Service Mesh 发展趋势(续):棋到中盘路往何方 | Service Mesh Meetup 实录
敖小剑,蚂蚁金服高级技术专家,十七年软件开发经验,微服务专家,Service Mesh 布道师,ServiceMesher 社区联合创始人。
本文内容整理自 8 月 11 日 Service Mesh Meetup 广州站主题演讲,完整的分享 PPT 获取方式见文章底部。
| 前言
标题“Service Mesh发展趋势(续)”中的“续”是指在今年5月底,我在 CloudNative Meetup上做了一个“ Service Mesh 发展趋势:云原生中流砥柱 ”的演讲,当时主要讲了三块内容:Service Mesh 产品动态、发展趋势、与云原生的关系。后来有同学反应希望部分感兴趣的内容能讲的更深一些,所以今天将继续“Service Mesh 发展趋势”这个话题。
今天给大家分享的内容有部分是上次演讲内容的深度展开,如社区关心的 Mixer v2 以及最近看到的一些业界新的技术方向,如 web assembly 技术,还有产品形态上的创新,如 google traffic director 对 Service Mesh 的虚拟机形态的创新支持。
在 Service Mesh 出道四年之际,也希望和大家一起带着问题来对 Service Mesh 未来的发展进行一些深度思考。
在正式开始分享之前,让我们先轻松一下,下面是最近流行的梗,各种灵魂拷问:

我们今天的分享内容,将效仿上面的方式,对 Servic Mesh 进行四个深入灵魂的拷问。
| Service Mesh 灵魂拷问一:要架构还是要性能?
第一个灵魂拷问针对 Istio 的:要架构还是要性能?
Istio 的回答:要架构
Istio 的回答很明确:架构优先,性能靠边。

左边是 Istio 的架构图,从 2017 年的 0.1 版本开始,一直到 Istio1.0,控制平面和数据平面完全物理分离,包括我们今天要关注的 Mixer 模块。Sidecar 通过和 Mixer 的交互实现策略检查和遥测报告。
右边是 Mixer 的架构图,在 Mixer 内部提供了很多 Adapter 实现,用来提供各种功能。这些 Adapter 运行在 Mixer 进程中,因此被称为进程内适配器(In-Process Adapter)。
为什么 Istio 选择 Mixer 和 Proxy 分离的架构?
我们先来看这个架构的优点,概括地说优点主要体现为:
-
架构优雅
-
职责分明
-
边界清晰
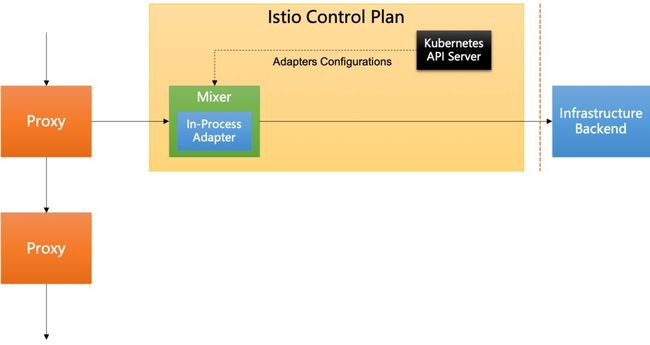
特别指出,上图右侧的红色竖线,是 Istio0.1 到 Istio1.0 版本中 Istio 和后台基础设施的边界。这意味着,从 k8s API Server 中读取 Adapter 相关的配置信息 (以 Istio CRD 的形式存在),是作为 Istio 功能的一部分。
具体的优点是:
-
Mixer 的变动不影响 Sidecar:包括 Mixer 的部署调整和版本升级;
-
Sidecar 无需和 Adapter 耦合,具体有:
-
Sidecar 不需要读取配置,因此也无需直接连接到 k8s AP Server/Istio Galley;
-
Adapter 的运行时资源开销和 Sidecar 无关;
-
Sidecar 不受 Adapter 增减/更新/升级影响;
-
保持 Sidecar 代码简单:数以几十计的 Adapter 的代码无需直接进入 Sidecar 代码;
-
数据平面可替换原则:如果有替换数据平面的需求,则 Mixer 分离的架构会让事情简单很多;
至于缺点,只有一个:性能不好。
而 1.1 版本之后,Istio 给出了新的回答:架构继续优先,性能继续靠边。
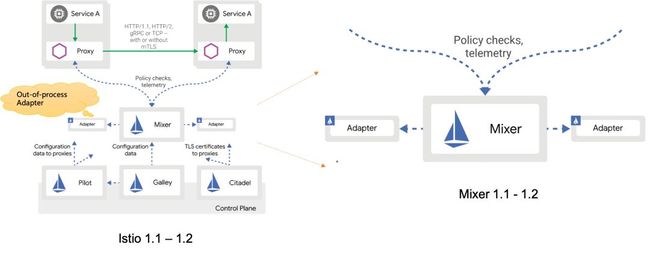
上图是 Istio1.1 版本之后新的架构图,和之前的差异在于 Mixer 发生了变化,增加了进程外适配器(Out-of-Process Adapter),而 Mixer 和新的 Out-of-Process Adapter 之前依然是远程调用。
为什么 Istio 改而选择 Out-of-Process Adapter?
下图是采用 Out-of-Process Adapter 之后的请求处理流程图,Mixer 通过 Bypass Adapter 选择需要的属性列表,然后通过远程调用发送给 Out-of-Process Adapter。Out-of-Process Adapter 实现和之前的 In-Process Adapter 类似的功能,但是改为独立于 Mixer 的单独进程。

