熟悉常用的HDFS操作(附录HDFS常用命令)
文章目录
-
- 1. 学习目的
- 2. 学习内容
- 3. 实验一
-
- 3.1 追加文本
- 3.2 覆盖文本
- 3.3 脚本完成
- 4. 实验二
-
- 4.1 下载文件脚本
- 4.2 输出文件内容脚本
- 4.3 显示单个文件信息脚本
- 4.4 显示目录信息脚本
- 4.5 自动创建目录脚本
- 4.6 追加文件脚本
- 4.7 删除文件脚本
- 4.8 移动路径
- 5. 实验三编写Java代码
-
- 5.1 远程运行
- 5.2 Linux端运行
- 附录 hadoop常用命令
1. 学习目的
1、理解HDFS在Hadoop体系结构中的角色;
2、熟练使用HDFS操作常用的Shell命令;
3、熟悉HDFS操作常用的Java API
2. 学习内容
1、编程实现指定功能,并利用Hadoop提供的Shell命令完成相同任务:
2、编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”。
3. 实验一
编程实现以下指定功能,并利用Hadoop提供的Shell命令完成相同任务
3.1 追加文本
向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件
首先我们启动我们hadoop的所有结点(此命令需在sbin目录下进行),命令:
sh start-all.sh
其中如果你是用管理员权限创建的目录,系统启动读取时需要你输入密码,输入即可

当然如果之前已经运行了nameNode和DataNode会显示运行失败,可以使用jps查看进程,用kill -9 进程号鲨掉进程再启动

可以看到其实通过
start-all.sh启动时,会启动很多服务,我们可以看一下这个脚本里面的内容
vim start-all.sh
核心内容如下:
# Start all hadoop daemons. Run this on master node.
echo "This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh"
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh
# start hdfs daemons if hdfs is present
if [ -f "${HADOOP_HDFS_HOME}"/sbin/start-dfs.sh ]; then
"${HADOOP_HDFS_HOME}"/sbin/start-dfs.sh --config $HADOOP_CONF_DIR
fi
# start yarn daemons if yarn is present
if [ -f "${HADOOP_YARN_HOME}"/sbin/start-yarn.sh ]; then
"${HADOOP_YARN_HOME}"/sbin/start-yarn.sh --config $HADOOP_CONF_DIR
fi
可以看到它启动了start-dfs.sh和start-yarn.sh两个脚本
这两个脚本在start-all.sh的同级目录下,请自行研究,主要内容就是为了启动hadoop的组件
上传本地文件到HDFS
上一次实验我们其实就已经上传过一个文件到hadoop中了,我们可以通过hadoop fs -ls -R /命令查看(请在hadoop目录下进行)
-ls 显示目录信息-R递归 所以:-ls -R 递归显示文件信息

查看一下文件内容,命令:
hadoop fs -cat /root/data/input/log.txt
![]()
我们现在直接来修改这个文件,由于上次实验我们是在/input目录下建了log.txt文件,这次我们依旧在这里建文件,当然文件建在哪里并不重要,请读者随意,echo打印,>重定向,这里将打印内容输出到指定目录的文件中,文件不存在会自动创建
![]()
追加到文件末尾的命令(这里最好用绝对路径):
hadoop fs -appendToFile /input/test2.txt /root/data/input/log.txt

