大数据技术原理与应用
大数据技术原理与应用
第一篇 大数据基础
第一章 大数据概述
1.1 信息化浪潮
| 信息化浪潮 | 发生时间 | 标志 | 解决问题 | 代表企业 |
|---|---|---|---|---|
| 第一次浪潮 | 1980年前后 | 个人计算机 | 信息处理 | Intel、AMD、IBM、苹果、微软、联想、戴尔、惠普等 |
| 第二次浪潮 | 1995年前后 | 互联网 | 信息传输 | 雅虎、谷歌、阿里巴巴、百度、腾讯等 |
| 第三次浪潮 | 2010年前后 | 物联网、云计算和大数据 | 信息爆炸 | 将涌现出一批新的市场标杆企业 |
1.2 技术支撑
存储设备容量不断增加、CPU处理能力大幅提升、网络带宽不断增加
1.3 数据产生阶段
运营式系统阶段、用户原创内容阶段、感知式系统阶段
1.4 大数据发展三个阶段
| 阶段 | 时间 | 内容 |
|---|---|---|
| 第一阶段:萌芽期 | 上世纪90年代至本世纪初 | 随着数据挖掘理论和数据库技术的逐步成熟,一批商业智能工具和知识管理技术开始被应用,如数据仓库、专家系统、知识管理系统等。 |
| 第二阶段:成熟期 | 本世纪前十年 | Web2.0应用迅猛发展,非结构化数据大量产生,传统处理方法难以应对,带动了大数据技术的快速突破,大数据解决方案逐渐走向成熟,形成了并行计算与分布式系统两大核心技术,谷歌的GFS和MapReduce等大数据技术受到追捧,Hadoop平台开始大行其道 |
| 第三阶段:大规模应用期 | 2010年以后 | 大数据应用渗透各行各业,数据驱动决策,信息社会智能化程度大幅提高 |
1.5 大数据特点
数据量大、数据类型繁多、处理速度快、价值密度低
1.6 大数据特征
(对思维方式的影响):全样而非抽样、效率而非精确、相关而非因果
1.7 四种范式
实验科学、理论科学、计算科学、数据密集型科学
1.8 大数据技术不同层面及其功能
| 技术层面 | 功能 |
|---|---|
| 数据采集 | 利用ETL工具将分布的、异构数据源中的数据如关系数据、平面数据文件等,抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础;或者也可以把实时采集的数据作为流计算系统的输入,进行实时处理分析 |
| 数据存储和管理 | 利用分布式文件系统、数据仓库、关系数据库、NoSQL数据库、云数据库等,实现对结构化、半结构化和非结构化海量数据的存储和管理 |
| 数据处理与分析 | 利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析;对分析结果进行可视化呈现,帮助人们更好地理解数据、分析数据 |
| 数据隐私和安全 | 在从大数据中挖掘潜在的巨大商业价值和学术价值的同时,构建隐私数据保护体系和数据安全体系,有效保护个人隐私和数据安全 |
1.9 两大核心技术
分布式存储
- GFS\HDFS
- BigTable\HBase
- NoSQL(键值、列族、图形、文档数据库)
- NewSQL(如:SQL Azure)
分布式处理
- MapReduce
1.10 大数据计算模式
| 大数据计算模式 | 解决问题 | 代表产品 |
|---|---|---|
| 批处理计算 | 针对大规模数据的批量处理 | MapReduce、Spark等 |
| 流计算 | 针对流数据的实时计算 | Storm、S4、Flume、Streams、Puma、DStream、Super Mario、银河流数据处理平台等 |
| 图计算 | 针对大规模图结构数据的处理 | Pregel、GraphX、Giraph、PowerGraph、Hama、GoldenOrb等 |
| 查询分析计算 | 大规模数据的存储管理和查询分析 | Dremel、Hive、Cassandra、Impala等 |
1.11 大数据、云计算、物联网的关系
- 云计算为大数据提供了技术基础,大数据为云计算提供用武之地
- 云计算为互联网提供海量数据存储能力,物联网为云计算提供广阔的应用空间
- 物联网是大数据的重要来源,大数据技术为物联网数据分析提供支撑
1.12 云计算概念
- 云计算实现了通过网络提供可伸缩的、廉价的分布式计算能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源
1.13 云计算的服务模式和类型

1.14 云计算关键技术
- 虚拟化
- 分布式存储
- 分布式计算
- 多租户
1.14 物联网概念
- 物联网是物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、机器、人员和物等通过新的方式联在一起,形成人与物、物与物相联,实现信息化和远程管理控制
1.15 物联网体系架构
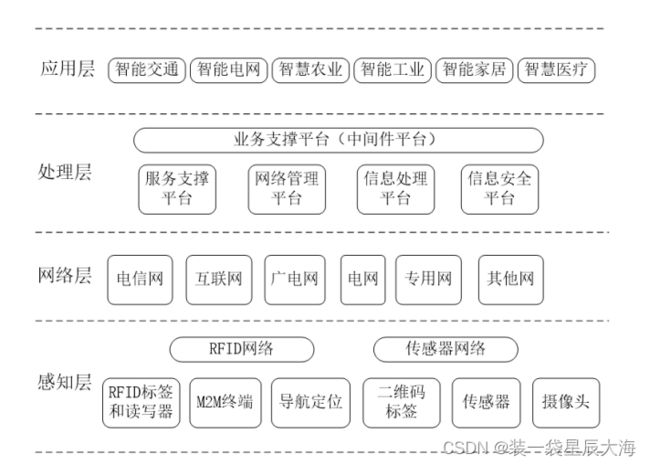
1.16 物联网关键技术
- 识别和感知技术(二维码、RFID、传感器等)、网络与通信技术、数据挖掘与融合技术等
1.17 物联网产业链
核心感应器件提供商、感知层末端设备提供商、网络提供商、软件与行业解决方案提供商、系统集成商、运营及服务提供商等六大环节

1.18 物联网特征
- 全面感知、可靠传输、智能处理
1.19 大数据思维
- 训练模型(特征)+多类型机器学习算法(权重)+数据来源广度性
第二章 大数据处理架构Hadoop
2.1 Hadoop简介
- Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
- Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中
- Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce
- Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力
- 几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop
2.2 Hadoop的特性
- 高可靠性
- 高效性
- 高可扩展性
- 高容错性
- 成本低
- 运行在Linux平台上
- 支持多种编程语言
2.3 Hadoop企业应用架构
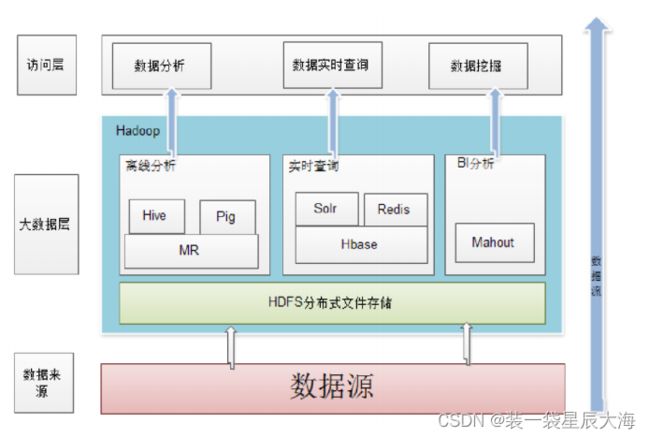
2.4 项目结构

| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式并行编程模型 |
| YARN | 资源管理和调度器 |
| Tez | 运行在YARN之上的下一代Hadoop查询处理框架 |
| Hive | Hadoop上的数据仓库 |
| HBase | Hadoop上的非关系型的分布式数据库 |
| Pig | 一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie | Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Spark | 类似于Hadoop MapReduce的通用并行框架 |
2.5 三种Shell命令方式区别
- hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
- hadoop dfs只能适用于HDFS文件系统
- hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
2.6 Hadoop框架核心
- 海量数据提供存储的HDFS
- 对数据进行计算的MapReduce
MapReduce的作业
- 从磁盘或从网络读取数据,即IO密集工作
- 计算数据,即CPU密集工作
Hadoop集群节点
- NameNode:负责协调集群中的数据存储
- DataNode:存储被拆分的数据块
- JobTracker:协调数据计算任务
- TaskTracker:负责执行由JobTracker指派的任务
- SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
2.6 Hadoop 1.0
- HDFS+MapReduce
- Hadoop 2.0包含HDFS Federation和YARN两个系统
2.7 Hadoop 的配置文件
- 位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml (Hadoop core的配置项,如HDFS和MapReduce常用的I/O设置等)和 hdfs-site.xml (Hadoop守护进程的配置项,包括NameNode、SecondaryNameNode和DataNode等)
2.8 修改配置文件
hdfs-site.xml:
- dfs.namenode.name.dir表示本地磁盘目录,是存储fsimage文件的地方;
- dfs.datanode.data.dir表示本地磁盘目录,HDFS数据存放block的地方
第二篇 大数据存储与管理
第三章 分布式文件系统HDFS
3.1 计算机集群结构
- 分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群
- 与之前使用多个处理器和专用高级硬件的并行化处理装置不同的是,目前的分布式文件系统所采用的计算机集群,都是由普通硬件构成的,这就大大降低了硬件上的开销
3.2 分布式文件系统结构
- 分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)

3.3 HDFS实现目标
- 兼容廉价的硬件设备
- 流数据读写
- 大数据集
- 简单的文件模型
- 强大的跨平台兼容性
3.4 HDFS应用局限性
- 不适合低延迟数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件
3.5 HDFS提高磁盘读写效率
- 提高读写效率,以块作为单位,而非字节。机械硬盘寻址时间非常耗时。以块为单位读写数据,实现将寻址时间分摊到大量数据中。
- HDFS默认一个块64MB,一个文件被分成多个块,以块作为存储单位,块的大小远远大于普通文件系统,目的是最小化寻址开销。
HDFS采用抽象的块概念,可以带来以下几个明显的好处:
- 支持大规模文件存储:文件以块为单位进行存储,一个大规模文件可以被分拆成若干个文件块,不同的文件块可以被分发到不同的节点上,因此,一个文件的大小不会受到单个节点的存储容量的限制,可以远远大于网络中任意节点的存储容量
- 简化系统设计:首先,大大简化了存储管理,因为文件块大小是固定的,这样就可以很容易计算出一个节点可以存储多少文件块;其次,方便了元数据的管理,元数据不需要和文件块一起存储,可以由其他系统负责管理元数据
- 适合数据备份:每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性
同时,块的大小不宜设置过大,因为MapReduce中的Map任务只处理一个块中的数据,如果启动的任务太少,会降低作业并行处理速度。
原因
- 是为了最小化寻址开销,HDFS设置的要远远大于普通文件系统,在处理大规模文件系统的时可以获得更好的性能
- 块的大小不宜过小,MapReduce中的Map任务一次只处理一个块中的数据
3.6 名称节点和数据节点
3.6.1 名称节点
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog
- FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据,FsImage文件包含文件系统中所有目录和文件inode的序列化形式。每个inode是一个文件或目录的元数据的内部表示,并包含此类信息:文件的复制等级、修改和访问时间、访问权限、块大小以及组成文件的块。对于目录,则存储修改时间、权限和配额元数据。FsImage文件没有记录块存储在哪个数据节点。而是由名称节点把这些映射保留在内存中,当数据节点加入HDFS集群时,数据节点会把自己所包含的块列表告知给名称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的。
- 操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作
名称节点记录了每个文件中各个块所在的数据节点的位置信息,收集名称节点的状态信息
数据结构
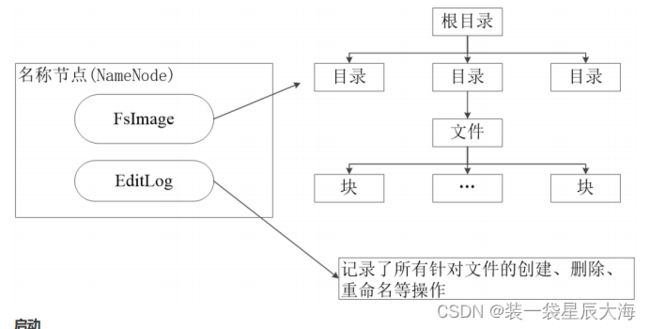
启动
- 在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
- 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件
- 名称节点起来之后,HDFS中的更新操作会重新写到EditLog文件中
3.6.2 第二名称节点
- 第二名称节点是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是单独运行在一台机器上
- 解决名称节点运行期间EditLog不断变大的问题
- (冷备份,检查点)功能:可以完成F和E的合并操作,减小E文件大小,缩短名称节点重启时间;可以作为名称节点的检查点,保存名称节点的元数据信息。
作用:
- 合并EditLog和FsImage,减小EditLog大小
- 作为名称节点的检查点(不是热备份)
合并过程:
- 第二名称节点请求名称节点停止使用EditLog文件,名称节点暂时使用EditLog.new文件;
- 第二名称节点把FsImage和EditLog拉回本地,加载到内存;
- 在内存中逐条执行EditLog中的操作并写入FsImage中;④合并结束把最新的FsImage.ckpt发送到名称节点;⑤名称节点收到后,用FSImage.ckpt替换旧的FsImage,并且命名为FsImage,用EditLog.new替换EditLog,并且命名为EditLog。
用途:
- 主要是防止日志文件 EditLog 过大,导致名称节点失败恢复时消耗过多时间;不是热备份,附带起到冷备份功能
- 第二名称节点(Secondary NameNode)是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS元数据信息的冷备份,并减少名称节点重启的时间。
3.6.3 数据节点
- 数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
- 每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中
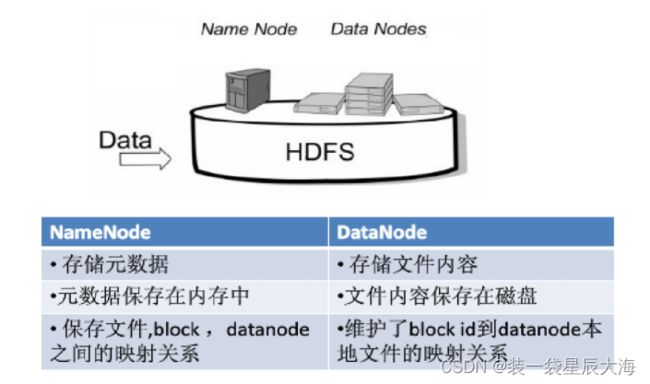
主节点”(Master Node)“名称结点”(NameNode),负责文件和目录的创建、删除和重命名,同时管理者数据节点和文件块的映射关系
从节点”(Slave Node)或者也被称为“数据节点”(DataNode),负责数据的读写和存储
分布式文件系统是针对大规模存储而设计的,过小会影响系统的扩展和性能
| NameNode | DataNode |
|---|---|
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘 |
| 保存文件,block,datanode之间的映射关系 | 维护了block id到datanode本地文件的映射关系 |
3.7 HDFS体系结构
- HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)
- 名称节点:作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。
- 集群中的数据节点:一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。
- 每个数据节点的数据会被保存在各地的Linux文件中,HDFS只有唯一一个名称节点
3.8 HDFS命名空间
- 包含目录、文件和块。整个 HDFS 只有一个命名空间,一个名称节点,名称节点负责管理命名空间,使用传统的分级文件体系。
3.9 HDFS体系结构局限性
- 命名空间的限制(名称节点是保存在内存中的,因此,名称节点能够容纳的对象(文件、块)的个数会受到内存空间大小的限制)
- 性能的瓶颈(整个分布式文件系统的吞吐量,受限于单个名称节点的吞吐量)
- 隔离问题(由于集群中只有一个名称节点,只有一个命名空间,因此,无法对不同应用程序进行隔离)
- 集群的可用性(一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用)
3.10 HDFS存储原理
3.10.1 冗余数据保存
- 作为一个分布式文件系统,为了保证系统的容错性和可用性,HDFS采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同的数据节点上
多副本方式优点
- 加快数据传输速度
- 容易检查数据错误
- 保证数据可靠性