采用 Out-of-Process Adapter 之后,Istio 的优点更加明显了,简单说就是:架构更优雅,职责更分明,边界更清晰。
而且,请注意:按照 Istio 的设想,此时 Out-of-Process Adapter 已经不再作为 Istio 的组成部分,它的代码实现、安装部署、配置、维护等职责也不再由 Istio 承担,请留意上图中的红色竖线位置。Out-of-Process Adapter 的引入,对于 Istio 来说职责和边界的改变会让 Istio 简单,但是对于使用者(主要指运维)来说则增加了额外的负担,因此造成了很大的争议。
至于缺点,除了上述的职责转移造成争议外,依然只有一个:性能不好,原来 Sidecar 和 Mixer 之间的远程调用已经让性能变得非常糟糕,现在 Mixer 和 Out-of-Process Adapter 之间再增多加一次远程调用,可谓雪上加霜。
Mixer v1 架构的优缺点分析
Mixer v1 架构的优点主要体现为:
1. 集中式服务:提高基础设施后端的可用性,为前置条件检查结果提供集群级别的全局 2 级缓存;
2.灵活的适配器模型,使其以下操作变得简单:
-
运维添加、使用和删除适配器;
-
开发人员创建新的适配器(超过20个适配器);
而 Mixer v1 架构的缺点,则主要体现为:
1. 管理开销:
-
管理 Mixer 是许多客户不想负担的;
-
而进程外适配器强制运维管理适配器,让这个负担更加重;
2. 性能:
-
即使使用缓存,在数据路径中同步调用 Mixer 也会增加端到端延迟;
-
进程外适配器进一步增加了延迟;
-
授权和认证功能是天然适合 mixer pipeline 的,但是由于 mixer 设计的延迟和 SPOF(单点故障)特性,导致直接在 Envoy 中实现(Envoy SDS);
3. 复杂性:
-
Mixer 使用一组称为模板的核心抽象,来描述传递给适配器的数据。这些包括“metrics”,“logentry”,“tracepan”等。这些抽象与后端想要消费的数据不匹配,导致运维需要编写一些手动配置,以便在规范的 Istio 样式和后端特定的样式之间进行映射。原本期望这种映射可以在适配器中实现很大程度上的自动化,但是最终还是太复杂并需要手动配置。
备注:上述优点和缺点的描述摘录自 mixer v2 proposal 。
其中,Mixer 性能问题一直以来都是 Istio 最被人诟病的地方。
那问题来了:如果要性能,该怎么做?
下图是 Mixer v1 的调用流程,Proxy/Sidecar 是请求数据的起点,Infrastructure Backend 是终点。Mixer v1 性能不好的原因是多了 Mixer 的一次远程访问,而 Out-of-Process Adapter 因为又额外引入了一次远程调用,导致性能更加糟糕:

因此,要彻底解决远程调用引入太多而造成的性能问题,答案很明显:

将 Mixer 的功能内置到 Sidecar 中,使用 In-Process Adapter ,直接连接 Sidecar 和 Infrastructure Backend。
Mixer v2
Mixer 带来的性能问题,以及 Mixer Cache 的失效,导致为了得到一个可用的性能,必须合并 Mixer 到 Sidecar。关于这个论断和行动,蚂蚁金服先行一步,在去年我的演讲 《大规模微服务架构下的Service Mesh探索之路》[1] (演讲时间:2018-06-30)中就介绍了蚂蚁金服的 ServiceMesh 方案,其中和 Istio 最大的变化就是合并 Mixer:

而在 2018 年底,Istio 社区终于提出了 Mixer v2 的 Proposal:Mixer V2 Architecture。
具体内容请见地址[2]:
https://docs.google.com/document/d/1QKmtem5jU2F3Lh5SqLp0IuPb8070J7aJEYu4_gS-s/edit#heading=h.hvvcgepdykro
也可以看我之前对这个内容的 摘要翻译[3]:
https://skyao.io/learning-istio/mixer/design/v2.html
下图是这个 Mixer V2 Architecture 的信息摘要,当前状态为 In Review,创建时间为 2018年12月18,迄今八个月:

Mixer v2 Proposal 的内容比较多,我们忽略各种细节,只看最核心的内容:
Mixer-In-Proxy. Mixer will be rewritten in C++ and directly embedded in Envoy. There will no longer be any stand-alone Mixer service. This will improve performance and reduce operational complexity.Mixer 合并进 Proxy。 Mixer 将用 C++ 重写并直接嵌入到 Envoy。将不再有任何独立的 Mixer 服务。这将提高性能并降低运维复杂性。
Mixer v2 的架构图如下:

| Service Mesh 灵魂拷问二:性能有了,架构怎么办?
Mixer 合并到 Sidecar 之后,性能有了,架构怎么办?这是我们今天的第二个灵魂拷问。
之所以提出这个问题,在于我们前面列出的 Mixer v1 的各种优点,在将 Mixer 简单合并到 Sidecar 之后,这些原来的优点就会摇身一变成为新方式下的缺点,而这是比较难接受的。从这个角度说,Istio 选择 Mixer v1 的架构也不是完全没有理由,只是性能上付出的代价过于高昂无法接受。
Mixer v1 的优点不应该成为 Mixer v2 的缺点。
这是我们对于将 Mixer 合并到 Sidecar 的要求,最起码不要全部优点都成为缺点。
合并没问题,如何合并才是问题!
Envoy 的可扩展设计
Envoy 在设计上是可扩展的,设计有大量的扩展点:
-
L4/L7 filters
-
Access loggers
-
Tracers
-
Health checkers
-
Transport sockets
-
Retry policy
-
Resource monitors
-
Stats sink
而 Envoy 的扩展方式也有三种:
-
C++:直接编码;
-
Lua:目前仅限于 HTTP Traffic;
-
Go extensions:beta, 用于 Cilium;
但是这三种扩展方式对于 Mixer 来说都并不理想,Lua 和 Go extension 不适用于 Mixer,而 C++ 直接编码方式则就会真的让之前的所有优点直接变成缺点。
Envoy 最新尝试的新扩展方式 Web Assembly,则成为我们今天的希望所在:

