Sharding-JDBC 分库分表
文章目录
- 一、分库分表策略
- 二、Sharding-JDBC
-
- 2.1 添加依赖
- 2.2 分库策略
-
- 2.2.1 数据库环境
- 2.2.2 yml 配置数据源
- 2.2.3 yml 配置分片算法
- 2.2.4 查看分库效果
- 2.3 分表策略
-
- 2.3.1 数据库环境
- 2.3.2 yml 配置分表策略
- 2.3.3 查看分表效果
- 2.4 分布式序列算法
-
- 2.4.1 UUID
- 2.4.2 雪花算法(Snowflake)
- 2.4.3 ShardingJDBC 实现
- 2.4.4 查看效果
- 2.5 读写分离
-
- 2.5.1 数据库主从结构
- 2.5.2 yml 配置数据源
- 2.5.3 yml 配置读写分离
- 2.5.4 查看读写分离效果
提示:以下是本篇文章正文内容,Java 系列学习将会持续更新
一、分库分表策略
在大型的互联网系统中,可能单台 MySQL 的存储容量无法满足业务的需求,这时候就需要进行扩容了。
和之前的问题一样,单台主机的硬件资源是存在瓶颈的,不可能无限制地纵向扩展,这时我们就得通过多台实例来进行容量的横向扩容,我们可以将数据分散存储,让多台主机共同来保存数据。
那么问题来了,怎么个分散法?
- 垂直拆分:我们的表和数据库都可以进行垂直拆分,所谓垂直拆分,就是将数据库中所有的表,按照业务功能拆分到各个数据库中(是不是感觉跟前面两章的学习的架构对应起来了)而对于一张表,也可以通过外键之类的机制,将其拆分为多个表。

- 水平拆分:水平拆分针对的不是表,而是数据,我们可以让很多个具有相同表的数据库存放一部分数据,相当于是将数据分散存储在各个节点上。

那么要实现这样的拆分操作,我们自行去编写代码工作量肯定是比较大的,因此目前实际上已经有一些解决方案了,比如我们可以使用 MyCat(也是一个数据库中间件,相当于挂了一层代理,再通过 MyCat 进行分库分表操作数据库,只需要连接就能使用)。类似的还有 ShardingSphere-Proxy 或是Sharding JDBC(应用程序中直接对 SQL 语句进行分析,然后转换成分库分表操作,需要我们自己编写一些逻辑代码)。
回到目录…
二、Sharding-JDBC
官方文档:https://shardingsphere.apache.org/document/5.1.0/cn/overview/#shardingsphere-jdbc

