Hbase高手之路 -- 第七章 -- HBase和Phoenix(全文检索)整合
Hbase高手之路 – 第七章 – HBase和Phoenix(全文检索)整合
一、 apache phoenix简介
1. 简介

Apache Phoenix让Hadoop中支持低延迟OLTP和业务操作分析。
- 提供标准的SQL以及完备的ACID事务支持
- 通过利用HBase作为存储,让NoSQL数据库具备通过有模式的方式读取数据,我们可以使用SQL语句来操作HBase,例如:创建表、以及插入数据、修改数据、删除数据等。
- Phoenix通过协处理器在服务器端执行操作,最小化客户机/服务器数据传输
Apache Phoenix可以很好地与其他的Hadoop组件整合在一起,例如:Spark、Hive、Flume以及MapReduce。
2. olap和oltp
1) olap:在线分析处理系统,hadoop、hbase
2) oltp:在线事务处理系统,传统的关系数据库支持的
sql:结构化查询语言
acid:原子性、一致性、独立性和持久性
3. Phoenix的作用
1) 提供标准的sql和acid事务支持
2) 让NoSQL数据库具备了有模式的方式读取数据,可以使用sql来创建表、插入、修改和删除数据
3) Phoenix通过协处理器在服务器端执行操作,无侵入式
4) 可以很好的与其他hadoop生态组件整合,例如spark、hive、flume、flink以及MR
4. 使用Phoenix是否会影响HBase性能

- Phoenix不会影响HBase性能,反而会提升HBase性能
- Phoenix将SQL查询编译为本机HBase扫描
- 确定scan的key的最佳startKey和endKey
- 编排scan的并行执行
- 将WHERE子句中的谓词推送到服务器端
- 通过协处理器执行聚合查询
- 用于提高非行键列查询性能的二级索引
- 统计数据收集,以改进并行化,并指导优化之间的选择
- 跳过扫描筛选器以优化IN、LIKE和OR查询
- 行键加盐保证分配均匀,负载均衡
5. 哪些公司在使用Phoenix

6. 官方性能测试
1) Phoenix对标Hive(基于HDFS和HBase)

2) Phoenix对标Impala

3) 关于上述官网两张性能测试的说明
上述两张图是从Phoenix官网拿下来的,这容易引起一个歧义。就是:有了HBase + Phoenix,那是不是意味着,我们将来做数仓(OLAP)就可以不用Hadoop + Hive了?
千万不要这么以为,HBase + Phoenix是否适合做OLAP取决于HBase的定位。Phoenix只是在HBase之上构建了SQL查询引擎(注意:我称为SQL查询引擎,并不是像MapReduce、Spark这种大规模数据计算引擎)。HBase的定位是在高性能随机读写,Phoenix可以使用SQL快插查询HBase中的数据,但数据操作底层是必须符合HBase的存储结构,例如:必须要有ROWKEY、必须要有列蔟。因为有这样的一些限制,绝大多数公司不会选择HBase + Phoenix来作为数据仓库的开发。而是用来快速进行海量数据的随机读写。这方面,HBase + Phoenix有很大的优势。
二、 apache phoenix安装
1. 下载