最近 Envoy 在开始提供 WASM 的支持,具体可以看 Support WebAssembly (WASM) in Envoy[4] 这个 Issue 的描述,目前从 github 的 milestone 中看到 Envoy 计划在1.12版本提供对 WASM 的支持(Envoy 1.11版本发布于7月12日)。
还有一个 envoy-wasm项目[5] ,定位为"Playground for Envoy WASM filter"。
WASM 简单介绍
这里对 Web Assembly 做一个简单介绍,首先看来自 Mozilla 的官方定义:
WebAssembly 是一种新的编码方式,可以在现代的网络浏览器中运行 - 它是一种低级的类汇编语言,具有紧凑的二进制格式,可以接近原生的性能运行,并为诸如 C / C ++ 等语言提供一个编译目标,以便它们可以在 Web 上运行。它也被设计为可以与 JavaScript 共存,允许两者一起工作。
更通俗的理解是:
WebAssembly 不是一门编程语言,而是一份字节码标准。WebAssembly 字节码是一种抹平了不同 CPU 架构的机器码,WebAssembly 字节码不能直接在任何一种 CPU 架构上运行,但由于非常接近机器码,可以非常快的被翻译为对应架构的机器码,因此 WebAssembly 运行速度和机器码接近。(类比 Java bytecode)
备注:摘录自 http://blog.enixjin.net/webassembly-int
而使用 Web Assembly 扩展 Envoy 的好处是:
-
避免修改 Envoy;
-
避免网络远程调用(check & report);
-
通过动态装载(重载)来避免重启 Envoy;
-
隔离性;
-
实时 A/B 测试;
Envoy 的 WASM 支持
Envoy 支持 Web Assembly 的架构和方式如下图所示:
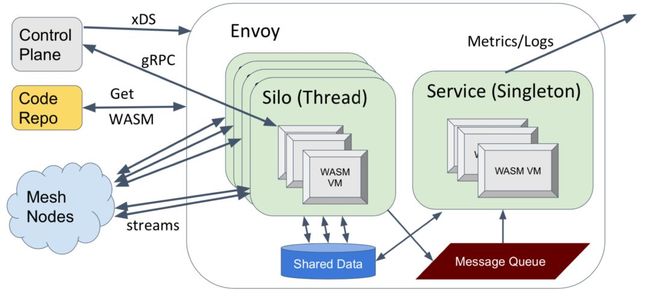
备注:内容来自演讲 “Extending Envoy with WebAssembly”
目前 Envoy 支持的 Web Assembly VM 有:
-
WAVM[6] (https://github.com/WAVM/WAVM)
-
V8[7] (https://v8.dev/)
-
Null Sandbox (use the API, compile directly into Envoy)
Mixer v2 和 WASM
Mixer v2 的终极目标形态应该是这样:
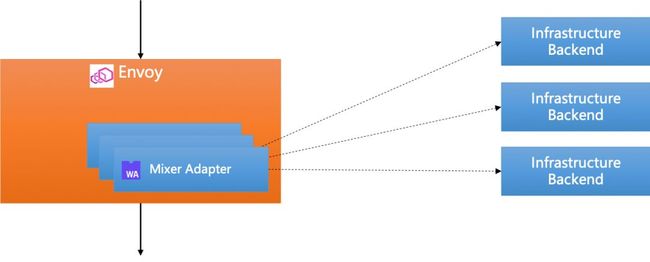
-
Mixer 合并到 Envoy:Adapter 以 In-Proxy Adapter 的形式存在;
-
Envoy 支持 Web Assembly 扩展:各种 Adapter 以高级语言编写,然后编译为 WASM,再被 Envoy 加载(静态/动态均可);
我们欣喜的看到,在 WASM 这样的“黑科技”的加持下,Istio 终于可以在弥补性能缺陷的同时,在系统架构上依然最大限度的维持 Mixer v1 的架构优雅、职责分明和边界清晰。
基于 WASM 扩展的 Mixer v2 真是一个令人兴奋而期待的新颖设计。
而对于 Mixer 的性能问题的解决方案,广大 Istio 社区可谓望穿秋水,从 2017 年初 Istio 开源发布 0.1 版本到今天,两年多时间过去,终于 Mixer v2 开始正视 Mixer 性能问题。但是,Mixer v2 要真正落地,还有非常长的路要走。

