ABTest基本原理(论文笔记)
参考论文:Overlapping Experiment Infrastructure: More, Better, Faster Experimentation
参考翻译:https://blog.csdn.net/qq_34417408/article/details/116427639
ABTest简介
所谓 AB test,就是测试用户对某个产品同一个元素A和B两个版本(只有这个元素不同)的反应差异,从而进行后续取舍判断。互联网公司经常要上线各种各样的实验,例如修改UI界面的某个按钮,上线一个新的算法等等,通过实验的对比指标来衡量这些修改对用户的影响程度,以此来提高用户体验,提高公司收益等等。
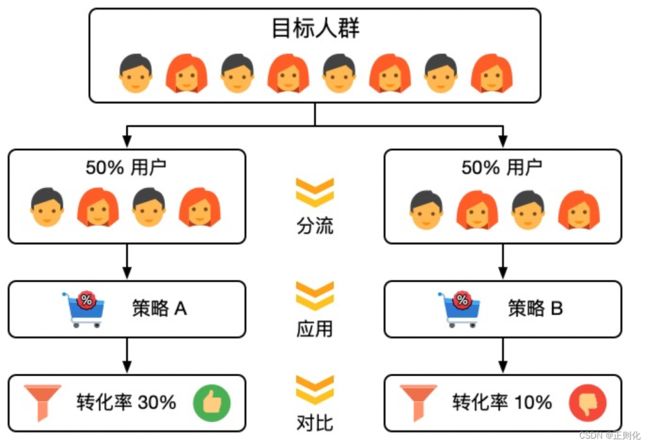
那么应该如何设计实验设施完成这套流程呢?
设计实验设施的目标是:更多、更好、更快。
- 更多:1)同时进行更多的实验,2)不同的实验可以灵活地使用不同的配置和不同的流量分配方式。
- 更好:1)不允许上线不合理的实验,2)迅速捕获并停止那些合理但效果很差的实验。
- 更快:1)可以方便快捷地创建实验,容易到非工程师不需要写代码就可以创建一个实验,2)快速收集和统计评价指标,通过图形化UI帮助分析效果,从而进行快速决策和迭代,3)实验系统不仅支持实验,并且可以对实验进行放量。
重叠实验设施(Overlapping Experiment Infrastructure)
文中给出的一个谷歌Web服务链路的例子
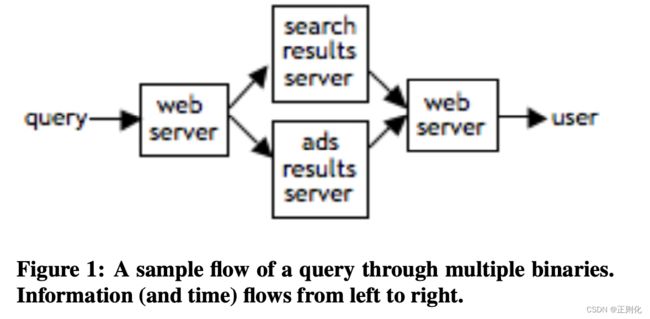
用户通过浏览器发送Web请求与谷歌进行交互,其中,原生的搜索过程与广告搜索过程是相互独立的,各自得出结果之后再拼接成最后的结果页。
这里面每个模块都有做实验的需求,那么应该通过什么方式来控制这些二进制程序执行各种实验的不同的逻辑呢?
实验参数
以往如果我们需要修改每个服务的执行逻辑,都需要修改代码并且走完漫长的编译发布流程。但是如果我们将程序和数据分离,那么就可以同时得到快速影响线上服务的通路,和慢速影响线上服务的通路(程序是慢的通路,改变参数值是快速的通路),即以下两种推送方式:
- 二进制推送:指发布新的程序(
Bug修复、性能提升、新特性,等等)。 - 数据推送:指推送最新的数据到相应的程序,其中包含了默认参数配置,参数是用来配置程序如何运行,比如,控制结果如何展示的服务也许有一个参数是决定顶部广告块的背景色。
可以看到,用数据推送的方式来修改服务的执行逻辑更加快速,非技术人员也可以绕过代码开发直接配置实验,因此为了让实验的创建和执行更方便,实验应该通过数据推送的方式来实现,即通过推送参数来执行实验。
为此,在数据推送中,有一个文件决定程序的默认参数配置,实验过程中,对照组会直接使用默认参数,而实验组则是使用实验携带的实验参数。此外,每次开发新的特性后,可能会添加一个或多个参数,比如说最简单的就是新增一个参数用于控制打开或关闭该新特性。后续可以围绕这些参数进行实验。
为了方便讲解,下面会假设每个实验只修改一个参数。实际上每个实验可以修改0到n个参数。
重叠分层架构
设计实验设施时,考虑以下两个方案,
| 结果 | 优点 | 缺点 | |
|---|---|---|---|
| 单层实验 | 每个请求最多只会命中一个实验 | 稳妥,不会出问题 | 扩展性不足,可支持的实验数量有限 |
| 多因素实验 | 每个请求最多可以同时命中 N个实验( N为参数个数) | 扩展性好,可以支持更多的实验数量 | 谷歌实验系统的实验参数太多,不能确保参数之间的独立性。例子:一个参数是Web页面的背景色,另一个是文字的颜色,虽然『蓝色』对两个参数都是合法值,但是如果同时修改两个参数,而且都取『蓝色』,那么就会导致页面不可读,用户体验差。 |
矛盾:
(1)想支持更多实验,会导致实验互相影响
(2)想保持每个实验的独立性,会导致支持实验数少
怎么样设计实验设施才能既支持更多的实验,又避免实验之间相互影响呢?本文提出的解决方案是将参数分成子集,

- 每个参数子集包含相互不能独立修改的参数。
- 一个参数子集会与一个实验层相关联。
- 每个实验只能修改自己所在实验层的参数
- 每个请求可以在 N个实验中,其中 N是层的数量。
