深度学习通俗简述
特征表示学习
简述:
特征表示学习是一套给机器灌入原始数据,然后能自动发现需要进行检测和分类的表达的方法
。
传统机器学习算法:
传统的机器学习算法,需要人为设计特征。比如要用线性回归预测一所房子的价格,我们会人为划分出面积、地段等要素,这些要素就是我们人为划分出来的特征。
但是,人为划分出来的特征往往是是不足够的,而且很多时候并不准确。比如我们划分除了面积和地段,却遗漏了房屋年限这一也很重要的要素,即使我们经过精确的统计和计算划分出了上百个特征,也依然存在遗漏或不准确的可能。
深度学习算法:
深度学习就是一种特征学习方法,把原始数据通过一些简单的但是非线性的模型转变成为更高层次的,更加抽象的表达。通过足够多的转换的组合,非常复杂的函数也可以被学习。
打个比方,以下图为例。
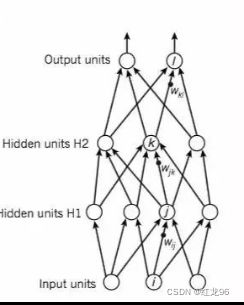
这是深度学习中全连接层的模型图。
Hidden units中的每一个神经元都可以看作划分出来的某一个特征,比如一号神经元可以看作地段,二号神经元可以看作年限,在用深度框架实现简单线性回归的过程中,往往也就是调用一个全连接层。但实际上在深度学习中,每一个神经元代表着什么,我们并不知道,它里面完全是一个黑匣子,具体的计算含义只有它自己知道,或者它自己也不知道。
在金庸的武侠小说里有这样一句话,叫“无招胜有招”。传统机器学习算法人为划分特征,追求剑招上的极致,但深度学习反其道而行之,直接放弃所有招数,把一切交给神经网络本身,做到以无招胜有招。
传统与深度:
虽然金庸在小说里提出了“无招胜有招”的概念,但是也有着条件,要么像令狐冲那样学会独孤九剑这样的精妙心法,要么像张无忌那样拥有着强大的内力。深度学习在上个世纪六十年代便出现了,但是在10年代却才大幅度火热起来,主要的原因在于以下三点:
①大数据时代出现了大量数据。
②计算机性能越来越强大。
③各种强大算法的相继出现。
经典深度学习网络
经典的神经网络就是我们所称的全连接层,深度学习是一个通过数据训练神经网络的过程。
大体的步骤有两个,分别是前向传播和反向传播。前向传播通过一系列好几层的计算得到我们想要的结果,比如计算得出房子的价格;反向传播把错误返回给网络,告诉网络要改正错误。
前向传播

前向传播大概的步骤是:
输入层→计算得出y(与神经元里的权重相乘求和)→激活函数(通过某些非线性的函数得到另一个值)→输出结果。
这里的隐层可以有好几层,不过具体步骤是一样的。
要加上个激活函数,大概的原因是,只靠线性函数不行,得不到那么好的效果,所以要加一点非线性的变换。
通过这样一系列的过程,深度学习可以做到从复杂的数据中逐步提取出数据的各项特征,并且一般每过一层提取的特征便越详细一些。每一个模块能够做到对我们需要的特征十分敏感,对不需要的特征忽略。在有大量数据的基础下,处理一些复杂任务时效果要胜过传统机器学习算法。
反向传播
深度学习也是机器学习的一种,和传统机器学习一样,一开始的权重都是随机初始化的,所以需要经过训练慢慢修改权重值。
所以数据通过前向传播一开始得出的值肯定时漏洞百出,误差极大。反向传播就是神经网络的反省机制,帮助神经网络修改神经元里的权重参数。
要做到反向传播,要准备一个目标函数(损失函数),还有训练网络的方法。
目标函数就是计算出损失的函数,所以也叫损失函数。常用的计算损失的方法有最小二乘法。训练神经网络的目标,就是要让目标函数的值降到最小,毕竟它算出的损失,肯定是损失越小越好。我们无法了解深度学习的网络内部具体怎么运作,正是通过目标函数告诉它我们需要一个什么样的结果。
我们经过计算得到的误差,要通过求偏导的方式往回传递。
训练网络的方式,基本都是属于梯度下降的一系列方法。
通过来自微积分的知识,我们可以知道,一个多元函数的梯度方向就是这个函数增加最快的方向,反之,梯度的反方向自然就是减小最快的方向。
一般运用的梯度下降的方法有三种,它们分别是:
①BGD(Batch Gradient Descent,批量梯度下降)
②MBGD(Mini-Batch Gradient Descent )
③SGD(stochastic,随机梯度下降)
它们之间的差别大概就是:BGD是计算出了每一个数据的误差,然后求总和求平均,然后更新,这样大方向是朝着全局最优,但算的实在太慢;SGD是算出了一个数据的误差就求梯度然后更新,这样算的快,但相对没那么准确,算出来的结果不一定是全局最优,但大多时候我们也可以接受;MBGD是一批一批的测,假如一共五百个数据,先用十个来测,下一次再用十个来测。
在深度学习中,MBGD用的会多一些。
由此可以得出反向传播的大概过程:
通过目标函数得出误差→求偏导找到梯度→利用梯度进行参数更新。
在不同的网络结构中,会有不同的目标函数和不同的公式进行参数更新。
卷积神经网络
卷积神经网络就是在经典神经网络的基础上,在输入层和全连接层加入了卷积层和池化层。一般用于处理多维数组数据。
卷积层是用来一层层提取特征的,池化层是来压缩或者说扔掉特征的(论文里的说法是融合特征,但总的还是让特征图变小)。
就拿人来说,我们与他人相处时往往都不会知道对方的全部信息,但只要记住几个关键的特征,比如这个人长得高还是矮,头发长还是短,脸上有没有麻子,只要掌握了这些关键的特征,就能够识别出一个人。