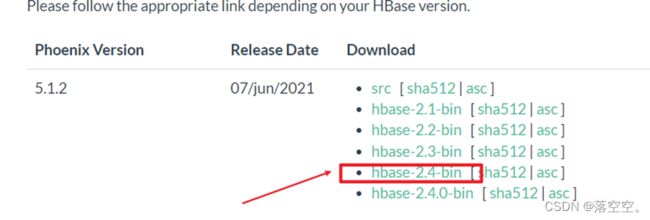

2. 上传到服务器
3. 解压
tar xzvf phoenix-hbase-2.4-5.1.2-bin.tar.gz -C ../servers/

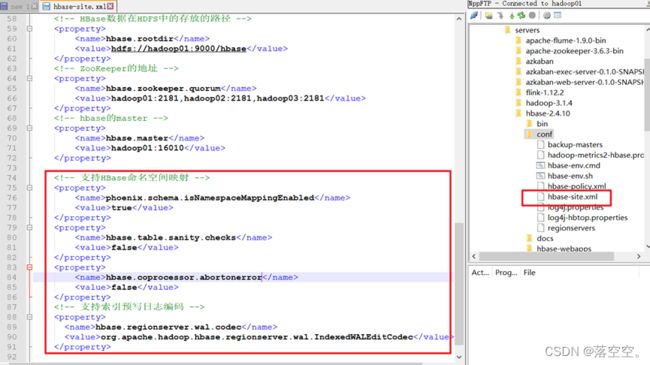
4. 修改hbase的配置文件
<property>
<name>phoenix.schema.isNamespaceMappingEnabledname>
<value>truevalue>
property>
<property>
<name>hbase.table.sanity.checksname>
<value>falsevalue>
property>
<property>
<name>hbase.coprocessor.abortonerrorname>
<value>falsevalue>
property>
<property>
<name>hbase.regionserver.wal.codecname>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodecvalue>
property>
5. 复制依赖包
- 依赖包的位置及介绍

- 复制phoenix的服务端jar包到master的lib文件夹
cp /export/servers/phoenix-hbase-2.4-5.1.2-bin/phoenix-server-hbase-2.4-5.1.2.jar .

- 复制phoenix的服务端jar包到两个worker的hbase的lib文件夹
scp phoenix-server-hbase-2.4-5.1.2.jar hadoop02:/export/servers/hbase-2.4.10/lib/
scp phoenix-server-hbase-2.4-5.1.2.jar hadoop03:/export/servers/hbase-2.4.10/lib/

- 复制phoenix的客户端jar包到phoenix客户端也就是hadoop01的phoenix的bin文件夹下
cp phoenix-client-hbase-2.4-5.1.2.jar bin/

6. 分发hbase的配置文件
scp conf/hbase-site.xml hadoop02:$PWD/conf
scp conf/hbase-site.xml hadoop03:$PWD/conf
7. 将配置好的hbase-site.xml文件复制到phoenix客户端也就是hadoop01的phoenix的bin目录下
cp /export/servers/hbase-2.4.10/conf/hbase-site.xml .

8. 重启hbase
9. 启动phoenix服务端
cd /export/servers/phoenix-hbase-2.4-5.1.2-bin
bin/sqlline.py hadoop01:2181
关闭方法:!quit
查看表

10. 查看hbase的web UI
三、 phoenix的使用
1. 需求
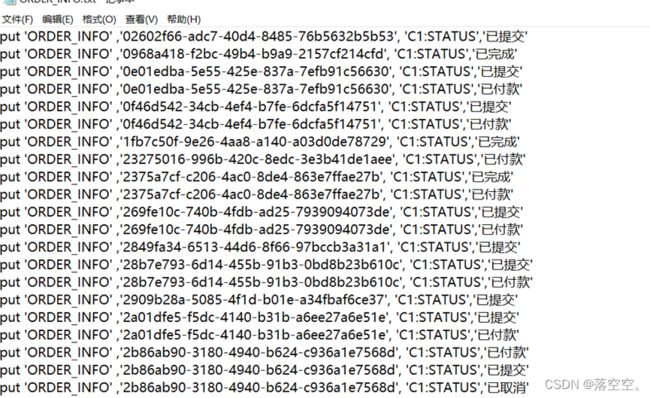
使用之前的订单数据,但是用phoenix来创建表,并进行数据的增删改查操作。
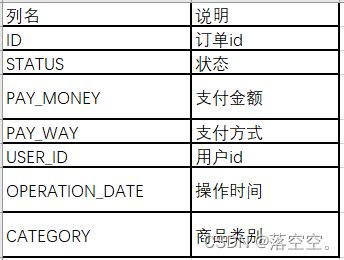
2. 创建表
- 语法:
create table if not exists 表名(
rowkey 名称 类型primary key,
列簇.列名 类型,
……
);
先用VS Code之类的编辑工具,写好创建表的语句
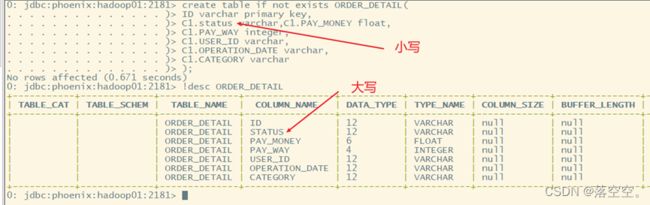
create table if not exists ORDER_DETAIL(
ID varchar primary key,
C1.STATIS varchar,
C1.PAY_MONEY float,
C1.PAY_WAY integer,
C1.USER_ID varchar,
C1.OPERATION_DATE varchar,
C1.CATEGORY varchar
);
再复制到phoenix的客户端运行