Sharding-JDBC 是一套开源的分布式数据库中间件解决方案,定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务,它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
2.1 添加依赖
这里我们主要演示一下水平分表方式,我们直接创建一个新的 SpringBoot 项目即可,依赖如下:
<dependencies>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starterartifactId>
<version>5.1.0version>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.2.2version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
dependencies>
回到目录…
2.2 分库策略
2.2.1 数据库环境
①我们使用 Docker 开启两个 MySQL 容器,代表我们的两个数据库:
![]()
②分别给两个数据库创建可外网访问的用户
CREATE USER 'wsy'@'%' IDENTIFIED BY '123456';
grant all on *.* to 'wsy'@'%';
flush privileges;
③再给两个数据库创建相同的库表结构:
create database yyds;
CREATE TABLE test (
id int not null primary key,
name varchar(30),
passwd varchar(30)
);
回到目录…
2.2.2 yml 配置数据源
我们是一个分库分表的状态,需要配置两个数据源:
spring:
shardingsphere:
datasource:
# 有几个数据就配几个,这里是名称,按照下面的格式,名称+数字的形式
names: db0,db1
# 为每个数据源单独进行配置
db0:
# 数据源实现类,这里使用默认的HikariDataSource
type: com.zaxxer.hikari.HikariDataSource
# 数据库驱动
driver-class-name: com.mysql.jdbc.Driver
# 不用我多说了吧
jdbc-url: jdbc:mysql://1.15.76.95:3307/yyds
username: wsy
password: 123456
db1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://1.15.76.95:3308/yyds
username: wsy
password: 123456
启动主类,可以通过观察日志,发现连接成功:
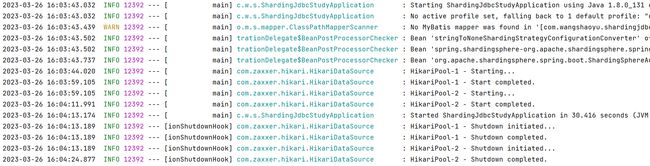
回到目录…
2.2.3 yml 配置分片算法
ShardingSphere 内置了很多分片算法,可以查询官网:shardingsphere-jdbc 分片算法。
现在我们就来编写配置文件,我们需要告诉 ShardingJDBC 要如何进行分片,首先明确:现在是两个数据库都有 test 表存放用户数据,我们目标是将用户信息分别存放到这两个数据库的表中。
spring:
shardingsphere:
rules:
sharding:
tables:
#这里填写表名称,程序中对这张表的所有操作,都会采用下面的路由方案
#比如我们上面Mybatis就是对test表进行操作,所以会走下面的路由方案
test:
#这里填写实际的路由节点,比如现在我们要分两个库,那么就可以把两个库、以及对应的表写上
#也可以使用表达式简写为 db$->{0..1}.test
actual-data-nodes: db0.test,db1.test
#这里是分库策略配置
database-strategy:
#这里选择标准策略,也可以配置复杂策略,基于多个键进行分片
standard:
#参与分片运算的字段,下面的算法会根据这里提供的字段进行运算
sharding-column: id
#这里填写我们下面自定义的算法名称
sharding-algorithm-name: my-alg
sharding-algorithms:
#自定义一个新的算法,名称随意
my-alg:
#算法类型,官方内置了很多种,这里演示最简单的一种
type: MOD
props:
sharding-count: 2
props:
#开启日志,一会方便我们观察
sql-show: true
这里我们使用的是 MOD,也就是取模分片算法。
它会根据主键的值进行取模运算,比如我们插入的 id=2,那么就表示对主键进行模2运算,根据数据源的名称,比如 db0 就是取模后为 0,db1 就是取模后为 1。也就是说,最终实现的效果就是单数放在db1,双数放在db0,当然它还支持一些其他的算法,这里就不多介绍了。
回到目录…
2.2.4 查看分库效果
我们需要对项目进行一些编写,添加我们的用户实体类和 Mapper:
@Data
@AllArgsConstructor
public class User {
int id;
String name;
String passwd;
}
@Mapper
public interface UserMapper {
@Select("select * from test where id = #{id}")
User getUserById(int id);
@Insert("insert into test(id, name, passwd) values(#{id}, #{name}, #{passwd})")
int addUser(User user);
}
① 那么现在我们编写一个测试用例来看看,是否能够按照我们上面的规则进行路由:
@SpringBootTest
class ShardingJdbcStudyApplicationTests {
@Resource
private UserMapper userMapper;
@Test
void contextLoads() {
for (int i = 1; i <= 10; i++) {
// 像数据库插入 1~10 用户
userMapper.addUser(new User(i, "xx-" + i, "123456"));
}
}
}
观察控制台日志,发现是交替插入两个数据库:

查看两个数据库:

② 当我们测试查询用户时,
@Test
void contextLoads2() {
for (int i = 1; i <= 10; i++) {
User user = userMapper.getUserById(i);
}
}
发现它也是轮询去两个数据库查询的。

