【Doris】Apache Doris 索引机制解析
1 引言
Apache Doris 存储引擎采用类似 LSM 树的结构提供快速的数据写入支持。进行数据导入时,数据会先写入 Tablet 对应的 MemTable 中,当 MemTable 写满之后,会将 MemTable 里的数据刷写(Flush)到磁盘,生成一个个不超过 256MB 的不可变的 Segment 文件。
MemTable 采用 SkipList 的数据结构,将数据暂时保存在内存中,SkipList 会按照 Key 对数据行进行排序,因此,刷写到磁盘上的 Segment 文件也是按 Key 排序的。Apache Doris 底层采用列存的方式来存储数据,每一列数据会被分为多个 Data Page。
为了提高数据读取效率,Apache Doris 底层存储引擎提供了丰富的索引类型,分别是前缀索引(Short Key Index)、Ordinal 索引、Zone Map索引、Bitmap 索引和 Bloom Filter 索引。前缀索引、Ordinal 索引和 Zone Map 索引不需要用户干预,会随着数据写入自动生成;Bitmap 索引和 Bloom Filter 索引需要用户干预,数据写入时默认不会生成这两种索引,用户可以有选择地为指定的列添加这两种索引。
数据从 MemTable 刷写到磁盘的过程分为两个阶段,第一阶段是将 MemTable 中的行存结构在内存中转换为列存结构,并为每一列生成对应的索引结构;第二阶段是将转换后的列存结构写入磁盘,生成 Segment 文件。
下面将分别对这些索引进行详细地介绍。
2 前缀索引(Short Key Index)
2.1 索引生成
前缀索引是一种稀疏索引。数据刷写过程中,每写入一定的数据行(默认为 1024 行)就会生成一条前缀索引项。前缀索引会对每一个索引间隔的第一个数据行的前缀字段进行编码,前缀字段的编码与前缀字段的值具有相同的排序规则,即前缀字段的值排序越靠前,对应的编码值排序也越靠前。Segment 文件是按 Key 排序的,因此,前缀索引项也是按 Key 排序的。
一个 Segment 文件中的前缀索引数据保存在一个独立的 Short Key Page 中,其中包含每一条前缀索引项的编码数据、每一条前缀索引项的 offset、Short Key Page 的 footer 以及 Short Key Page 的 Checksum 信息。Short Key Page 的 footer 中记录了 Page 的类型、前缀索引编码数据的大小、前缀索引 offset 数据的大小、前缀索引项的数目等信息。
Short Key Page 在 Segment 中的 offset 和大小会被保存在Segment文件的footer中,以便于数据读取时能够正确地从Segment文件中加载出前缀索引数据。前缀索引的存储结构如图1所示。
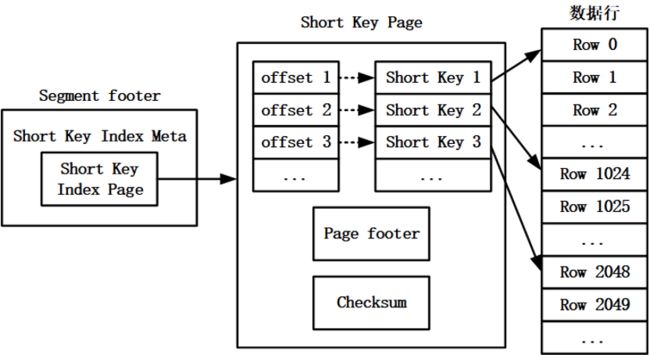
图1 前缀索引的存储结构
2.2 查询过滤
数据查询时,会打开Segment文件,从footer中获取Short Key Page的offset以及大小,然后从Segment文件中读取Short Key Page中的索引数据,并解析出每一条前缀索引项。
如果查询过滤条件包含前缀字段时,就可以使用前缀索引进行快速地行过滤。查询过滤条件会被划分成多个Key Range。对一个Key Range进行行过滤的方法如下:
(1)在整个Segment的行范围内寻找Key Range上界对应的行号upper rowid(寻找Segment中第一个大于Key Range上界的行)。
-
对Key Range上界的前缀字段key进行编码。
-
寻找key可能存在的范围下界start。根据编码寻找前缀索引中第一个等于(存在前缀索引项与key的编码相同)或大于(不存在前缀索引项的与key的编码相同)key编码的前缀索引项。如果找到满足条件的索引项,并且该索引项不是第一条前缀索引项,则将该索引项的前一条前缀索引项对应的行号记录为start(前缀索引是稀疏索引,第一个等于或大于Key Range上界key的数据行有可能在前一条前缀索引项对应的数据行之后);如果找到满足条件的索引项,并且该索引项是第一条前缀索引项,则记录该索引项对应的行号为start。如果没有找到一条前缀索引项等于或大于key的编码,则记录最后一条前缀索引项对应的行号为start(第一个等于或大于key的行有可能在最后一条前缀索引项之后)。
-
寻找key可能存在的范围上界end。根据编码寻找前缀索引中第一个大于key的二进制编码的索引项。如果找到满足条件的索引项,则记录该索引项对应的行号为end;如果没有找到一条前缀索引项大于key的编码,则记录Segment最后一行的行号为end。
-
使用二分查找算法在start与end之间的行范围内寻找第一个大于key的编码的行,行号记为upper rowid。
注:前缀索引是稀疏索引,不能精确定位到key所在的行,只能粗粒度地定位出key可能存在的范围,然后使用二分查找算法精确地定位key的位置,如图2所示。
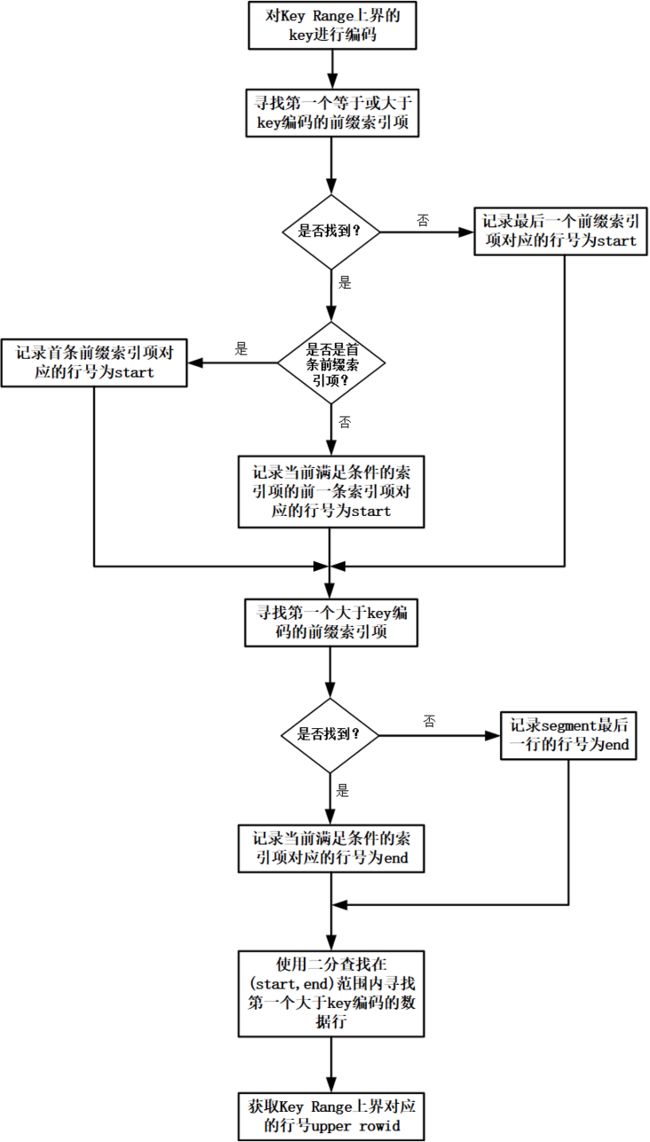
图2 使用前缀索引定位row id的过程