进行查看
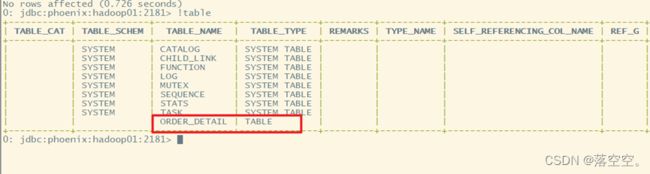
在hbase的web UI界面查看刚创建的表
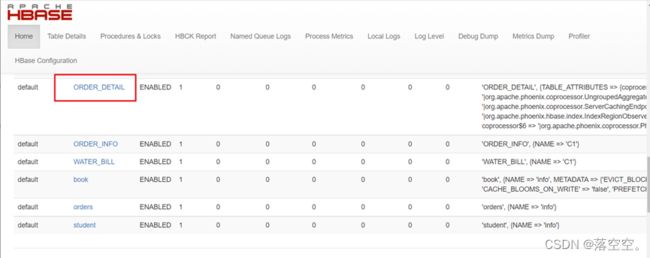
同时也可以看到表默认只有一个分区region,也就是没有分区
3. 查看表
- 语法:
!desc ORDER_DETAIL

4. 删除表
- 语法:
drop table if exists 表名;
drop table if exists ORDER_DETAIL;
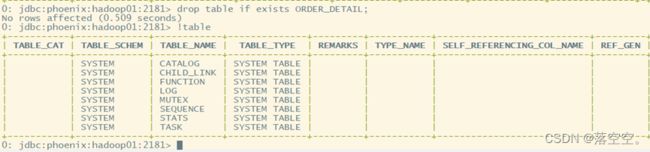
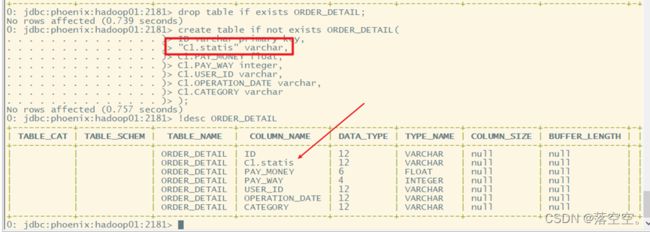
5. 大小写问题
- 如果在使用列簇、列名的时候没有添加双引号,Phoenix会自动转换为大写
- 如果要将列名改为小写,则要用双引号括起来,
注意:如果一旦加了小写,后面任何使用该列的地方都需要使用双引号,否则会报错
6. 插入数据
在phoenix中,插入数据并不是insert,而是upsert,相当于insert+update,与hbase shell中的put相对应。如果不存在则插入,否则更新
- 语法:
upsert into ORDER_DETAIL1(列簇名.列名,……) values (值1,值2,……);
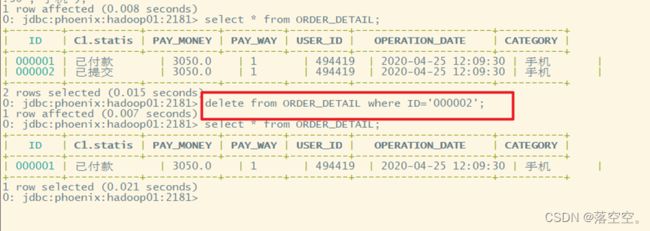
upsert into ORDER_DETAIL1 values ('000001','已提交',3050,1,'494419','2020-04-25 12:09:30','手机');

7. 查询数据
与标准的sql一样,phoenix也是用select实现数据的查询
- 语法:
select * from 表名;
select * from ORDER_DETAIL;

8. 更新数据
在phoenix中,更新数据也是用upsert
- 语法:
upsert into 表名(列名,列簇名.列名,……) values(值1,值2,……);
upsert into ORDER_DETAIL(ID,C1.STATUS) values ('000001','已付款');

