猿人学web端爬虫攻防大赛赛题解析_第六题:js 混淆 - 回溯
第六题:js 混淆 - 回溯
- 1、前言
- 2、题目理解
- 3、加密原理解析
-
- 3.1、加密位置判断
- 3.2、解密_萌新试错版
- 3.3、解密_老手经验版
- 4、代码实现过程
-
- 4.1、坑一:风控不通过
- 4.2、坑二:参数q设置有误
- 4.3、完全体代码
- 5、结语
- 6、参考文献
1、前言
万万没想到,距离上次做完第四题之后,再次动手写猿人学赛题解析的博客已经是四个多月之后了。其中各种艰辛,难以言表,只能说逆向这鬼东西水太深了,要掌握的各种知识和骚操作是真的不少,奈何自己人菜瘾还大,不信邪非要靠自己手撕代码,想在不借助外力的情况下,自己把代码还原出来,结果是撞南墙撞的头破血流,一颗勤奋好学的热血之心险些就此熄灭。第六题相比第五题还算简单,即使这样我也前前后后琢磨了差不多小半个月,惭愧啊,话不多说,直蹦主题。
2、题目理解
一开始看到这题的时候,我第一眼关注的是回溯两个字,想着肯定是要靠层层挖掘混淆后加密代码逻辑,最终还原出真实的加密代码。事实证明有时候过度理解不是啥好事,因为这题他尽管有回溯,但回的没我想象的那么多,最后证明了使用正确解题方法要比死扣代码高效的多!
3、加密原理解析
事实上,这题解析过程我大致经历了两个阶段,从一开始的生啃硬扣代码逻辑到后面得知这加密原理可以一眼看出,我的内心是崩溃的o(╥﹏╥)o,所以了解RSA的朋友们,可以直接跳到3.2了,如果需要的话。。。
3.1、加密位置判断
先看题目加载内容,既然是要找奖金总额,那想必奖金金额应该是通过ajax请求异步返回的:
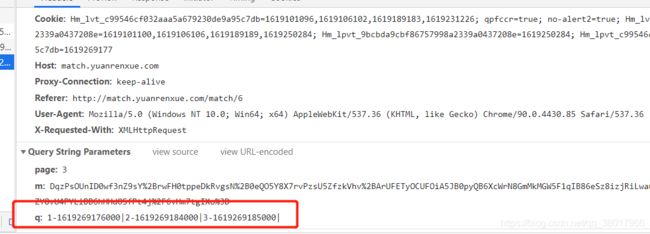
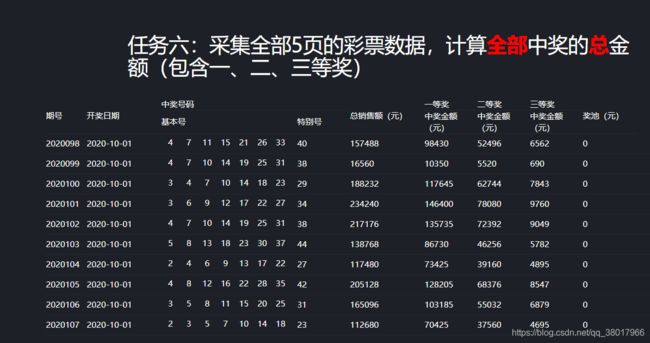 果不其然,在chrome浏览器的XHR请求里,找到了这个请求的url和对应的返回值,观察一下发现这些值只是三等奖的中奖金额,但题目要求的可是全部中奖金额,那一等奖和二等奖的值是从哪来的呢?
果不其然,在chrome浏览器的XHR请求里,找到了这个请求的url和对应的返回值,观察一下发现这些值只是三等奖的中奖金额,但题目要求的可是全部中奖金额,那一等奖和二等奖的值是从哪来的呢?
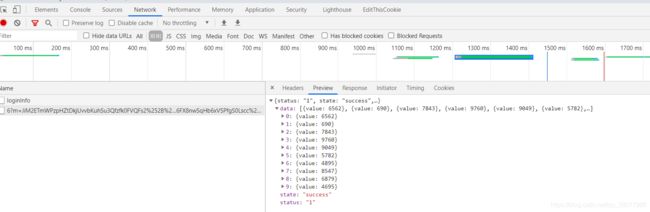
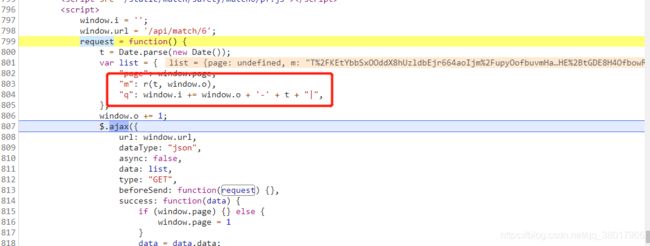
这里回到网页的源码部分,可以很容易找到其他金额的生成逻辑,这段代码出现了跟数值相关的操作,推测就是其他奖金金额生成的位置。算了一下,二等奖是三等奖的8倍,一等奖是三等奖的15倍,总金额是一等奖的24倍,跟最终请求结果里的数值是一致的,所以这里的问题解决了。