3.10.2 数据存取策略
数据存放
- 第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
- 第二个副本:放置在与第一个副本不同的机架的节点上
- 第三个副本:与第一个副本相同机架的其他节点上
- 更多副本:随机节点,集群中随机存放
数据读取
- HDFS提供了一个API可以确定一个数据节点所属的机架ID,客户端也可以调用API获取自己所属的机架ID
- 从名称节点获取数据块不同副本的存放位置列表(数据节点信息),客户端调用 API 获取它自己的机架 ID 以及这些数据节点的机架 ID,若发现某个数据块副本对应的机架 ID 和客户端对应的机架 ID 相同时,就优先选择该副本读取数据,如果没有发现,就随机选择一个副本读取数据
3.10.3 数据错误与恢复
名称节点出错
- 名称节点保存了所有的元数据信息,其中,最核心的两大数据结构是FsImage和Editlog,如果这两个文件发生损坏,那么整个HDFS实例将失效。因此,HDFS设置了备份机制,把这些核心文件同步复制到备份服务器SecondaryNameNode上。当名称节点出错时,就可以根据备份服务器SecondaryNameNode中的FsImage和Editlog数据进行恢复。
名称节点失效
- 使用第二名称节点,当名称节点出错时,就可以根据第二名称节点中的FsImage 和 Editlog 数据进行恢复,但会丢失 EditLog.new 中的数据(合并期间)
数据节点失效
- 由于一些数据节点的不可用,会导致一些数据块的副本数量小于冗余因子,名称节点会定期检查这种情况,一旦发现某个数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本(可以调整冗余数据的位置)
数据节点出错
- 每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态
- 当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自一些数据节点的心跳信息,这时,这些数据节点就会被标记为“宕机”,节点上面的所有数据都会被标记为“不可读”,名称节点不会再给它们发送任何I/O请求
- 这时,有可能出现一种情形,即由于一些数据节点的不可用,会导致一些数据块的副本数量小于冗余因子
- 名称节点会定期检查这种情况,一旦发现某个数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本
- HDFS和其它分布式文件系统的最大区别就是可以调整冗余数据的位置
数据出错
- 网络传输和磁盘错误等因素,都会造成数据错误
- 客户端在读取到数据后,会采用md5和sha1对数据块进行校验,以确定读取到正确的数据
- 在文件被创建时,客户端就会对每一个文件块进行信息摘录,并把这些信息写入到同一个路径的隐藏文件里面
- 当客户端读取文件的时候,会先读取该信息文件,然后,利用该信息文件对每个读取的数据块进行校验,如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块
3.11 HDFS数据读写
- FileSystem是一个通用文件系统的抽象基类,可以被分布式文件系统继承,所有可能使用Hadoop文件系统的代码,都要使用这个类
- Hadoop为FileSystem这个抽象类提供了多种具体实现
- DistributedFileSystem就是FileSystem在HDFS文件系统中的具体实现
- FileSystem的open()方法返回的是一个输入流FSDataInputStream对象,在HDFS文件系统中,具体的输入流就是DFSInputStream;FileSystem中的create()方法返回的是一个输出流FSDataOutputStream对象,在HDFS文件系统中,具体的输出流就是DFSOutputStream。
从HDFS读数据
①加载配置文件,生成 FileSystem 对象,根据文件名调用 open 方法创建 FSDataInputStream 类型的输入流 in;
②输入流 in 远程 RPC 调用名称节点,获得文件开始部分数据块所有副本位置(根据和客户端的距离排序);
③输入流 in 选择距离最近的数据节点建立连接并且 in.read 读取数据,读完后断开连接;
④输入流 in 通过getBlockLocations 查找下一数据块(客户端已缓存则不用调用);
⑤重复上述找最佳数据块、建立连接、读取数据块、读完断开连接的过程;
⑥客户端读完数据,输入流 in 调用close 关闭输入流。
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FSDataInputStream getIt = fs.open(new Path("test"));
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
System.out.println(d.readLine());
d.close(); fs.close();
从HDFS写数据
①加载配置文件,生成 FileSystem 对象,根据文件名调用 create 方
法创建 FSDataOutputStream 类型的输入流 out;
②输入流 out 远程 RPC 调用名称节点,名称节点构造新文件,添加文件信息,并且写在 EditLog 里;
③客户端通过输出流 out.write向 HDFS 写入数据;
④输出流 out 中的数据被分成一个个分包,放入输出流 out 的DFSOutputStream 类型的对象的内部队列,然后输出流 out 向名称节点申请保存文件和副本数据块的若干数据节点,这些数据节点形成一个数据流管道,按照流水线复制策略依次发送;
⑤收到数据的节点向发送方发送确认包,它们沿着流水线逆流而上,经过各个数据节点发回客 户端 ,客 户端收到确认包以后 ,就将对应的 分包从输出流 out 的DFSOutputStream 类型的对象的内部队列中移除;
⑥客户端通过输出流 out.close 关闭输出流,当输出流 out 的DFSOutputStream 类型的对象的内部队列中的所有分包收到却分包以后,ClientProtocl.complete 通知名称节点关闭文件。
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
byte[] buff = "Hello world".getBytes(); String filename = "test";
FSDataOutputStream os = fs.create(new Path(filename));
os.write(buff,0,buff.length); System.out.println("Create:"+ filename);
os.close(); fs.close();
- 上传本地文件至HDFS上的目录下:hdfs dfs -put 本地文件目录 HDFS文件目录
- 下载HDFS上的文件至本地目录中:hdfs dfs -get HDFS文件目录 本地文件目录
- 查看HDFS上文件:hdfs dfs -cat HDFS文件路径
- 查看HDFS目录中的文件名:hdfs dfs -ls HDFS目录路径
判断文件是否存在
String fileName = "test";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(fileName)))
System.out.println("文件存在");
else
System.out.println("文件不存在");
HDFS默认冗余因子为3,两份副本放在同一个机架的不同机器,第三个放在不同机架的机器上
3.12 HDFS通信协议
- 通过网络传输,建立在 TCP/IP 上;客户端向名称节点发起 TCP 连接,使用客户端协议;名称节点和数据节点间菜蔬数据节点协议;客户端与数据节点通过 RPC通信,它是响应来自客户端和数据节点的 RPC 请求
第四章 分布式数据库HBase
4.1 BigTable
- BigTable是一个分布式存储系统
- 利用谷歌提出的MapReduce分布式并行计算模型来处理海量数据
- 使用谷歌分布式文件系统GFS作为底层数据存储
- 采用Chubby提供协同服务管理
- 可以扩展到PB级别的数据和上千台机器,具备广泛应用性、可扩展性、高性能和高可用性等特点
4.2 HBase简介
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。Hbase不支持事务
HBase和BigTable的底层技术对应关系
| ** **BigTable | HBase | |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同服务管理 | Chubby | Zookeeper |
4.3HBase与传统关系数据库区别
- 数据类型(关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase则采用了更加简单的数据模型,它把数据存储为未经解释的字符串)
- 数据操作(关系数据库中包含了丰富的操作,其中会涉及复杂的多表连接。HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为HBase在设计上就避免了复杂的表和表之间的关系)
- 存储模式(关系数据库是基于行模式存储的。HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的)
- 数据索引(关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。HBase只有一个索引——行键,通过巧妙的设计,HBase中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来)
- 数据维护(在关系数据库中,更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留)
- 可伸缩性(关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反,HBase和BigTable这些分布式数据库就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩)
4.4 HBase访问接口
| 类型 | 特点 | 场合 |
|---|---|---|
| Native Java API | 最常规和高效的访问方式 | 适合Hadoop MapReduce作业并行批处理HBase表数据 |
| HBase Shell | HBase的命令行工具,最简单的接口 | 适合HBase管理使用 |
| Thrift Gateway | 利用Thrift序列化技术,支持C++、PHP、Python等多种语言 | 适合其他异构系统在线访问HBase表数据 |
| REST Gateway | 解除了语言限制 | 支持REST风格的Http API访问HBase |
| Pig | 使用Pig Latin流式编程语言来处理HBase中的数据 | 适合做数据统计 |
| Hive | 简单 | 当需要以类似SQL语言方式来访问HBase的时候 |
4.5 HBase数据模型相关概念
-
表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
-
行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
-
列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元
-
列限定符:列族里的数据通过列限定符(或列)来定位
-
单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
-
时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
HBase中、一个“四维坐标”,即[行键, 列族, 列限定符, 时间戳]确定一个单元格
HBase概念视图和物理视图不同,在物理视图中这些空的列不会被存储成null,而是不会被存储,当请求这些空白的单元格的时候会返回null值
HBase面向列存储
4.6 HBase功能组件
- 库函数:链接到每个客户端;
- 一个Master主服务器(Master负责管理和维护HBase表的分区信息,维护Region服务器列表,分配Region,负载均衡);
- 许多个Region服务器(每个行区间构成一个分区,被称为Region,包含了位于某个值域区间内的所有数据,他是负载均衡和数据分发的基本单位。Region服务器负责存储和维护分配给自己的Region,处理来自客户端的读写请求(Region服务器和Region不是一个概念)
- 客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据
- 客户端并不依赖Master,而是通过Zookeeper(提供分布式协调一致性服务)来获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小
4.7 Region的定位
- 一个Region标识符可以表示为:“表名+开始主键+RegionID”
4.8 HBase的三层结构
| 层次 | 名称 | 作用 |
|---|---|---|
| 第一层 | Zookeeper文件 | 记录了-ROOT-表的位置信息 |
| 第二层 | -ROOT-表 | 记录了.META.表的Region位置信息-ROOT-表只能有一个Region。通过-ROOT-表,就可以访问.META.表中的数据 |
| 第三层 | .META.表 | 记录了用户数据表的Region位置信息,.META.表可以有多个Region,保存了HBase中所有用户数据表的Region位置信息(可以保存的Region的数目是2的34次个Region) |
①Zookeeper** 组件里有一个 Zookeeper 文件,里面存放了“-ROOT-”表的地址和 Master 的地址;
②根数据表 -ROOT- 里存放了元数据表“.META.”的 Region和 Region 服务器的映射关系。这个表只能存放在一个 Region 里,不能被分割,在程序里写死的。
③元数据表“.META.里存放了用户数据表的 Region 的 Region 服务器的映射关系,会被分裂成多个 Region。
④用户数据表分割成多个 Region,由“表名+开始主键+RegionID”来标识一个 Region。为了加快访问速度,.META.表的全部 Region 都会被保存在内存中
4.9 Region服务器工作原理
用户读写数据过程
- 用户写入数据时,被分配到相应Region服务器去执行
- 用户数据首先被写入到MemStore和Hlog中
- 只有当操作写入Hlog之后,commit()调用才会将其返回给客户端
- 当用户读取数据时,Region服务器会首先访问MemStore缓存,如果找不到,再去磁盘上面的StoreFile中寻找
缓存的刷新
- 系统会周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记
- 每次刷写都生成一个新的StoreFile文件,因此,每个Store包含多个StoreFile文件
- 每个Region服务器都有一个自己的HLog 文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧的Hlog文件,开始为用户提供服务
StoreFile的合并
- 每次刷写都生成一个新的StoreFile,数量太多,影响查找速度
- 调用Store.compact()把多个合并成一个
- 合并操作比较耗费资源,只有数量达到一个阈值才启动合并
4.10 Store工作原理
- Store是Region服务器的核心
- 多个StoreFile合并成一个
- 单个StoreFile过大时,又触发分裂操作,1个父Region被分裂成两个子Region
4.11 HLog工作原理
- 分布式环境必须要考虑系统出错。HBase采用HLog保证系统恢复
- HBase系统为每个Region服务器配置了一个HLog文件,它是一种预写式日志(Write Ahead Log)
- 用户更新数据必须首先写入日志后,才能写入MemStore缓存,并且,直到MemStore缓存内容对应的日志已经写入磁盘,该缓存内容才能被刷写到磁盘
- Zookeeper会实时监测每个Region服务器的状态,当某个Region服务器发生故障时,Zookeeper会通知Master
- Master首先会处理该故障Region服务器上面遗留的HLog文件,这个遗留的HLog文件中包含了来自多个Region对象的日志记录
- 系统会根据每条日志记录所属的Region对象对HLog数据进行拆分,分别放到相应Region对象的目录下,然后,再将失效的
- Region重新分配到可用的Region服务器中,并把与该Region对象相关的HLog日志记录也发送给相应的Region服务器
- Region服务器领取到分配给自己的Region对象以及与之相关的HLog日志记录以后,会重新做一遍日志记录中的各种操作,把日志记录中的数据写入到MemStore缓存中,然后,刷新到磁盘的StoreFile文件中,完成数据恢复
- 共用日志优点:提高对表的写操作性能;缺点:恢复时需要分拆日志
4.12 构建HBase二级索引
- Coprocessor构建二级索引
- Coprocessor提供了两个实现:endpoint和observer,endpoint相当于关系型数据库的存储过程,而observer则相当于触发器
- observer允许我们在记录put前后做一些处理,因此,而我们可以在插入数据时同步写入索引表
优点:非侵入性:引擎构建在HBase之上,既没有对HBase进行任何改动,也不需要上层应用做任何妥协
缺点:每插入一条数据需要向索引表插入数据,即耗时是双倍的,对HBase的集群的压力也是双倍的
4.13 HBase和Hadoop其他组件关系
- 用 MapReduce 处理 HBase 中海量数据;用 Zookeeper实现协同服务和失败恢复;用 HDFS 作为底层存储;用 Sqoop 导入 RDBMS 数据,用 Pig和 Hive 提供高层语言支持。(HBase 的查询语言会变成 MapReduce 代码执行)
安装Hadoop步骤
①创建hadoop用户,加入sudo组
②安装SSH服务器端,配置SSH无密码登录
③安装JDK,配置环境变量java_home、jre_home、classpath、path
④安装Hadoop,修改配置文件core-site.xml(hadoop挂载目录和默认文件系统),修改配置文件hdfs-site.xml(副本数为1,主节点和数据节点的挂载目录)
⑤格式化NameNode,开启Hadoop:start-dfs.sh
- 打开HBase start-hbase.sh
- 打开Base Shell:hbase shell
- 查看HBase表的基本信息:describe 表名
- 查看当前HBase数据库创建了哪些表:list
- 向HBase表添加数据:put 表名,主键值,列名,单元格值
- 获取一个指定行键对应的所有列的值:get 表名,主键值
- 获取全表指定列或者列族的值:scan 表名,列名
- 删除单元格:delete 表名,主键值,列名
- 删除行键:deleteall 表名,主键值
- 让表不可用:disable 表名
- 删除表:drop 表名
- 创建表teacher,列族为username,所有单元格里数据版本数为5:
- create ‘teacher’,{NAME=>‘username’,VERSIONS=>5}
HBase建立连接
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase");
try{ connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
}catch (IOException e){
e.printStackTrace(); }
HBase建表
TableName tableName = TableName.valueOf(myTableName);
if(admin.tableExists(tableName)){
System.out.println("talbe is exists!");
}else {
HTableDescriptor htd = new HTableDescriptor(tableName);
for(String str:colFamily){
HColumnDescriptor hcd = new HColumnDescriptor(str);
htd.addFamily(hcd); }//for
admin.createTable(htd); }//else
HBase删除表
TableName tn = TableName.valueOf(tableName);
if (admin.tableExists(tn)) {
admin.disableTable(tn);
admin.deleteTable(tn); }
HBase查看已有表