这样我们就很轻松地实现了分库策略。
回到目录…
2.3 分表策略
接着我们来看分表,比如现在我们的数据库中有 test_0 和 test_1 两张表,表结构一样,但是我们也是希望能够根据 id 取模运算的结果分别放到这两个不同的表中,实现思路其实是差不多的。
这里首先需要介绍一下两种表概念:
- 逻辑表:相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为
t_order。 - 真实表:在水平拆分的数据库中真实存在的物理表。 即上个示例中的
t_order_0到t_order_9这十张表。
2.3.1 数据库环境
现在我们就以一号数据库为例,那么我们在里面创建上面提到的两张表,之前的那个 test 表删不删都可以,就当做不存在就行了:
create table test_0 (
`id` int primary key,
`name` varchar(255) NULL,
`passwd` varchar(255) NULL
);
create table test_1 (
`id` int primary key,
`name` varchar(255) NULL,
`passwd` varchar(255) NULL
);

回到目录…
2.3.2 yml 配置分表策略
接着我们不要去修改任何的业务代码,Mybatis 里面写的是什么依然保持原样,即使我们的表名已经变了,我们需要做的是通过路由来修改原有的 SQL,配置如下:
spring:
shardingsphere:
rules:
sharding:
tables:
#这里填写表名称,程序中对这张表的所有操作,都会采用下面的路由方案
#比如我们上面Mybatis就是对test表进行操作,所以会走下面的路由方案
test:
#这里填写实际的路由节点,比如现在我们要分到db0库的两张表上
#也可以分开写为 db0.test_0,db0.test_1
actual-data-nodes: db0.test_$->{0..1}
#现在我们来配置一下分表策略,注意这里是 table-strategy,分库是用 database-strategy
table-strategy:
#基本都跟之前是一样的
standard:
sharding-column: id
sharding-algorithm-name: my-alg
sharding-algorithms:
my-alg:
#选择算法类型,INLINE支持我们自行编写表达式
type: INLINE
props:
#比如我们还是希望进行模2计算得到数据该去的表
#只需要给一个最终的表名称就行了test_,后面的数字是表达式取模算出的
#实际上这样写和MOD模式一模一样
algorithm-expression: test_$->{id % 2}
#查询也会根据分片策略来进行。如果我们进行范围查询,实际上依然会进行全量查询
#INLINE算法默认是不支持进行全量查询的,所以我们应该设为 true
allow-range-query-with-inline-sharding: true
props:
#开启日志,一会方便我们观察
sql-show: true
分片算法有很多内置的,可以在这里查询官网:shardingsphere-jdbc 分片算法。
回到目录…
2.3.3 查看分表效果
① 我们来测试一下,看看会不会按照我们的策略进行分表插入:


② 再来看看查询,也会根据我们配置的策略,选择对应的表进行:
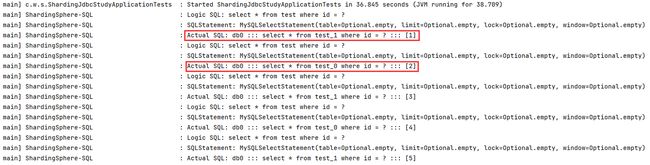
③ 当我们进行范围查询时,又是怎样的?
注意:INLINE 算法默认是不支持进行全量查询的,我们得手动允许
allow-range-query-with-inline-sharding: true
否则,会有以下报错:

我们现在向 Mapper 中添加一条 SQL 接口:
@Select("select * from test where id between #{start} and #{end}")
List<User> getUsersByIdRange(int start, int end);
我们来测试一下:
@Test
void contextLoads3() {
List<User> list = userMapper.getUsersByIdRange(3, 8);
}
我们可以发现,内部真正执行的 SQL 是分别查询了两张表,并将结果进行了合并。
![]()
这样我们就很轻松地实现了分表策略。
回到目录…
2.4 分布式序列算法
在复杂分布式系统中,特别是微服构架中,往往需要对大量的数据和消息进行唯一标识。随着系统的复杂,数据的增多,分库分表成为了常见的方案,对数据分库分表后需要有一个唯一 ID 来标识一条数据或消息(如订单号、交易流水、事件编号等),此时一个能够生成全局唯一ID的系统是非常必要的。
比如我们之前创建过学生信息表、图书借阅表、图书管理表,所有的信息都会有一个ID作为主键,并且这个ID有以下要求:
- 为了区别于其他的数据,这个ID必须是全局唯一的。
- 主键应该尽可能的保持有序,这样会大大提升索引的查询效率。
那么我们在分布式系统下,如何保证ID的生成满足上面的需求呢?
2.4.1 UUID
UUID 是由一组 32 位数的16进制数字随机构成的,我们可以直接使用 JDK 为我们提供的 UUID 类来创建:
public static void main(String[] args) {
String uuid = UUID.randomUUID().toString();
System.out.println(uuid);
}
结果为 73d5219b-dc0f-4282-ac6e-8df17bcd5860,生成速度非常快,可以看到确实是能够保证唯一性,因为每次都不一样,而且这么长一串那重复的概率真的是小的可怜。
但是它并不满足我们上面的第二个要求,也就是说我们得到的都是一些无序的ID。
2.4.2 雪花算法(Snowflake)
我们来看雪花算法,它会生成一个一个 64bit 大小的整型的 ID,int 肯定是装不下了。
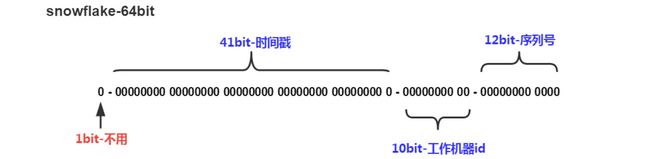
可以看到它主要是三个部分组成,时间 + 工作机器ID + 序列号,时间以毫秒为单位。
- 41 个 bit 位能表示约70年的时间,时间纪元从 2016年11月1日 零点开始,可以使用到 2086 年。
- 工作机器ID 其实就是节点ID,每个节点的ID都不相同,那么就可以区分出来,10 个bit位可以表示最多1024个节点。
- 最后 12 位就是每个节点下的序列号,因此每台机器每毫秒就可以有 4096 个系列号。
这样,它就兼具了上面所说的唯一性和有序性了。这已经是市面上最好的方案了,但是依然是有缺点的:第一个是时间问题,如果机器时间出现倒退,那么就会导致生成重复的ID。第二是节点容量只有1024个,如果是超大规模集群,也是存在隐患的。
回到目录…
2.4.3 ShardingJDBC 实现
Sharding-JDBC 支持以上两种算法为我们自动生成 ID,文档: ShardingSphere-JDBC > 内置算法 > 分布式序列算法。
我们以 ShardingJDBC 的雪花算法为例,来为我们生成唯一 ID。
① 首先是配置数据库,我们两个数据库的 test 表的 id 是 int 类型,装不下64位的,改为 bigint 类型:
ALTER TABLE `yyds`.`test` MODIFY COLUMN `id` bigint NOT NULL FIRST;
② 接着我们需要修改一下 Mybatis 的插入语句,因为现在 id 是由 ShardingJDBC 自动生成,不需要手动插入了:
@Insert("insert into test(name, passwd) values(#{name}, #{passwd})")
int addUser(User user);
③ 接着我们在 yml 中配置:还是采用分库策略、自定义主键生成算法
spring:
shardingsphere:
rules:
sharding:
tables:
test:
actual-data-nodes: db0.test,db1.test
#这里还是分库策略
database-strategy:
standard:
sharding-column: id
sharding-algorithm-name: my-alg
#这里使用自定义的主键生成策略
key-generate-strategy:
column: id
key-generator-name: my-gen
key-generators:
#这里写我们自定义的主键生成算法
my-gen:
#使用雪花算法
type: SNOWFLAKE
props:
#工作机器ID,保证唯一就行
worker-id: 666
sharding-algorithms:
my-alg:
type: MOD
props:
sharding-count: 2
回到目录…
2.4.4 查看效果
我们来编写一下测试用例:
@Test
void contextLoads4() {
for (int i = 1; i <= 20; i++) {
mapper.addUser(new User("aaa" + i, "123456"));
}
}
查看日志:在插入的时候,将我们的 SQL 语句自行添加了一个 id 字段,并且使用的是雪花算法生成的值。