当然我们也可以重新上传一份
命令很简单,就是把源文件上传到hadoop的目标目录中,前提是hadoop中要有这个目录,没有请使用hadoop fs -mkdir -p /root/data/input创建
hadoop fs -put /input/test2.txt /root/data/input/
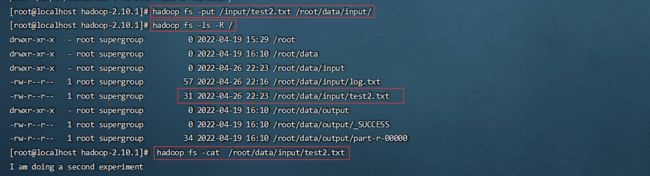
3.2 覆盖文本
覆盖文本和追加文本一样,只是要注意本地文件和hadoop中的目录都要存在
命令:
hadoop fs -copyFromLocal -f 本地文件路径 hadoop中文件路径
我这里在之前的test2.txt中覆盖一行文本,>>表示重定向并追加,>表示重定向并覆盖
![]()
所以我的命令就是:
hadoop fs -copyFromLocal -f /input/test2.txt /root/data/input/test2.txt
![]()
3.3 脚本完成
其实脚本也就是一段能够执行的代码,在windows平台上是以.bat的后缀名出现的,在Linux上是以.sh后缀名出现的
if $(hadoop fs -test -e /root/data/input/test2.txt);then $(hadoop fs -appendToFile /input/test2.txt /root/data/input/test2.txt);
else $(hadoop fs -copyFromLocal -f /input/test2.txt /root/data/input/test2.txt);
fi
我们先来分析一下这三行脚本,在Linux的shell脚本中if和fi是要成对出现的,表示判断语句
$()是用来做命令替换用的,表示括号内的是一串可以运行的执行,而不是字符串,我们还经常采用反撇号**``**来做命令替换
then、else就更好理解了,就是分支语句
Hadoop fs –test –[ezd] PATH 对PATH进行如下类型的检查:-e PATH是否存在,如果PATH存在,返回0,否则返回1;-z 文件是否为空,如果长度为0,返回0,否则返回1; -d 是否为目录,如果PATH为目录,返回0,否则返回1
综上所示,脚本的作用就是判断一下你有没有中hadoop中已经存在test2.txt这个文件了,存在就追加,不存在就覆盖(会默认创建)
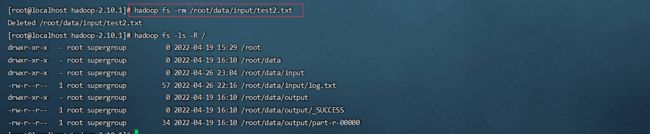
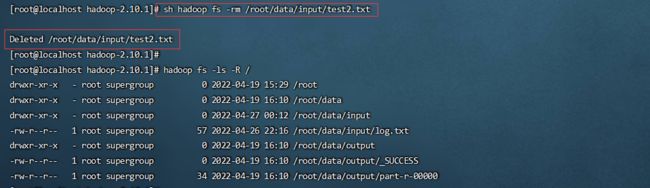
接下来我们演示一下,在演示之前我们先将之前hadoop中的test2.txt文件删除掉
我们就在当前目录下创建这个脚本,起名为test.sh
vim test.sh
输入脚本(这里你要填你的路径哦!)

执行一下(sh表示用shell脚本执行)
sh test.sh
![]()
查看一下,可以看到没有文件,所以追加了文本

然后再运行一次sh test.sh,可以看到因为文件已经存在了,所以这一次是追加文本了

4. 实验二
4.1 下载文件脚本
从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名
上面的脚本会写了,下面的脚本就很容易理解了
if $(hadoop fs -test -e /input/test2.txt);then $(hadoop fs -copyToLocal /root/data/input/test2.txt /input/test3.txt);
else $(hadoop fs -copyToLocal /root/data/input/test2.txt /input/test2.txt);
fi
先判断一下在本地中有没有test2.txt这个文件了,有就执行下面的代码也就是下载文件为test3.txt,没有就下载为test2.txt
这里我们先把之前/input/test2.txt这个文件删掉,命令为rm -f -f表示强制删除
接下来我们继续创建一个脚本,也在当前目录下
vim test2.sh