(2)在0 ~ upper rowid范围内寻找Key Range下界对应的行号lower rowid(寻找Segment中第一个等于或大于Key Range下界的行)。
与寻找Key Range上界对应的row id的方法相同,不再赘述。
(3)获取Key Range的行范围。upper_rowid与lower_rowid之间的所有数据行都是当前Key Range需要扫描的行范围。
3 Ordinal 索引
3.1 索引生成
Apache Doris 底层采用列存的方式来存储数据,每一列数据会被分为多个Data Page。
数据刷写时,会为每一个Data Page生成一条Ordinal索引项,其中保存Data Page在Segment文件中的offset、Data Page的大小以及Data Page的起始行号,所有Data Page的Ordinal索引项会保存在一个Ordinal Index Page中, Ordinal Index Page在Segment文件中的offset以及Ordinal Index Page的大小会被保存在Segment文件的footer中,以便于数据读取时能够通过两级索引找到Data Page(首先,通过Segment文件的footer找到Ordinal Index Page,然后,通过Ordinal Index Page中的索引项找到Data Page)。
Ordinal Index Page包含以下信息:所有Ordinal索引项数据、Ordinal Index Page的footer以及Short Key Page的Checksum信息。Ordinal Index Page的footer中包含当前Page的类型、Ordinal索引项数据的大小、Ordinal索引项数目等信息。
如果列中只有一个Data Page时,即该列只有一条Ordinal索引项,则Segment文件中不需要保存该列的Ordinal索引数据,只需要将这唯一的Data Page在Segment文件中的offset以及该Data Page的大小保存在Segment文件的footer中。数据读取时可以通过Segment文件的footer直接找到这唯一的Data Page。Ordinal索引的存储结构如图3所示。
Ordinal索引的作用是为了方便其他类型的索引能够使用统一的方式查找Data Page,进而可以对其他类型的索引屏蔽Data Page在Segment文件中的offset。
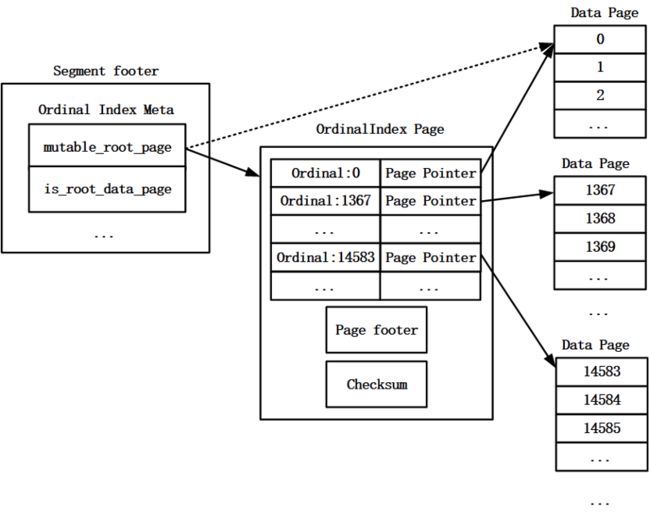
图3 Ordinal索引的存储结构
3.2 查询过滤
数据查询时,会加载每一个列的Ordinal索引数据。通过Segment footer中记录的Ordinal索引的Meta信息判断当前列是否存在Ordinal Index Page,即判断当前列是否有多个Data Page。
如果当前列存在Ordinal Index Page,则从Segment footer中获取Ordinal Index Page在Segment中的offset和Ordinal Index Page的大小,然后从Segment文件中读取Ordinal Index Page数据,并解析出每一条Ordinal索引项,即可通过Ordinal索引项获取当前列中每一个Data Page的起始行号、Data Page在Segment中的offset以及Data Page的大小。
如果当前列不存在Ordinal Index Page,则可以直接从Segment footer中获取当前列中唯一的Data Page在Segment中的offset以及Data Page的大小。
4 Zone Map 索引
Apache Doris 会为Segment文件中的一列数据添加Zone Map索引,同时会为列中的每一个Data Page添加Zone Map索引。Zone Map索引项中记录了每一列或列中每一个Data Page的最大值(max value)、最小值(min value)、是否有null值(has null)以及是否有非null值(has not null)的信息。初始化时,max value会被设置为当前列类型的最小值,min value会被设置为当前列类型的最大值,has null和has not null会被设置为false。
4.1 索引生成
数据刷写时,会给每一个Data Page创建一条Zone Map索引项。向Data Page中每添加一条数据,都会更新Data Page的Zone Map索引项。
如果添加的数据是null,则将Zone Map索引项的has null标志设置为true,否则,将Zone Map索引项的has not null标志设置为true。
如果添加的数据小于Zone Map索引项的min value,则使用当前数据更新min value;如果添加的数据大于Zone Map索引项的max value,则使用当前数据更新max value。