HTableDescriptor htds[] = admin.listTables();
for(HTableDescriptor htd : htds){
System.out.println(htd.getNameAsString()); }
HBase插入数据
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(rowKey.getBytes());
put.addColumn(colFamily.getBytes(), col.getBytes(), val.getBytes());
table.put(put); table.close();
HBase删除数据
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(rowKey.getBytes());
table.delete(delete); table.close();
HBase查询数据
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(rowKey.getBytes());
get.addColumn(colFamily.getBytes(),col.getBytes());
Result result = table.get(get);
showCell(result); table.close();
- 启动Redis的客户端,为了输出中文:
- cd /usr/local/redis
- ./src/redis-cli --raw
- 显示MongoDB里的数据库:show dbs
- 创建数据库School:use School
- 显示MongoDB里的数据库:show dbs
- 创建一个集合student:db.createCollection(‘student’)
- MongoDB插入数据:
- db.student.insert({_id:1, sname: ‘zhangsan’, sage: 20})
- 格式化输出查看表数据:db.student.find().pretty()
- AND条件查询:db.student.find({sname: ‘zhangsan’, sage: 22})
- OR条件查询:db.student.find({$or: [{sage: 22}, {sage: 25}]})
- 修改数据:db.student.update({sname: ‘lisi’}, {$set: {sage: 30}}, false, true)
- 删除数据:db.student.remove({sname: ‘chenliu’})
- 删除集合:db.student.drop()
MongoDB的更新
MongoCollection collection = getCollection("School", "student");
collection.updateMany(Filters.eq("sname", "Mary"), new Document("$set", new Document("sage", 22)));
System.out.println("更新成功!");
MongoDB的插入
MongoCollection collection = getCollection("School", "student");
Document doc1 = new Document("sname", "Mary").append("sage", 25);
Document doc2 = new Document("sname", "Bob").append("sage", 20);
List documents = new ArrayList();
documents.add(doc1); documents.add(doc2);
collection.insertMany(documents); System.out.println("数据插入成功");
MongoDB的查询
MongoCollection collection = getCollection("School", "student");
MongoCursor cursor2 = collection.find().iterator();
while (cursor2.hasNext()) {
System.out.println(cursor2.next().toJson()); }//while
MongoDB的删除
MongoCollection collection = getCollection("School", "student");
collection.deleteOne(Filters.eq("sname", "Bob"));
System.out.println("删除成功!");
MongoDB的建立连接和返回集合(表)
mongoClient = new MongoClient("localhost", 27017);
MongoDatabase mongoDatabase = mongoClient.getDatabase(dbname);
MongoCollection collection = mongoDatabase.getCollection(collectionname);
return collection;
词频统计的Map逻辑
public static class TokenizerMapper extends Mapper {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {}
public void map(Object key, Text value, Mapper.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}} }
词频统计的Reduce逻辑
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable values, Reducer.Context context) throws IOException, InterruptedException {
int sum = 0; //统计单词的个数,初始为0
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum); //reduce函数的处理逻辑,求和
context.write(key, this.result);
}}
- 编译:javac WordCount.java
- 打包:jar -cvf WordCount.jar *.class
- 运行:jar WordCount.jar input output
Hive的启动
- 开启Hadoop(start-dfs.sh)
- 开启mysql(service mysql start)
- 查看mysql是否启动成功(sudo netstat -tap |grep mysql)
- 开启hive(hive)
Hive的关闭
- 关闭hive(exit)
- 关闭MySQL(service mysql stop)
- 关闭Hadoop(stop-dfs.sh)
Hive进行词频统计
create table docs(line string);
load data inpath 'hdfs://localhost:9000/input' overwrite into table docs;
create table word_count as select word, count(1) as count from
(select explode(split(line,' '))as word from docs) w
group by word order by word;
select * from word_count;
Hive的wordcount算法详解
- 查询表docs里的每一行,以空格分隔,返回结果(单词)重命名为word
- 按照word进行分组并排序,相同的word值在一个分组里,然后查询相同word值的个数
- 把word值和word个数查询出来重名为word_count表
11.为了加速寻址,客户端会缓存位置信息,把查询过的位置信息缓存起来,这样以后访问相同的数据时,就可以直接从客户端缓存中获取Region的位置信息;寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器。
12.Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
13.一个Region服务器内部管理了一系列Region对象和一个Hlog文件,每个Hlog(磁盘上面的记录文件)由多个Store组成,每个Store(对应了表中的一个列族的存储)包含了一个Memstore(是在内存中的缓存,包含了最近更新的数据)和若干个StoreFile(磁盘中的文件)。
14.所有Region对象共用一个HLog文件。
15.create:创建表;list:列出HBase中所有的表信息;put:向表、行、列指定的单元格添加数据(一次只能为一个表的一行数据的一个列添加一个数据);scan:浏览表的相关信息;get:通过表名、行、列、时间戳、时间范围和版本号来获得相应单元格的值;Alter:修改列族模式;Count:统计表中的行数;enable/disable:使表有效或无效;drop:删除表,删除某个表之前必须先使表无效;Describe:显示表的相关信息
4.14 Zookeeper使用场景
①HBase 的 Region 三级寻址;
②HDFS HA 确保同一时刻只有一个活跃的名称节点;
③Nimbus 将 Task 和 Supervisor 相关的信息提交到 Zookeeper 集群上。
第五章 NoSQL数据库
5.1 NoSQL特点
- 灵活的可扩展性
- 灵活的数据模型
- 与云计算紧密融合
5.2 关系数据库无法满足Web2.0的需求表现
- 无法满足海量数据的管理需求
- 无法满足数据高并发的需求
- 无法满足高可扩展性和高可用性的需求
5.3 NoSQL与关系数据库的比较
| 比较标准 | RDBMS | NoSQL | 备注 |
|---|---|---|---|
| 数据库原理 | 完全支持 | 部分支持 | RDBMS有关系代数理论作为基础NoSQL没有统一的理论基础 |
| 数据规模 | 大 | 超大 | RDBMS很难实现横向扩展,纵向扩展的空间也比较有限,性能会随着数据规模的增大而降低NoSQL可以很容易通过添加更多设备来支持更大规模的数据 |
| 数据库模式 | 固定 | 灵活 | RDBMS需要定义数据库模式,严格遵守数据定义和相关约束条件NoSQL不存在数据库模式,可以自由灵活定义并存储各种不同类型的数据 |
| 查询效率 | 快 | 可以实现高效的简单查询,但是不具备高度结构化查询等特性,复杂查询的性能不尽人意 | RDBMS借助于索引机制可以实现快速查询(包括记录查询和范围查询)很多NoSQL数据库没有面向复杂查询的索引,虽然NoSQL可以使用MapReduce来加速查询,但是,在复杂查询方面的性能仍然不如RDBMS |
| 一致性 | 强一致性 | 弱一致性 | RDBMS严格遵守事务ACID模型,可以保证事务强一致性很多NoSQL数据库放松了对事务ACID四性的要求,而是遵守BASE模型,只能保证最终一致性 |
| 数据完整性 | 容易实现 | 很难实现 | 任何一个RDBMS都可以很容易实现数据完整性,比如通过主键或者非空约束来实现实体完整性,通过主键、外键来实现参照完整性,通过约束或者触发器来实现用户自定义完整性但是,在NoSQL数据库却无法实现 |
| 扩展性 | 一般 | 好 | RDBMS很难实现横向扩展,纵向扩展的空间也比较有限NoSQL在设计之初就充分考虑了横向扩展的需求,可以很容易通过添加廉价设备实现扩展 |
| 可用性 | 好 | 很好 | RDBMS在任何时候都以保证数据一致性为优先目标,其次才是优化系统性能,随着数据规模的增大,RDBMS为了保证严格的一致性,只能提供相对较弱的可用性大多数NoSQL都能提供较高的可用性 |
5.4关系数据库
- 优势:以完善的关系代数理论作为基础,有严格的标准,支持事务ACID四性,借助索引机制可以实现高效的查询,技术成熟,有专业公司的技术支持。(互联网企业,传统企业的非关键业务)
- 劣势:可扩展性较差,无法较好支持海量数据存储,数据模型过于死板、无法较好支持Web2.0应用,事务机制影响了系统的整体性能等
5.5 NoSQL数据库
- 优势:可以支持超大规模数据存储,灵活的数据模型可以很好地支持Web2.0应用,具有强大的横向扩展能力等(电信银行等)
- 劣势:缺乏数学理论基础,复杂查询性能不高,大都不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难
5.6 NoSQL四大类型
- 键值数据库
- 列族数据库
- 文档数据库
- 图数据库(图数据结构的一数据库)
5.7 不同类型数据库比较
- MySQL产生年代较早,而且随着LAMP大潮得以成熟。尽管其没有什么大的改进,但是新兴的互联网使用的最多的数据库
- MongoDB是个新生事物,提供更灵活的数据模型、异步提交、地理位置索引等五花十色的功能
- HBase是个“仗势欺人”的大象兵。依仗着Hadoop的生态环境,可以有很好的扩展性。但是就像象兵一样,使用者需要养一头大象(Hadoop),才能驱使他
- Redis是键值存储的代表,功能最简单。提供随机数据存储。就像一根棒子一样,没有多余的构造。但是也正是因此,它的伸缩性特别好。就像悟空手里的金箍棒,大可捅破天,小能成缩成针
5.8 NoSQL三大基石
- CAP
- BASE
- 最终一致性
C:一致性,是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的,或者说,所有节点在同一时间具有相同的数据。
A:可用性,是指快速获取数据,可以在确定的时间内返回操作结果,保证每个请求不管成功或者失败都有响应。
P:分区容忍性,是指当出现网络分区的情况时分离的系统也能够正常运行,也就是说,系统中任意信息的丢失或失败不会影响系统的继续运作。
处理CAP的问题时,可以有几个明显的选择
- CA:也就是强调一致性(C)和可用性(A),放弃分区容忍性(P),最简单的做法是把所有与事务相关的内容都放到同一台机器上。很显然,这种做法会严重影响系统的可扩展性。传统的关系数据库(MySQL、SQL Server和PostgreSQL),都采用了这种设计原则,因此,扩展性都比较差
- CP:也就是强调一致性(C)和分区容忍性(P),放弃可用性(A),当出现网络分区的情况时,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务
- AP:也就是强调可用性(A)和分区容忍性(P),放弃一致性(C),允许系统返回不一致的数据
5.9 BASE的ACID
| ACID | BASE |
|---|---|
| 原子性(Atomicity) | 基本可用(Basically Available) |
| 一致性(Consistency) | 软状态/柔性事务(Soft state) |
| 隔离性(Isolation) | 最终一致性 (Eventual consistency) |
| 持久性 (Durable) |
- A:原子性,是指事务必须是原子工作单元,对于其数据修改,要么全都执行,要么全都不执行
- C:一致性,是指事务在完成时,必须使所有的数据都保持一致状态
- I:隔离性,是指由并发事务所做的修改必须与任何其它并发事务所做的修改隔离
- D:持久性,是指事务完成之后,它对于系统的影响是永久性的
- 基本可用,是指一个分布式系统的一部分发生问题变得不可用时,其他部分仍然可以正常使用,也就是允许分区失败的情形出现
- “软状态(soft-state)”是与“硬状态(hard-state)”相对应的一种提法。数据库保存的数据是“硬状态”时,可以保证数据一致性,即保证数据一直是正确的。“软状态”是指状态可以有一段时间不同步,具有一定的滞后性
- 最终一致性,一致性的类型包括强一致性和弱一致性,二者的主要区别在于高并发的数据访问操作下,后续操作是否能够获取最新的数据。对于强一致性而言,当执行完一次更新操作后,后续的其他读操作就可以保证读到更新后的最新数据;反之,如果不能保证后续访问读到的都是更新后的最新数据,那么就是弱一致性。而最终一致性只不过是弱一致性的一种特例,允许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,必须最终读到更新后的数据。最常见的实现最终一致性的系统是DNS(域名系统)。一个域名更新操作根据配置的形式被分发出去,并结合有过期机制的缓存;最终所有的客户端可以看到最新的值。
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以区分为:
- 因果一致性:如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将获得A写入的最新值。而与进程A无因果关系的进程C的访问,仍然遵守一般的最终一致性规则
- “读己之所写”一致性:可以视为因果一致性的一个特例。当进程A自己执行一个更新操作之后,它自己总是可以访问到更新过的值,绝不会看到旧值
- 单调读一致性:如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值
- 会话一致性:它把访问存储系统的进程放到会话(session)的上下文中,只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统保证不会延续到新的会话
- 单调写一致性:系统保证来自同一个进程的写操作顺序执行。系统必须保证这种程度的一致性,否则就非常难以编程了
5.10 MongoDB主要特点
- 提供了一个面向文档存储,操作起来比较简单和容易
- 可以设置任何属性的索引来实现更快的排序
- 具有较好的水平可扩展性
- 支持丰富的查询表达式,可轻易查询文档中内嵌的对象及数组
- 可以实现替换完成的文档(数据)或者一些指定的数据字段
- MongoDB中的Map/Reduce主要是用来对数据进行批量处理和聚合操作
- 支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等语言
- MongoDB安装简单
第六章 云数据库 x
第三篇 大数据处理与分析
第七章 MapReduce
7.1 并行计算框架对比
| ** ** | 传统并行计算框架 | MapReduce |
|---|---|---|
| 集群架构/容错性 | 例如HPC,共享式(共享内存/共享存储)及硬件之间高耦合,容错性差 | 非共享式,容错性好 |
| 硬件/价格/扩展性 | 刀片服务器、高速网、SAN(存储区域网络),价格贵,扩展性差 | 普通PC机,便宜,扩展性好 |
| 编程/学习难度 | what-how,难 | what,简单 |
| 适用场景 | 实时、细粒度计算、计算密集型 | 批处理、非实时、数据密集型 |
7.2 MapReduce模型简介
- MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce
- 编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算
- MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
- MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为,移动数据需要大量的网络传输开销
- MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker,Slave上运行TaskTracker
- Hadoop框架是用Java实现的,但是,MapReduce应用程序则不一定要用Java来写
7.3 MapReduce体系结构
- MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
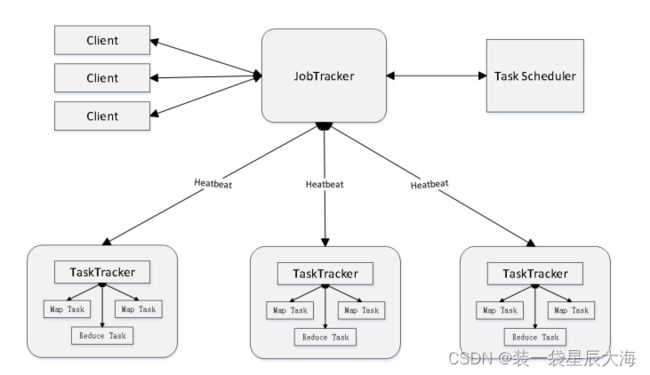
1)Client
- 用户编写的MapReduce程序通过Client提交到JobTracker端
- 用户可通过Client提供的一些接口查看作业运行状态
2)JobTracker
- JobTracker负责资源监控和作业调度
- JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
- JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在TaskTracker资源出现空闲时,选择合适的任务去使用这些资源
3)TaskTracker
- TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
- TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用
4)Task
- Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
7.4 MapReduce工作流程