我们执行一次:
sh test2.sh

可以看到没有该文件,所以下载文件文件名为test2.txt
我们再执行一次,可以看到生成的是test3.txt

这里可能也会有问题,可能是由于hadoop版本或者是权限问题不支持判断本地文件,这里我们知道脚本含义就可以了
4.2 输出文件内容脚本
将HDFS中指定文件的内容输出到终端中
命令:
hadoop fs -cat /root/data/input/test2.txt
其实直接执行也可以的,这里直接用简单的方式将其作为脚本执行,读者也可以自行像上面一样建个xxx.sh再执行
其实脚本不也就是一段可以执行的代码吗
![]()
4.3 显示单个文件信息脚本
显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息
hadoop fs -ls -h /root/data/input/test2.txt
![]()
4.4 显示目录信息脚本
给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息
hadoop fs -ls -R -h /root/data/input

4.5 自动创建目录脚本
提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录
#!/bin/bash
if $(hadoop fs -test -d /root/data/input2);then $(hadoop fs -touchz /root/data/input2/test.txt);
else $(hadoop fs -mkdir -p /root/data/input2 && hadoop fs -touchz /root/data/input2/test.txt);
fi
hadoop fs -touchz递归的创建一个文件
这个和之前的太类似了,这里就不赘述了
4.6 追加文件脚本
向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;
hadoop fs -appendToFile 本地目录/文件 hadoop目录/文件
4.7 删除文件脚本
删除HDFS中指定的文件
hadoop fs -rm /root/data/input/test2.txt
4.8 移动路径
在HDFS中,将文件从源路径移动到目的路径
mv命令详解
使用方法:hadoop fs -mv URI [URI …]
将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
示例:
- hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -mv hdfs://host:port/file1 hdfs://host:port/file2 hdfs://host:port/file3 hdfs://host:port/dir1
返回值:
成功返回0,失败返回-1
我们将input下面的log.txt移动到output目录下
hadoop fs -mv /root/data/input/log.txt /root/data/output/log.txt

5. 实验三编写Java代码
编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本
5.1 远程运行
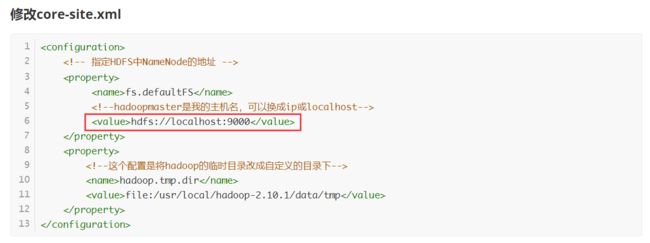
其实我们在3.1节中启动hadoop中所有组件的时候启动了nodeMange,nodeMange提供了一个网页来供我们管理我们的结点和集群,默认端口9000,我们可以在配置文件中找到
管理界面:http://localhost:8088
NameNode界面:http://localhost:50070
HDFS NameNode界面:http://localhost:8042
我这里访问我的nameNode管理界面,由于我用的是云服务器,所以地址隐藏了,默认端口50070,在这里你可以对你的集群进行管理