当一个Data Page写满之后,会更新一次列的Zone Map索引项,如果Data Page索引项的min value小于列索引项的min value,则使用Data Page索引项的min value更新列索引项的min value;如果Data Page索引项的max value大于列索引项的max value,则使用Data Page索引项的max value更新列索引项的max value;如果Data Page索引项的has null标志为true,则更新列索引项的has null标志为true;如果Data Page索引项的has not null标志为true,则更新列索引项的has not null标志为true。更新Zone Map索引的过程如图4所示。
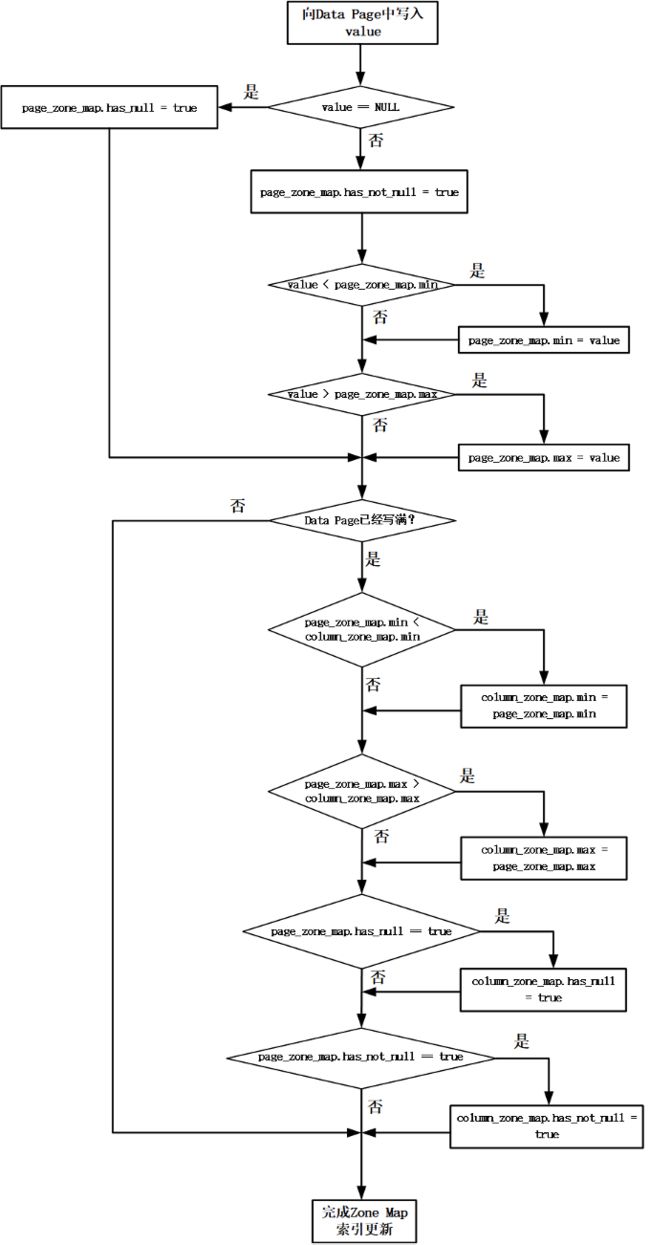
图4 更新Zone Map索引的过程
列中每一个Data Page的Zone Map索引项会被序列化之后保存在Zone Map Index Page中。
Zone Map Index Page中包含以下信息:Zone Map索引项数据、Zone Map Index Page的footer以及Zone Map Index Page的Checksum信息。
Zone Map Index Page的footer中包含当前Page的类型、当前Page中Zone Map索引项数据的大小、当前Page中Zone Map索引项数目以及当前Page中第一条索引项在整个列的Zone Map索引项中的序号等信息。
一个Zone Map Index Page写满之后,会创建新的Zone Map Index Page用于记录该列后续的Zone Map索引项。
如果某一列有多个Zone Map Index Page,则该列的Zone Map索引会采用两级索引机制。第二级索引为多个的Zone Map Index Page,其中保存Data Page的Zone Map索引数据,每一个Zone Map Index Page会生成一条Ordinal索引项,所有Zone Map Index Page的Ordinal索引项会被保存在一个Ordinal Index Page(注意,此处的Ordinal 索引与第3部分的Ordinal 索引不同,此处的Ordinal 索引指向Zone Map Index Page,而第3部分的Ordinal 索引指向Data Page)中作为一级索引。
每一个的Ordinal索引项由key和value两部分组成,key记录了当前Zone Map Index Page中第一条索引项在整个列的Zone Map索引项中的序号,value记录了当前Zone Map Index Page在Segment文件中的offset和大小。
Ordinal Index Page中包含以下信息:所有Zone Map Index Page的Ordinal 索引数据、Ordinal Index Page的footer以及Ordinal Index Page的Checksum信息。Ordinal Index Page的footer中包含当前Page的类型、当前Page中索引数据的大小、当前Page中索引项数目等。
一级索引Ordinal Index Page在Segment文件中的offset和大小会被记录在Segment文件的footer中。如果某一列只有一个Zone Map Index Page,则不需要两级索引,这个唯一的Zone Map Index Page在Block中的offset和大小会被记录在Segment文件的footer中。Zone Map索引的存储结构如图5所示。
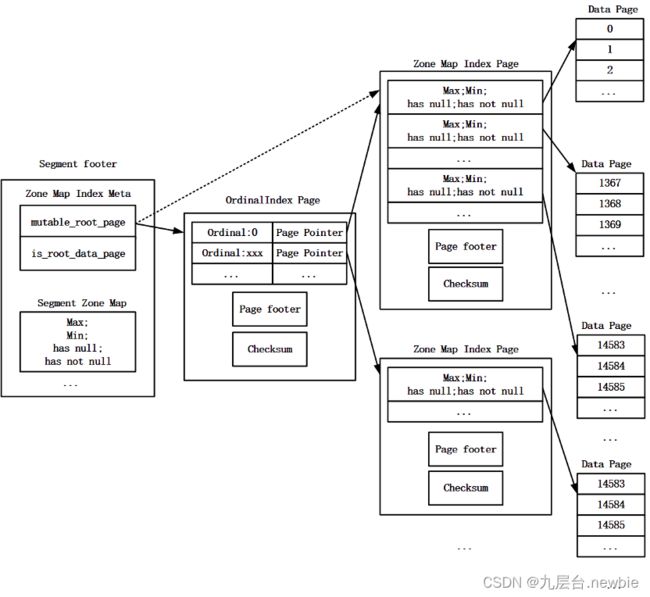
图5 Zone Map索引的存储结构
4.2 查询过滤
数据查询时,会加载每一个列的Zone Map索引数据,并解析出每一个Data Page的Zone Map索引数据。
通过Segment footer中记录的Zone Map索引的Meta信息判断当前列的Zone Map是否含有两级索引。
如果含有两级索引,则Segment footer中记录了一级索引Ordinal Index Page在Segment文件中的offset和大小,加载一级索引Ordinal Index Page,并解析出每一个的Ordinal索引项的key和value,key记录了每一个Zone Map Index Page中第一条索引项在整个列所有的Zone Map索引项中的序号,value记录了每一个Zone Map Index Page在Segment文件中的offset和大小。
否则,当前列的Zone Map索引只含有一个Zone Map Index Page,Segment footer中记录了该Zone Map Index Page在Segment文件中的offset和大小。可以通过Zone Map Index Page解析出每一个Data Page的Zone Map索引数据,其中包括最大值(max value)、最小值(min value)、是否有null值(has null)以及是否有非null值(has not null)的信息。
使用Zone Map对Data Page进行过滤的方法如下:
-
过滤条件的运算符不是IS。如果Zone Map索引的has null为true(Data Page中含有NULL值),则Data Page不能被过滤掉。
-
