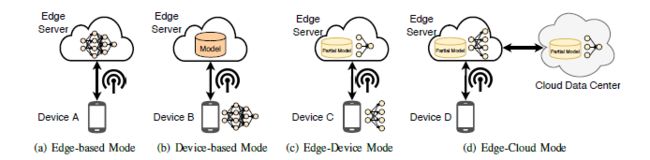
- Edge Intelligence6对边缘智能的最先研究成果进行了全面调查,首先回顾了在边缘运行的人工智能应用程序的背景和动机,然后提供了一个在边缘的深度学习模型训练/推理的总体架构、框架和出现的关键技术,最终讨论了在边缘智能上未来的研究机遇。边缘智能模型推理架构可以分为以下几种:(1)Edge-based(DNN模型推理在边缘服务器完成,预测结果将返回到设备中);(2)Device-based(移动设备从边缘服务器获取DNN模型,并在本地执行模型推理);(3)Edge-device(设备执行DNN模型到一个特定层后将中间数据发送到边缘服务器,边缘服务器将执行剩余层并将预测结果发送到设备上);(4)Edge-cloud(设备主要负责输入数据收集,DNN模型则在边缘和云上执行)。
- Edge-Cloud Model7是一个在边缘和云上协作的处理模型,来进行实时视频处理。所用到的技术主要包括:(1)划分(Splitting):神经网络被划分到一个边缘分区和一个云分区;(2)压缩(Compression):数据在被发送到云之前先在边缘被压缩;(3)通信差异(Differential communication):只发送当前帧和先前帧的差异。验证中被评估的性能度量包括:(1)延迟(Latency):处理图像和在边缘应用NN技术的时间;(2)压缩比(Compression ratio):原始图像和压缩图像大小的比例;(3)精度(Accuracy):原始神经网络检测到的图像中被应用技术后神经网络中检测到的比例。该验证旨在提供一个关于集合NN技术和正确配置意义的挑战和权衡。
- 分布式DNN架构8在设计过程中将传感目标和网络带宽限制看作第一要素,学习端到端如何表示原始传感数据,从而可以很好地适应传感设备和云之间的不同网络带宽。它利用边缘设备上的浅层神经网络动态地压缩有用数据,在数据中心的深层神经网络对其进行解压缩,并根据数据相关性向边缘编码器提供积极的反馈。其系统的主要组成部分为:(1)分布式边缘编码器;(2)物理网络链接;(3)集中式编码器;(4)预训练决策模型;(5)动态特征选择代理;(6)从数据中心到边缘设备的反馈。

- NestDNN9作为一个将运行资源的动态性考虑在内的框架,对于移动视觉系统可支持资源感知性多租用的设备深度学习。它支持每个深度学习模型来提供灵活的资源和精度之间的权衡,并且在运行期间动态地为每个深度学习模型选择最优的资源和精度间的权衡,从而更好地适应系统可用运行资源的需求。NestDNN被划分成一个离线阶段和一个在线阶段,其中离线阶段由三部分组成,分别是模型剪枝、模型复原和模型分析,在线阶段则为每个应用程序选择最优的派生模型,然后分配最优的运行资源数量到每个所选的派生模型,从而最大化总体推理精度并最小化总体推理延迟。

- Adapt CNNs10是一种用于能量受限的图像分类任务的自适应神经网络设计,所做工作的关键点是CNNs体系架构设置和网络选择问题被看作超参数来进行全局优化,并增强了贝叶斯优化到所设计空间的特性中,可以更快地到达邻近最优的区域,最优设计可以通过网格搜索被确定。我们考虑了以下两种情况:(1)所有的CNNs在移动系统上本地执行,其表示为local;(2)较少复杂的网络被部署在移动系统(边缘节点),而更精确的网络在一个服务器上执行(远程执行)。自适应网络执行过程:给定一个要被分类的图像,神经网络 N 1 N_1 N1总是要被首先执行,接下来一个决策函数 k k k被评估来决定从 N 1 N_1 N1执行后的分类结果应当被返回作为最终结果,或者到下一个网络 N 2 N_2 N2来被执行。一般来说,我们将决策函数 k i , j k_{i,j} ki,j表示为: N i ( x ) → { 0 , 1 } N_i(x) \rightarrow \{0,1\} Ni(x)→{0,1},从而来提供置信度反馈,以及决定在状态 N i ( k i , j = 0 ) N_i(k_{i,j}=0) Ni(ki,j=0)退出或者在接下来的阶段 N j ( k i , j = 1 ) N_j(k_{i,j}=1) Nj(ki,j=1)继续执行。

Part 2: Model Compressing
- Pruning算法11通过只学习重要连接而不影响精度,来减少神经网络所要求的内存和计算资源。该方法使用三个步骤来减去冗余连接:第一是训练网络来学习重要的连接;第二是减去不重要的连接;第三是重新训练该网络来微调剩余连接的权值。其剪枝过程由两个阶段组成,第一个阶段是:学习网络的拓扑结构,学习重要连接并移除不重要连接;第二个阶段是:重新训练稀疏网络,从而使剩余连接仍可以补偿已被移除的连接。剪枝和重训练阶段可以迭代式重复进行,从而进一步减少网络的复杂性。.