我们可以通过一些端口来获取hadoop的信息,接下来我们用
Java通过hadoop暴露的一些端口来获取信息在远程我们需要使用Maven导入以下jar包。或者你可以去maven的中央仓库中找到(注意要和你的hadoop版本相匹配)
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>2.1.1version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-itartifactId>
<version>1.2.6version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.3version>
dependency>
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.net.URISyntaxException;
public class demo {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
// 下面的地址是hadoop的地址
FileSystem fs=FileSystem.get(
new URI("hdfs://192.168.153.129:9000"), new Configuration(), "root");
// 下面的地址是hadoop的地址,后面的路径是你要读取的文件
FSDataInputStream in = fs.open(new Path(
"hdfs://192.168.153.129:9000/你的文件名路径"));
BufferedReader d = new BufferedReader(new InputStreamReader(in));
System.out.println("读取文件:"+remoteFilePath);
String line;
while ((line = d.readLine()) != null) {
System.out.println(line)
}
d.close();
in.close();
fs.close();
}
}
这里你执行的话会报一个错
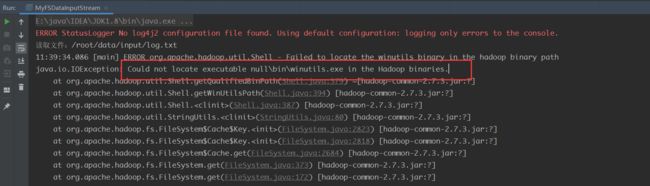
原因是缺少winutils.exe程序,我们需要在自己的电脑上安装一下这个插件
注意:winutils.exe的版本号一定要和使用的hadoop版本号保持一致!!!
下载地址
现在我们来安装一下(两种方式)
- 未配置环境变量–>配置环境变量HADOOP_HOME,然后重启电脑。
- 或者代码中设置System.setProperty(“hadoop.home.dir”, “hadoop安装路径”)。
我这里采用方式二
System.setProperty("hadoop.home.dir","D:\\Environment\\Hadoop\\hadoop-common-2.2.0-bin-master\\bin");
完整代码为:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Arrays;
/**
* @author: Eureka
* @date: 2022/4/27 12:06
* @Description:
*/
public class demo {
public static void main(String[] args) throws Exception {
System.setProperty("hadoop.home.dir","D:\\Environment\\Hadoop\\hadoop-common-2.2.0-bin-master");
System.setProperty("HADOOP_USER_NAME","root"); //设置访问的用户
FileSystem fs = FileSystem.get(new URI("hdfs://你的hadoop访问地址+端口号"), new Configuration(),"root");
Path homeDirectory = fs.getHomeDirectory(); //拿到hdfs的根路径
System.out.println(homeDirectory);
FileStatus[] fileStatuses = fs.listStatus(new Path("/root/data/input")); //查看指定路径下文件状态
System.out.println(Arrays.toString(fileStatuses));//打印文件
Path path = new Path("/root/data/input/log.txt");
FSDataInputStream fsDataInputStream = fs.open(path);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream));
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);//打印指定文件
}
bufferedReader.close();//关闭流
fsDataInputStream.close();
}
}
运行结果:
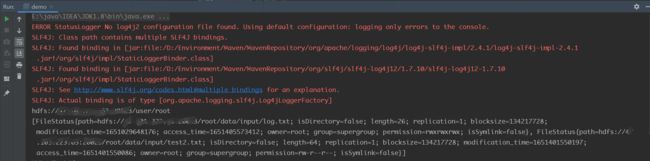
5.2 Linux端运行
在Linux端运行需要自己手动导入jar包,都在hadoop的目录下,我们可以将依赖放入jdk的lib目录下就可以使用了
hadoop-2.10.1/share/hadoop/common
hadoop-2.10.1/share/hadoop/common/bin
hadoop-2.10.1/share/hadoop/hdfs
hadoop-2.10.1/share/hadoop/hdfs/bin
这里我们只需要使用改包进行编译运行hadoop-common-2.10.1.jar
我们先找到自己jar包的路径,我的在:

现在我们可以执行以下代码了
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Arrays;
public class demo {
public static void main(String[] args) throws Exception {
FileSystem fs = FileSystem.get(new URI("hdfs://127.0.0.1:9000"), new Configuration(),"root");
Path path = new Path("/root/data/input/log.txt");
FSDataInputStream fsDataInputStream = fs.open(path);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream));
System.out.println("读取文件:" + path);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
bufferedReader.close();
fsDataInputStream.close();
}
}
先建立demo.java文件
vim demo.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Arrays;
/**
* @author: 梁峰源
* @date: 2022/4/27 12:06
* @Description: TODO
*/
public class demo {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","root");
FileSystem fs = FileSystem.get(new URI("hdfs://127.0.0.1:9000"), new Configuration(),"root");
Path homeDirectory = fs.getHomeDirectory(); //获得根文件夹
System.out.println(homeDirectory); //打印根文件夹
FileStatus[] fileStatuses = fs.listStatus(new Path("/root/data/input"));
System.out.println(Arrays.toString(fileStatuses)); //打印根文件夹下面的东西
Path path = new Path("/root/data/input/log.txt");
FSDataInputStream fsDataInputStream = fs.open(path);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream));
System.out.println("读取文件:"+path);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
bufferedReader.close();
fsDataInputStream.close();
}
}
保存退出
这里需要加载四个路径下的jar,用extCLassLoader进行加载
/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common
/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/hdfs
/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common/lib:
/usr/lib/jvm/jre-1.8.0-openjdk/lib
你要找到自己的jar路径然后像我下面一下拼接起来
使用编译命令
javac -Djava.ext.dirs=/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common:/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/hdfs:/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common/lib:/usr/lib/jvm/jre-1.8.0-openjdk/lib demo.java