- 不同的Map任务之间不会进行通信
- 不同的Reduce任务之间也不会发生任何信息交换
- 所有的数据交换都是通过MapReduce框架自身去实现的
7.5 Split分片

- HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其处理单位是split。split 是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定
7.6 Map任务数量
- Hadoop为每个split创建一个Map任务,split 的多少决定了Map任务的数目。大多数情况下,理想的分片大小是一个HDFS块
7.7 Reduce任务数量
- 最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目
- 通常设置比reduce任务槽数目稍微小一些的Reduce任务个数(这样可以预留一些系统资源处理可能发生的错误)
7.8 Shuffle过程

Map端Shuffle过程
①分区partition
②写入环形内存缓冲区
③执行溢出写
排序sort—>合并combiner—>生成溢出写文件
④归并merge

- 每个Map任务分配一个缓存
- MapReduce默认100MB缓存
- 设置溢写比例0.8
- 分区默认采用哈希函数(hash(key)modR)
- 排序是默认的操作
- 排序后可以合并(Combine)
- 合并不能改变最终结果
- 在Map任务全部结束之前进行归并
- 归并得到一个大的文件,放在本地磁盘
- 文件归并时,如果溢写文件数量大于预定值(默认是3)则可以再次启动合并,少于3不需要
- JobTracker会全程监控map任务的执行情况
合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>
如果归并,会得到<“a”,<1,1>>
Reduce端的Shuffle过程
①复制copy
②归并merge
③reduce

- Reduce任务通过RPC向JobTracker询问Map任务是否已经完成,若完成,则领取数据
- Reduce将领取到的数据先放入缓存,来自不同Map节点,先归并,再合并,写入磁盘
- 多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
- 当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce
(1) Reduce端的Shuffle过程----领取数据
(2) Reduce端的Shuffle过程----把数据输入给Reduce任务
(3) Reduce端的Shuffle过程----把数据输入给Reduce任务

7.9 WordCount设计思路
- 首先,需要检查WordCount程序任务是否可以采用MapReduce来实现。适合用MapReduce来处理的数据集需要满足一个前提条件:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。在WordCount程序任务中,不同单词之间的频数不存在相关性,彼此独立,可以把不同的单词分发给不同的机器进行并行处理,因此可以采用MapReduce来实现词频统计任务。
- 其次,确定MapReduce程序的设计思路。把文件内容解析成许多个单词,然后把所有相同的单词聚集到一起,最后计算出每个单词出现的次数并输出。
- 最后,确定MapReduce程序的执行过程。把一个大文件切分成许多个分片,每个分片输入给不同机器上的 Map 任务,并行执行完成“从文件中解析出所有单词”的任务。Map 的输入采用Hadoop默认的
7.10 MapReduce具体应用
MapReduce可以很好地应用于各种计算问题
- 关系代数运算(选择、投影、并、交、差、连接)
- 分组与聚合运算
- 矩阵-向量乘法
- 矩阵乘法
用MapReduce实现关系的选择运算
- 对于关系的选择运算,只需要Map过程就能实现,对于关系R中的每个元组t,检测其是否满足条件的所需元组,如果满足条件,则输出键值对
用MapReduce实现关系的自然连接
7.11 MapReduce执行阶段
- MapReduce 框架使用 InputFormat 模块作 Map 前的预处理;
- 将输入文件切分为逻辑上的多个 InputSplit,是 Map 的输入单位,只记录了数据的位置和长度;
- 通过 RecordReader 根据 InputSplit 中的信息处理 InputSplit 中的记录;
- 加载数据转为键值对输入给 Map 任务;
- Map 任务根据用户自定义的逻辑拆分为一系列的
- Shuffle,分区、排序、合并、归并,得到
- Reduce 从不同的 map 节点读取
- 结果通过OutputFormat 模块,写入 HDFS
第八章 Hadoop再探讨
8.1 Hadoop的局限与不足
Hadoop1.0的核心组件(仅指MapReduce和 HDFS ,不包括Hadoop生态系统内的Pig · Hive 、 HBase 等其他组件)主要存在以下不足:
- 抽象层次低,需人工编码
- 表达能力有限
- 开发者自己管理作业(Job)之间的依赖关系
- 难以看到程序整体逻辑
- 执行迭代操作效率低
- 资源浪费(Map和 Reduce分两阶段执行)
- 实时性差 (适合批处理,不支持实时交互式)
8.2 针对Hadoop的改进与提升
Hadoop的优化与发展主要体现在两个方面:
- 一方面是 Hadoop自身两大核心组件MapReduce和HDFS的架构设计改进
- 另一方面是Hadoop生态系统其它组件的不断丰富,加入了Pig 、Tez 、Spark和 Kafka等新组件
Hadoop框架自身的改进:从1.0到2.0
| 组件 | Hadoop1.0****的问题 | Hadoop2.0****的改进 |
|---|---|---|
| HDFS | 单一名称节点,存在单点失效问题 | 设计了HDFS HA,提供名称节点热备机制 |
| HDFS | 单一命名空间,无法实现资源隔离 | 设计了HDFS 联邦,管理多个命名空间 |
| MapReduce | 资源管理效率低 | 设计了新的资源管理框架YARN |
HDFS联邦
解决以下三个问题
- 命名服务不可以水平扩展
- 系统整体性能受限于单个名称节点的吞吐量
- 单个名称节点难以提供不同程序之间的隔离性
不断完善的Hadoop生态系统
| 组件 | 功能 | 解决Hadoop中存在的问题 |
|---|---|---|
| Pig | 处理大规模数据的脚本语言,用户只需要编写几条简单的语句,系统会自动转换为MapReduce作业 | 抽象层次低,需要手工编写大量代码 |
| Spark | 基于内存的分布式并行编程框架,具有较高的实时性,并且较好支持迭代计算 | 延迟高,而且不适合执行迭代计算 |
| Oozie | 工作流和协作服务引擎,协调Hadoop上运行的不同任务 | 没有提供作业(Job)之间依赖关系管理机制,需要用户自己处理作业之间依赖关系 |
| Tez | 支持DAG作业的计算框架,对作业的操作进行重新分解和组合,形成一个大的DAG作业,减少不必要操作 | 不同的MapReduce任务之间存在重复操作,降低了效率 |
| Kafka | 分布式发布订阅消息系统,一般作为企业大数据分析平台的数据交换枢纽,不同类型的分布式系统可以统一接入到Kafka,实现和Hadoop各个组件之间的不同类型数据的实时高效交换 | Hadoop生态系统中各个组件和其他产品之间缺乏统一的、高效的数据交换中介 |
8.3 HDFS2.0新特征-HDFS HA
HDFS HA:为了解决单点故障问题,提供热备份
HDFS1.0组件及其功能回顾名称节点保存元数据:
- 在磁盘上: Fslmage和 EditLog
- 在内存中:映射信息,即文件包含哪些块,每个块存储在哪个数据节点
-
HDFS 1.0存在单点故障问题
-
第二名称节点(SecondaryNameNode )无法解决单点故障问题
-
第二名称节点用途
-
主要是防止日志文件EditLog过大,导致名称节点失败恢复时消耗过多时间
-
不是热备份,附带起到冷备份功能
-