回到请求奖金的这个url这里,发现这里有两个参数,m和q,我们要模拟正确的请求必然要找到这两个参数的生成逻辑,对于有经验的爬虫老手来说,在源代码里观察一下估计就能大概找到位置了。
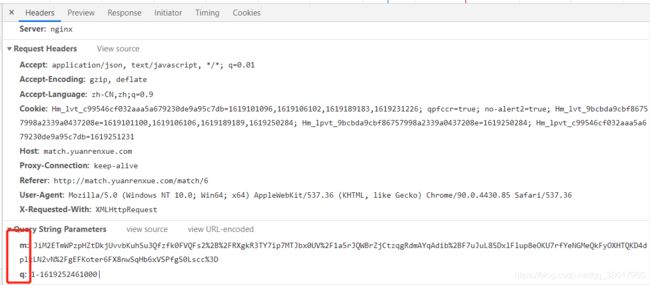
这里还是用朴素的寻找逻辑讲讲这个过程,万一有比我还萌新的萌新看到这篇博客了呢,这里我是选择设置XHR断点,当检测到发送了包含api/match/6?m=这段字符串的请求发起时,请求就会自动在这里断下来:
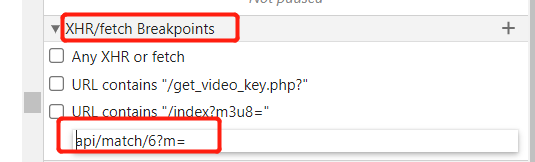
然后我们就可以看到整个调用栈了,一步步网上追,观察m和q最早是在哪里被赋值的:
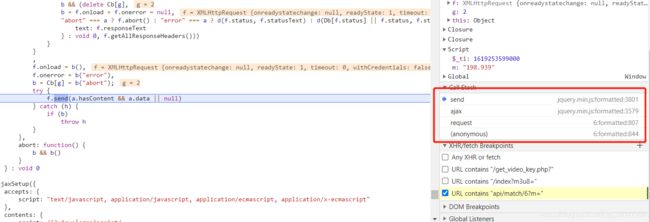
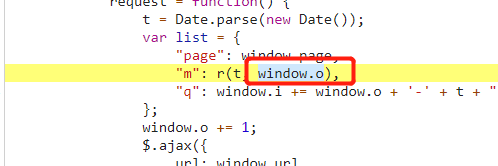
很轻易的就在request函数这里找到了m和q被赋值的地方,粗略一看,m是由r函数生成的,q是由时间戳加其他字符一起拼接而成的,相对来说比较简单,q里的window.o在多观察几次以后发现就是翻页的页数,或者说每发送一次数据请求,这个值都会加1:
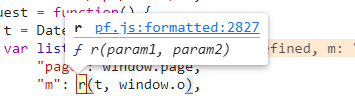
再来看m,调试的时候鼠标放这一看,发现它是由pf.js文件里的r函数生成,好家伙,这就是第六题最难解决的加密参数了吧,毕竟一般能被单独放到js文件里加密的参数都不简单,反正我是经常惨败而归。
3.2、解密_萌新试错版
先看看我使用硬扣法,试图通过一步步还原m值的惨痛经历。
首先在pf.js文件文件内,我们一开始就追到了r函数的位置,param1是前面的时间戳t,param2是翻页页数,初看是根据这两个值来进行加密。
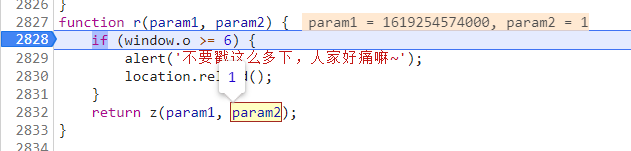
r函数里又调用了z函数,z函数内调用了函数_n:
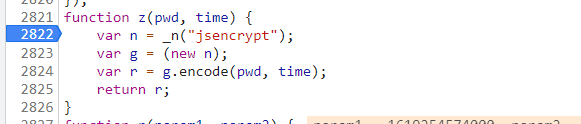
在这里,_n的本体是n函数,n函数是匿名函数function(i)的闭包函数:
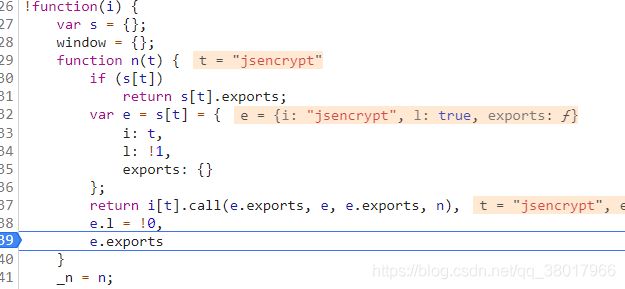
_n("jsencrypt")等于n("jsencrypt"),这个函数运行结果实际上就是这个函数内的匿名函数n:
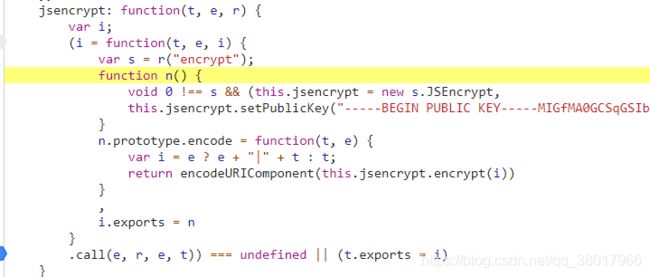
匿名函数n被new了一下之后,变成了g函数,也就是说最初的r函数最后实际上运行的是这个encode函数:

这个函数内实际又调用的是this.jsencrypt.encrypt(i)这个函数,再往前追溯发现调用的是这个encrypt函数:
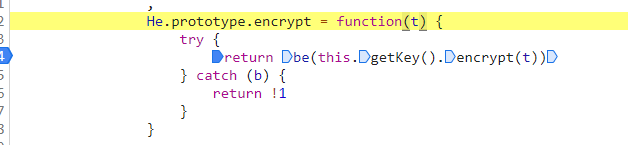
而在它内部,他又调用了be函数:

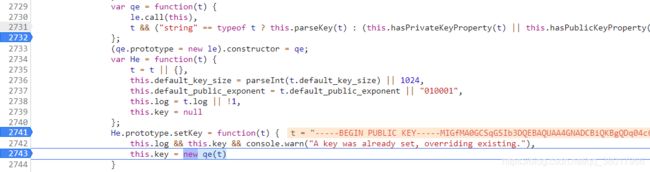
be函数的参数是getKey这个函数的结果加密而成,这个函数没有做其他操作,直接返回了this.key:

进一步找到了this.key的生成位置,很明显它是qe对象实例化后的结果,经过调试,qe函数执行的就是this.parseKey(t),此处这个参数t就是代码里明文写出来的这段字符串:“-----BEGIN PUBLIC KEY----MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDq04c6My441Gj0UFKgrqUhAUg+kQZeUeWSPlAU9fr4HBPDldAeqzx1UR92KJHuQh/zs1HOamE2dgX9z/2oXcJaqoRIA/FXysx+z2YlJkSk8XQLcQ8EBOkp//MZrixam7lCYpNOjadQBb2Ot0U/Ky+jF2p+Ie8gSZ7/u+Wnr5grywIDAQAB-----END PUBLIC KEY-----”:
事实上,在经历了上面这一步步调试之后,我又往更深处追了十几个嵌套函数,一个个套娃函数,每当我以为差不多该找到尽头的时候,里面都会有新的其他函数的调用。总共追了小几十层调用逻辑后我终于有点失去耐心了,这是人干的事吗?难道真有要回溯几百次的加密?那还不如把整个代码全复制出来调试算了(我真后悔没有早点这么做,真的!),实在没辙了,开始网上找教程,才发现别人真的是直接把所有代码复制出来,并且一眼就看出了是个啥加密,还是吃了没文化的亏啊!!!
3.3、解密_老手经验版