考虑划分参数子集(或者说划分实验层)的方式,比如说可以根据模块化的程序进行划分,不同二进制程序里的参数可以划分到不同的子集中,而且同一个程序里的参数也可以进一步进行划分。划分时要确保不同实验层的参数之间是相互独立的,而同一个实验层的参数之间不要求相互独立(反正一个请求在同一个实验层内只会同时命中其中一个实验,肯定不会同时修改两个参数)
更严格的一些定义:
- 域是指流量划分的一个子集。
- 层是指参数划分的一个子集。
- 实验是指在一个流量划分上,进行零个或多个参数的修改,并最后改变请求处理的过程。
三者关系:
- 域中包含层,层中包含实验
- 层中也可以包含域。也就是说域和层可以相互嵌套,在一个层中嵌套域可以使这一层中的参数在嵌套域中进行进一步划分。
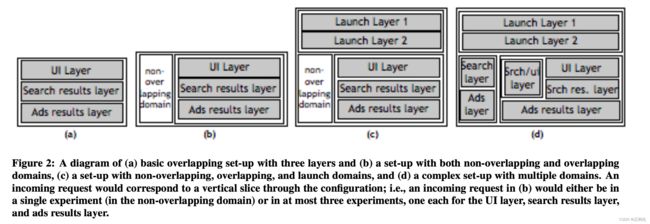
一开始时,我们有一个默认的域和层,它有包含所有的流量和参数,然后我们可以逐步进行划分
1、实验层划分
将参数划分成三个实验层,见(a)。此时每个请求最多只会同时在三个实验中,每层一个,每个实验只能修改相应层的参数。
2、域划分
将流量划分成两个域,见(b)。左边是非重叠域,只有一个默认实验层,这个域中的请求只会命中一个实验(非常灵活,每个实验都不用担心被其他实验影响,可以同时修改大量参数);右边是重叠域,包含三个实验层,这个域中的请求最多可以同时在三个实验中。
3、发布层
- 发布层总是在默认域中(因此每个发布层都有全部流量)。
- 发布层是对参数的一个独立划分,比如,一个参数最多只能同时在一个发布层和最多一个正常层中。
- 参数覆盖的优先级:正常实验层的参数 > 发布层的参数 > 默认参数。也就是说,命中发布层的实验时,对应的实验参数值变成了新的默认参数,除非同时也命中了正常实验层的实验且二者指定的是同一个参数,否则二进制程序就会使用这个新的默认参数。
通过发布层,我们能以一种标准通用的方式逐步灰度并最终全量一个实验策略,且可以跟踪灰度过程中实验效果变化。 通常情况下,每有一个新特性要开始全量时都需要新建一个发布层,当这个新特性最终完成全量时,再将相应的发布层删除,然后修改默认参数值,将该实验固化。
流量分配
实验和域都是在操作一份流量,为了更有效的进行实验流量分配,我们提出了两个不同的概念:分配类型和分流条件。
分配类型
最简单的是随机方法,即对每个请求都进行随机分配,但问题是如果是用户可见的改变,比如背景色,就会导致可能同一个用户在连续访问时背景色在不断地切换,导致体验不佳。
在网页访问过程中,cookie被用来定位唯一用户,因此Web实验中常常借助cookie来作为流量分配的依据,好处是对于同一个用户的连续查询,它可以提供一致性的用户体验。比如说用一个id来标识一个cookie,对cookie id模1000,模相等的流量聚合为实验流量。在实验配置中使用cookie的模,也可以很容易地检查流量之间是否有冲突:实验1可能会用cookie模1和模2,实验2可能使用cookie模3和模4,这两个实验就会有大致相同的请求量(假设cookie分配是随机的)。
为了让层与层之间实现流量分配的相互独立,在cookie取模时需要加入层id的信息(否则的话,假如一个cookie模1000的结果为1,那么它就必定命中每一个实验层中模为1的那部分实验,导致不同层的实验之间不再独立)
mod = f(cookie, layer) % 1000
此外,文中还提出了综合cookie和日期的信息后再取模的方式,还有根据用户id取模的方式等。
总结
文中提出的主要有四种:
- 用户id取模
- cookie id取模
- cookie id + 日期 取模
- 随机方法
分流条件
分流条件(condition)指的是,在通过流量分配类型选择一部分流量后,再通过仅分配特定条件的流量给实验或域,以达到更高效利用流量的目的。比如,一个实验仅仅改变来自日语的查询,那么实验配置中只抽取日语的流量。有了分流条件,一个只使用『日语』流量的实验,和一个只使用英语流量的实验,可以使用相同的cookie取模。分流条件是直接在实验(或域)的配置中指定的。
偏置问题
分配流量时,先依次按照四种分配类型进行判断,如果当前请求
- 不满足当前的分配类型(比如对用户id取模的值不匹配),继续判断剩下的分配类型
- 满足了当前的分配类型,此时如果设置有分流条件,则判断分流条件,如果匹配上,则匹配上对应的实验。如果匹配不上,则匹配不到实验,此时是否要继续判断剩下的分配类型呢?
