全云化架构(十二):ElasticJob架构
ElasticJob架构
Elastic-Job 是 ddframe 中的 dd-job 作业模块分离出来的作业框架,基于 Quartz 和 Curator 开发,在 2015 年开源。
一、基本介绍
Elastic-Job提供了一种轻量级,无中心化解决方案。
没有统一的调度中心。集群的每个节点都是对等的, 节点之间通过注册中心进行分布式协调。E-Job 存在主节点的概念,但是主节点没有调度 的功能,而是用于处理一些集中式任务,如分片,清理运行时信息等。
Elastic-Job 最开始只有一个 elastic-job-core 的项目,在 2.X 版本以后主要分为 Elastic-Job-Lite 和 Elastic-Job-Cloud 两个子项目。
其中,Elastic-Job-Lite 定位为轻量 级无中心化解决方案,使用 jar 包的形式提供分布式任务的协调服务。而 Elastic-Job-Cloud 使用 Mesos + Docker 的解决方案,额外提供资源治理、应用分发以及进程隔离等服务(跟 Lite 的区别只是部署方式不同,他们使用相同的 API,只要开发一次)。
| Elastic-Job-Lite | Elastic-Job-Cloud | |
|---|---|---|
| 无中心化 | 是 | 否 |
| 资源分配 | 不支持 | 支持 |
| 作业模式 | 常驻 | 常驻 + 瞬时 |
| 部署依赖 | ZooKeeper | ZooKeeper + Mesos |
二、功能列表
1.弹性调度
- 支持任务在分布式场景下的分片和高可用
- 能够水平扩展任务的吞吐量和执行效率
- 任务处理能力随资源配备弹性伸缩
2.资源分配
- 在适合的时间将适合的资源分配给任务并使其生效
- 相同任务聚合至相同的执行器统一处理
- 动态调配追加资源至新分配的任务
3.作业治理
- 失效转移
- 错过作业重新执行
- 自诊断修复
4.作业依赖(TODO)
- 基于有向无环图(DAG)的作业间依赖
- 基于有向无环图(DAG)的作业分片间依赖
5.作业开放生态
- 可扩展的作业类型统一接口
- 丰富的作业类型库,如数据流、脚本、HTTP、文件、大数据等
- 易于对接业务作业,能够与 Spring 依赖注入无缝整合
6.可视化管控端
- 作业管控端
- 作业执行历史数据追踪
- 注册中心管理
三、项目架构
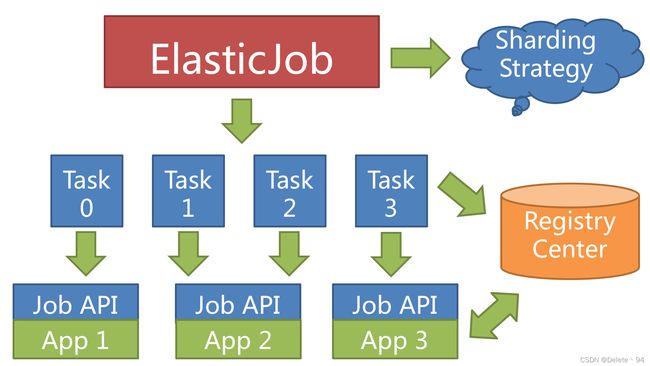
1.ElasticJob-lite
架构图