过滤条件为 field = value。如果 value在Zone Map索引的最大值与最小值之间,则Data Page不能被过滤掉。
-
过滤条件为 field != value。如果value小于Zone Map索引的最小值或value大于Zone Map索引的最大值,则Data Page不能被过滤掉。
-
过滤条件为 field < value。如果value大于Zone Map索引的最小值,则Data Page不能被过滤掉。
-
过滤条件为 field <= value。如果value大于或等于Zone Map索引的最小值,则Data Page不能被过滤掉。
-
过滤条件为 field > value。如果value小于Zone Map索引的最大值,则Data Page不能被过滤掉。
-
过滤条件为 field >= value。如果value小于或等于Zone Map索引的最大值,则Data Page不能被过滤掉。
-
过滤条件为 field IN {value1, value2, …}。如果value1、value2、…中至少存在一个值在Zone Map索引的最大值与最小值之间,则Data Page不能被过滤掉。
-
过滤条件为 field IS NULL。如果Zone Map索引的has null为true(Data Page中含有NULL值),则Data Page不能被过滤掉。
-
过滤条件为 field IS NOT NULL。如果Zone Map索引的has not null为true(Data Page中含有非NULL值),则Data Page不能被过滤掉。
对于未被Zone Map索引过滤的Data Page,可以使用Ordinal索引快速定位这些Data Page的起始行的行号,并获取这些Data Page的行范围。通过Data Page对应的Ordinal索引项快速获取当前Data Page的起始行的行号start,通过下一条Ordinal索引项快速获取后一个Data Page的起始行的行号end,左闭右开区间[start, end)即为当前Data Page的row范围。
5 Bitmap 索引
为了加速数据查询,Apache Doris支持用户为某些字段添加Bitmap索引。Bitmap索引由两部分组成:
-
有序字典:有序保存一列中所有的不同取值。
-
字典值的Roaring位图:保存有序字典中每一个取值的Roaring位图,表示字典值在列中的行号。
例如:如图6所示,一列数据为[x, x, y, y, y, z, y, x, z, x],一共包含10行,则该列数据的Bitmap索引的有序字典为{x, y, z}, x、y、z对应的位图分别为:
x的位图: [0, 1, 7, 9]
y的位图: [2, 3, 4, 6]
z的位图: [5, 8]
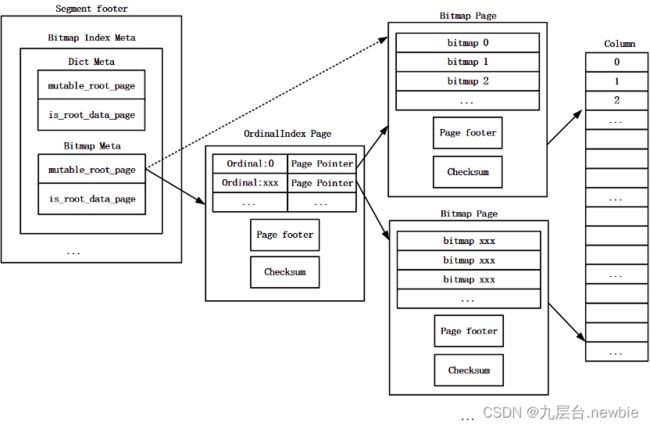
图6 Bitmap索引结构
5.1 索引生成
数据刷写时,会给用户指定的列创建Bitmap索引。向列中每添加一个值,都会更新当前列的Bitmap索引。从Bitmap索引的有序字典中查找添加的值是否已经存在,如果本次添加的值在Bitmap索引的有序字典中已经存在,则直接更新该字典值对应的Roaring位图,如果本次添加的值在Bitmap索引的有序字典中不存在,则将该值添加到有序字典,并为该字典值创建Roaring位图。当然,NULL值也会有单独的Roaring位图。
Bitmap索引的字典数据和Roaring位图数据分开存储。
列中Bitmap索引的字典值会按顺序保存在Dict Page中。Dict Page中包含以下信息:Bitmap索引的字典数据、Dict Page的footer以及Dict Page的Checksum信息。Dict Page的footer中包含当前Page的类型、当前Page中Bitmap索引的字典数据的大小、当前Page中Bitmap索引的字典值数目以及当前Page中第一个字典值在整个列的Bitmap索引字典值中的序号等信息。Bitmap索引的字典数据会按照LZ4F格式进行压缩。
一个Dict Page写满之后,会创建新的Dict Page用于记录该列后续的字典数据。
如果某一列有多个Dict Page,则会采用两级索引机制。第二级索引为多个的Dict Page,其中保存Bitmap索引的字典数据,每一个Dict Page生成一条Value索引项,所有Dict Page的Value索引项会被保存在一个Value Index Page中作为一级索引。每一个的Value索引项记录了当前Dict Page中第一个字典值的编码以及当前Dict Page在Segment文件中的offset和大小。
Value Index Page中包含以下信息:所有Dict Page的Value索引数据、Value Index Page的footer以及Value Index Page的Checksum信息。Value Index Page的footer中包含当前Page的类型、当前Page中索引数据的大小、当前Page中索引项数目等。
