PyTorch深度学习实战 | 典型卷积神经网络

在深度学习的发展过程中,出现了很多经典的卷积神经网络,它们对深度学习的学术研究和工业生产都起到了巨大的促进作用,如VGG、ResNet、Inception和DenseNet等,很多投入实用的卷积神经都是在它们的基础上进行改进的。初学者应从试验开始,通过阅读论文和实现代码(tensorflow.keras.applications包中实现了很多有影响力的神经网络模型的源代码)来全面了解它们。下文简要讨论两个有代表性的卷积神经网络,它们都是卷积层、池化层、全连接层等的不同组合。
01、VGG-16,VGG-19
VGG-16[32]是牛津大学的Visual Geometry Group在2015年发布的共16层的卷积神经网络,有约1.38亿个网络参数。该网络常被初学者用来学习和体验卷积神经网络。
VGG-16模型是针对ImageNet挑战赛设计的,该挑战赛的数据集为ILSVRC-2012图像分类数据集。ILSVRC-2012图像分类数据集的训练集有总共有1281167张图片,分为1000个类别,它的验证集有50000张图片样本,每个类别50个样本。
ILSVRC-2012图像分类数据集是2009年开始创建的ImageNet图像数据集的一部分。基于该图像数据集举办了具有很大影响力的ImageNet挑战赛,很多新模型就是在该挑战赛上发布的。
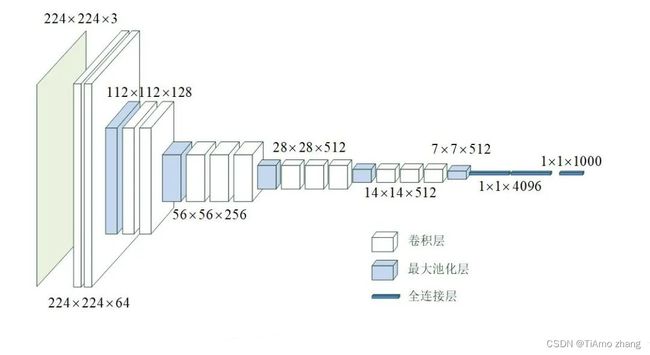
图 1 VGG-16模型的网络结构
VGG-16模型的网络结构如图1所示,从左侧输入大小为224×224×3的彩色图片,在右侧输出该图片的分类。
输入层之后,先是2个大小为3×3、卷积核数为64、步长为1、零填充的卷积层,此时的数据维度大小为224×224×64,在水平方向被拉长了。
然后是1个大小为2×2的最大池化层,将数据的维度降为112×112×64,再经过2个大小为3×3、卷积核数为128、步长为1、零填充的卷积层,再一次在水平方向上被拉长,变为112×112×128。
然后是1个大小为2×2的最大池化层,和3个大小为3×3、卷积核数为256、步长为1、零填充的卷积层,数据维度变为56×56×256。
然后是1个大小为2×2的最大池化层,和3个大小为3×3、卷积核数为512、步长为1、零填充的卷积层,数据维度变为28×28×512。
然后是1个大小为2×2的最大池化层,和3个大小为3×3、卷积核数为512、步长为1、零填充的卷积层,数据维度变为14×14×512。
然后是1个大小为2×2的最大池化层,数据维度变为7×7×512。
然后是1个Flatten层将数据拉平。
最后是3个全连接层,节点数分别为4096、4096和1000。
除最后一层全连接层采用Softmax激活函数外,所有卷积层和全连接层都采用relu激活函数。
从上面网络结构可见,经过卷积层,通道数量不断增加,而经过池化层,数据的长度和宽度不断减少。
Visual Geometry Group后又发布了19层的VGG-19模型。
TensorFlow实现了VGG-16模型和VGG-19模型 。TensorFlow还提供了用ILSVRC-2012-CLS图像分类数据集预先训练好的VGG-16和VGG-19模型,下面给出一个用预先训练好的模型来识别一幅图片(图2)的例子。