卷积层
卷积层就是设计一个卷积核(一个与输入数据有相同深度的矩阵),在多维数据数据上像图上那样一步步一定,然后对应数据相乘累加得到一个值,这个得到的值是新得出的矩阵也就是特征图中的其中一个值。新的到的特征图里的每一个值都是原先输入图片里某一个区域里提取出来的特征。
这个新的出的值,是从原先多维数组数据里好几个值里得出的,卷积层就是这样子进行特征的提取浓缩。每经过一层特征就提取的多一些也更详细一些。
假设输入的数据是一张彩色图片(三维矩阵),那么使用的卷积核必须得也是一个三维矩阵,并且深度(长宽以外的另外一个维度的大小)必须和输入图相同。
不管输入的图片深度大小是多少,经过一个卷积核的特征提取后,得到的特征图都是平的,也就是深度只有1的。但如果一个卷积核走过一遍后再来一个卷积核再走一遍,那么就会又得到一个新的平的特征图,它们堆一起,就变成一个三维矩阵了。
也就是说,有几个卷积核就会得到几个新的特征图,就会得到深度多大的三维矩阵。
每一个卷积核提取的都是不同的特征,我们要识别一张图上的物体是不是猫,一号卷积核提取的可能是胡须的特征,二号卷积提取的可能是眼睛的特征。
池化层
池化层也可以理解成缩水层,本来大小是52x52的图,经过池化后便会变成26x26大小。
池化的方式一般有两种:最大池化和平均池化。
最大池化就是在每四个值里挑出最大的那个,其他的都扔了;平均池化都是把四个都扔了,留下这四个值的平均值。
关于为什么要扔掉一些特征,大概的原因就是特征多了,计算也慢了,效率也低了,然后就是正如前面所说,要挑出的是重要的特征,因此可以晒掉一些相对不那么重要的特征。
递归神经网络
卷积神经网络主要处理多维数组的数据,递归神经网络主要处理序列输入的任务,所以递归神经网络常常用于处理自然语言处理方面的问题。像语音和语言,利用RNNs能获得更好的效果。

该图的大概讲了讲递归神经网络是怎么干事的,就是会把前一轮传进来的数据传给这一轮传进来的。因为像文字这样的序列数据,前后往往是有关联的。
但是,如果把以前的数据都完全保留下来的话,对于计算显然是一个负担,因此需要适当筛掉一些数据,就像卷积神经网络里池化层存在的理由类似。
我们如果要通过输入的一段文字来预测接下来的文字,肯定是离要预测的文字越近的文字和这段文字的关联越大。就拿一篇百万字长篇小说来说,排除作者刻意前后对称,第一句话和最后一句话肯定是关联最小的,那么在预测最后一句话时就没必要留下第一句话的数据。
这时候得提一提LSTM网络。
相比一般的递归神经网络,LSTM网络通俗地来说就是加入了一个权重参数,来决定要遗忘哪些信息。