9. 删除数据
在phoenix中,删除数据与标准的sql一样,也是用delete from实现数据的删除
- 语法:
delete from 表名 where rowkey列名=值;
delete from ORDER_DETAIL where ID='000002';
四、 HBase的命名空间
1. 简介
- 在一个项目中,需要使用HBase保存多张表,这些表会按照业务域来划分
- 为了方便管理,不同的业务域以名称空间(namespace)来划分,这样管理起来会更加容易
- 类似于Hive中的数据库,不同的数据库下可以放不同类型的表
- HBase默认的名称空间是「default」,默认情况下,创建表时表都将创建在 default 名称空间下
- HBase中还有一个命名空间「hbase」,用于存放系统的内建表(namespace、meta)

2. 创建命名空间
语法:
create_namespace 命名空间名

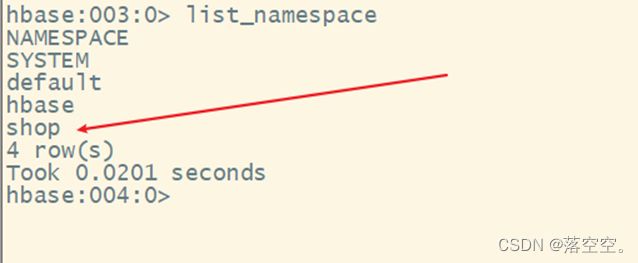
3. 查看命名空间列表
语法:
list_namespace
4. 查看命名空间
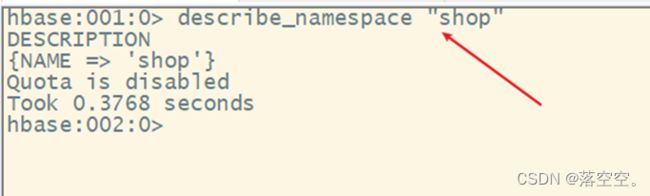
describe_namespace 命名空间名
5. 删除命名空间
语法:
drop_namespace 命名空间名

注意:
删除命名空间时,在该命名空间下必须没有表,否则无法删除
6. 在指定命名空间下创建表
语法:
create "命名空间名:表名","列簇名"
create "shop:goods","C1"

注意:
使用带有命名空间的表,使用冒号将命名空间和表名连接在一起
7. 添加数据到命名空间表
语法:
put "命名空间名:表名","rowkey","列簇:列名",值
put "shop:goods","000001","C1:price",5800
![]()

五、 列簇设计
- HBase列蔟的数量应该越少越好
- 两个及以上的列蔟HBase性能并不是很好
- 一个列蔟所存储的数据达到flush的阈值时,表中所有列蔟将同时进行flush操作
- 这将带来不必要的I/O开销,列蔟越多,对性能影响越大
- 一般情况下,只设计一个列簇
六、 版本设计
版本数一般设计为1
一般情况下,如果对数据不做修改,只保留一个版本,可以节省大量的存储空间

- 此处,我们需要保存的历史聊天记录是不会更新的,一旦数据保存到HBase中,就不会再更新
- 无需考虑版本问题
- 本次项目中只保留一个版本即可,这样可以节省大量空间
- HBase默认创建表的版本为1,故此处保持默认即可
七、 数据压缩
1. 压缩算法
hbase默认创建的表是不进行数据压缩的,进行数据压缩可以节省大量的存储空间,hbase可以使用多种数据压缩编码,包括LZO、SNAPPY、GZIP。
在HBase可以使用多种压缩编码,包括LZO、SNAPPY、GZIP。只在硬盘压缩,内存中或者网络传输中没有压缩。
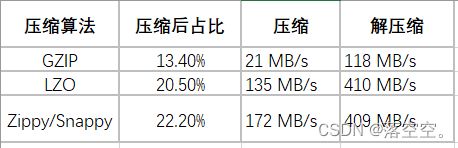
- GZIP的压缩率最高,但是其实CPU密集型的,对CPU的消耗比其他算法要多,压缩和解压速度也慢;
- LZO的压缩率居中,比GZIP要低一些,但是压缩和解压速度明显要比GZIP快很多,其中解压速度快的更多;
- Zippy/Snappy的压缩率最低,而压缩和解压速度要稍微比LZO要快一些
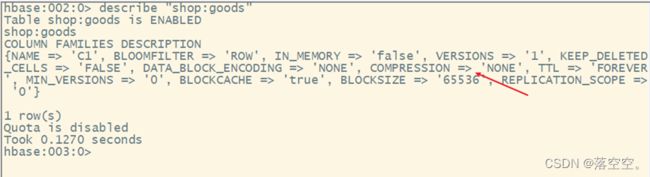
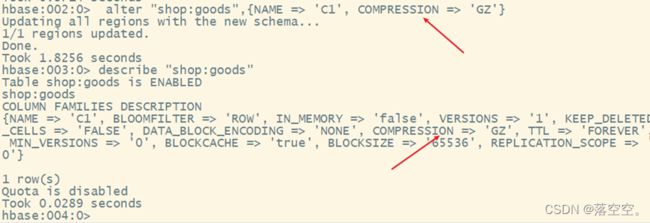
2. 查看表的压缩方式
hbase创建的表默认是没有数据压缩的
3. 设置数据压缩
1) 创建新表的时候
语法:
create "命名空间名:表名",{NAME => '列簇名', COMPRESSION => '压缩算法名'}
示例:
create "shop:orders",{NAME => 'C1', COMPRESSION => 'GZ'}
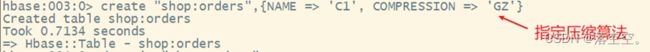