要实现如上图所示 Mixer v2 终极目标形态,需要:
-
Envoy 提供对 WASM 的支持;
-
Istio 大规模架构调整,实施 mixer v2;
目前,Envoy 对 Web Assembly 的支持预计有希望在 3-6 个月内实现,具体情况可以通过下面的 Issue[8] 来了解:
https://github.com/envoyproxy/envoy/issues/4272
我们从这个 Issue 中可以大体总结 Envoy 对 WASM 支持的过程:
-
2018年8月28日,Issue 创建,提交对 WASM 支持的想法;
-
2018年10月开始动手,进行 poc;
-
2019年5月 poc 完成,然后创建 envoy-wasm 项目;
-
目前这个 Issue 放在 Envoy 的下一个 milestone1.12 中;
Envoy 最近刚发布了 1.11 版本,根据最近两年中 Envoy 的稳健表现,Envoy 一般三个月发布一个版本,这样预计 1.12 版本会在未来三个月内提供。即使 1.12 版本未能完成,延后到 1.13 版本,也会在六个月内提供。
但是 Istio 方面的进展,则非常不乐观:Mixer v2 从提出到现在 8 个月了,依然是 In Review 状态。

考虑到过去两年间 Istio 团队表现出来的组织能力和执行能力,我个人持悲观态度,我的疑问和担忧是:
-
Istio 能否接受 Mixer v2?
-
如果接受,什么时候开工?
-
如果开工,什么时候完工?
-
如果完工,什么时候稳定?
Mixer v2 虽然前景美好,奈何还需时日,尤其取决于 Istio 的表现:社区的殷切期待和 Istio 的犹豫未决可谓耐人寻味。
最后感叹一声:南望王师又一年,王师还在 Review 间......
| Service Mesh 灵魂拷问三:要不要支持虚拟机?
在聊完性能与架构之后,我们继续今天的第三个灵魂拷问:在有了“高大上”的容器/k8s/云原生,还要不要支持“土里土气”的虚拟机?
Service Mesh 主流产品对虚拟机的支持
首先我们看一下 Service Mesh 主流产品对虚拟机的支持情况:
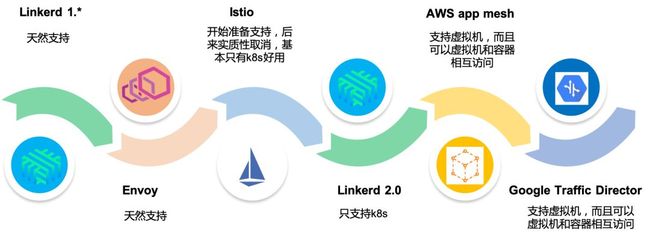
-
Service Mesh 的第一代产品,典型如
Linkered1.*和 Envoy,天然支持虚拟机 -
Service Mesh 的第二代产品,如 Istio,在刚开始发布时还计划提供对非 k8s 的支持,但是后面实质性的取消,基本只有在 k8s 上才好用。
Linkerd2.*更是明确只提供 k8s 的支持。 -
AWS 在 2018 年推出的 app mesh,不仅仅可以支持虚拟机,而且可以支持虚拟机和容器相互访问,稍后 Google 推出了 Traffic Director 产品,也是同样思路。
稍加回顾,就会发现:历史总是惊人的相似,螺旋式上升?波浪式起伏?