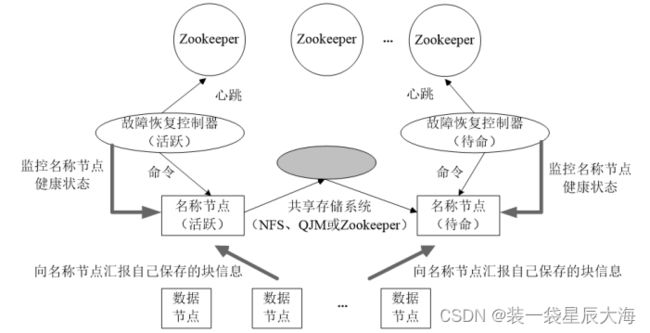
- HDFS HA ( High Availability)是为了解决单点故障问题
- HA集群设置两个名称节点,“活跃(Active)”和“待命( Standby) ”
- 两种名称节点的状态同步,可以借助于一个共享存储系统来实现
- 一旦活跃名称节点出现故障,就可以立即切换到待命名称节点
- Zookeeper确保一个名称节点在对外服务
- 名称节点维护映射信息,数据节点同时向两个名称节点汇报信息
8.4 HDFS2.0新特性-HDFS Federation
HDFS1.0中仍存在的问题
- 单点故障问题
- 命名服务不可以水平扩展
- 系统整体性能受限于单个名称节点的吞吐量
- 单个名称节点难以提供不同程序之间的隔离性
- HDFS HA是热备份,提供高可用性,但是无法解决可扩展性、系统性能和隔离性
HDFS Federation的设计
- 设计了多个相互独立的名称节点,使得HDFS的命名服务能够水平扩展,这些名称节点分别进行各自命名空间和块的管理,相互之间是联盟(Federation)关系,不需要彼此协调
- 所有名称节点会共享底层的数据节点存储资源,数据节点向所有名称节点汇报
- 属于同一个命名空间的块构成一个“块池”

HDFS Federation的访问方式
- 对于Federation 中的多个命名空间,可以采用客户端挂载表方式进行数据共享和访问
- 客户可以访问不同的挂载点来访问不同的命名空间
- 把各个命名空间挂载到全局“挂载表”(mount-table)中,实现数据全局共享
- 同样的命名空间挂载到个人的挂载表中,就成为应用程序可见的命名空间

HDFS Federation相对于HDFS 1.0的优势
- HDFS Federation设计可解决单名称节点存在的以下几个问题:
- HDFS集群扩展性。多个名称节点各自分管一部分目录,使得一个集群可以扩展到更多节点,不再像HDFS1.0中那样由于内存的限制制约文件存储数目
- 性能更高效·多个名称节点管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率
- 良好的隔离性。用户可根据需要将不同业务数据交由不同名称节点管理,这样不同业务之间影响很小
- 需要注意的,HDFS Federation并不能解决单点故障问题,也就是说,每个名称节点都存在在单点故障问题,需要为每个名称节点部署一个后备名称节点以应对名称节点挂掉对业务产生的影响
8.5 MapReduce1.0的缺陷
- 存在单点故障
- JobTracker “大包大揽”导致任务过重(任务多时内存开销大,上限4000节点)
- 容易出现内存溢出(分配资源只考虑MapReduce任务数,不考虑CPU、内存)
- 资源划分不合理(强制划分为slot,包括Map slot和Reduce slot)

8.6 新一代资源调度框架YARN设计思路
YARN架构思路:将原JobTacker三大功能拆分

- MapReduce1.0既是一个计算框架,也是一个资源管理调度框架
到了Hadoop2.0以后, - MapReduce1.0中的资源管理调度功能被单独分离出来形成了YARN,它是一个纯粹的资源管理调度框架,而不是一个计算框架
- MapReduce2.0是运行在YARN之上的一个纯粹的计算框架,不再自己负责资源调度管理服务,而是由YARN为其提供资源管理调度服务
8.7 YARN体系结构
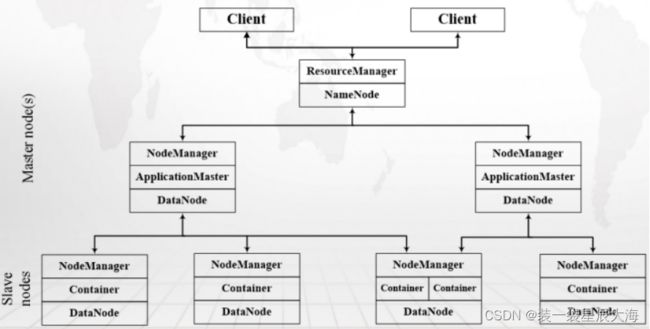
-
ResourceManager
-
处理客户端请求
-
启动/监控ApplicationMaster
-
监控NodeManager
-
资源分配与调度
-
-
ApplicationMaster
- 为应用程序申请资源,并分配给内部任务
- 任务调度、监控与容错
-
NodeManager
- 单个节点上的资源管理
- 处理来自ResourceManger的命令
- 处理来自ApplicationMaster的命令

8.8 ResourceManager
- ResourceManager (RM)是一个全局的资源管理器,负责整个系统的资源管理和分配,主要包括两个组件,即调度器(Scheduler)和应用程序管理器(ApplicationsManager)
- 调度器接收来自ApplicationMaster的应用程序资源请求,把集群中的资源以“容器”的形式分配给提出申请的应用程序,容器的选择通常会考虑应用程序所要处理的数据的位置,进行就近选择,从而实现“计算向数据靠拢”
- 容器(Container)作为动态资源分配单位,每个容器中都封装了一定数量的CPU、内存、磁盘等资源,从而限定每个应用程序可以使用的资源量
- 调度器被设计成是一个可插拔的组件,YARN不仅自身提供了许多种直接可用的调度器,也允许用户根据自己的需求重新设计调度器
- 应用程序管理器(Applications Manager)负责系统中所有应用程序的管理工作,主要包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动等
8.9 ApplicationMaster
- ResourceManager接收用户提交的作业,按照作业的上下文信息以及从NodeManager收集来的容器状态信息,启动调度过程,为用户作业启动一个ApplicationMaster
ApplicationMaster的主要功能是:
- 当用户作业提交时,ApplicationMaster与
ResourceManager协商获取资源,ResourceManager会以容器的形式为ApplicationMaster分配资源 - ApplicationMaster把获得的资源进一步分配给内部的各个任务(Map任务或Reduce任务),实现资源的“二次分配”
- 与NodeManager保持交互通信进行应用程序的启动、运行、监控和停止,监控申请到的资源的使用情况,对所有任务的执行进度和状态进行监控,并在任务发生失败时执行失败恢复(即重新申请资源重启任务)
- 定时向ResourceManager发送“心跳”消息,报告资源的使用情况和应用的进度信息
- 当作业完成时,ApplicationMaster向ResourceManager注销容器,执行周期完成
8.10 NodeManager
NodeManager是驻留在一个YARN集群中的每个节点上的代理,主要负责:
- 容器生命周期管理
- 监控每个容器的资源(CPU、内存等)使用情况
- 跟踪节点健康状况
- 以“心跳”的方式与ResourceManager保持通信
- 向ResourceManager汇报作业的资源使用情况和每个容器的运行状态
- 接收来自ApplicationMaster的启动/停止容器的各种请求
需要说明的是,NodeManager主要负责管理抽象的容器,只处理与容器相关的事情,而不具体负责每个任务(Map任务或Reduce任务)自身状态的管理,因为这些管理工作是由
ApplicationMaster完成的,ApplicationMaster会通过不断与NodeManager通信来掌握各个任务的执行状态
8.11 YARN工作流程
步骤1:用户编写客户端应用程序,向YARN提交应用程序,提交的内容包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
步骤2: YARN中的RM负责接收和处理来自客户端的请求,为应用程序分配一个容器,在该容器中启动一个AM
步骤3:AM被创建后会首先向RM注册
步骤4:AM采用轮询的方式向RM申请资源
步骤5:RM以“容器”的形式向提出申请的AM分配资源
步骤6:在容器中启动任务
步骤7:各个任务向自己的AM汇报自己的状态和进度
步骤8:应用程序运行完成后,AM向RM的应用程序管理器注销并关闭自己
同上
- client 向 ApplicationsManager 提交应用程序(job),也包括一个起
- 点 ApplicationMaster 的 命 令 ;
- 应 用 程 序 从 scheduler 获 得 一 个 container ,ApplicationManager 去对应的 NodeManager 启 动 一 个 ApplicationMaster ( 启 动ApplicationMaster 也会消耗资源,NodeManager 会向 scheduler 定期发送自己的资源使用情况);
- ApplicationMaster 向 ApplicationsManager 去注册;
- ApplicationMaster 向 scheduler给自己分配到的任务申请 container
- 申请到资源后,ApplicationMaster 去相应的节点的NodeManager 启动相应的任务**;**
- NodeManager 去启动相应的任务,消耗了自己的 container;
- 各个任务的执行进程向 ApplicationMaster 汇报自己的状态,以便失败重启;
- ApplicationMaster 向 ApplicationsManager 注销并关闭自己;或者去重启失败的任务。

8.12 YARN与MapReduce1.0框架的对比分析
总体而言,YARN相对于MapReduce1.0来说具有以下优势:
-
大大减少了承担中心服务功能的ResourceManager的资源消耗
- ApplicationMaster来完成需要大量资源消耗的任务调度和监控
- 多个作业对应多个ApplicationMaster,实现了监控分布化
-
MapReduce1.0既是一个计算框架,又是一个资源管理调度框架,但是,只能支持MapReduce编程模型。而YARN则是一个纯粹的资源调度管理框架,在它上面可以运行包括MapReduce在内的不同类型的计算框架,只要编程实现相应的ApplicationMaster
-
YARN中的资源管理比MapReduce1.0更加高效
- 以容器为单位,而不是以slot为单位,提高了资源的利用率
8.13 YARN发展目标
YARN的目标就是实现“一个集群多个框架”,为什么?
-
一个企业当中同时存在各种不同的业务应用场景,需要采用不同的计算框架
- MapReduce实现离线批处理
- 使用Impala实现实时交互式查询分析
- 使用Storm实现流式数据实时分析
- 使用Spark实现迭代计算
-
这些产品通常来自不同的开发团队,具有各自的资源调度管理机制
-
为了避免不同类型应用之间互相干扰,企业就需要把内部的服务器拆分成多个集群,分别安装运行不同的计算框架,即“一个框架一个集群”
-
导致问题
- 集群资源利用率低
- 数据无法共享
- 维护代价高
-
YARN的目标就是实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度管理框架YARN,在YARN之上可以部署其他各种计算框架
-
由YARN为这些计算框架提供统一的资源调度管理服务,并且能够根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性收缩
-
可以实现一个集群上的不同应用负载混搭,有效提高了集群的利用率
-
不同计算框架可以共享底层存储,避免了数据集跨集群移动
8.14 Spark
- Hadoop缺陷,其MapReduce计算模型延迟过高,无法胜任实时、快速计算的需求,因而只适用于离线批处理的应用场景
- 中间结果写入磁盘,每次运行都从磁盘读数据
- 在前一个任务执行完成之前,其他任务无法开始,难以胜任复杂、多阶段的计算任务
- Spark是一个可应用于大规模数据处理的快速、通用引擎
- Spark在借鉴MapReduce优点的同时,解决了MapReduce所面临的问题
- 内存计算,带来了更高的迭代运算效率
- 基于DAG的任务调度执行机制,优于MapReduce的迭代执行机制
- 当前,Spark正以其结构一─体化、功能多元化的优势,逐渐成为当今大数据领域最热门的大数据计算平台
8.15 Hadoop生态系统
HDFS(分布式文件系统)、Hbase(分布式数据库)、MapReduce(批处理计算框架)、Hive(数据仓库)、Pig(流数据处理)、Mahout(机器学习算法库)、Zookeeper(分布式协作服务)、Flume(日志收集)、Sqoop(和 RDBMS 交换数据)