图2 试验用的小狗照片
代码清单1 VGG-19预训练模型应用(vgg19_app.py)
1. import tensorflow.keras.applications.vgg19 as vgg19
2. import tensorflow.keras.preprocessing.image as imagepre
3.
4. # 加载预训练模型
5. model = vgg19.VGG19(weights='E:\\MLDatas\\vgg19_weights_tf_dim_ordering_tf_kernels.h5', include_top=True) # 加载预先下载的模型
6. # 加载图片并转换为合适的数据形式
7. image = imagepre.load_img('116.jpg', target_size=(224, 224))
8. imagedata = imagepre.img_to_array(image)
9. imagedata = imagedata.reshape((1,) + imagedata.shape)
10.
11. imagedata = vgg19.preprocess_input(imagedata)
12. prediction = model.predict(imagedata) # 分类预测
13. results = vgg19.decode_predictions(prediction, top=3)
14. print(results)
15. #[[('n02113624', 'toy_poodle', 0.6034094), ('n02113712', 'miniature_poodle', 0.34426507), ('n02113799', 'standard_poodle', 0.0124355545)]]可见,图片为toy poodle的概率最大,为0.6。
02、残差网络
随着网络层次的加深,训练集的损失函数可能会呈现出先下降再上升的现象,称为网络退化(degradation)现象。残差网络(ResNet)[33]提出了抑制梯度消散、网络退化来加速训练收敛的方法,克服了层数多导致的收敛慢、甚至无法收敛的问题,使网络的层数得以增加。
残差单元是残差网络的基本组成部分,它的特点是有一条跨层的短接。图3示例了一个残差单元。该单元有两条传递路径,除了常规的卷积、批标准化、激活处理路径外,还有一条跨层的直接传递路径。

图3 残差单元示例
残差网络一般要由很多残差单元首尾连接而成。残差网络的思想是通过跨层的短接,在误差反向传播时,去掉不变的主体部分,从而突出微小的变化,使得网络对误差更加敏感。通过短接还使得误差消散问题得到了较好的解决。试验结果证明残差网络具有良好的学习效果。
图3所示残差单元在TensorFlow框架下的实现见代码清单2,其中第28行是将两条处理路径传来的数据相加。该代码来自tensorflow.keras.applications包,该包包含了许多经典模型的实现代码,值得读者仔细分析。
代码清单 2残差单元[1]
1. def block1(x, filters, kernel_size=3, stride=1, conv_shortcut=True, name=None):
2. bn_axis = 3 if backend.image_data_format() == 'channels_last' else 1
3. if conv_shortcut:
4. shortcut = layers.Conv2D(
5. 4 * filters, 1, strides=stride, name=name + '_0_conv')(
6. x)
7. shortcut = layers.BatchNormalization(
8. axis=bn_axis, epsilon=1.001e-5, name=name + '_0_bn')(
9. shortcut)
10. else:
11. shortcut = x
12. x = layers.Conv2D(filters, 1, strides=stride, name=name + '_1_conv')(x)
13. x = layers.BatchNormalization(
14. axis=bn_axis, epsilon=1.001e-5, name=name + '_1_bn')(
15. x)
16. x = layers.Activation('relu', name=name + '_1_relu')(x)
17. x = layers.Conv2D(
18. filters, kernel_size, padding='SAME', name=name + '_2_conv')(
19. x)
20. x = layers.BatchNormalization(
21. axis=bn_axis, epsilon=1.001e-5, name=name + '_2_bn')(
22. x)
23. x = layers.Activation('relu', name=name + '_2_relu')(x)
24. x = layers.Conv2D(4 * filters, 1, name=name + '_3_conv')(x)
25. x = layers.BatchNormalization(
26. axis=bn_axis, epsilon=1.001e-5, name=name + '_3_bn')(
27. x)
28. x = layers.Add(name=name + '_add')([shortcut, x])
29. x = layers.Activation('relu', name=name + '_out')(x)
30. return x03、源码展示
链接: https://pan.baidu.com/s/1kG88Z39otL7GrVhiSOJlqA?pwd=6yb8 提取码: 6yb8