2.ElasticJob-Cloud
采用自研 Mesos Framework 的解决方案,额外提供资源治理、应用分发以及进程隔离等功能。
架构图

四、调度模型
1.进程内调度
ElasticJob-Lite 是面向进程内的线程级调度框架。通过它,作业能够透明化的与业务应用系统相结合。 它能够方便的与 Spring 、Dubbo 等 Java 框架配合使用,在作业中可自由使用 Spring 注入的 Bean,如数据源连接池、Dubbo 远程服务等,更加方便的贴合业务开发。
2.进程级调度
ElasticJob-Cloud 拥有进程内调度和进程级别调度两种方式。 由于 ElasticJob-Cloud 能够对作业服务器的资源进行控制,因此其作业类型可划分为常驻任务和瞬时任务。 常驻任务类似于 ElasticJob-Lite,是进程内调度;瞬时任务则完全不同,它充分的利用了资源分配的削峰填谷能力,是进程级的调度,每次任务的会启动全新的进程处理。
作业接口
ElasticJob 的作业可划分为基于 class 类型和基于 type 类型两种。
Class 类型的作业由开发者直接使用,需要由开发者实现该作业接口实现业务逻辑。典型代表:Simple 类型、Dataflow 类型。
Simple 类型,意为简单实现,未经任何封装的类型。需实现 SimpleJob 接口。 该接口仅提供单一方法用于覆盖,此方法将定时执行。 与Quartz原生接口相似,但提供了弹性扩缩容和分片等功能。
Dataflow 类型用于处理数据流,必须实现 fetchData()和 processData()的方法,一个用来获取数据,一个用来处理获取到的数据。
Type 类型的作业只需提供类型名称即可,开发者无需实现该作业接口,而是通过外置配置的方式使用。典型代表:Script 类型、HTTP 类型。
Script 类型,支持 shell,python,perl 等所有类型脚本。 可通过属性配置 script.command.line 配置待执行脚本,无需编码。 执行脚本路径可包含参数,参数传递完毕后,作业框架会自动追加最后一个参数为作业运行时信息。
HTTP 类型,3.0.0-beta 提供,可通过属性配置http.url,http.method,http.data等配置待请求的http信息。 分片信息以Header形式传递,key为shardingContext,值为json格式。
五、作业监听
1.常规监听器
例如执行任务处理作业服务器的文件,处理完成后删除文件,可考虑使用每个节点均执行清理任务。 此类型任务实现简单,且无需考虑全局分布式任务是否完成,应尽量使用此类型监听器。
需要实现ElasticJobListener 接口
2.分布式监听器
例如作业处理数据库数据,处理完成后只需一个节点完成数据清理任务即可。 此类型任务处理复杂,需同步分布式环境下作业的状态同步,提供了超时设置来避免作业不同步导致的死锁,应谨慎使用。
需要继承AbstractDistributeOnceElasticJobListener 抽象类
3.SPI实现
将JobListener实现添加至infra-common下resources/META-INF/services/org.apache.shardingsphere.elasticjob.infra.listener.ElasticJobListener
4.事件追踪
ElasticJob 提供了事件追踪功能,可通过事件订阅的方式处理调度过程的重要事件,用于查询、统计和监控。 目前提供了基于关系型数据库的事件订阅方式记录事件。
// 初始化数据源
DataSource dataSource = ...;
// 定义日志数据库事件溯源配置
TracingConfiguration tracingConfig = new TracingConfiguration<>("RDB", dataSource);
// 初始化注册中心
CoordinatorRegistryCenter regCenter = ...;
// 初始化作业配置
JobConfiguration jobConfig = ...;
jobConfig.getExtraConfigurations().add(tracingConfig);
new ScheduleJobBootstrap(regCenter, jobConfig).schedule();
对应库自动创建 JOB_EXECUTION_LOG 和 JOB_STATUS_TRACE_LOG 两张表以及若干索引。
六、弹性调度
弹性调度是 ElasticJob 最重要的功能,能够让任务通过分片进行水平扩展的任务处理。
1.分片
ElasticJob 中任务分片项的概念,使得任务可以在分布式的环境下运行,每台任务服务器只运行分配给该服务器的分片。 随着服务器的增加或宕机,ElasticJob 会近乎实时的感知服务器数量的变更,从而重新为分布式的任务服务器分配更加合理的任务分片项,使得任务可以随着资源的增加而提升效率。
任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
举例说明,如果作业分为 4 片,用两台服务器执行,则每个服务器分到 2 片,分别负责作业的 50% 的负载,如下图所示。