运行
java -Djava.ext.dirs=/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common:/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/hdfs:/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common/lib:/usr/lib/jvm/jre-1.8.0-openjdk/lib demo

附录 hadoop常用命令
更多命令请看hadoop官方中文文档!!!!!
hadoop官方中文文档
1 hadoop fs -ls
列出指定目录下的内容,支持pattern匹配。输出格式如filename(full path)size.n代表备份数。
2 hadoop fs -lsr
递归列出该路径下所有子目录信息
3 hadoop fs -du
显示目录中所有文件大小,或者指定一个文件时,显示此文件大小
4 hadoop fs -dus
显示文件大小 相当于 linux的du -sb s代表显示只显示总计,列出最后的和 b代表显示文件大小时以byte为单位
5 hadoop fs -mv
将目标文件移动到指定路径下,当src为多个文件,dst必须为目录
6 hadoop fs -cp
拷贝文件到目标位置,src为多个文件时,dst必须是个目录
7 hadoop fs -rm [skipTrash]
删除匹配pattern的指定文件
8 hadoop fs -rmr [skipTrash]
递归删除文件目录及文件
9 hadoop fs -rmi [skipTrash]
为了避免误删数据,加了一个确认
10 hadoop fs -put <> ...
从本地系统拷贝到dfs中
11 hadoop fs -copyFromLocal...
从本地系统拷贝到dfs中,与-put一样
12 hadoop fs -moveFromLocal ...
从本地系统拷贝文件到dfs中,拷贝完删除源文件
13 hadoop fs -get [-ignoreCrc] [-crc]
从dfs中拷贝文件到本地系统,文件匹配pattern,若是多个文件,dst必须是个目录
14 hadoop fs -getmerge
从dfs中拷贝多个文件合并排序为一个文件到本地文件系统
15 hadoop fs -cat
输出文件内容
16 hadoop fs -copyTolocal [-ignoreCre] [-crc]
与 -get一致
17 hadoop fs -mkdir
在指定位置创建目录
18 hadoop fs -setrep [-R] [-w]
设置文件的备份级别,-R标志控制是否递归设置子目录及文件
19 hadoop fs -chmod [-R] ,MODE]...|OCTALMODE>PATH
修改文件权限, -R递归修改 mode为a+r,g-w,+rwx ,octalmode为755
20 hadoop fs -chown [-R] [OWNER][:[GROUP]] PATH
递归修改文件所有者和组
21 hadoop fs -count[q]
统计文件个数及占空间情况,输出表格列的含义分别为:DIR_COUNT.FILE_COUNT.CONTENT_SIZE.FILE_NAME,如果加-q 的话,还会列出QUOTA,REMAINING_QUOTA,REMAINING_SPACE_QUOTA
Hadoop fs –test –[ezd] PATH 对PATH进行如下类型的检查:-e PATH是否存在,如果PATH存在,返回0,否则返回1;-z 文件是否为空,如果长度为0,返回0,否则返回1; -d 是否为目录,如果PATH为目录,返回0,否则返回1