答案是不继续判断。

比如说一个指定cookie取模上有两个实验,一个分配条件为日语流量,另一个分配条件是英语流量,而这个cookie取模剩余的流量,就是非日语非英语流量,如果继续考虑剩下的分配类型并且命中实验三的话,那么实验三就得到大量非日语非英语流量,而实验三本身并没有配置任何的分流条件,违背了实验三的意愿,可能会出问题,这就是偏置的现象。
因此,为了避免分配顺序后几种分配方式的偏置,不将上述剩余的流量分配给分配顺序后几种分配方式的实验(我们通过将有偏的剩余流量分配一个偏置id来避免偏置)
实验逻辑
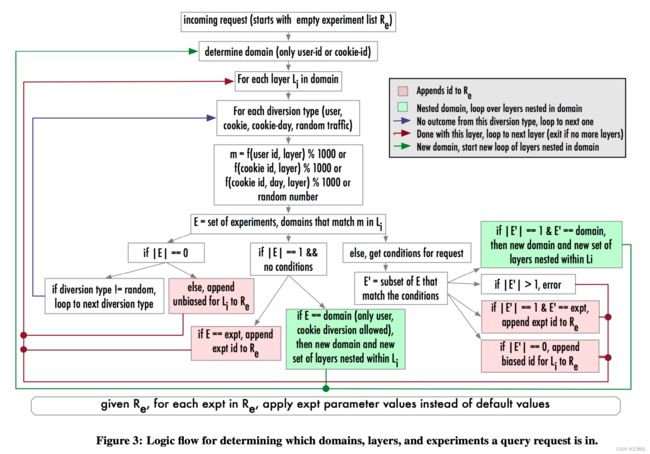
1、一个请求进入实验系统,刚开始时带有一个空的实验列表。
2、根据userid和cookieid确定这个请求会被分配到哪一个域中,是非重叠域,还是重叠域
3、遍历域中的实验层
4、遍历四种分配类型,看是否有实验/域配置在同一个流量槽里:
- 没有实验/域在槽里:继续遍历其他分配类型
- 有实验/域在槽里,且这个实验/域没有配置分流条件:如果是实验,则直接把实验参数塞进实验列表中,如果是域,则遍历这个域中的实验层呢个。
- 有实验/域在槽里,且这个实验/域配置有分流条件:用分流条件筛选
- 剩余实验/域数量=0:不遍历剩余的分配类型(防止偏置问题),直接遍历下一个实验层
- 剩余实验/域数量>1:同一个实验层最多只会命中一个实验,错误
- 剩余实验/域数量=1,且是域:继续遍历域里的实验层。
- 剩余实验/域数量=1,且是实验:把实验参数塞进实验列表里。
所有循环都遍历完成后,得到的实验列表R中就存放着这个请求命中的实验参数,二进制程序在后续的逻辑处理时就会使用对应的实验参数值而不是默认参数值,从而执行这些实验的特性。
工具与流程
监控、日志、实验指标分析、实验流程规范等。
成果
重叠实验设施上线后,达成了更多、更好、更快的效果。
More
| 目标 | 达成方式 |
|---|---|
| 同时进行更多的实验 | 重叠分层实验设施,每个请求最多可命中N个实验(N为实验层数) |
| 每个实验可以使用不同的配置和不同的流量分配方式 | 每个实验可配置不同的实验参数,选择不同的流量分配类型和分流条件 |
Better
| 目标 | 达成方式 |
|---|---|
| 不允许上线不合理的实验 | 实验流程规范:实验委员会包含一组工程师,审核实验者在做实验前提交的一个轻量级的checklist |
| 迅速捕获并停止那些合理但效果很差的实验 | 快速收集统计实验指标、告警机制 |
Faster
| 目标 | 达成方式 |
|---|---|
| 非工程师也可以方便快捷地创建实验 | 执行使用使用的是数据推送方式而不是二进制推送方式,非工程师只需要填写实验参数而不是修改代码 |
| 快速收集和统计评价指标,图形化UI帮助分析效果 | 快速收集统计实验指标、前端UI |
| 不仅支持实验,而且支持对实验进行放量 | 通过重叠分层架构中的发布层进行放量 |