ElasticJob 可以设置分片项和自定义分片参数
个性化参数可以和分片项匹配对应关系,用于将分片项的数字转换为更加可读的业务代码。
例如:按照地区水平拆分数据库,数据库 A 是北京的数据;数据库 B 是上海的数据;数据库 C 是广州的数据。 如果仅按照分片项配置,开发者需要了解 0 表示北京;1 表示上海;2 表示广州。 合理使用个性化参数可以让代码更可读,如果配置为 0=北京,1=上海,2=广州,那么代码中直接使用北京,上海,广州的枚举值即可完成分片项和业务逻辑的对应关系。
2.资源最大限度利用
ElasticJob 提供最灵活的方式,最大限度的提高执行作业的吞吐量。 当新增加作业服务器时,ElasticJob 会通过注册中心的临时节点的变化感知到新服务器的存在,并在下次任务调度的时候重新分片,新的服务器会承载一部分作业分片,如下图所示。
将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项。
例如:3 台服务器,分成 10 片,则分片项分配结果为服务器 A = 0,1,2;服务器 B = 3,4,5;服务器 C = 6,7,8,9。 如果服务器 C 崩溃,则分片项分配结果为服务器 A = 0,1,2,3,4; 服务器 B = 5,6,7,8,9。 在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量。
3.高可用
当作业服务器在运行中宕机时,注册中心同样会通过临时节点感知,并将在下次运行时将分片转移至仍存活的服务器,以达到作业高可用的效果。 本次由于服务器宕机而未执行完的作业,则可以通过失效转移的方式继续执行。如下图所示。

七、ElasticJob-Lite 实现原理
ElasticJob-Lite 并无作业调度中心节点,而是基于部署作业框架的程序在到达相应时间点时各自触发调度。 注册中心仅用于作业注册和监控信息存储。而主作业节点仅用于处理分片和清理等功能。
1.弹性分布式实现
第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务。
某作业服务器上线时会自动将服务器信息注册到注册中心,下线时会自动更新服务器状态。
主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
通过上一项说明可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
2.注册中心数据结构
注册中心在定义的命名空间下,创建作业名称节点,用于区分不同作业,所以作业一旦创建则不能修改作业名称,如果修改名称将视为新的作业。 作业名称节点下又包含5个数据子节点,分别是 config, instances, sharding, servers 和 leader。

config 节点:作业配置信息,以 YAML 格式存储
instances 节点:作业运行实例信息,子节点是当前作业运行实例的主键。 作业运行实例主键由作业运行服务器的 IP 地址和 PID 构成。 作业运行实例主键均为临时节点,当作业实例上线时注册,下线时自动清理。注册中心监控这些节点的变化来协调分布式作业的分片以及高可用。 可在作业运行实例节点写入 TRIGGER 表示该实例立即执行一次。
sharding 节点:作业分片信息,子节点是分片项序号,从零开始,至分片总数减一。 分片项序号的子节点存储详细信息。每个分片项下的子节点用于控制和记录分片运行状态。 节点详细信息说明:
| 子节点名称 | 是否临时节点 | 描述 |
|---|---|---|
| instance | 否 | 执行该分片项的作业运行实例主键 |
| running | 是 | 分片项正在运行的状态仅配置 monitorExecution 时有效 |
| failover | 是 | 如果该分片项被失效转移分配给其他作业服务器,则此节点值记录执行此分片的作业服务器 IP |
| misfire | 否 | 是否开启错过任务重新执行 |
| disabled | 否 | 是否禁用此分片项 |
servers 节点:作业服务器信息,子节点是作业服务器的 IP 地址。 可在 IP 地址节点写入 DISABLED 表示该服务器禁用。 在新的云原生架构下,servers 节点大幅弱化,仅包含控制服务器是否可以禁用这一功能。 为了更加纯粹的实现作业核心,servers 功能未来可能删除,控制服务器是否禁用的能力应该下放至自动化部署系统。
leader 节点:作业服务器主节点信息,分为 election,sharding 和 failover 三个子节点。 分别用于主节点选举,分片和失效转移处理。
八、作业流程图
1.作业启动

2.作业执行

3.失效转移
ElasticJob 不会在本次执行过程中进行重新分片,而是等待下次调度之前才开启重新分片流程。 当作业执行过程中服务器宕机,失效转移允许将该次未完成的任务在另一作业节点上补偿执行。
失效转移需要与监听作业运行时状态同时开启才可生效。
失效转移是当前执行作业的临时补偿执行机制,在下次作业运行时,会通过重分片对当前作业分配进行调整。 举例说明,若作业以每小时为间隔执行,每次执行耗时 30 分钟。如下如图所示。

图中表示作业分别于 12:00,13:00 和 14:00 执行。图中显示的当前时间点为 13:00 的作业执行中。
如果作业的其中一个分片服务器在 13:10 的时候宕机,那么剩余的 20 分钟应该处理的业务未得到执行,并且需要在 14:00 时才能再次开始执行下一次作业。 也就是说,在不开启失效转移的情况下,位于该分片的作业有 50 分钟空档期。如下如图所示。