查看数据库:没有任何问题,插入了唯一ID,也是按照分库策略进行的插入。

回到目录…
2.5 读写分离
我们来看看读写分离,我们之前实现了 MySQL 的主从复制:MySQL与分布式:主从复制
那么我们就基于之前的主从结构,实现读写分离,主库作为写,从库作为读:

2.5.1 数据库主从结构
① 我们之前在 Docker 中开启了两个 MySQL 容器,代表一主一从的结构:
![]()
② 注意:我们需要将从库开启只读模式,在 MySQL 配置文件中添加如下:
# 仅对普通用户有效,超级用户root还是可以插入数据的
read-only = 1
③ 从库重启后,重新搭建主从结构,搭建成功!

④ 主库创建我们需要操作的库表信息,从库也随之有了:
create database yyds;
CREATE TABLE test (
id int not null primary key,
name varchar(30),
passwd varchar(30)
);
总结一下:具体信息
| 主库 | 从库 | |
|---|---|---|
| docker 容器名 | mysql-master | mysql-slave |
| mysql 映射端口 | 3301 | 3302 |
| mysql 远程访问用户 | wsy, 123456 | wsy, 123456 |
| 库名 | yyds | yyds |
| yyds 表名 | test | test |
| test 表字段 | (id, name, passwd) | (id, name, passwd) |
回到目录…
2.5.2 yml 配置数据源
spring:
shardingsphere:
datasource:
names: master-db,slave-db
master-db:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://1.15.76.95:3301/yyds
username: wsy
password: 123456
slave-db:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://1.15.76.95:3302/yyds
username: wsy
password: 123456
2.5.3 yml 配置读写分离
当有多个 slave 时,就需要进行负载均衡了。官方提供了很多负载均衡算法: ShardingSphere-JDBC > 内置算法 > 负载均衡算法
spring:
shardingsphere:
rules:
#配置读写分离
readwrite-splitting:
data-sources:
#名称随便写
user-db:
#这里使用静态类型,动态Dynamic类型可以自动发现auto-aware-data-source-name,这里不演示
type: Static
props:
#配置写库(只能一个)
write-data-source-name: master-db
#配置从库(多个,逗号隔开)
read-data-source-names: slave-db
#负载均衡策略,可以自定义
load-balancer-name: my-load
load-balancers:
#自定义的负载均衡策略
my-load:
type: ROUND_ROBIN
props:
sql-show: true
回到目录…
2.5.4 查看读写分离效果
① 编写一个测试用例:写操作
@Test
void contextLoads5() {
userMapper.addUser(new User(1, "zhangsan", "123456"));
userMapper.addUser(new User(2, "lisi", "123456"));
userMapper.addUser(new User(3, "wangwu", "123456"));
}
查看控制台日志:发现确实只向主库插入了数据。

查看数据库:虽然没有直接向从库插入数据,但从库依然同步了数据。

② 再编写一个测试用例:读操作
@Test
void contextLoads6() {
User user1 = userMapper.getUserById(1);
User user2 = userMapper.getUserById(2);
User user3 = userMapper.getUserById(3);
}
查看控制台日志:发现确实只向从库读取了数据。

回到目录…
总结:
提示:这里对文章进行总结:
本文是对Sharding-JDBC的学习,学习了如何分库分表,了解了它内置的分片算法;又使用了Sharding提供的分布式序列算法:雪花算法;最后又用Sharding实现了主从结构下数据库的读写分离。之后的学习内容将持续更新!!!