2) 修改已有的表
语法:
alter "命名空间名:表名",{NAME => '列簇名', COMPRESSION => '压缩算法名'}
示例
alter "shop:goods",{NAME => 'C1', COMPRESSION => 'GZ'}
八、 ROWKEY设计原则
1. 避免使用递增行键/时序的数据
如果ROWKEY设计的都是按照顺序递增(例如:时间戳),这样会有很多的数据写入时,负载都在一台机器上。我们尽量应当将写入大压力均衡到各个RegionServer
2. 避免rowkey和列的长度过大
- 在HBase中,要访问一个Cell(单元格),需要有ROWKEY、列蔟、列名,如果ROWKEY、列名太大,就会占用较大内存空间。所以ROWKEY和列的长度应该尽量短小
- ROWKEY的最大长度是64KB,建议越短越好
3. 使用long等类型比String类型更节省空间
long类型为8个字节,8个字节可以保存非常大的无符号整数,例如:18446744073709551615。如果是字符串,是按照一个字节一个字符方式保存,需要快3倍的字节数存储。
4. rowkey唯一性
- 设计rowkey时,必须保证它的唯一性。
- 如果不唯一,因为hbase采用key-value的存储方式,若向hbase的一张表中插入相同rowkey的数据,则原来的数据会被新的数据覆盖
5. 避免数据热点
1) 热点
- 热点是指大量的客户端(client)直接访问集群的一个或者几个节点(可能是读、也可能是写)
- 大量地访问量可能会使得某个服务器节点超出承受能力,导致整个RegionServer的性能下降,其他的Region也会受影响
2) 预分区
默认情况下,一个hbase表只有一个分区(region),被托管在一个RegionServer中

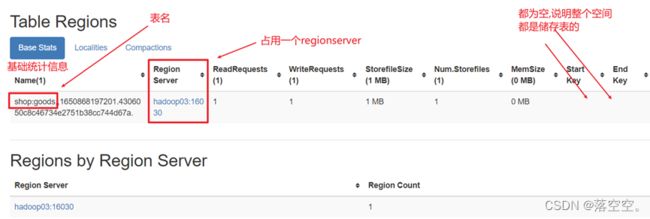
3) start key和end key
每个region有两个重要的属性:start key和end key,标识这个region维护的rowkey的范围。如果只有一个region,这它们都为空,没有边界。所有的数据都会存放在这个region中。但数据很大的时候,会将region通过去一个mid key来分成两个region。
4) 预分区的个数
预分区的个数=节点的倍数,如果有三个节点,则预分区的个数为6。
默认region的大小为10G,假如进行预估接下来的一年时间数据的大小为10T,则需要的预分区数=10*1000G/10G=1000个region。
5) ROWKEY避免热点设计
1. 反转策略
- 如果设计出的ROWKEY在数据分布上不均匀,但ROWKEY尾部的数据却呈现出了良好的随机性,可以考虑将ROWKEY的翻转,或者直接将尾部的bytes提前到ROWKEY的开头。
- 反转策略可以使ROWKEY随机分布,但是牺牲了ROWKEY的有序性
- 缺点:利于Get操作,但不利于Scan操作,因为数据在原ROWKEY上的自然顺序已经被打乱
2. 加盐策略
- Salting(加盐)的原理是在原ROWKEY的前面添加固定长度的随机数,也就是给ROWKEY分配一个随机前缀使它和之间的ROWKEY的开头不同
- 随机数能保障数据在所有Regions间的负载均衡
- 缺点:因为添加的是随机数,基于原ROWKEY查询时无法知道随机数是什么,那样在查询的时候就需要去各个可能的Regions中查找,加盐对比读取是无力的
3. 哈希策略
- 基于 ROWKEY的完整或部分数据进行 Hash,而后将Hashing后的值完整替换或部分替换原ROWKEY的前缀部分
- 这里说的 hash 包含 MD5、sha1、sha256 或 sha512 等算法
- 缺点:Hashing 也不利于 Scan,因为打乱了原RowKey的自然顺序
九、 设置预分区
1. 指定start key和end key来分区
1) 创建预分区
语法:
create "test:t1",'C1',SPLITS=>['10','20','30','40']