一级索引Value Index Page在Segment文件中的offset和大小会被记录在Segment文件的footer中。如果某一列只有一个Dict Page,则不需要两级索引,这个唯一的Dict Page在Segment文件中的offset和大小会被记录在Segment文件的footer中。Bitmap索引的字典数据的存储结构如图7所示。
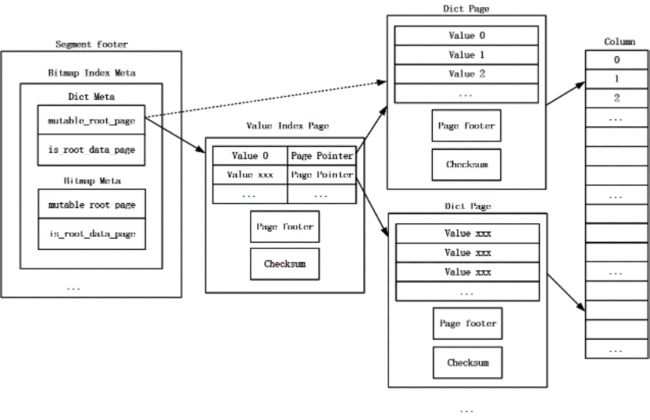
图7 Bitmap索引的字典数据的存储结构
列中Bitmap索引的Roaring位图数据会保存在Bitmap Page中。
Bitmap Page中包含以下信息:Bitmap索引的Roaring位图数据、Bitmap Page的footer以及Bitmap Page的Checksum信息。
Bitmap Page的footer中包含当前Page的类型、当前Page中Bitmap索引的Roaring位图数据的大小、当前Page中Bitmap索引的Roaring位图数目以及当前Page中第一个Roaring位图在整个列的Bitmap索引的Roaring位图中的序号等信息。Bitmap索引的Roaring位图数据不进行压缩。
一个Bitmap Page写满之后,会创建新的Bitmap Page用于记录该列后续的Roaring位图数据。
如果某一列有多个Bitmap Page,则会采用两级索引机制。第二级索引为多个的Bitmap Page,其中保存Bitmap索引的位图数据,每一个Bitmap Page生成一条Ordinal索引项,所有Bitmap Page的Ordinal索引项会被保存在一个Ordinal Index Page(注意,此处的Ordinal 索引与第3部分的Ordinal 索引不同,此处的Ordinal 索引指向Bitmap Page,而第3部分的Ordinal 索引指向Data Page)中作为一级索引。
每一个的Ordinal索引项由key和value两部分组成,key记录了当前Bitmap Page中第一个Roaring位图在整个列的BitMap索引Roaring位图中的序号,value记录了当前Bitmap Page在Segment文件中的offset和大小。
Ordinal Index Page中包含以下信息:所有Bitmap Page的Ordinal 索引数据、Ordinal Index Page的footer以及Ordinal Index Page的Checksum信息。Ordinal Index Page的footer中包含当前Page的类型、当前Page中索引数据的大小、当前Page中索引项数目等。
一级索引Ordinal Index Page在Segment文件中的offset和大小会被记录在Segment文件的footer中。如果某一列只有一个Bitmap Page,则不需要两级索引,这个唯一的Bitmap Page在Segment文件中的offset和大小会被记录在Segment文件的footer中。Bitmap索引的Roaring位图数据的存储结构如图8所示。

图8 Bitmap索引的Roaring位图数据的存储结构
5.2 查询过滤
数据查询时,会加载列的Bitmap索引数据,并解析出有序字典和Roaring位图数据。
-
首先,通过Segment footer中记录的Bitmap索引的字典Meta信息判断当前列的Bitmap索引的字典是否含有两级索引,如果含有两级索引,则Segment footer中记录了一级索引Value Index Page在Block中的offset和大小,首先加载一级索引Value Index Page,并解析出每一个的Value索引项,获得每一个Dict Page中第一个字典值和每一个Dict Page在Segment文件中的offset和大小;否则,当前列的Bitmap索引只含有一个Dict Page,Segment footer中记录了该Dict Page在Segment文件中的offset和大小。可以通过Dict Page解析出每一个字典值。
-
然后,通过Segment footer中记录的Bitmap索引的Roaring位图Meta信息判断当前列的Bitmap索引的Roaring位图是否含有两级索引,如果含有两级索引,则Segment footer中记录了一级索引Ordinal Index Page在Segment文件中的offset和大小,首先加载一级索引Ordinal Index Page,并解析出每一个的Ordinal索引项,获得每一个Bitmap Page中第一个Roaring位图在整个列的Bitmap索引Roaring位图中的序号以及每一个Bitmap Page在Segment文件中的offset和大小;否则,当前列的Bitmap索引只含有一个Bitmap Page,Segment footer中记录了该Bitmap Page在Segment文件中的offset和大小。可以通过Bitmap Page中解析出每一个字典值对应的Roaring位图。
真正使用Bitmap索引进行数据过滤时才会加载Dict Page和Bitmap Page。
使用某一个查询过滤条件进行行过滤的方法如下:
-
过滤条件为 field = value。从 Dict Page 中寻找第一个等于或大于 value 的字典值,并且获取该字典值在有序字典中的序号ordinal。如果寻找到的字典值恰好等于value,则从 Bitmap Page 中读取第ordinal个位图,则该位图表示通过该查询条件过滤之后留下的行范围。