1,HDFS(hadoop分布式文件系统)
是hadoop体系中数据存储管理的基础。他是一个高度容错的系统,能检测和应对硬件故障。
client:切分文件,访问HDFS,与那么弄得交互,获取文件位置信息,与DataNode交互,读取和写入数据。
namenode:master节点,在hadoop1.x中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户 端请求。
DataNode:slave节点,存储实际的数据,汇报存储信息给namenode。
secondary namenode:辅助namenode,分担其工作量:定期合并fsimage和fsedits,推送给namenode;紧急情况下和辅助恢复namenode,但其并非namenode的热备。
2,mapreduce(分布式计算框架)
mapreduce是一种计算模型,用于处理大数据量的计算。其中map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
jobtracker:master节点,只有一个,管理所有作业,任务/作业的监控,错误处理等,将任务分解成一系列任务,并分派给tasktracker。
tacktracker:slave节点,运行 map task和reducetask;并与jobtracker交互,汇报任务状态。
map task:解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入到本地磁盘(如果为map—only作业,则直接写入HDFS)。
reduce task:从map 它深刻地执行结果中,远程读取输入数据,对数据进行排序,将数据分组传递给用户编写的reduce函数执行。
3, hive(基于hadoop的数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
4,hbase(分布式列存数据库)
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。和传统关系型数据库不同,hbase采用了bigtable的数据模型:增强了稀疏排序映射表(key/value)。其中,键由行关键字,列关键字和时间戳构成,hbase提供了对大规模数据的随机,实时读写访问,同时,hbase中保存的数据可以使用mapreduce来处理,它将数据存储和并行计算完美结合在一起。
5,zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
6,sqoop(数据同步工具)
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
7,pig(基于hadoop的数据流系统)
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。通常用于离线分析。
8,mahout(数据挖掘算法库)
mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建只能应用程序。mahout现在已经包含了聚类,分类,推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法是,mahout还包含了数据的输入/输出工具,与其他存储系统(如数据库,mongoDB或Cassandra)集成等数据挖掘支持架构。
9,flume(日志收集工具)
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。
10,资源管理器的简单介绍(YARN和mesos)
随着互联网的高速发展,基于数据 密集型应用 的计算框架不断出现,从支持离线处理的mapreduce,到支持在线处理的storm,从迭代式计算框架到 流式处理框架s4,…,在大部分互联网公司中,这几种框架可能都会采用,比如对于搜索引擎公司,可能的技术方法如下:网页建索引采用mapreduce框架,自然语言处理/数据挖掘采用spark,对性能要求到的数据挖掘算法用mpi等。公司一般将所有的这些框架部署到一个公共的集群中,让它们共享集群的资源,并对资源进行统一使用,这样便诞生了资源统一管理与调度平台,典型的代表是mesos和yarn。
11,其他的一些开源组件:
1)cloudrea impala:
一个开源的查询引擎。与hive相同的元数据,SQL语法,ODBC驱动程序和用户接口,可以直接在HDFS上提供快速,交互式SQL查询。impala不再使用缓慢的hive+mapreduce批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎。可以直接从HDFS或者Hbase中用select,join和统计函数查询数据,从而大大降低延迟。
2)spark:
spark是个开源的数据 分析集群计算框架,最初由加州大学伯克利分校AMPLab,建立于HDFS之上。spark与hadoop一样,用于构建大规模,延迟低的数据分析应用。spark采用Scala语言实现,使用Scala作为应用框架。
spark采用基于内存的分布式数据集,优化了迭代式的工作负载以及交互式查询。
与hadoop不同的是,spark与Scala紧密集成,Scala象管理本地collective对象那样管理分布式数据集。spark支持分布式数据集上的迭代式任务,实际上可以在hadoop文件系统上与hadoop一起运行(通过YARN,MESOS等实现)。
3)storm
storm是一个分布式的,容错的计算系统,storm属于流处理平台,多用于实时计算并更新数据库。storm也可被用于“连续计算”,对数据流做连续查询,在计算时将结果一流的形式输出给用户。他还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。
4)kafka
kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息
5)redis
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
第九章 数据仓库Hive
9.1 数据仓库
-
数据仓库(Data Warehouse)是一个面向主题的
( Subject Oriented)·集成的( lntegrated )﹑相对稳定的( Non-Volatile)·反映历史变化( Time Variant)的数据集合,用于支持管理决策 -
企业数据仓库有效集成了来自不同部门、不同地理位置﹑具有不同格式的数据,为企业管理决策者提供了企业范围内的单一数据视图,从而为综合分析和科学决策奠定了坚实的基础。
-
数据仓库体系结构通常包含4个层次:
- 数据源:包括外部数据、现有业务(OLTP:联机事务处理)系统和文档资料等。
- 数据存储和管理:主要涉及对数据的存储和管理,包括数据仓库﹑数据集市﹑数据仓库监视﹑运行与维护工具和元数据管理等
- 数据服务:为前端工具和应用提供数据服务,可以直接从数据仓库中获取数据供前端应用使用,也可以通过OLAP(联机分析处理)服务器为前端应用提供更加复杂的数据服务
- 数据应用:直接面向最终用户。

9.2 传统数据仓库面临的挑战
- 无法满足快速增长的海量数据存储需求
- 无法有效处理不同类型的数据
- 计算和处理能力不足
9.3 Hive简介
- Hive是一个构建于Hadoop顶层的数据仓库工具,支持大规模数据存储、分析,具有良好的可扩展性。
- 某种程度上可以看作是用户编程接口,本身不存储和处理数据
- 依赖分布式文件系统HDFS存储数据
- 依赖分布式并行计算模型MapReduce(或者Tez ·Spark)处理数据
- 定义了简单的类似SQL的查询语言—— HiveQL
- 用户可以通过编写的HiveQL语句运行MapReduce任务
- 可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上
- 是一个可以提供有效、合理、只管组织和使用数据的分析工具
- Hive具有的特点非常适用于数据仓库
- 提供适合数据仓库操作的工具
- Hive本身提供了一系列对数据进行提取﹑转换﹑加载(ETL)的工具,可以存储﹑查询和分析存储在Hadoop中的大规模数据,可以将结构化数据文件映射为数据库表
- 采用批处理方式处理海量数据
- Hive需要把 HiveQL语句转换成MapReduce任务运行
- 数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化
- 提供适合数据仓库操作的工具
9.4 Hive与Hadoop生态系统中其他组件的关系
- Hive依赖于HDFS 存储数据
- Hive依赖于MapReduce处理数据
- 在某些场景下Pig可以作为Hive的替代工具,主要用于数据仓库的ETL环节。
- HBase提供数据的实时访问
9.5 Hive与传统数据库的对比分析
- Hive在很多方面和传统的关系数据库类似,但是它的底层依赖的是 HDFS和MapReduce ,所以在很多方面又有别于传统数据库
| 对比项目 | Hive | 传统数据库 |
|---|---|---|
| 数据存储 | HDFS | 本地文件系统 |
| 索引 | 支持有限索引 | 支持复杂索引 |
| 分区 | 支持 | 支持 |
| 执行引擎 | MapReduce、Tez、Spark | 自身的执行引擎 |
| 执行延迟 | 高 | 低 |
| 扩展性 | 好 | 有限 |
| 数据规模 | 大 | 小 |
9.6 Hive在企业中的部署和应用
- Hive在企业大数据分析平台中的应用

- Facebook的数据仓库架构

- Facebook的数据仓库架构-数据处理描述流程
- Web服务器及内部服务(如搜索后台)产生日志数据
- Scribe服务器把几百个甚至上千个日志数据集存放在几个甚至几十个Filers(网络文件服务器)上
- 网络文件服务器上的大部分日志文件被复制存放在HDFS系统中。并且维度数据也会每天从内部的MySQL 数据库上复制到这个HDFS系统中
- Hive为 HDFS收集所有数据创建一个数据仓库,用户可以通过编写HiveQL语言创建各种概要信息和报表以及数据执行的历史分析,同时内部的MySQL数据库也可以从中获取处理后的数据。
- 把需要实时联机访问的数据存放在Oracle RAC(可以在低成本服务器上构建高可用性数据库系统)上。
9.7 Hive系统架构
- 用户与Hive交互接口模块CLl·HWI ( Hive WebInterface) 、JDBC ODBC、Thrift Server
- 驱动模块(Driver):编译器、优化器、执行器等,负责把 HiveSQL语句转换成一系列MapReduce 作业
- 元数据存储模块(表名字、表列等)(Metastore)是一个独立的关系型数据库(自带MySQL数据库)

9.8 从外部访问Hive的典型方式
除了用CLI和 HWI工具来访问Hive 外,还可以采用以下几种典型外部访问工具:
-
Karmasphere是由Karmasphere公司发布的一个商业产品。
- 可以直接访问Hadoop里面结构化和非结构化的数据,可以运用SQL及其他语言,可以用于Ad Hoc查询和进一步的分析;
- 还为开发人员提供了一种图形化环境,可以在里面开发自定义算法,为应用程序和可重复的生产流程创建实用的数据集。
-
Hue是由 Cloudera公司提供的一个开源项目
- 是运营和开发Hadoop 应用的图形化用户界面;
- Hue程序被整合到一个类似桌面的环境,以web程序的形式发布,对于单独的用户来说不需要额外的安装。
-
Qubole 公司提供了“Hive即服务”的方式
-
托管在AWS平台,这样用户在分析存储在亚马逊S3云中的数据集时,就无需了解Hadoop系统管理;
-
提供的Hadoop服务能够根据用户的工作负载动态调整服务器资源配置,实现随需计算。
-
9.9 SQL语句转换成MapReduce的基本原理
- join的实现原理
- select name,orderid from User join Order on User.uid=Order.uid
1是表User的标记位

2是表Order的标记位
- group by实现原理
- 一个分组(Group By)操作,其功能是把表Score的不同片段按照rank和level的组合值进行合并,计算不同rank和 level的组合值分别有几条记录
- select rank, level ,count(*) as value from score group byrank. level

9.10 SQL语句转换成MapReduce的基本原理
当用户向Hive输入一段命令或查询时,Hive 需要与Hadoop交互工作来完成该操作:
- 驱动模块接收该命令或查询编译器
- 对该命令或查询进行解析编译
- 由优化器对该命令或查询进行优化计算
- 该命令或查询通过执行器进行执行
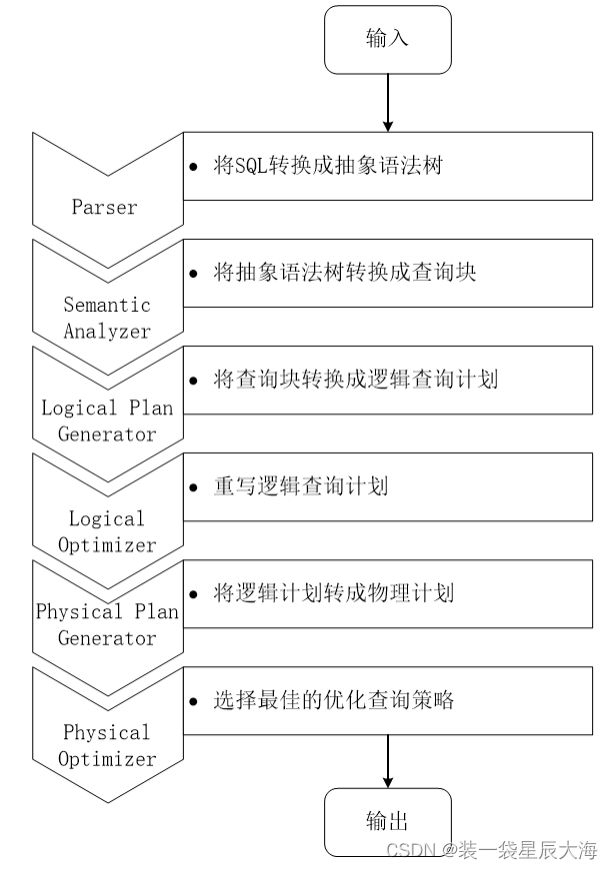
9.11 SQL查询转换成MapReduce作业过程
- 由Hive驱动模块中的编译器对用户输入的sQL语言进行词法和语法解析,将SQL语句转化为抽象语法树的形式
- 抽象语法树的结构仍很复杂,不方便直接翻译为MapReduce算法程序,因此,把抽象语法树转化为查询块
- 把查询块转换成逻辑查询计划,里面包含了许多逻辑操作符
- 重写逻辑查询计划,进行优化,合并多余操作,减少MapReduce任务数量
- 将逻辑操作符转换成需要执行的具体MapReduce任务
- 对生成的MapReduce任务进行优化,生成最终的MapReduce任务执行计划
- 由Hive驱动模块中的执行器,对最终的MapReduce任务进行执行输出
说明:
- 当启动MapReduce程序时,Hive本身是不会生成MapReduce程序的
- 需要通过一个表示“Job执行计划”的XML文件驱动执行内置的﹑原生的Mapper和 Reducer模块
- Hive通过和 Yarn通信来初始化MapReduce任务,不必直接部署在Yarn所在的管理节点上执行
- 通常在大型集群上,会有专门的网关机来部署Hive工具。网关机的作用主要是远程操作和管理节点上的Yarn通信来执行任务
- 数据文件通常存储在HDFS上, HDFS由名称节点管理
9.12 Hive HA的基本原理
Hive HA(Hive High Availability)高可用Hive解决方案
Hive在极少数情况下,甚至会出现端口不响应或者进程丢失的问题