2) hbase的web ui查看分区的占用情况
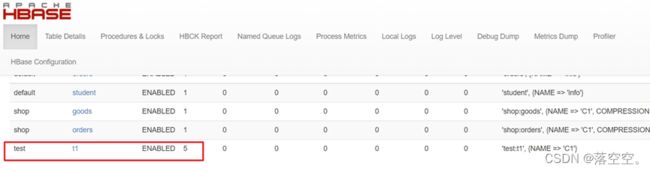
点击t1表,查看详情


2. 指定分区的数量、分区策略
1) 创建预分区
create "test:t2","C1",{NUMREGIONS=>6,SPLITALGO=>'HexStringSplit'}

2) hbase的web ui查看分区的占用情况
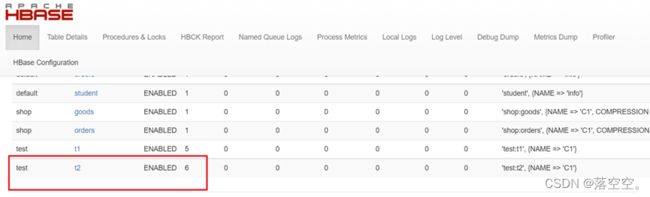
点击t2查看详情
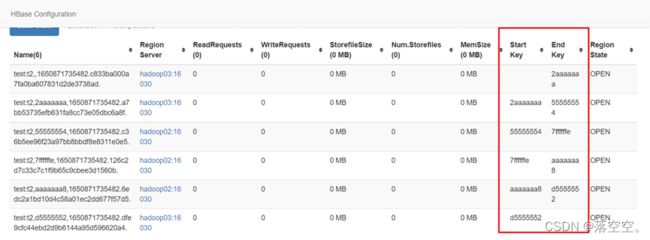
3) 分区数量
一般按照数据量来预估或者根据节点数的倍数来设定
4) 分区策略
- HexStringSplit:rowkey是采用十六进制字符串作为前缀
- DecimalStringSplit:rowkey采用十进制数字字符串作为前缀
- UniformStringSplit:rowkey的前缀是随机的
十、 Phoenix的视图
Phoenix的视图就是对已经创建的HBase表建立映射关系,从而实现对已有表的快速查询
1. 创建视图
语法:
create view if not exists "命名空间名"."表名" (
"Rowkey名" 类型r primary key,
"列簇"."列名" 类型,
"列簇"."列名" 类型
……
);
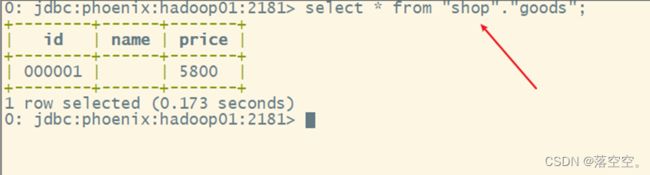
create view if not exists "shop"."goods" (
"id" varchar primary key,
"C1"."name" varchar,
"C1"."price" varchar
);