-
过滤条件为 field != value。从Dict Page中寻找第一个等于或大于value的字典值,并且获取该字典值在有序字典中的序号ordinal。如果寻找到的字典值恰好等于value,则从Bitmap Page中读取第ordinal个位图,则该位图表示需要被过滤掉的行范围。
-
过滤条件为 field < value。从Dict Page中寻找第一个等于或大于value的字典值,并且获取该字典值在有序字典中的序号ordinal。从Bitmap Page中读取前面ordinal个位图,这些位图的并集表示通过该查询条件过滤之后留下的行范围。
-
过滤条件为 field <= value。从Dict Page中寻找第一个等于或大于value的字典值,并且获取该字典值在有序字典中的序号ordinal。如果寻找到的字典值恰好等于value,则从Bitmap Page中读取前面ordinal + 1个位图;如果寻找到的字典值大于value,则从Bitmap Page中读取前面ordinal个位图,这些位图的并集表示通过该查询条件过滤之后留下的行范围。
-
过滤条件为 field > value。从Dict Page中寻找第一个等于或大于value的字典值,并且获取该字典值在有序字典中的序号ordinal。如果寻找到的字典值恰好等于value,则从Bitmap Page中读取第ordinal个位图之后的所有位图;如果寻找到的字典值大于value,则从Bitmap Page中读取第ordinal以及之后的所有位图,这些位图的并集表示通过该查询条件过滤之后留下的行范围。
-
过滤条件为 field >= value。从Dict Page中寻找第一个等于或大于value的字典值,并且获取该字典值在有序字典中的序号ordinal。从Bitmap Page中读取ordinal之后的所有位图,这些位图的并集表示通过该查询条件过滤之后留下的行范围。
5.3 适用场景
Apache Doris支持在建表时对指定的列创建Bitmap索引,也可以对已经创建的表执行Alter Table命令添加Bitmap索引。
ALTER TABLE table_name ADD INDEX index_name (column_name) USING BITMAP COMMENT ‘’;
目前只支持对TINYINT、SMALLINT、INT、 UNSIGNEDINT、BIGINT、LARGEINT、CHAR、 VARCHAR、DATE、DATETIME、BOOL和DECIMAL类型的字段创建Bitmap索引,其他类型的字段均不支持Bitmap索引。Bitmap索引比较适合在基数较低的列上进行等值查询或范围查询的场景。
6 Bloom Filter 索引
Apache Doris支持用户对取值区分度比较大的字段添加Bloom Filter索引,Bloom Filter索引按照Data Page的粒度生成。数据写入时,会记录每一个写入Data Page的值,当一个Data Page写满之后,会根据该Data Page的所有不同取值为该Data Page生成Bloom Filter索引。数据查询时,查询条件在设置有Bloom Filter索引的字段进行过滤,当某个Data Page的Bloom Filter没有命中时,表示该Data Page中没有需要的数据,这样可以对Data Page进行快速过滤,减少不必要的数据读取。
6.1 索引生成
数据刷写时,会给每一个Data Page创建一条Bloom Filter索引项。Apache Doris采用了基于Block的Bloom Filter算法。每一个Data Page对应的Bloom Filter索引数据会被划分为多个Block,每个Block的数据长度为BYTES_PER_BLOCK(默认为32字节,共256bit),Block中的每一个Bit位会被初始化为0。向Data Page中写入数据时,每一个不同的取值value都会将一个Block中的BITS_SET_PER_BLOCK(默认值为8)个Bit置位为1。Bloom Filter索引的结构如图9所示。
单个Data Page的Bloom Filter索引数据长度BLOOM_FILTER_BIT通过如下公式计算:
BLOOM_FILTER_BIT = -N * ln(FPP) / (ln(2) ^ 2)
其中,N表示当前Data Page中的不同取值的个数;FPP(False Positive Probablity) 表示期望的误判率,默认取值为0.05。(注:计算出的Bloom Filter数据长度(单位为bit)一定是2的整数次幂。)
Bloom Filter中,每一个Block的长度为BYTES_PER_BLOCK(32字节),因此,Bloom Filter中的Block数量通过如下公式计算:
BLOCK_NUM = (BLOOM_FILTER_BIT / 8) / BYTES_PER_BLOCK;
为Data Page生成Bloom Filter索引项的方法如下:
-