Hive HA原理:
-
将若干个hive实例纳入一个资源池,然后对外提供一个唯一的接口,进行proxy relay。
-
对于程序开发人员,就把它认为是一台超强“hive" 。每次它接收到一个HIVE查询连接后,都会轮询资源池里可用的hive资源。
9.13 Hive HA在报表中心的应用流程
- Hive HA在报表中心的应用流程:
- 在Hadoop集群上构建的数据仓库由多个Hive进行管理>由HAProxy提供一个接口,对Hive实例进行访问
- 由Hive处理后得到的各种数据信息,或存放在MySQL 数据库中,或直接以报表的形式展现
- 不同人员会根据所需数据进行相应工作
- 其中,HAProxy是 Hive HA原理的具体实现。
9.14 Hive的数据类型
- Hive的基本数据类型
| 类型 | 描述 | 示例 |
|---|---|---|
| TINYINT | 1个字节(8位)有符号整数 | 1 |
| SMALLINT | 2个字节(16位)有符号整数 | 1 |
| INT | 4个字节(32位)有符号整数 | 1 |
| BIGINT | 8个字节(64位)有符号整数 | 1 |
| FLOAT | 4个字节(32位)单精度浮点数 | 1.0 |
| DOUBLE | 8个字节(64位)双精度浮点数 | 1.0 |
| BOOLEAN | 布尔类型,true/false | true |
| STRING | 字符串,可以指定字符集 | “xmu” |
| TIMESTAMP | 整数、浮点数或者字符串 | 1327882394(Unix新纪元秒) |
| BINARY | 字节数组 | [0,1,0,1,0,1,0,1] |
- Hive的集合数据类型
| 类型 | 描述 | 示例 |
|---|---|---|
| ARRAY | 一组有序字段,字段的类型必须相同 | Array(1,2) |
| MAP | 一组无序的键/值对,键的类型必须是原子的,值可以是任何数据类型,同一个映射的键和值的类型必须相同 | Map(‘a’,1,’b’,2) |
| STRUCT | 一组命名的字段,字段类型可以不同 | Struct(‘a’,1,1,0) |
9.15 Hive的安装与配置
1.Hive安装
安装Hive之前需要安装jdk1.6以上版本以及启动Hadoop o
- 下载安装包apache-hive-1.2.1-bin.tar.gz
下载地址:http://www.apache.org/dyn/closer.cgi/hive/ - 解压安装包apache-hive-1.2.1-bin.tar.gz至路径/usr/local
- 配置系统环境,将hive下的bin目录添加到系统的path中
2.Hive配置
Hive有三种运行模式,单机模式﹑伪分布式模式、分布式模式。
均是通过修改hive-site.xml文件实现,如果hive-site.xml文件不存在,我们可以参考$HIVE_HOME/conf目录下的hive-default.xml.template文件新建
9.16 Hive的优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写MapReduce ,减少开发人员的学习成本。
- Hive 的执行延迟比较高,因此Hive 常用于数据分析,对实时性要求不高的场合。
- Hive 优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高·
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
9.17 Hive的缺点
- Hive的HQL表达能力有限
- 迭代式算法无法表达
- 数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
- Hive的效率比较低
- Hive自动生成的MapReduce作业,通常情况下不够智能化
- Hive_调优比较困难,粒度较粗
9.18 Hive的用户自定义函数
用户自定义函数类别分为以下三种
- UDF ( User-Defined-Function) :一进一出
- 用户自定义标量函数,输入输出为一对一,如内置的upper函数;
- UDAF ( User-Defined Aggregation Function)聚集函数,多进一出
- 用户自定义聚合函数,输入输出为多对一,如内置的count/max/min/sum 函数;
- UDTF/( User-Defined Table-Generating
Functions)一进多出,如lateral view explore()
创建自定义函数的步骤
- 编码实现类,继承相应的UDF类(不同类型的两数继承类不一样),并在相应的方法中实现业务处理逻辑
- 打包上传到hive安装目录的lib目录下;
- 加载jar包, hive重启会自动加载lib下的所有jar包;也可以手动加载jar包, cli命令如下:
add jar /usr/local/apache-hive-3.1.2-bin/lib/hadoop-test-1.O-SNAPSHOT.jar; - 创建函数,分为永久函数和临时函数, temporary表示为临时函数, tuomin是函数名,后面引号里为实现类的全限定名, cli命令如下:
create temporary function tuomin as’cn.Ish.hive.udf.TuoMin’; - 查看函数信息
desc function extended tuomin; - 不需要了可以删除函数
drop temporary function if exists tuomin;
9.19 总结
- Hive是一个构建在Hadoop 之上的数据仓库工具,主要用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。Hive在某种程度上可以看作用户编程接口,本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce(或者Tez ·Spark)处理数据。Hive支持使用自身提供的命令行CLI和简单网页HWI访问方式。
- Hive在数据仓库中的具体应用中,主要用于报表中心的报表分析统计上。在Hadoop集群上构建的数据仓库由多个Hive进行管理,具体采用Hive HA原理,实现一台超强“Hive" o Impala作为开源大数据分析引擎,它支持实时计算,在性能上比 Hive高出3~ 30倍。
9.20 基于用户的协同过滤
兴趣相似的用户往往有相同的物品喜好;第一步:找到和目标用户兴趣相似的用户集合,Wuv = |N(u)∩N(v)| / sqrt(|N(u)||N(v)|),其中令 N(u)表示用户 u 感兴趣的物品集合(物品->用户倒排表);第二步:找到该集合中的用户所喜欢的、且目标用户没有听说过的物品推荐给目标用户,用户u对物品i的感兴趣程度p(u,i) = ∑[v∈S(u,K)∩N(i)] Wuv,S(u, K)是和用户 u 兴趣最接近的 K 个用户的集合,N(i)是喜欢物品 i 的用户集合,对所有物品计算*Pui后,可以对 Pui进行降序处理,取前N个物品作为推荐结果展示给用户u
9.21 基于物品的协同过滤
给目标用户推荐那些和他们之前喜欢的物品相似的物品;第一步:计算物品之间的相似度,Wij = |N(i)∩N(j)| / sqrt(|N(i)||N(j)|),其中 N(u)是用户 u 喜欢的物品的集合(物品->物品倒排表)第二步:根据物品的相似度和用户的历史行为,给用户生成推荐列表,用户 u 对物品 j 的兴趣程度 p(u,j) = ∑[i∈S(j,K)∩N(u)] Wji,S(j, K)是和物品 j 最相似的 K 个物品的集合,N(u)是用户 u 喜欢的物品的集合。
9.22 区别
①UserCF 算法推荐的是那些和目标用户有共同兴趣爱好的其他用户所喜欢的物品;
②ItemCF 算法推荐的是那些和目标用户之前喜欢的物品类似的其他物品;
③UserCF 算法的推荐更偏向社会化,而 ItemCF 算法的
推荐更偏向于个性化。
第十章 Spark x
第十一章 流计算
11.1 流数据定义
- 即数据以大量、快速、时变的流形式持续到达
11.2 流数据特征
- 数据快速持续到达,潜在大小也许是无穷无尽的
- 数据来源众多,格式复杂
- 数据量大,但是不十分关注存储,一旦经过处理,要么被丢弃,要么被归档存储
- 注重数据的整体价值,不过分关注个别数据
- 数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达数据
11.3 静态数据和流数据处理
对应着两种截然不同的计算模式:批量计算和实时计算
- 批量计算:充裕时间处理静态数据,如Hadoop
- 流数据不适合采用批量计算,因为流数据不适合用传统的关系模型建模
- 流数据必须采用实时计算,响应时间为秒级
- 在大数据时代,数据格式复杂、来源众多、数据量巨大,对实时计算提出了很大的挑战。因此,针对流数据的实时计算——流计算,应运而生
11.4 流计算定义
- 实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息
- 流计算秉承一个基本理念,即数据的价值随着时间的流逝而降低
11.5 流计算系统需求
-
高性能:处理大数据的基本要求,如每秒处理几十万条数据
-
海量式:支持TB级甚至是PB级的数据规模
-
实时性:保证较低的延迟时间,达到秒级别,甚至是毫秒级别
-
分布式:支持大数据的基本架构,必须能够平滑扩展
-
易用性:能够快速进行开发和部署
11.6 流计算框架和平台
-
商业级的流计算平台(IBM InfoSphere Streams和IBM StreamBase )
-
开源流计算框架(Twitter Storm:免费、开源的分布式实时计算系统,可简单、高效、可靠地处理大量的流数据
Yahoo! S4(Simple Scalable Streaming System):开源流计算平台,是通用的、分布式的、可扩展的、分区容错的、可插拔的流式系统 )
-
公司为支持自身业务开发的流计算框架
11.7 数据处理流程
- 传统数据处理流程:需要先采集数据并存储在关系数据库等数据管理系统中,之后由用户通过查询操作和数据管理系统进行交互
11.8 流计算处理流程
- 一般包含三个阶段:数据实时采集、数据实时计算、实时查询服务
11.9 数据实时采集
-
数据实时采集阶段通常采集多个数据源的海量数据,需要保证实时性、低延迟与稳定可靠
-
目前有许多互联网公司发布的开源分布式日志采集系统均可满足每秒数百MB的数据采集和传输需求,如: Facebook的Scribe LinkedIn的Kafka 淘宝的Time Tunnel 基于Hadoop的Chukwa和Flume
11.10 数据采集系统基本架构
-
Agent:主动采集数据,并把数据推送到Collector部分
-
Collector:接收多个Agent的数据,并实现有序、可靠、高性能的转发
-
Store:存储Collector转发过来的数据(对于流计算不存储数据)
11.11 实时查询服务
-
实时查询服务经由流计算框架得出的结果可供用户进行实时查询、展示或储存
-
传统的数据处理流程,用户需要主动发出查询才能获得想要的结果。而在流处理流程中,实时查询服务可以不断更新结果,并将用户所需的结果实时推送给用户
-
虽然通过对传统的数据处理系统进行定时查询,也可以实现不断地更新结果和结果推送,但通过这样的方式获取的结果,仍然是根据过去某一时刻的数据得到的结果,与实时结果有着本质的区别
11.12流处理系统与传统的数据处理系统区别
-
流处理系统处理的是实时的数据,而传统的数据处理系统处理的是预先存储好的静态数据
-
用户通过流处理系统获取的是实时结果,而通过传统的数据处理系统,获取的是过去某一时刻的结果
-
流处理系统无需用户主动发出查询,实时查询服务可以主动将实时结果推送给用户
11.13 流计算适用场景
- 流计算适合于需要处理持续到达的流数据、对数据处理有较高实时性要求的场景
11.14 Storm框架特点
-
整合性:Storm可方便地与队列系统和数据库系统进行整合
-
简易的API:Storm的API在使用上即简单又方便
-
可扩展性:Storm的并行特性使其可以运行在分布式集群中
-
容错性:Storm可自动进行故障节点的重启、任务的重新分配
-
可靠的消息处理:Storm保证每个消息都能完整处理
-
支持各种编程语言:Storm支持使用各种编程语言来定义任务
-
快速部署:Storm可以快速进行部署和使用
-
免费、开源:Storm是一款开源框架,可以免费使用
11.15 Storm主要术语
包括Streams、Spouts、Bolts、Topology和Stream Groupings
-
Streams:Storm将流数据Stream描述成一个无限的Tuple序列,这些Tuple序列会以分布式的方式并行地创建和处理
-
Spout:Storm认为每个Stream都有一个源头,并把这个源头抽象为Spout
-
通常Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,发送到Stream中。Spout是一个主动的角色,在接口内部有个nextTuple函数,Storm框架会不停的调用该函数
-
Bolt:Storm将Streams的状态转换过程抽象为Bolt。Bolt即可以处理Tuple,也可以将处理后的Tuple作为新的Streams发送给其他Bolt
-
Bolt可以执行过滤、函数操作、Join、操作数据库等任何操作
-
Bolt是一个被动的角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑
-
Topology:Storm将Spouts和Bolts组成的网络抽象成Topology,它可以被提交到Storm集群执行。Topology可视为流转换图,图中节点是一个Spout或Bolt,边则表示Bolt订阅了哪个Stream。当Spout或者Bolt发送元组时,它会把元组发送到每个订阅了该Stream的Bolt上进行处理
-
Topology里面的每个处理组件(Spout或Bolt)都包含处理逻辑, 而组件之间的连接则表示数据流动的方向
-
Stream Groupings:Storm中的Stream Groupings用于告知Topology如何在两个组件间(如Spout和Bolt之间,或者不同的Bolt之间)进行Tuple的传送。每一个Spout和Bolt都可以有多个分布式任务,一个任务在什么时候、以什么方式发送Tuple就是由Stream Groupings来决定的
11.16 Storm中的Stream Groupings方式
-