熟悉前段和逆向的老江湖们,见惯了各种网站使用的常用加密算法,他们往往一眼就通过代码的特征和结构看出面前是什么加密,比如这道题里,典型的特征就是代码里多次出现的jsencrypt,以及设置公钥和秘钥的相关内容,如果了解RSA加密相关知识的,确实能很容易通过这些特征看出来这就RSA加密算法。
![]() 当然,这里作者肯定是对算法做了点修改的,代码调试过程中还是有几个坑。
当然,这里作者肯定是对算法做了点修改的,代码调试过程中还是有几个坑。
首先在pf.js文件里的头几行就有一段颜文字混淆的内容,就是下面这些看起来很可爱,但是为了混淆视听,增大理解难度的代码:

对于这种混淆可以用解混淆工具直接还原,也可以直接在浏览器控制台调试,看看原始代码内容是什么,比如直接去掉颜文字混淆代码最后的('_')表情符号,在控制台运行后出现了如下代码:
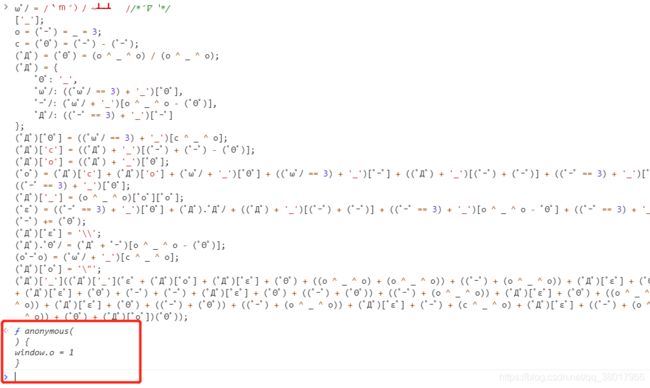
也就是说这里的混淆源代码就是定义了一个匿名函数,内容是window.o = 1,其实就是给这个变量赋了个值:
ƒ anonymous(
) {
window.o = 1
}
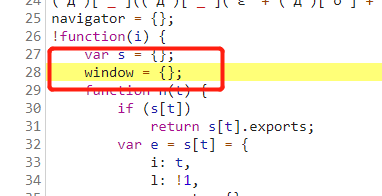
当然这里在本地运行时还要在代码开头给window对象赋值,并将原始的将window赋值为空的代码注释掉:
window = global;
上面是第一个坑,还有第二处,就是代码运行过程中会提示一个Message too long for RSA的错误:

回到浏览器查看,找到这段字符输出的位置,是判断e和t这个字符串的长度大小:

往上追,发现t就是时间戳字符串,那可以判断就是e这个字符串的值有误了:

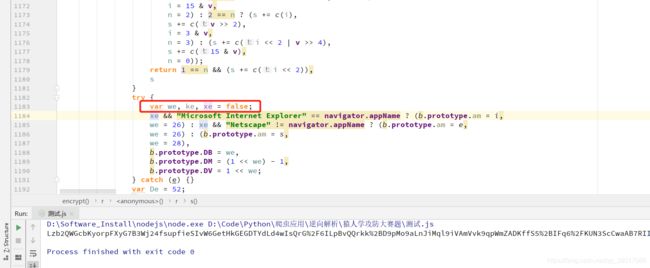
经过层层调试(这里就不细说了,毕竟反正找着也挺累,再加上看某个解析时大佬开头就给提示了,后面就没花太大功夫找了),最终找到了问题所在,就是这里的xe的值有问题:

控制台输出一下,发现其实就是个false,将其替换一下,就能正常输出加密结果了

nodejs环境下的运行结果:
以上就是整个加密的还原过程,要说复杂吧也不是很复杂,要说简单吧,很多东西没有js基础还真的是会完全摸不着头脑,别人凭经验几十秒就能看出来的东西,可能你要摸索好几天才能梳理清楚来龙去脉,只能说逆向还是需要花时间好好打磨基础的。
4、代码实现过程
满心欢喜的以为掌握了真谛的自己,在用python实现过程中还是遇到了好几个坑,令我百思不得其解,苦思冥想,朝思暮想,最终也没想太透彻
4.1、坑一:风控不通过
第一个问题是在写好用于请求第一页内容的代码之后,运行了一波发现返回结果是风控不通过,一开始我还以为是请求速度太快,所以加了几秒暂停,但依然得不到正确响应,于是又从头到尾检查加密参数、请求头是不是有问题,反复跟浏览器端的请求对比,发现代码真的是没问题,但就是通过不了风控,直到我把代码拿到另一台电脑运行,返回结果就正常了。。。。
那我就想肯定是我电脑环境出问题了,比如服务端检测了指纹信息什么的,但是加密参数里并没有跟指纹相关的信息传过去啊,最后当我用代理换了个ip以后,居然通过风控了,所以问题只能是出在服务器把我ip封了,且只针对第六题,后来把ip换回来发现也能正常响应了,这就让我有点迷了,按道理通过程序请求应该是没有太多其他特征可以检测的,可是为什么就换了一次ip再换回来就能正常请求结果了,这个问题有待日后了解。

4.2、坑二:参数q设置有误
第一题得到正确响应后马上写了个循环,期待得到所有正确返回值,结果程序一跑起来,第二题往后面又开始风控不通过了,真是吐了一口老血,毕竟按我的观察,每请求一次,参数q都会带上上一次的时间戳信息,所以我也是这么构造q值的。
q = q+str(page) + '-' + t + '|'
后来发现浏览器端跟本地端运行还是有区别的,在浏览器我们每次点击跳页的时候,window都会加1,不管是跳转到第几页,就是点一次值增加一点,这是靠浏览器端检测的。但是在本地运行时服务器并不会检测到我是第几次请求,所以参数q是可以不用累加上一次请求时间戳的,即可以把每次请求都当第一次请求,只改变时间戳t值就行。
4.3、完全体代码
Python实现代码如下,对应的6_js回溯.js源码在这里:github:js回溯
# -*- coding: utf-8 -*-
# @Time : 2021/4/20 21:44
# @Author : zzt
# @Email : [email protected]
# @File : 6_js回溯.py
# @Software: PyCharm
import requests
import time
from Naked.toolshed.shell import execute_js, muterun_js
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Host': 'match.yuanrenxue.com',
'Proxy-Connection': 'keep-alive',
'Referer': 'http://match.yuanrenxue.com/match/6',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
session = requests.session()
session.headers=headers
for page in range(1, 6):
t = str(int(time.time())* 1000)
'''第一种传参方式,按请求次数对应'''
q = str(page) + '-' + t + '|'
js_result = muterun_js('6_js回溯.js',t+' '+str(page))
'''第二种传参方式,每次都算第一次请求'''
# q = str(1) + '-' + t + '|'
# js_result = muterun_js('6_js回溯.js',t+' '+str(1))
m=js_result.stdout.strip()
if page==1:
params = (
('m', m),
('q', q),
)
else:
params = (
('page',page),
('m', m),
('q', q),
)
if page>3:
headers['User-Agent']='yuanrenxue.project'
url = 'http://match.yuanrenxue.com/api/match/6'
response = session.get(url, params=params).json()
print(response)
5、结语
搞逆向很痛苦,复盘学习过程也很痛苦,学习本身就是件挺痛苦的事,尤其是得不到正反馈的时候,多受几次打击很容易产生要放弃的念头,所以还是要循序渐进,由易到难,把基础搞扎实,下次再上来就挑战对自己这么有难度的题就扇自己大嘴巴子!
6、参考文献
1、吾爱破解大佬解析
2、B站大佬视频详解