MySQL的执行逻辑和表的结构 | 数据分析学习历程全记录
该篇文章包含以下几部分:
- MySQL的执行逻辑
- 表的结构
MySQL的执行逻辑
很多人在最初开始学习SQL语言时会产生一个误解,将SQL误认为就是MySQL,但事实上SQL是一种语言,而MySQL是数据库管理系统(DBMS),一种建立用户和数据库之间的联系的系统。
因为MySQL技术成熟,经典且被广泛运用,因此很多课程中都是以MySQL为例子对SQL语言和DBMS的结构进行讲解,但并不代表所有的DBMS的结构都相同,但其框架不会有很大的差别。
下图是从MySQL官网中下载的图片,展示了MySQL的运行逻辑。
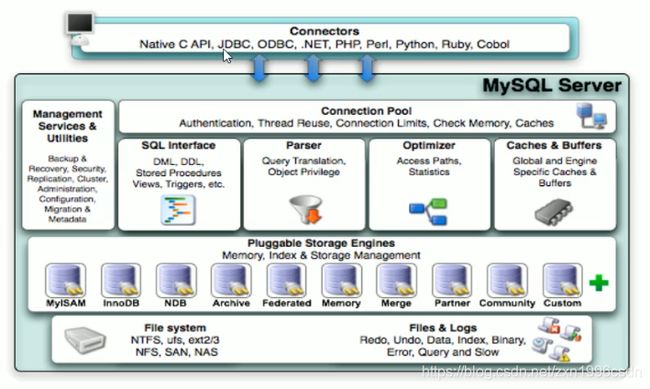
我们可以将其细分为:
连接层(connectors)
服务层(Connection Pool;Management Services & Utilities;SQL Interface;Parser;Optimizer;Caches & Buffers)
引擎层(Pluggable Storage Engines)
存储层(File system;Files & Logs)
接下来我们详细讲一下每一个模块的作用。
连接层connectors:
用于连接的客户端,比如Java数据库连接(JDBC),是Java语言中用来连接数据库的方法,比如微软提供的开放数据库连接(ODBC),比如超文本预处理器(PHP)以及Python等。
连接状态可以分为短连接和长连接。短连接的特点是执行少数几次查询就会断开,会浪费大量资源。相比之下,长连接的特点是一直保持连接,默认的无动作断开连接的等待时长是8个小时,但长连接会产生驻留内存。
驻留内存可以通过固定时间自动重新连接,或者手动输入mysql_reset_connection进行重新连接,来进行释放。
服务层Connection pool:
连接池组件,用以接收客户端发起的连接请求,开启线程等相关操作。
服务层Management service & utilities:
与系统配置相关的模块。
服务层SQL Interface:
SQL接口,接受用户的SQL命令,并且返回用户需要查询的结果。
服务层Parser:
解析器,用于解析客户端发过来的请求,对其进行词法分析和语义分析。
词法分析:检测每个单词的含义。比如检测某个单词是否是函数,某个单词是否是表名等。
语义分析:校验语法规则,查看是否满足Mysql语法规范。比如From是否跟在select之后等。
服务层Optimizer:
优化器,用于对SQL语句进行优化处理,选择最优的解,得到最高的执行效率。比如查询请求是否使用索引,使用哪一个索引等。
服务层Caches & buffers:
检查缓存,当缓存中存在需要查询的数据时,则直接响应,返回结果,不再扫描数据库。
引擎层Storage engines:
存储引擎,用于对数据进行创建、查询、更新和删除操作,不同的存储引擎对应不同的方法。
存储层File system:
硬件,用于存储数据。
存储层Files & Logs:
数据本身以及执行日志等相关信息。
表的结构
设置表属性
对于数据库中的每一张表而言,都需要三个属性对其进行定义,即存储引擎(ENGINE),行记录格式(ROW FORMAT)和字符编码(CHARACTER SET)
接下来对这三个属性进行更详细讲解。
存储引擎
回想之前讲到的MySQL结构,我们发现不管是对数据库进行怎样的处理或是查询,都是通过存储引擎进行访问的。
不同的存储引擎意味着不同的数据存储方式和访问方式,常用的引擎包括MyISAM和Innodb,在MySQL5.5之后的版本的默认引擎都是Innodb。
行记录格式
对字段的记录格式可以分为两种,一种为静态,即不管真实的数据的字节长度是多少,都会给其分配相同的字节长度,这种存储方式读取速度较快,但是遇到不足分配的字节长度的数据,则会浪费多余出来的空间。
另一种为动态,即规定最大可用的字节长度,对于小于最大可用字节长度的数据,仅占用该数据本身的字节,这种存储方式读取速度较慢,但节省空间。