ShuffleGrouping:随机分组,随机分发Stream中的Tuple,保证每个Bolt的Task接收Tuple数量大致一致
-
FieldsGrouping:按照字段分组,保证相同字段的Tuple分配到同一个Task中
-
AllGrouping:广播发送,每一个Task都会收到所有的Tuple
-
GlobalGrouping:全局分组,所有的Tuple都发送到同一个Task中
-
NonGrouping:不分组,和ShuffleGrouping类似,当前Task的执行会和它的被订阅者在同一个线程中执行
-
DirectGrouping:直接分组,直接指定由某个Task来执行Tuple的处理
11.17 Storm框架设计
- Storm运行任务的方式与Hadoop类似:Hadoop运行的是MapReduce作业,而Storm运行的是“Topology” 但两者的任务大不相同,主要的不同是:MapReduce作业最终会完成计算并结束运行,而Topology将持续处理消息(直到人为终止)
Storm与Hadoop架构组件功能对应关系
| ** ** | Hadoop | Storm |
|---|---|---|
| 应用名称 | Job | Topology |
| 系统角色 | JobTracker | Nimbus |
| TaskTracker | Supervisor | |
| 组件接口 | Map/Reduce | Spout/Bolt |
- worker:每个worker进程都属于一个特定的Topology,每个Supervisor节点的worker可以有多个,每个worker对Topology中的每个组件(Spout或 Bolt)运行一个或者多个executor线程来提供task的运行服务
- executor:executor是产生于worker进程内部的线程,会执行同一个组件的一个或者多个task
- task:实际的数据处理由task完成,在Topology的生命周期中,每个组件的task数目是不会发生变化的,而executor的数目却不一定。executor数目小于等于task的数目,默认情况下,二者是相等的
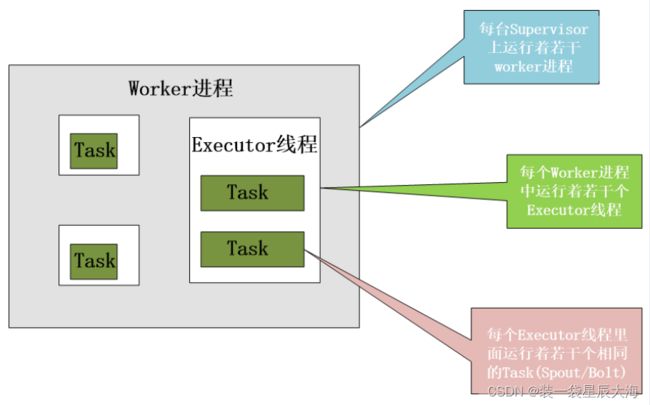
11.18 Storm集群的节点方式
Storm集群采用“Master—Worker”的节点方式:
-
Master节点运行名为“Nimbus”的后台程序(类似Hadoop中的“JobTracker”),负责在集群范围内分发代码、为Worker分配任务和监测故障
-
Worker节点运行名为“Supervisor”的后台程序,负责监听分配给它所在机器的工作,即根据Nimbus分配的任务来决定启动或停止Worker进程,一个Worker节点上同时运行若干个Worker进程
-
Storm使用Zookeeper来作为分布式协调组件,负责Nimbus和多个Supervisor之间的所有协调工作
11.19 Spark Streaming
- 基本原理:是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据
- Spark Streaming最主要的抽象:DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段的DStream,每一段数据转换为Spark中的RDD,并且对DStream的操作都最终转变为对相应的RDD的操作
11.20 Spark Streaming与Strom对比
- Spark Streaming和Storm最大的区别在于,Spark Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级响应
- Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面,相比于Storm,RDD数据集更容易做高效的容错处理
- Spark Streaming采用的小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法,因此,方便了一些需要历史数据和实时数据联合分析的特定应用场合
11.21 Storm工作流程
Master 节点运行名为“Nimbus”的后台程序,Worker 节点运行名为“Supervisor”的后台程序。
①所有 Topology 任务的提交必须在 Storm 客户端节点上进行,提交后,由 Nimbus 节点分配给其他 Supervisor 节点进行处理。
②Nimbus 节点首先将提交的 Topology 进行分片,分成一个个 Task,分配给相应的 Supervisor,并将 Task 和 Supervisor相关的信息提交到Zookeeper 集群上;
③Supervisor 会去Zookeeper 集群上认领自己的Task,通知自己的 Worker 进程进行 Task 的处理
第十二章 Flink x
第十三章 图计算 x
第十四章 数据可视化
14.1 数据可视化定义
-
数据可视化是指将大型数据集中的数据以图形图像形式表示,并利用数据分析和开发工具发现其中未知信息的处理过程
-
数据可视化技术的基本思想是将数据库中每一个数据项作为单个图元素表示,大量的数据集构成数据图像,同时将数据的各个属性值以多维数据的形式表示,可以从不同的维度观察数据,从而对数据进行更深入的观察和分析
14.2 数据可视化的作用
在大数据时代,可视化技术可以支持实现多种不同的目标:
-
观测、跟踪数据
-
分析数据
-
辅助理解数据
-
增强数据吸引力
14.3 可视化入门级工具
- Excel是微软公司的办公软件Office家族的系列软件之一,可以进行各种数据的处理、统计分析和辅助决策操作,已经广泛地应用于管理、统计、金融等领域
14.4 信息图表工具
信息图表是信息、数据、知识等的视觉化表达,它利用人脑对于图形信息相对于文字信息更容易理解的特点,更高效、直观、清晰地传递信息,在计算机科学、数学以及统计学领域有着广泛的应用
-
Google Chart API
谷歌公司的制图服务接口Google Chart API,可以用来为统计数据自动生成图片,该工具使用非常简单,不需要安装任何软件,可以通过浏览器在线查看统计图表 https://developers.google.cn/chart /interactive/docs
-
D3
D3是最流行的可视化库之一,是一个用于网页作图、生成互动图形的JavaScript函数库,提供了一个D3对象,所有方法都通过这个对象调用。D3能够提供大量线性图和条形图之外的复杂图表样式,例如Voronoi图、树形图、圆形集群和单词云等。
-
Visual.ly
Visual.ly是一款非常流行的信息图制作工具,非常好用,不需要任何设计相关的知识,就可以用它来快速创建自定义的、样式美观且具有强烈视觉冲击力的信息图表。
-
Tableau
Tableau是桌面系统中最简单的商业智能工具软件,更适合企业和部门进行日常数据报表和数据可视化分析工作。Tableau实现了数据运算与美观的图表的完美结合,用户只要将大量数据拖放到数字“画布”上,转眼间就能创建好各种图表。
-
大数据魔镜
大数据魔镜是一款优秀的国产数据分析软件,它丰富的数据公式和算法可以让用户真正理解探索分析数据,用户只要通过一个直观的拖放界面就可创造交互式的图表和数据挖掘模型。
14.5 地图工具
- 地图工具在数据可视化中较为常见,它在展现数据基于空间或地理分布上有很强的表现力,可以直观地展现各分析指标的分布、区域等特征。当指标数据要表达的主题跟地域有关联时,就可以选择以地图作为大背景,从而帮助用户更加直观地了解整体的数据情况,同时也可以根据地理位置快速地定位到某一地区来查看详细数据
-
Google Fusion Tables
Google Fusion Tables让一般使用者也可以轻松制作出专业的统计地图。该工具可以让数据表呈现为图表、图形和地图,从而帮助发现一些隐藏在数据背后的模式和趋势。
-
Modest Maps
Modest Maps是一个小型、可扩展、交互式的免费库,提供了一套查看卫星地图的API,只有10KB大小,是目前最小的可用地图库,它也是一个开源项目,有强大的社区支持,是在网站中整合地图应用的理想选择。
-
Leaflet
Leaflet是一个小型化的地图框架,通过小型化和轻量化来满足移动网页的需要。
14.6 时间线工具
时间线是表现数据在时间维度的演变的有效方式,它通过互联网技术,依据时间顺序,把一方面或多方面的事件串联起来,形成相对完整的记录体系,再运用图文的形式呈现给用户。时间线可以运用于不同领域,最大的作用就是把过去的事物系统化、完整化、精确化。
-
Timetoast
Timetoast是在线创作基于时间轴事件记载服务的网站,提供个性化的时间线服务,可以用不同的时间线来记录你某个方面的发展历程、心理路程、进度过程等等。Timetoast基于 flash 平台,可以在类似 flash时间轴上任意加入事件,定义每个事件的时间、名称、图像、描述,最终在时间轴上显示事件在时间序列上的发展,事件显示和切换十分流畅,随着鼠标点击可显示相关事件,操作简单。
-
Xtimeline
Xtimeline 是一个免费的绘制时间线的在线工具网站,操作简便,用户通过添加事件日志的形式构建时间表,同时也可给日志配上相应的图表。不同于Timetoast的是,Xtimeline是一个社区类型的时间轴网站,其中加入了组群功能和更多的社会化因素,除了可以分享和评论时间轴外,还可以建立组群讨论所制作的时间轴。
14.7 高级分析工具
-
R
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具,使用难度较高。R的功能包括数据存储和处理系统、数组运算工具(具有强大的向量、矩阵运算功能)、完整连贯的统计分析工具、优秀的统计制图功能、简便而强大的编程语言,可操纵数据的输入和输出,实现分支、循环以及用户可自定义功能等,通常用于大数据集的统计与分析。
-
Weka
Weka是一款免费的、基于Java环境的、开源的机器学习以及数据挖掘软件,不但可以进行数据分析,还可以生成一些简单图表。
-
Gephi
Gephi是一款比较特殊也很复杂的软件,主要用于社交图谱数据可视化分析,可以生成非常酷炫的可视化图形。
第四篇 大数据应用
第十五章 大数据在互联网领域的应用 x
第十六章 大数据在生物医学领域的应用 x
第十七章 大数据其他的应用 x
已知HBase数据库中已经存在一个学生表student(id,name,sex,age),表中的数据如下所示,其中id是行键。请按要求写出下列操作的HBase Shell命令。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2t7xBiT2-1671264200600)(file:///C:\Users\HUAWEI\AppData\Local\Temp\ksohtml11156\wps1.jpg)]
1 scan ‘student’
2 get ‘student’ ,’2015001’
3 put ‘student’,’2015004’,’info:name’,’chenli’
4 put ‘student’,’2015003’,’age’,’25’
5 deleteall ‘student’,’2015002’
要任何设计相关的知识,就可以用它来快速创建自定义的、样式美观且具有强烈视觉冲击力的信息图表。
-
Tableau
Tableau是桌面系统中最简单的商业智能工具软件,更适合企业和部门进行日常数据报表和数据可视化分析工作。Tableau实现了数据运算与美观的图表的完美结合,用户只要将大量数据拖放到数字“画布”上,转眼间就能创建好各种图表。
-
大数据魔镜
大数据魔镜是一款优秀的国产数据分析软件,它丰富的数据公式和算法可以让用户真正理解探索分析数据,用户只要通过一个直观的拖放界面就可创造交互式的图表和数据挖掘模型。
14.5 地图工具
- 地图工具在数据可视化中较为常见,它在展现数据基于空间或地理分布上有很强的表现力,可以直观地展现各分析指标的分布、区域等特征。当指标数据要表达的主题跟地域有关联时,就可以选择以地图作为大背景,从而帮助用户更加直观地了解整体的数据情况,同时也可以根据地理位置快速地定位到某一地区来查看详细数据
-
Google Fusion Tables
Google Fusion Tables让一般使用者也可以轻松制作出专业的统计地图。该工具可以让数据表呈现为图表、图形和地图,从而帮助发现一些隐藏在数据背后的模式和趋势。
-
Modest Maps
Modest Maps是一个小型、可扩展、交互式的免费库,提供了一套查看卫星地图的API,只有10KB大小,是目前最小的可用地图库,它也是一个开源项目,有强大的社区支持,是在网站中整合地图应用的理想选择。
-
Leaflet
Leaflet是一个小型化的地图框架,通过小型化和轻量化来满足移动网页的需要。
14.6 时间线工具
时间线是表现数据在时间维度的演变的有效方式,它通过互联网技术,依据时间顺序,把一方面或多方面的事件串联起来,形成相对完整的记录体系,再运用图文的形式呈现给用户。时间线可以运用于不同领域,最大的作用就是把过去的事物系统化、完整化、精确化。
-
Timetoast
Timetoast是在线创作基于时间轴事件记载服务的网站,提供个性化的时间线服务,可以用不同的时间线来记录你某个方面的发展历程、心理路程、进度过程等等。Timetoast基于 flash 平台,可以在类似 flash时间轴上任意加入事件,定义每个事件的时间、名称、图像、描述,最终在时间轴上显示事件在时间序列上的发展,事件显示和切换十分流畅,随着鼠标点击可显示相关事件,操作简单。
-
Xtimeline
Xtimeline 是一个免费的绘制时间线的在线工具网站,操作简便,用户通过添加事件日志的形式构建时间表,同时也可给日志配上相应的图表。不同于Timetoast的是,Xtimeline是一个社区类型的时间轴网站,其中加入了组群功能和更多的社会化因素,除了可以分享和评论时间轴外,还可以建立组群讨论所制作的时间轴。
14.7 高级分析工具
-
R
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具,使用难度较高。R的功能包括数据存储和处理系统、数组运算工具(具有强大的向量、矩阵运算功能)、完整连贯的统计分析工具、优秀的统计制图功能、简便而强大的编程语言,可操纵数据的输入和输出,实现分支、循环以及用户可自定义功能等,通常用于大数据集的统计与分析。
-
Weka
Weka是一款免费的、基于Java环境的、开源的机器学习以及数据挖掘软件,不但可以进行数据分析,还可以生成一些简单图表。
-
Gephi
Gephi是一款比较特殊也很复杂的软件,主要用于社交图谱数据可视化分析,可以生成非常酷炫的可视化图形。