针对Data Page中的每一个不同的取值value,计算出一个64位的HASH_CODE。Apache Doris中,Bloom Filter的Hash策略为HASH_MURMUR3。
-
取HASH_CODE的高32位计算出当前value在Bloom Filter中对应的Block,方法如下:
BLOCK_INDEX = (HASH_CODE >> 32) & (BLOCK_NUM - 1)
其中,BLOCK_INDEX表示Block的序号,BLOCK_NUM为2的整数次幂,则BLOCK_INDEX一定小于BLOCK_NUM。
- 取HASH_CODE的低32位计算出当前value会将Block中的哪些Bit置位为1,方法如下:
uint32_t key = (uint32_t)HASH_CODE
uint32_t SALT[8] = {0x47b6137b, 0x44974d91, 0x8824ad5b, 0xa2b7289d, 0x705495c7, 0x2df1424b, 0x9efc4947, 0x5c6bfb31};
uint32_t masks[BITS_SET_PER_BLOCK];
for (int i = 0; i < BITS_SET_PER_BLOCK; ++i) {
masks\[i\] = key \* SALT\[i\];
masks\[i\] = masks\[i\] >> 27;
masks\[i\] = 0x1 << masks\[i\];
}
其中,masks[i]包含32个Bit,其中只有1个Bit被置位为1,其他31个Bit均为0。
- 将masks[i]与Block中第i个32Bit按位取或,更新Data Page的Bloom Filter索引数据。(一个Block中包含256个Bit,即 BITS_SET_PER_BLOCK 个32 Bit)
uint32_t* BLOCK_OFFSET = BLOOM_FILTER_OFFSET + BYTES_PER_BLOCK * BLOCK_INDEX
for (int i = 0; i < BITS_SET_PER_BLOCK; ++i) {
*(BLOCK_OFFSET + i) |= masks[i];
}
其中,BLOOM_FILTER_OFFSET表示当前Data Page的Bloom Filter的偏置,BLOCK_OFFSET表示当前block的偏置。

图9 Bloom Filter索引的结构
Bloom Filter索引项中单独设置了Data Page中是否包含了NULL值的标志。
列中每一个Data Page的Bloom Filter索引项会被保存在Bloom Filter Index Page中。Bloom Filter Index Page中包含以下信息:Bloom Filter索引项数据、Bloom Filter Index Page的footer以及Bloom Filter Index Page的Checksum信息。Bloom Filter Index Page的footer中包含当前Page的类型、当前Page中Bloom Filter索引项数据的大小、当前Page中Bloom Filter索引项数目以及当前Page中第一条索引项在整个列的Bloom Filter索引项中的序号等信息。
一个Bloom Filter Index Page写满之后,会创建新的Bloom Filter Index Page用于记录该列后续的Bloom Filter索引项。如果某一列有多个Bloom Filter Index Page,则该列的Bloom Filter索引会采用两级索引机制。第二级索引为多个的Bloom Filter Index Page,其中保存Data Page的Bloom Filter索引数据,每一个Bloom Filter Index Page生成一条Ordinal索引项,所有Bloom Filter Index Page的Ordinal索引项会被保存在一个Ordinal Index Page(注意,此处的Ordinal 索引与第3部分的Ordinal 索引不同,此处的Ordinal 索引指向Bloom Filter Index Page,而第3部分的Ordinal 索引指向Data Page)中作为一级索引。
每一个的Ordinal索引项由key和value两部分组成,key记录了当前Bloom Filter Index Page中第一条索引项在整个列的Bloom Filter索引项中的序号,value记录了当前Bloom Filter Index Page在Segment文件中的offset和大小。Ordinal Index Page中包含以下信息:所有Bloom Filter Index Page的Ordinal 索引数据、Ordinal Index Page的footer以及Ordinal Index Page的Checksum信息。Ordinal Index Page的footer中包含当前Page的类型、当前Page中索引数据的大小、当前Page中索引项数目等。一级索引Ordinal Index Page在Segment文件中的offset和大小会被记录在Segment文件的footer中。如果某一列只有一个Bloom Filter Index Page,则不需要两级索引,这个唯一的Bloom Filter Index Page在Segment文件中的offset和大小会被记录在Segment文件的footer中。Bloom Filter索引的存储结构如图10所示。