对于所有字段都是静态存储的表,我们叫它静态表,相反,则称之为动态表。
字符编码
将文字或数字进行编码用于存储在计算机之中,比如ASCII码就是最早出现的最基本的字符编码。
MySQL默认的字符编码是Latin-1,不支持中文,需要将其修改为GBK或者UTF8才能支持中文。
表结构
库是一系列相关的数据库的集,一个数据库中有系统库和用户库,我们可以通过系统库对数据库进行操作,比如开启或者关闭某种服务,用户库则存储着数据。
在关系数据库中的表是一系列二维数组的集合,用来代表和储存数据对象之间的关系。
数据库中的每个表都有一个名字,用来标识自己,在一个库中不能出现重复的表名。
表的模式(schema):
表示数据库和表的布局及特性的信息,在系统库的information_schema中的table可以看到每一张表的模式。
输入:
Select * from information_schema.tables;
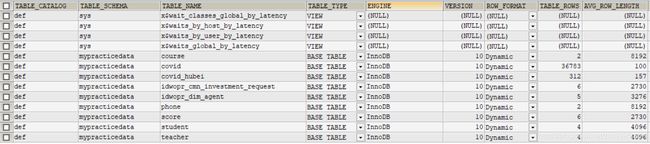
上图是截取的一部分表的信息,table_schema显示的是该表属于哪个库,table_name表示表的名字,Engine表示采用的是哪个存储引擎,row_format显示是静态表还是动态表,table_rows表示表中有多少行记录等等。
表的列(column):
或者称之为字段,所有表都是由一个或多个字段组成,同样可以通过information_schema对每一列进行查询,这里查询我的一个用来练习的库。
输入:
Select * from information_schema.columns where table_schema = 'mypracticedata';
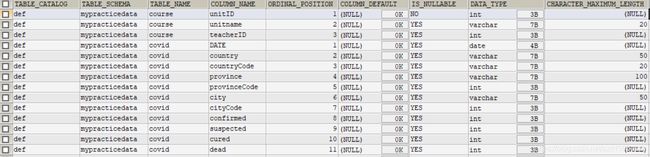
Table_schema表示该列属于哪个库,table_name表示该列属于哪个表,column_name表示列的名字,ordinal_position表示列的位置,is_nullable表示该列是否允许NULL值,data_type表示该列允许的数据类型,character_maximum_length表示允许的最大长度等。
Innodb存储引擎限制了每张表的存储字段数量,最高是1017个字段。在创建表时,包含过多的字段将影响使用。
列的数据类型(datatype):
每个字段都有相应的数据类型,它限制(或容许)该列中存储的数据。
MYSQL支持五大数据类型:
数值型,如BIGINT,FLOAT和DECIMAL等。
日期和时间类型,如DATETIME和TIMESTAMP等。
字符串类型,如VARCHAR,CHAR和BLOB等。
空间数据类型,如GEOMETRY,POINT和POLYGON等。
JSON数据类型。
数据类型的选择取决于字段存储的具体数据,需要确保选择的数据类型可以正确存储数据,并最大化利用存储空间,同一个数据可以用不同的数据类型进行存储,我们应该根据具体情况选择最合适的数据类型。
表的行(row):
表中的一行就是表的一个记录。
MySQL允许每条记录最长达到65535字节,对于超过长度的情况是可以处理的,但是会影响性能,因此在选择数据类型时要按照最大化利用空间的原则进行选择,减少空间的占用。
表的主键(primary key):
主键是表中的一个或一组字段,用于保证表中的记录的唯一性,特点是该字段的值能够唯一区分表中的每一行。其要求是每一行主键的值唯一,并且不能是NULL。
在创建表时,应该总是定义一个主键,虽然有时并不需要主键参与查询等操作,但主键的存在有助于以后对数据的管理。
比如想要删除表中的某一记录,如果表的数据量很大,并且没有主键,将很难保证删除的记录是真正需要删除的记录,也难以保证没有删除其它的数据。因此主键的存在,可以保证对表的操作仅涉及到相关的记录。
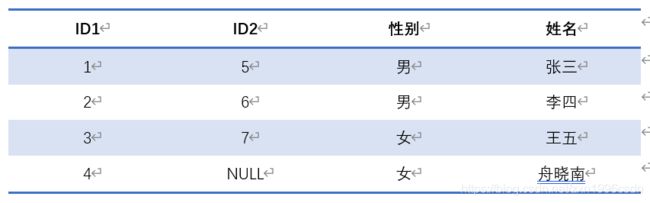
在下表中,ID1可以作为主键,但是ID2和性别无法作为主键,因为ID2中存在NULL值,而性别列中男性对应两人,女性对应两人,无法区分每一行。
欢迎关注知乎账号:舟晓南