- Deep Compression12由三个阶段组成:pruning(剪枝)、trained quantization(训练量化)和Huffman coding(霍夫曼编码),它们一起工作来减少神经网络的存储要求并且不影响精度损失。一个三阶段步骤来减少神经网络所要求的存储,同时保持原有的精度。首先,我们通过移除冗余连接来修剪网络,只保持最有信息价值的连接。然后,权重被量化从而使多个连接共享相同的权重,于是只有codebook(有效权重)和索引需要被存储。最后,我们使用霍夫曼编码,来充分利用有效权重的偏置分布。

- Channel Pruning13是一种用于加速深度神经网络的通道剪枝方法,它直接地减少特征映射宽度,将一个网络进行缩减。我们通过两个步骤来解决问题:(1)通道选择,选择最有代表性的通道,然后基于LASSO回归剪去冗余的通道;(2)特征映射重建,利用最小二乘法对剩余通道输出进行重构。对于优化问题的具体解决步骤,我们将其分解为 β \beta β子问题和 W W W子问题,前者固定 W W W值,求解 β \beta β来进行通道选择;后者固定 β \beta β值,利用选择好的通道求解 W W W来最小化重构误差。

Part 3: Reinforcement Learning
- DQN14可以使用端到端的强化学习,直接从高维度传感输入中学习到成功的策略。Deep Q-network能够将深度神经网络与强化学习进行结合。我们考虑一类任务,代理可以通过一系列观察、行动和奖励来进行交互,代理的目标是以某种方式选择动作,来最大化累积未来奖励。我们使用深度卷积神经网络来接近最优action-value函数,在做过一个观察(s)和一个动作(a)后,由一个行为策略 π = P ( a ∣ s ) \pi=P(a|s) π=P(a∣s)来实现时间步骤t的最大化累积奖励。DQN中使用两个关键技术:(1)使用experience replay来随机化数据,从而消除观察序列中的相关性;(2)使用一种迭代式更新来调整action-value(Q)为只定期更新的目标值,从而降低了与目标的相关性。其Q-learning的更新公式为: Q ∗ ( s , a ) = Q ( s , a ) + α ( r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ) Q^*(s,a)=Q(s,a)+\alpha(r+\gamma \max \limits_ a'Q(s',a')-Q(s,a)) Q∗(s,a)=Q(s,a)+α(r+γamax′Q(s′,a′)−Q(s,a))。

- 本文15我们使用一个递归网络来生成神经网络的模型描述,并利用强化学习来训练RNN,从而最大化在验证集上的生成架构的期望精度。它是一种基于梯度的方法来寻找良好的架构,使用一个递归网络作为控制器,在真实数据上训练指定网络会导致验证集上的准确性,然后使用准确性作为奖励信号,通过计算策略梯度来更新控制器。最终在下一个迭代过程中,控制器将对接收到的高精度架构有着更高的概率,随着时间推移控制器可以学习改进其搜索。

References
Kang Y, Hauswald J, Gao C, et al. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge[C]//ACM SIGARCH Computer Architecture News. ACM, 2017, 45(1): 615-629. ↩︎
Li E, Zhou Z, Chen X. Edge intelligence: On-demand deep learning model co-inference with device-edge synergy[C]//Proceedings of the 2018 Workshop on Mobile Edge Communications. ACM, 2018: 31-36. ↩︎
Hardy C, Le Merrer E, Sericola B. Distributed deep learning on edge-devices: feasibility via adaptive compression[C]//2017 IEEE 16th International Symposium on Network Computing and Applications (NCA). IEEE, 2017: 1-8. ↩︎
Dey S, Mukherjee A, Pal A, et al. Partitioning of cnn models for execution on fog devices[C]//Proceedings of the 1st ACM International Workshop on Smart Cities and Fog Computing. ACM, 2018: 19-24. ↩︎
Huang Y, Zhu Y, Fan X, et al. Task scheduling with optimized transmission time in collaborative cloud-edge learning[C]//2018 27th International Conference on Computer Communication and Networks (ICCCN). IEEE, 2018: 1-9. ↩︎
Zhou Z, Chen X, Li E, et al. Edge Intelligence: Paving the Last Mile of Artificial Intelligence with Edge Computing[J]. arXiv preprint arXiv:1905.10083, 2019. ↩︎
Grulich P M, Nawab F. Collaborative edge and cloud neural networks for real-time video processing[J]. Proceedings of the VLDB Endowment, 2018, 11(12): 2046-2049. ↩︎
Chinchali S P, Cidon E, Pergament E, et al. Neural networks meet physical networks: Distributed inference between edge devices and the cloud[C]//Proceedings of the 17th ACM Workshop on Hot Topics in Networks. ACM, 2018: 50-56. ↩︎
Fang B, Zeng X, Zhang M. Nestdnn: Resource-aware multi-tenant on-device deep learning for continuous mobile vision[C]//Proceedings of the 24th Annual International Conference on Mobile Computing and Networking. ACM, 2018: 115-127. ↩︎
Stamoulis D, Chin T W R, Prakash A K, et al. Designing adaptive neural networks for energy-constrained image classification[C]//Proceedings of the International Conference on Computer-Aided Design. ACM, 2018: 23. ↩︎
Han S, Pool J, Tran J, et al. Learning both weights and connections for efficient neural network[C]//Advances in neural information processing systems. 2015: 1135-1143. ↩︎
Han S, Mao H, Dally W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding[J]. arXiv preprint arXiv:1510.00149, 2015. ↩︎
He Y, Zhang X, Sun J. Channel pruning for accelerating very deep neural networks[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1389-1397. ↩︎
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529. ↩︎
Zoph B, Le Q V. Neural architecture search with reinforcement learning[J]. arXiv preprint arXiv:1611.01578, 2016. ↩︎