2. 查询数据
select * from "命名空间名"."表名" where 条件;
十一、 二级索引
一般情况下,Hbase会根据rowkey建立索引,来提供查询的速度,这样的索引叫做一级索引。如果根据name进行查询,因为没有根据name建立索引,所以查询效率比较低,这是可以给name来创建二级索引。
1. 索引分类
- 全局索引
- 本地索引
- 覆盖索引
- 函数索引
1) 全局索引
- 全局索引适用于读多写少业务
- 全局索引绝大多数负载都发生在写入时,当构建了全局索引时,Phoenix会拦截写入(DELETE、UPSERT值和UPSERT SELECT)上的数据表更新,构建索引更新,同时更新所有相关的索引表,开销较大
- 读取时,Phoenix将选择最快能够查询出数据的索引表。默认情况下,除非使用Hint,如果SELECT查询中引用了其他非索引列,该索引是不会生效的
- 全局索引一般和覆盖索引搭配使用,读的效率很高,但写入效率会受影响
语法:
create index 索引名称 on 表名(列名1,列名2……);
举例:
create index idxname on ORDER_DETAIL(CATEGORY);

注意:
Phoenix中的索引,其实底层还是Hbase的表结构,这些索引表是专门用来加快查询速度。

2) 本地索引
- 本地索引适合写操作频繁,读相对少的业务
- 当使用SQL查询数据时,Phoenix会自动选择是否使用本地索引查询数据
- 在本地索引中,索引数据和业务表数据存储在同一个服务器上,避免写入期间的其他网络开销
- 在Phoenix 4.8.0之前,本地索引保存在一个单独的表中,在Phoenix 4.8.1中,本地索引的数据是保存在一个影子列蔟中
- 本地索引查询即使SELECT引用了非索引中的字段,也会自动应用索引的
注意:创建表的时候指定了SALT_BUCKETS,是不支持本地索引的。

创建语法:
CREATE local INDEX 索引名称 ON 表名 (列名1, 列名2, 列名3...)
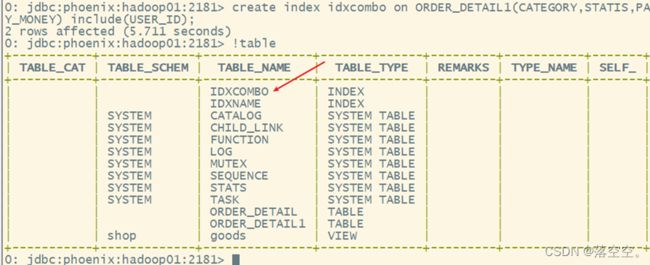
3) 覆盖索引
可以不需要在找到索引条目后返回到主表中,可以将关心的数据捆绑在索引行中,从而节省了读取的时间开销。
创建语法:
create index 索引名称 on 表名(列名1,列名2……) include(列名3);
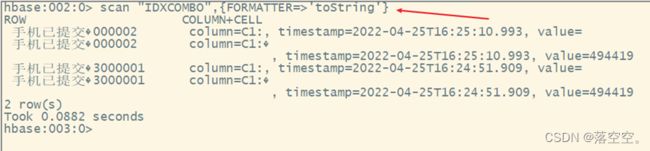
create index idxcombo on ORDER_DETAIL1(CATEGORY,STATIS,PAY_MONEY) include(USER_ID);
scan "IDXCOMBO",{FORMATTER=>'toString'}
4) 函数索引
适用于高版本的phoenix,可以基于任意表达式(函数)创建索引
语法
create index 索引名称 on 表名(函数名(列名1),列名2……);
2. 创建索引
create index idxsuerid on ORDER_DETAIL1(C1.USER_ID) include(ID,C1.PAY_MONEY);

3. 根据索引查询数据
select USER_ID,ID,PAY_MONEY from ORDER_DETAIL1 where USER_ID="494419";
![]()
4. 删除索引
drop index 索引名 on 表名
drop index IDXCOMBO on ORDER_DETAIL1;
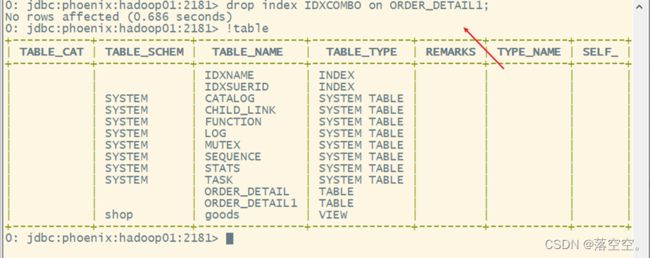
5. 查看索引