Service Mesh 对于虚拟机的态度,从
Linkerd1.* 和 Envoy的支持,到 Istio / Linkerd2.* 的不支持,再到 AWS app mesh 和 Google Traffic Director 的支持,可谓一波三折。未来如果有新形态的 Service Mesh 产品出现,对虚拟机的支持又会是如何?支持还是不支持,我们拭目以待。
虚拟机支持与否的背后
第一个转折容易理解:相比虚拟机,k8s 提供了太多便利。随着容器的普及,k8s 的一统天下,社区对云原生的日益接受,虚拟机模式失宠容易理解。
轻松一下,引用最近的一个梗 “小甜甜 VS 牛夫人”,感觉可以非常形象的描述虚拟机失宠的场面:

第二个转折该如何解释?
AWS App Mesh 提供对虚拟机支持是容易理解的,毕竟 AWS 上目前还是以虚拟机为主,而且 k8s/云原生本来就是 Google 和 AWS 竞争的重要武器,AWS app mesh 提供对虚拟机的支持,并且可以打通就有的虚拟机体现和新的k8s 体系,对AWS意义重大。
但是,作为 k8s 和云原生的主要推动力量, Google 为什么在 Traffic Director 这个产品上没有继续 Istio / Linkerd2 只支持 k8s 的做法,而是效仿 AWS 呢?

原因简单而直白:理想和现实的差距。
-
理想:云原生普及,容器普遍落地,生产上 k8s 广泛使用;
-
现实:虚拟机大量存在,大量公司未能有效掌握 k8s,大部分应用还是运行在虚拟机上;
关于 Service Mesh 形态和云原生未能普及的思考,去年(2018-02-10
)在 DreamMesh抛砖引玉(2)-CloudNative[9] 这篇博客中我有详细描述,当时也和很多社区同学深入讨论。援引当时的一小段总结:
)在 DreamMesh抛砖引玉(2)-CloudNative[9] 这篇博客中我有详细描述,当时也和很多社区同学深入讨论。援引当时的一小段总结:
理想很丰满,现实很骨感。Cloud Native 虽然令人向往,然而现实中,有多少企业是真的做好了 Cloud Native 的准备?
问题:到底该先容器/k8s,再上微服务/Service Mesh;还是先微服务/Service Mesh,再上容器/k8s?每个公司都会有自己的实际情况和选择。
在去年底(2018-11-25),我和同事曾经做过一个名为 "蚂蚁金服 Service Mesh 渐进式迁移方案" 的主题演讲,详细描述了 Service Mesh 和 k8s 落地可能的多种演进路线:

在关于先 Service Mesh,还是先 k8s 的这个问题上,Google Traffic Director 的选择是:支持 Service Mesh 先行。即容许应用在进行容器化改造和 k8s 落地之前,也能够从 ServiceMesh 获益。为此,Google Traffic Director 在标准的 k8s 之外,为基于虚拟机的应用(未做容器化改造)和基于自管理的 docker 容器(有容器但不是 k8s)提供支持:

对此,Traffic Director 官方文档是这样描述的:“按您的节奏进行现代化改造”。
创新:Google Traffic Director 的虚拟机支持
对于如何在虚拟机上提供 Service Mesh 的支持,Google Traffic Director 给出了一个创新的思路。
为了方便管理虚拟机实例,Google Traffic Director 提供了托管式实例组(Managed Instance Group,实际来自 GCP),效仿容器和 k8s 的方式来管理虚拟机:

其中最重要的是提供实例模版(Instance Template)来进行虚拟机的硬件配置/操作系统配置,然后基于实例模版来创建虚拟机实例,并通过自动启动脚本来获取并启动应用,从而实现了从零启动一个运行于虚拟机的应用的全过程自动化。
而实例模版+自动启动脚本配合,可以实现类似容器和 k8s 下的很多类似功能,比如应用版本升级时只需要修改实例模版(和其中的自动启动脚本),类似容器下的修改镜像文件。实例模版提供对实例副本数的管理,包括固定大小和自动伸缩(由此提供类 serverless 的特性)。
类似的,为了方便管理运行于虚拟机上的应用实例,Traffic Director 效仿 k8s/Istio 的方式来管理服务:

Traffic Director 提供了可同时用于 k8s/容器/虚拟机三种模式下的统一的服务抽象,容许在控制台手工创建服务并关联到实例模版(以及实例模版背后的虚拟机实例和运行其上的应用),可以通过托管实例组配置健康检查/灰度发布等高级特性。
Google Traffic Director 在 Service Mesh 虚拟机支持上的创新思路在于:补齐虚拟机的短板,向容器看齐,维持一致的用户体验。如下图所示,在通过托管式实例组向容器/k8s 看齐(当然非常有限)之后,配合统一的 Traffic Director 服务抽象,就可以实现统一管理应用,如配置路由规则。从而实现在最上层为不同 Service Mesh 模式提供一致的用户体验:

通过上述的创新方式,Traffic Director 将 Service Mesh 对虚拟机的支持提升到新的高度。
备注:关于Google Traffic Director 对虚拟机支持的细节,请见我的另一篇博客文档 "Service Mesh先行:Google Traffic Director实践分析"[10]
| Service Mesh 灵魂拷问四:说好的供应商不锁定呢?
在夸赞完 Google 和 Traffic Director 之后,我们进行今天的最后一个灵魂拷问,这个问题的目标直指 Google:
说好的供应商不锁定呢?
供应商不锁定,是 Google 和 CNCF 一直强调和倡导的理念,也是云原生最重要的基石之一。Google 一直用供应商不锁定这块大石头狠狠的砸 AWS 的脑袋,但是,这块石头也是可以用来砸 Google 自己的脚的。
SMI 的意义和最近的社区支持情况
在 Service Mesh 领域,供应商不锁定的典型代表,就是 SMI(Service Mesh Interface)。
备注:关于 Service Mesh Interface 的介绍,我之前的博客文档 Service Mesh Interface详细介绍[11] 有非常详细的描述。
让我们来共同回味 SMI 为整个 Service Mesh 社区带来的美好愿景:
“SMI 是在 Kubernetes 上运行服务网格的规范。它定义了由各种供应商实现的通用标准。这使得最终用户的标准化和服务网格供应商的创新可以两全其美。SMI 实现了灵活性和互操作性。 ”
“SMI API 的目标是提供一组通用的,可移植的 Service Mesh API,Kubernetes 用户可以以供应商无关的方式使用这些 API。通过这种方式,可以定义使用 Service Mesh 技术的应用程序,而无需紧密绑定到任何特定实现。 ”
下图这张图可以让我们更好的理解 SMI 在 Service Mesh 生态中的位置和 SMI 对整个生态的重要:

在 SMI 发布之后,最近 Service Mesh 社区的主要玩家都纷纷开始提供对 SMI 的支持:
-
Linkerd:发布于 2019-07-11的 Linkerd 2.4.0 版本开始支持 SMI;
-
Consul Connect: 发布于 2019-07-09 的 Consul 1.6 版本开始支持 SMI;
Google 在 Service Mesh 标准化上的反常表现
标准化是供应商不锁定的基石,只有实现标准化,才能基于统一的标准打造社区和生态,上层的应用/工具等才有机会在不同的厂商实现之间迁移,从而打造一个有序竞争的积极向上的生态系统。
Service Mesh 问世四年来,在标准化方面做的并不到位,而 Google 在 Service Mesh 标准化上的表现更是反常。具体说,SMI 出来之前:
-
Istio 迟迟未贡献给 CNCF,可以说 Istio 至今依然是 Google(还有 IBM/Lyft)的项目,而不是社区的项目;
-
Istio API 是私有 API,未见有标准化动作;
-
Envoy xDS v2 API 是社区事实标准,但这其实是 Envoy 的功劳;
-
统一数据平面 API(UDPA),感觉更像是 Envoy 在推动,和 Istio 关系不大;
Google 作为 Service Mesh 界的领头羊,在标准化方面表现可谓消极怠工,几乎可以说是无所作为。以至于 SMI 这样的标准,居然是微软出面牵头。而在 SMI 出来之后,除 Istio/AWS 之外几乎所有 Service Mesh 玩家都参与的情况下,依然未见 Istio 有积极回应。
AWS 不加入社区容易理解,毕竟 AWS 自成体系,AWS 本来也就是“供应商不锁定”的革命对象。而 Google 这位“供应商不锁定”运动的发起者,在 Service Mesh 标准化上的反常表现,却是耐人寻味:屠龙的勇士,终将变成恶龙吗?
再次以此图,致敬 AWS和 Google:

下图是目前的 SMI 阵营:汇集几乎所有 Service Mesh 玩家,唯独 AWS 和 Google 缺席:

期待 Google 后续的行动,说好的供应商不锁定,请勿忘此初心。
总结与展望
Service Mesh 出道四年,对于一个新技术,四年时间不算短,到了该好好反思当下和着眼未来的时候了,尤其是目前 Service Mesh 在落地方面表现远不能令人满意的情况下。
正如标题所言:棋到中盘,路往何方?
今天的 Service Mesh 发展趋势探讨,我们以灵魂拷问的方式提出了四个问题。每一个问题和答案,都会深刻影响未来几年 Service Mesh 的走向,请大家在未来一两年间密切关注这些问题背后所代表的 Service Mesh 技术发展走向和产品形态演进:
1. 要架构,还是要性能?关注点在于 Service Mesh 的落地,落地还有落地。性能不是万能的,但是没有性能是万万不能的
2. 性能有了,架构怎么办?关注点在于回归性能之后的架构优化,以创新的方式实现性能与架构的兼得,用新技术来解决老问题
3. 要不要支持虚拟机?关注点依然是落地,对现实的妥协或者说学会接地气,以创新思维来实现用新方法解决老问题
4. 说好的供应商不锁定呢?关注点在于标准化,还有标准化之后的生态共建和生态繁荣。
本次 Service Mesh 发展趋势的续篇到此为止,今年年底前也许还会有 Service Mesh 发展趋势序列的第三篇(名字大概会叫做续2吧),希望届时能看到一些令人眼前一亮的新东西。敬请期待!
回顾资料下载
https://tech.antfin.com/community/activities/781/review/876
文章相关链接集合
[1] 大规模微服务架构下的Service Mesh探索之路:https://www.servicemesher.com/blog/the-way-to-service-mesh-in-ant-financial/
[2] Mixer V2 Architecture:https://docs.google.com/document/d/1QKmtem5jU2F3Lh5SqLp0IuPb8070J7aJEYu4_gS-s/edit#heading=h.hvvcgepdykro
[3] Mixer V2 Architecture 内容摘要翻译:https://skyao.io/learning-istio/mixer/design/v2.html
[4] Support WebAssembly (WASM) in Envoy:https://github.com/envoyproxy/envoy/issues/4272
[5] envoy-wasm 项目:https://github.com/envoyproxy/envoy/issues/4272
[6] WAVM:https://github.com/WAVM/WAVM
[7] V8:
https://v8.dev/
https://v8.dev/
[8] Envoy 对 Web Assembly 的支持详细 Issue:
https://github.com/envoyproxy/envoy/issues/4272
https://github.com/envoyproxy/envoy/issues/4272
[9] DreamMesh抛砖引玉(2)-CloudNative:
https://skyao.io/post/201802-dreammesh-brainstorm-cloudnative/
https://skyao.io/post/201802-dreammesh-brainstorm-cloudnative/
[10] Service Mesh先行:Google Traffic Director 实践分析:
https://skyao.io/post/20190707-google-traffic-director-practice/
https://skyao.io/post/20190707-google-traffic-director-practice/
[11] [Service Mesh Interface 详细介绍]:
https://skyao.io/post/201906-service-mesh-interface-detail/
https://skyao.io/post/201906-service-mesh-interface-detail/