在开启失效转移功能之后,ElasticJob 的其他服务器能够在感知到宕机的作业服务器之后,补偿执行该分片作业。如下图所示。

在资源充足的情况下,作业仍然能够在 13:30 完成执行。
4.执行机制
当作业执行节点宕机时,会触发失效转移流程。ElasticJob 根据触发时的分布式作业执行的不同状况来决定失效转移的执行时机。
5.通知执行
当其他服务器感知到有失效转移的作业需要处理时,且该作业服务器已经完成了本次任务,则会实时的拉取待失效转移的分片项,并开始补偿执行。 也称为实时执行。
6.问询执行
作业服务在本次任务执行结束后,会向注册中心问询待执行的失效转移分片项,如果有,则开始补偿执行。 也称为异步执行。
7.适用场景
开启失效转移功能,ElasticJob 会监控作业每一分片的执行状态,并将其写入注册中心,供其他节点感知。
在一次运行耗时较长且间隔较长的作业场景,失效转移是提升作业运行实时性的有效手段; 对于间隔较短的作业,会产生大量与注册中心的网络通信,对集群的性能产生影响。 而且间隔较短的作业并未见得关注单次作业的实时性,可以通过下次作业执行的重分片使所有的分片正确执行,因此不建议短间隔作业开启失效转移。
另外需要注意的是,作业本身的幂等性,是保证失效转移正确性的前提。
九、错过任务重执行
1.概念
ElasticJob 不允许作业在同一时间内叠加执行。 当作业的执行时长超过其运行间隔,错过任务重执行能够保证作业在完成上次的任务后继续执行逾期的作业。
错过任务重执行功能可以使逾期未执行的作业在之前作业执行完成之后立即执行。 举例说明,若作业以每小时为间隔执行,每次执行耗时 30 分钟。如下如图所示。
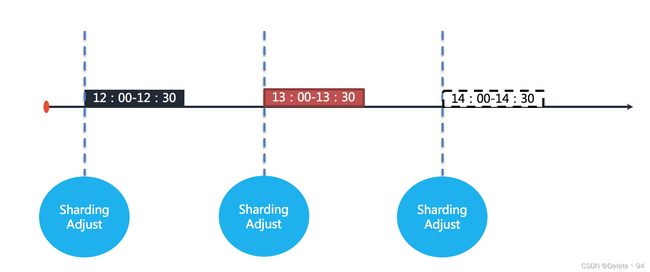
图中表示作业分别于 12:00,13:00 和 14:00 执行。图中显示的当前时间点为 13:00 的作业执行中。
如果 12:00 开始执行的作业在 13:10 才执行完毕,那么本该由 13:00 触发的作业则错过了触发时间,需要等待至 14:00 的下次作业触发。 如下如图所示。

在开启错过任务重执行功能之后,ElasticJob 将会在上次作业执行完毕后,立刻触发执行错过的作业。如下图所示。

在 13:00 和 14:00 之间错过的作业将会重新执行。
2.适用场景
在一次运行耗时较长且间隔较长的作业场景,错过任务重执行是提升作业运行实时性的有效手段; 对于未见得关注单次作业的实时性的短间隔的作业来说,开启错过任务重执行并无必要。
十、内置策略
分片策略
平均分片策略,根据分片项平均分片
奇偶分片策略,根据作业名称哈希值的奇偶数决定按照作业服务器 IP 升序或是降序的方式分片
轮询分片策略,根据作业名称轮询分片
线程池策略
CPU 资源策略
类型:CPU
根据 CPU 核数 * 2 创建作业处理线程池。
单线程策略
类型:SINGLE_THREAD
使用单线程处理作业。
错误处理策略
记录日志策略
类型:LOG
默认内置:是
记录作业异常日志,但不中断作业执行。
抛出异常策略
类型:THROW
默认内置:是
抛出系统异常并中断作业执行。
忽略异常策略
类型:IGNORE
默认内置:是
忽略系统异常且不中断作业执行。
邮件通知策略
类型:EMAIL
默认内置:否
发送邮件消息通知,但不中断作业执行。需添加maven依赖
企业微信通知策略
类型:WECHAT
默认内置:否
发送企业微信消息通知,但不中断作业执行。需添加maven依赖
钉钉通知策略
类型:DINGTALK
默认内置:否
发送钉钉消息通知,但不中断作业执行。