图10 Bloom Filter索引的存储结构
6.2 查询过滤
数据查询时,会加载列的Bloom Filter索引数据,并解析出每一个Data Page的Bloom Filter索引项。首先,通过Segment footer中记录的Bloom Filter索引的Meta信息判断当前列的Bloom Filter是否含有两级索引,如果含有两级索引,则Segment footer中记录了一级索引Ordinal Index Page在Segment文件中的offset和大小,先加载一级索引Ordinal Index Page,并解析出每一个的Ordinal索引项的key和value,key记录了每一个Bloom Filter Index Page中第一条索引项在整个列所有的Bloom Filter索引项中的序号,value记录了每一个Bloom Filter Index Page在Segment文件中的offset和大小;否则,当前列的Bloom Filter索引只含有一个Bloom Filter Index Page,Segment footer中记录了该Bloom Filter Index Page在Segment文件中的offset和大小。可以通过Bloom Filter Index Page解析出每一个Data Page的Bloom Filter索引数据。
判断某个值value是否命中Bloom Filter的方法如下:
-
首先,基于HASH_MURMUR3方法对查询过滤条件的值value计算出64位的HASH_CODE;
-
然后,采用与生成Bloom Filter索引数据相同的方法计算出该value值在Bloom Filter中对应的Block,以及在Block中对应的BITS_SET_PER_BLOCK个Bit位。
-
判断Bloom Filter索引数据中对应Block的这BITS_SET_PER_BLOCK个Bit的值是否均为1。如果对应Block中的这BITS_SET_PER_BLOCK个Bit值均为1,则表示Bloom Filter命中,该value值在Bloom Filter对应的Data Page中可能存在;否则,表示Bloom Filter未命中,该value值在Bloom Filter对应的Data Page中一定不存在。
数据查询时,查询过滤条件(“=”、"IS"或"IN"语句)在设置有Bloom Filter索引的列依次对每一个Data Page进行过滤。进行NULL值查询时,可以直接使用Bloom Filter索引项中的NULL值标志进行Data Page过滤。进行非NULL值查询时,使用查询过滤条件对Data Page进行过滤的方法如下:
-
过滤条件为 field = value 。如果value未命中某一个Data Page对应的Bloom Filter,则该Data Page可以被过滤掉。
-
过滤条件为 field IN {value1, value2, …} 。如果 value1、value2、…中所有值都未命中某一个Data Page对应的Bloom Filter,则该Data Page可以被过滤掉。
过滤条件为 field IS NULL 。如果NULL值未命中某一个Data Page对应的Bloom Filter,则该Data Page可以被过滤掉。
6.3 适用场景
Apache Doris支持在建表时对指定的列创建Bloom Filter索引,也可以对已经创建的表执行Alter Table命令添加Bloom Filter索引。
ALTER TABLE table_name SET (“bloom_filter_columns”=“c1, c2, c3”);
目前只支持对SMALLINT、INT、UNSIGNEDINT、 BIGINT、LARGEINT、CHAR、 VARCHAR、DATE、DATETIME和DECIMAL类型的字段创建Bloom Filter索引,其他类型的字段均不支持Bloom Filter索引。对于创建了Bloom Filter索引的字段,查询条件是"="、"is"或"in"语句时,才会使用Bloom Filter索引进行Data Page的过滤。Bloom Filter索引比较适合在基数较高的列上进行等值查询的场景。
结束语
为了加快数据查询效率,Apache Doris 的存储引擎提供了前缀索引、Ordinal 索引、Zone Map索引、Bitmap 索引和 Bloom Filter 索引,可以在数据读取之前快速地进行数据过滤。前缀索引、Ordinal 索引和 Zone Map 索引不需要用户干预,会随着数据写入自动生成;数据写入时默认不会生成 Bitmap 索引和 Bloom Filter 索引,用户可以有选择地为指定的列添加这两种索引。本文主要从数据写入过程中索引的生成、索引的物理存储结构以及数据查询过程中如何使用索引进行数据过滤等方面对这几种索引的的底层机制分别进行了详细地剖析。