全链路压测实践
一 背景
随着业务的不断增长,系统的稳定性保障尤为重要,传统压测存在诸多不足,以往的压测中各个业务线对单个接口压测,需要单独准备测试机,测试成本高,而且无法直接压测线上接口,也没有历史压测记录的收集对比。针对上述情况我们自研了全链路压测平台进行压测,直接对线上接口进行压测,节省了机器资源,同时可以观察链路上各个节点的健康度和稳定性,及时发现薄弱环节,提高系统健壮性。本文将阐述全链路压测的核心设计与实践。
二 全链路压测检测
1.什么是全链路压测
基于实际的生产业务场景、系统环境,模拟海量的用户请求和数据对整个业务链进行压力测试(流量录制、回放、施压等),并持续调优。全链路压测与传统压测区别如下:
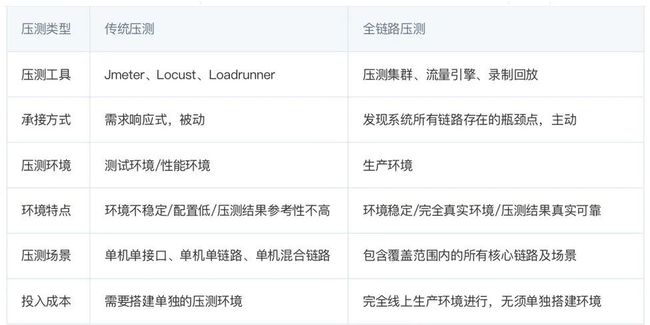
2.全链路压测的优势
(1)直接压测生产环境,完全真实请求场景
(2)大幅度节省机器成本
(3)完整的链路监控
(4)快速发现存在问题
3.技术选型
在技术选型上我们主要考虑两个因素:
(1)对现有系统的改造难度
(2)能否能够有效降低人力和机器成本。
我们调研了业界的主要方案:
(1)流量打标,美团和阿里都采用了流量打标方案;
(2)机器打标,达达采用了机器打标方案。
这两种方案都可以实现数据隔离和流量隔离,两种方案的主要区别如下:
流量打标
DB层:使用 影子库/影子表隔离数据
Cache层:使用 影子缓存 隔离数据
MQ层:使用 影子队列 隔离数据
流量打标架构图:

机器打标
机器打标通过单独部署独立的机器、独立的DB、MQ实现,采用不用的链路来实现流量隔离和数据隔离,各压测节点的机器都需要单独部署,相比流量打标需要更多的机器资源。
考虑到机器成本问题、改造难度问题我们最终选择了流量打标。流量打标有以下优点:
方案成熟,美团、阿里都采用了流量打标方案。
相对机器成本低,不需要单独部署压测机器。
改造成本低,公司内部使用的中间件统一,比如使用统一的JAVA框架、PHP框架、MQ、数据库代理等,这样只改造统一的中间件就可以标记和识别压测流量。
三 压测平台核心设计
1.总体架构
压测平台的总体架构图:

压测平台主要组成模块:
1)brain
brain是整个压测平台的控制中心,用户在brain管理后台发起压测任务。brain的主要职责如下:
压测目标的创建和配置
压测任务的创建、启动、终止
压测报告的展示
2)duckpear-engine
duckpear-engine是发压引擎,包括kafka-replay、goreplay、vegeta,该模块的核心功能是命令的组装、执行。
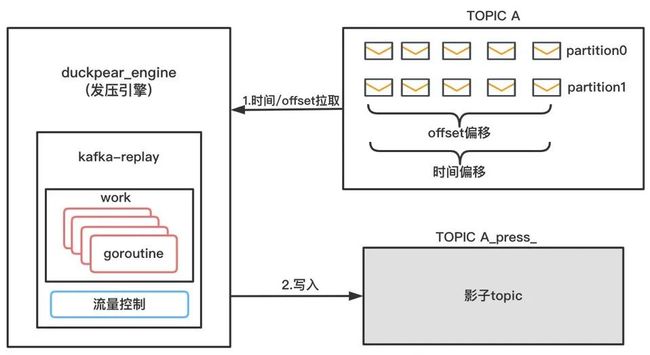
(1)kafka-replay
kafka-replay是对某个topic A进行回放,回放时会将消息写入影子topic A_press_。支持两种方式进行回放:
根据消息生产的时间进行回放
根据消息的偏移量进行回放
(2)goreplay
goreplay是对线上http流量进行录制和回放。
流量录制:采集业务服务的端口流量,然后将请求记录存储到腾讯云cos上,流量录制可以录制指定sfns下的一台或者多台机器。
流量回放:针对录制的流量进行回放到指定的机器上,回放时可以指定回放的频率,支持以固定的tps回放,和按录制的qps进行倍速回放。
(3)vegeta
接口压测工具是在vegeta基础上二次开发, vegeta和jmeter一样可以指定线程数、执行时间、构造请求参数、结果断言等,支持分布式运行,当压测需求吞吐量比较高时可以采用多机进行分布式压测。
2.核心组件
1)vegeta
接口压测引擎是基于开源框架vegeta做的二次开发,vegeta采用go语言实现。选型vegeta主要考量点有两个:(1)并行性能:vegeta发压通过goroutine实现,goroutine具有简单轻量、并发性能表现优异的特点。
(2)二次开发的难易程度:现有系统使用go开发,选型vegeta降低了系统集成难度。
架构图:

为满足业务需求,vegeta我们做了以下改造:
(1)SDK改造,以SDK模式集成到duckpear_engine中,不再启动单独的vegeta进程,避免了进程管理问题,提高了系统稳定性。
(2)支持顺序压测和并行压测功能,当多个接口同时进行压测时适用并行压测场景,如果当前请求依赖上一个请求的结果时适用顺序压测场景。
(3)支持参数构造功能,通过上传参数附件,结合参数构造模板可以构造出请求体。
(4)支持结果断言功能,同时支持JSON、TEXT、XML断言。
(5)支持prometheus监控,实时监控发压机和目的接口。
流量录制和回放是基于开源框架GoReplay做的二次开发,GoReplay基于 Go 语言实现,底层依赖 pcap 库提供流量录制能力。著名的 tcpdump 也依赖于 pcap 库,目前只支持录制 http 流量。
Goreplay架构图:

录制和回放的流程如下:
录制流程:
(1)用户在压测平台提交录制请求给压测引擎
(2)压测引擎生成录制命令
(3)录制命令通过运维执行系统下发到指定的机器上,调起GoReplay
(5)录制结束后GoReplay退出,并通知压测引擎录制结束
回放流程:
(1)用户在压测平台提交回放请求给压测引擎
(2)压测引擎生成回放命令
(3)压测引擎直接拉起 GoReplay
(4)GoReplay从腾讯云cos下载录制的文件
(5)GoReplay解析文件后进行回放
(6)录制结束后GoReplay退出,并通知压测引擎回放结束
Goreplay我们做了以下改造:
(1)支持速率控制功能,可设定固定的频率进行回放。
(2)支持流量还原功能,可按录制的qps进行还原或者倍速还原。
(3)支持cos存储,针对录制的大文件分割成小文件存储到cos上,流量还原时从cos上下载文件。
(4)支持prometheus监控,实时对发压机和目的接口进行监控。
3)kafka-replay
kafka-replay回放按消息生产的时间或者消息的偏移量进行回放, 回放到影子topic,同时回放时可以指定回放的线程数和速率。kafka-replay用来压测kafka的写入性能。
架构图如下:
3.数据隔离
db:通过两套配置一个是生产库一个是影子库实现数据隔离,当识别到压测流量后首先判断是否有影子库配置,如果有影子库配置则写入影子库,如果未配置则使用原库名加固定后缀_press_作为影子库。
redis:识别到压测流量后会判断是否配置影子redis,如果配置,则使用影子redis。如果未配置会区分真实key和影子key,如果是压测流量,缓存时会写入影子key。
sfmq:sfmq-proxy通过header识别压测流量,写入kafka时会在当前topic增加后缀, pusher 配置订阅压测的topic,pusher下发请求时会增加header标示,标记为压测流量。
数据隔离架构图:

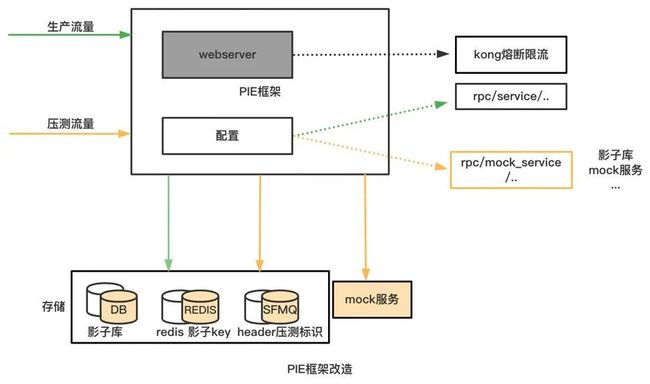
4.流量隔离
开发框架PIE:增加流量识别和压测开关、增加kong网关熔断限流、增加接口mock服务,当识别到压测流量后会根据配置最终写入影子库、影子topic或者访问mock服务。
四 压测平台核心功能
1.kafka回放
kafka回放可视化界面:
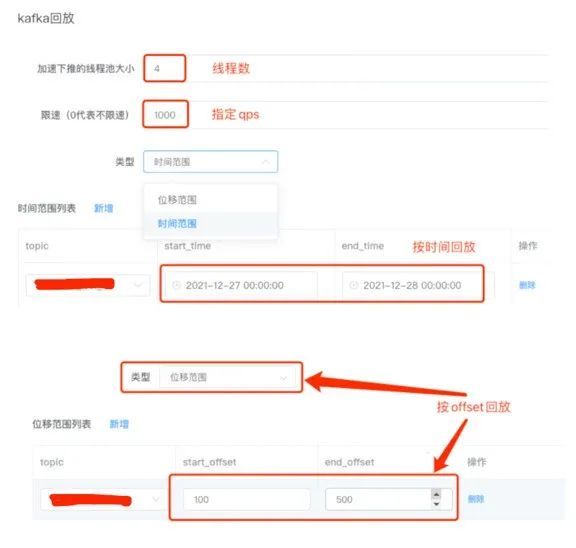
主要功能:
1)指定下推线程数
2)设定下推的速率
3)按时间或者offset回放
4)生成回放报告
2.流量录制与回放
流量录制和回放是对线上http流量进行录制并按一定的频率进行回放。
流量录制和回放可视化界面:

流量录制和回放主要功能:
1)指定录制的机器
2)设定录制时间
3)录制参数过滤
4)指定回放的机器
5)回放的时间和速率
6)回放线程数量
7)回放报告生成
3.接口压测
接口压测可视化界面如下:
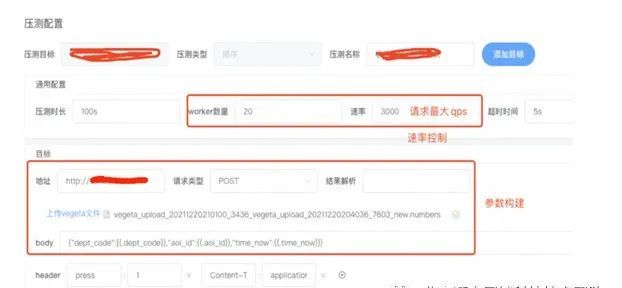
接口压测主要功能:
1)支持串行和并行压测
2)压测线程数控制
3)压测速率控制,设置的速率是发压的最大QPS
4)请求参数通过参数模板和附件构建
5)压测报告生成
此外vegeta还可以模拟固定的qps持续进行请求,例如我们希望某个服务A他能承受的最大QPS是1000,这时候vegeta能持续产生1000qps的负载进行一段时间的压测,这段时间里,我们可能通过监控系统的核心指标来判断系统的健康度和稳定性vegeta可以满足这个场景下的压测需求。
4.发压引擎扩容
发压引擎是分布式的,发压引擎实现了可扩展能力,通过配置和压测目标绑定实现扩容。扩容方式如下:
1)发压引擎对应的sfns添加机器资源
2)通过统一的服务发布平台发布发压引擎服务
3)配置发压引擎和压测目标的映射,实现发压引擎和压测目标的绑定
五 全链路压测实施
全链路压测实施分成:压测前,压测中,压测后:
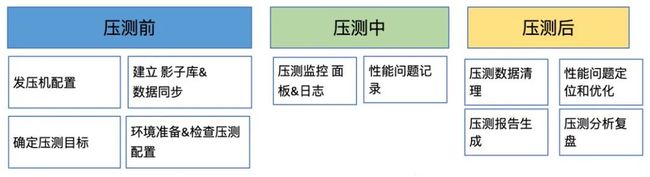
其中压测前有三个关键点:压测数据准备、压测配置检查、评估可能出现的风险点。
压测中需观察链路上各个节点的监控指标是否正常,出现异常时及时终止本次压测。
压测后主要对压测过程进行复盘,分析压测结果,评估是否达到压测目标以及系统是否存在性能瓶颈。
六 总结
目前压测平台已经在智域、大数据业务线中落地,其它业务线也在陆续接入。压测平台降低了压测门槛,节省了机器资源,通过压测平台可视化的界面可以很方便的完成压测任务和对压测结果的分析,但是压测平台还是有一些痛点,比如压测数据准备,特别是存在超大表时数据同步工作耗时较长。
为了更好地评估系统性能,及时发现性能瓶颈,并降低压测实施难度,未来将进一步完善压测平台,降低数据准备等相关工作,更好地服务于业务。
现在我邀请你进入我们的软件测试学习交流群:【
746506216】,备注“入群”, 大家可以一起探讨交流软件测试,共同学习软件测试技术、面试等软件测试方方面面,还会有免费直播课,收获更多测试技巧,我们一起进阶Python自动化测试/测试开发,走向高薪之路。
资源分享
下方这份完整的软件测试视频学习教程已经上传CSDN官方认证的二维码,朋友们如果需要可以自行免费领取 【保证100%免费】

